Sao lưu - một trong những điều quan trọng nhất cần lưu ý khi quản lý cơ sở dữ liệu. Người ta nói rằng có hai loại người - những người sao lưu dữ liệu của họ và những người sẽ sao lưu dữ liệu của họ. Trong bài đăng trên blog này, chúng tôi sẽ thảo luận về các phương pháp hay về sao lưu và chỉ cho bạn cách bạn có thể xây dựng một hệ thống sao lưu đáng tin cậy bằng cách sử dụng ClusterControl.
Chúng ta sẽ xem cách ClusterControl’s cung cấp cho bạn quản lý sao lưu tập trung cho MySQL, MariaDB, MongoDB và PostgreSQL. Nó cung cấp cho bạn các bản sao lưu nóng của các tập dữ liệu lớn, khôi phục tại thời điểm, mã hóa dữ liệu lúc còn lại và đang chuyển, tính toàn vẹn của dữ liệu thông qua xác minh khôi phục tự động, sao lưu đám mây (AWS, Google và Azure) cho Khôi phục sau thảm họa, các chính sách lưu giữ để đảm bảo tuân thủ cũng như cảnh báo và báo cáo tự động.
Các loại sao lưu
Có hai kiểu sao lưu chính mà chúng ta có thể thực hiện trong ClusterControl:
- Sao lưu logic - sao lưu dữ liệu được lưu trữ ở định dạng con người có thể đọc được như SQL
- Sao lưu vật lý - sao lưu chứa dữ liệu nhị phân
Cả hai bổ sung cho nhau - sao lưu hợp lý cho phép bạn (ít nhiều dễ dàng) truy xuất tối đa một hàng dữ liệu. Sao lưu vật lý sẽ cần nhiều thời gian hơn để hoàn thành điều đó, nhưng mặt khác, chúng cho phép bạn khôi phục toàn bộ máy chủ rất nhanh chóng (có thể mất hàng giờ hoặc thậm chí vài ngày khi sử dụng sao lưu hợp lý).
ClusterControl hỗ trợ sao lưu cho MySQL / MariaDB / Percona Server, PostgreSQL và MongoDB.
Lên lịch sao lưu
Bắt đầu sao lưu trong ClusterControl đơn giản và hiệu quả bằng cách sử dụng trình hướng dẫn. Lập lịch sao lưu mang lại sự thân thiện với người dùng và khả năng truy cập vào các tính năng khác như mã hóa, tự động kiểm tra / xác minh bản sao lưu hoặc lưu trữ đám mây.
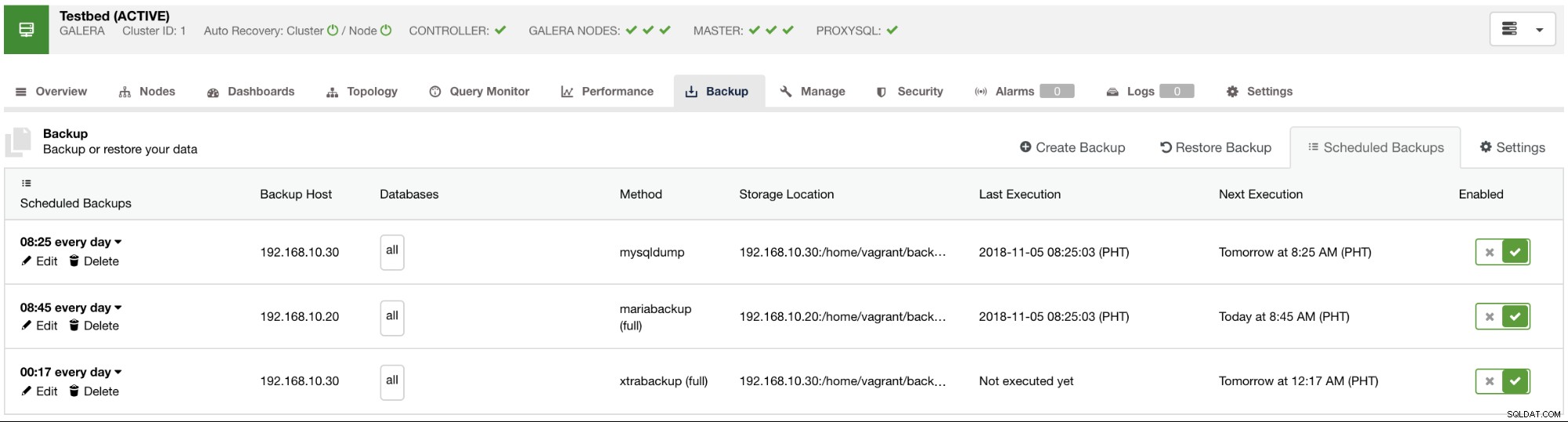
Các bản sao lưu đã lên lịch có sẵn sẽ được liệt kê trong tab Sao lưu theo lịch trình như được thấy trong hình ảnh bên dưới:
Như một phương pháp hay để lập lịch sao lưu, bạn phải có khả năng lưu giữ bản sao lưu đã xác định của mình và nên sao lưu hàng ngày. Tuy nhiên, nó cũng phụ thuộc vào dữ liệu bạn cần, lưu lượng truy cập bạn có thể mong đợi và tính khả dụng của dữ liệu bất cứ khi nào bạn cần, đặc biệt là trong quá trình khôi phục dữ liệu mà dữ liệu đã vô tình bị xóa hoặc hỏng đĩa - đó là điều không thể tránh khỏi. Cũng có những tình huống mà việc mất dữ liệu có thể tái tạo hoặc có thể được sao chép theo cách thủ công, chẳng hạn như tạo báo cáo, hình thu nhỏ hoặc dữ liệu được lưu trong bộ nhớ cache. Mặc dù câu hỏi phụ thuộc vào việc bạn cần chúng ngay lập tức như thế nào bất cứ khi nào thảm họa xảy ra; khi có thể, bạn muốn sao lưu cả hai bản sao lưu mysqldump và xtrabackup hàng ngày để MySQL tận dụng tính khả dụng của bản sao lưu hợp lý và vật lý. Để bao gồm nhiều cơ sở hơn nữa, bạn có thể muốn lên lịch nhiều lần chạy xtrabackup gia tăng mỗi ngày. Điều này có thể tiết kiệm một số dung lượng ổ đĩa, I / O đĩa hoặc thậm chí cả I / O CPU hơn là sao lưu toàn bộ.
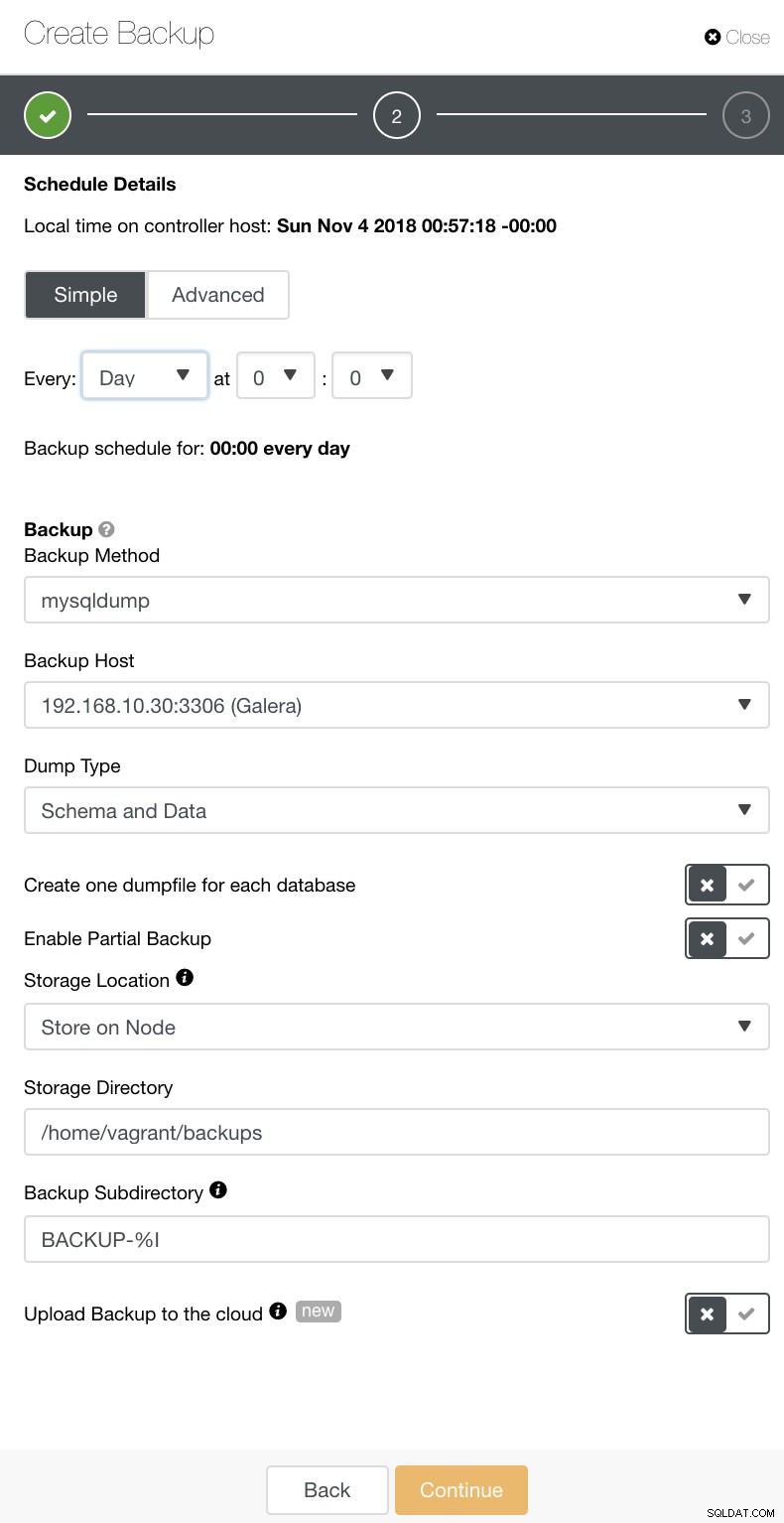
Trong ClusterControl, bạn có thể dễ dàng lập lịch các loại sao lưu khác nhau này. Có một số cài đặt để quyết định. Bạn có thể lưu trữ một bản sao lưu trên bộ điều khiển hoặc cục bộ, trên nút cơ sở dữ liệu nơi bản sao lưu được thực hiện. Bạn cần quyết định vị trí lưu trữ bản sao lưu và cơ sở dữ liệu nào bạn muốn sao lưu - tất cả tập dữ liệu hay lược đồ riêng biệt? Xem hình ảnh bên dưới:
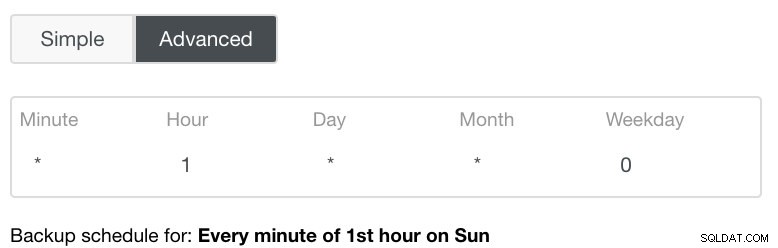
Cài đặt Nâng cao sẽ tận dụng cấu hình giống cron để có thêm chi tiết. Xem hình ảnh bên dưới:
Bất cứ khi nào xảy ra lỗi, ClusterControl sẽ xử lý những vấn đề này một cách hiệu quả và tạo ra nhật ký để chẩn đoán thêm về lỗi sao lưu.
Tùy thuộc vào loại sao lưu bạn đã chọn, có các cài đặt riêng biệt để định cấu hình. Đối với Xtrabackup và Galera Cluster, bạn có thể có các tùy chọn để chọn cài đặt nào mà bản sao lưu vật lý của bạn sẽ áp dụng khi chạy. Xem bên dưới:
- Sử dụng tính năng Nén
- Mức độ nén
- Bỏ đồng bộ hóa nút trong khi sao lưu
- Ổ khóa dự phòng
- Khóa DDL trên mỗi bảng
- Xtrabackup Chủ đề sao chép song song
- Tốc độ truyền tải mạng (MB / s)
- Sử dụng PIGZ cho gzip song song
- Bật mã hóa
- Giữ chân
Bạn có thể thấy, trong hình ảnh bên dưới, cách bạn có thể gắn cờ các tùy chọn cho phù hợp và có các biểu tượng chú giải công cụ cung cấp thêm thông tin về các tùy chọn mà bạn muốn tận dụng cho chính sách dự phòng của mình.
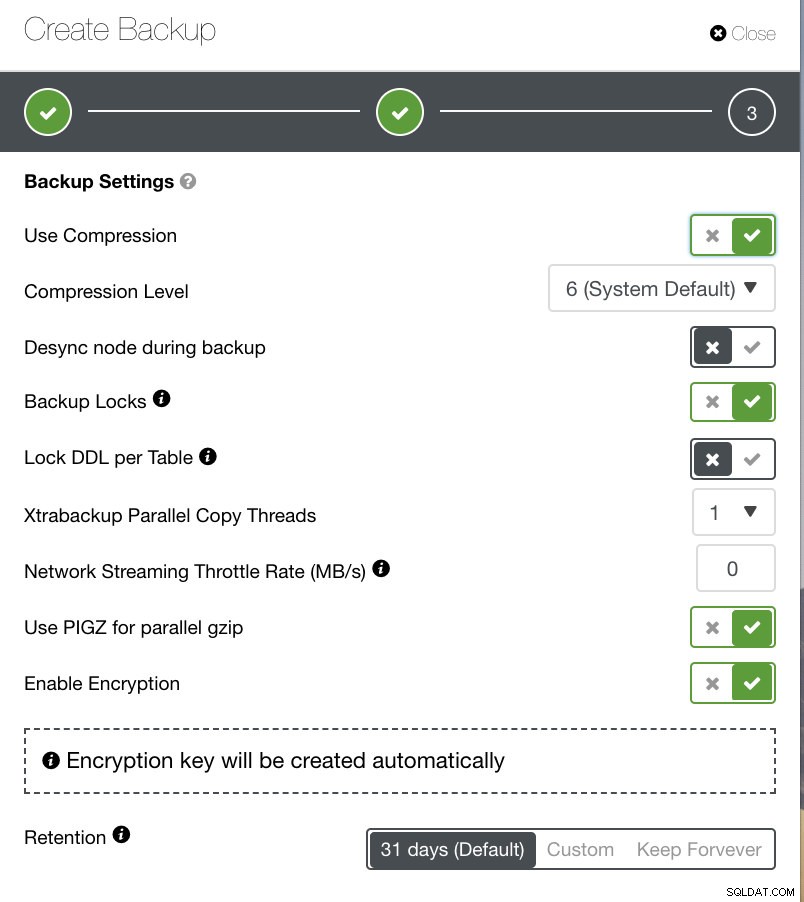
Tùy thuộc vào chính sách sao lưu của bạn, ClusterControl có thể được điều chỉnh cho phù hợp với các phương pháp hay nhất để sử dụng các bản sao lưu cập nhật sẵn có của bạn. Khi xác định chính sách sao lưu của mình, bạn phải có sẵn thiết lập theo yêu cầu từ phần cứng đến phần mềm đến đám mây, độ bền, tính khả dụng cao hoặc khả năng mở rộng.
Khi sao lưu trên Galera Cluster, bạn nên đặt nút Galera wsrep_desync =ON trong khi sao lưu đang chạy. Điều này sẽ loại bỏ nút tham gia Kiểm soát luồng và sẽ bảo vệ toàn bộ cụm khỏi độ trễ sao chép, đặc biệt nếu dữ liệu của bạn được sao lưu lớn. Trong ClusterControl, hãy nhớ rằng điều này cũng có thể xóa nút sao lưu mục tiêu của bạn khỏi bộ cân bằng tải. Điều này đặc biệt đúng nếu bạn sử dụng proxy HAProxy, ProxySQL hoặcMaxScale. Nếu bạn đã thiết lập trình quản lý cảnh báo trong trường hợp nút bị giải đồng bộ hóa, bạn có thể tắt trong khoảng thời gian đó khi quá trình sao lưu đã được kích hoạt.
Một cách phổ biến khác để giảm thiểu tác động của bản sao lưu đối với Cụm Galera hoặc tổng thể nhân bản là triển khai một nô lệ nhân bản và sau đó sử dụng nó như một nguồn sao lưu - theo cách này, Galera Cluster sẽ không bị ảnh hưởng bất kỳ lúc nào vì bản sao lưu trên nô lệ được tách khỏi cụm.
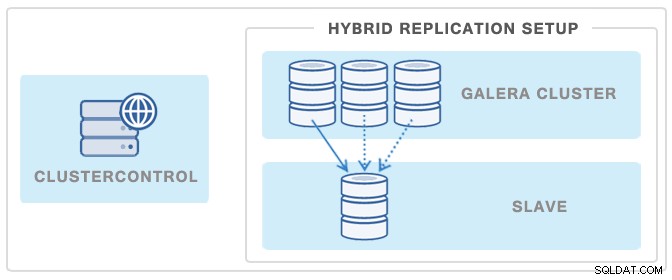
Bạn có thể triển khai một nô lệ như vậy chỉ trong vài cú nhấp chuột bằng cách sử dụng ClusterControl. Xem hình ảnh bên dưới:
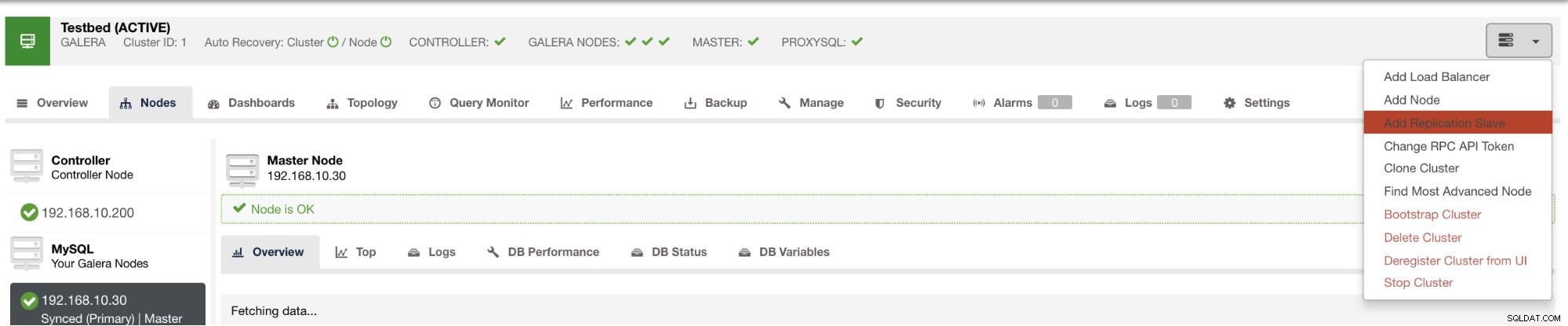
và khi bạn nhấp vào nút đó, bạn có thể chọn các nút để thiết lập nô lệ. Đảm bảo rằng đã bật ghi nhật ký nhị phân cho các nút. Việc kích hoạt bản ghi nhị phân cũng có thể được thực hiện thông qua ClusterControl, điều này bổ sung thêm tính khả thi cho việc quản lý bản gốc mong muốn của bạn. Xem hình ảnh bên dưới:
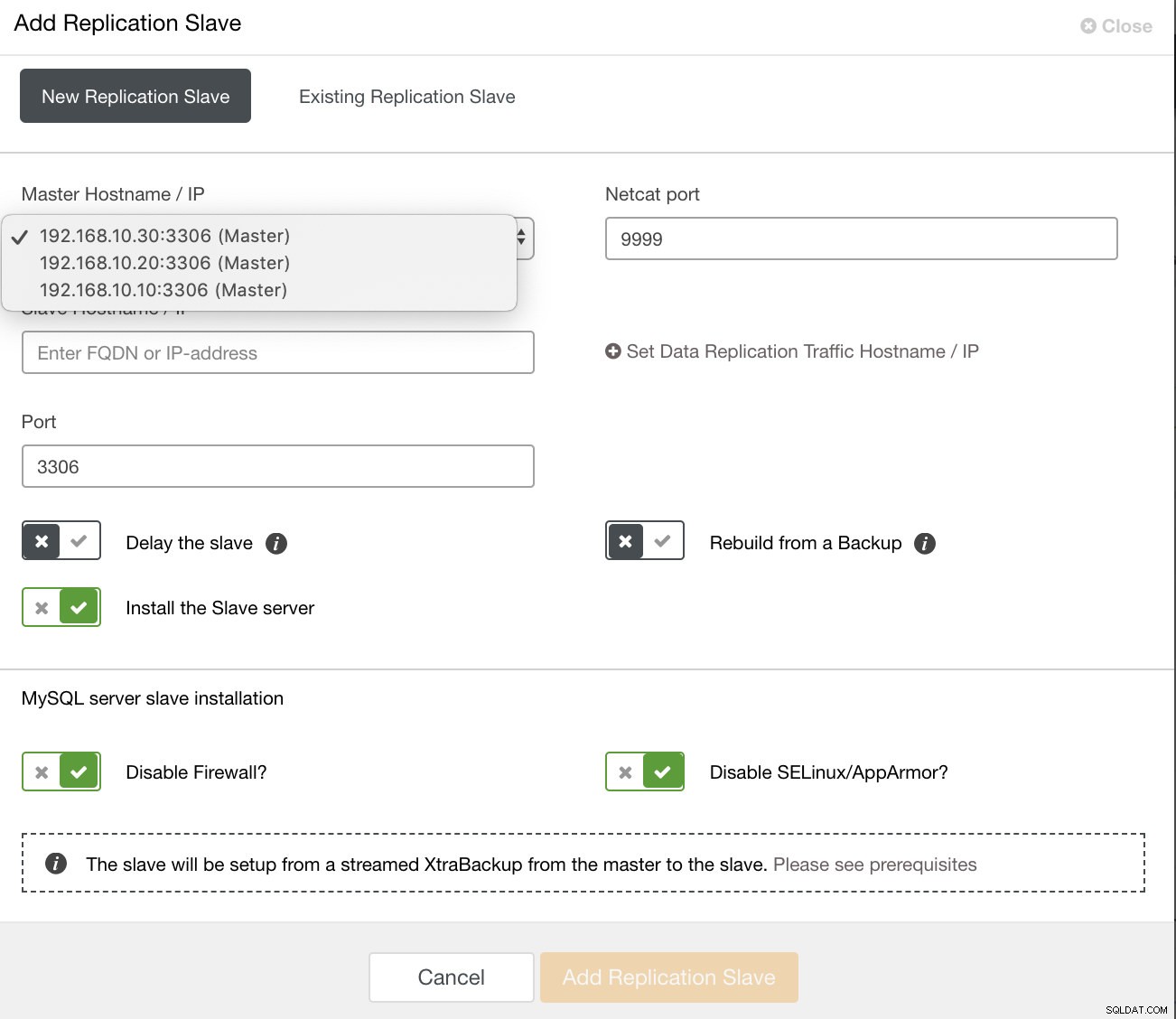
và bạn cũng có thể thiết lập nô lệ sao chép hiện có,
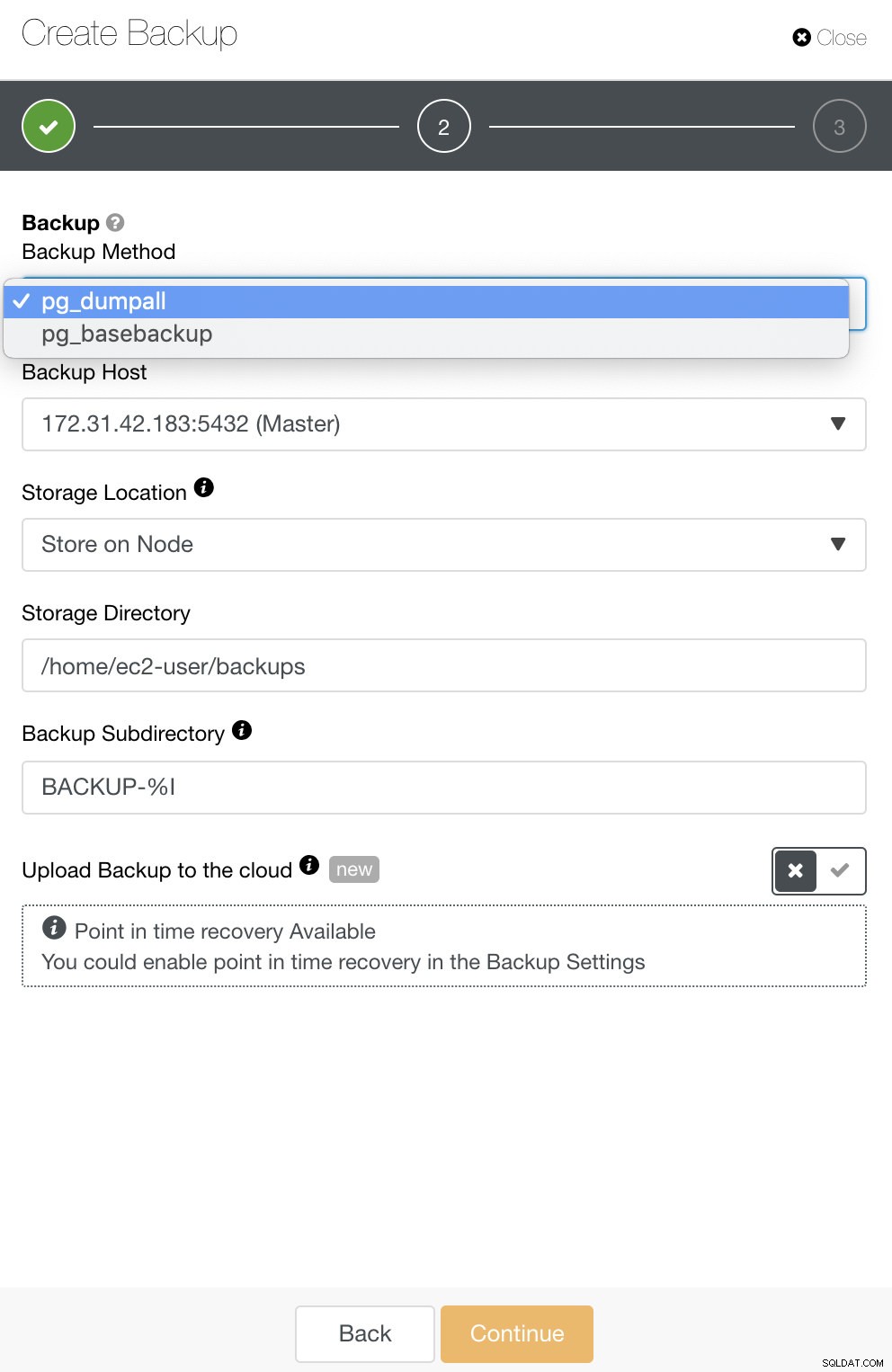
Đối với PostgreSQL, bạn có các tùy chọn để sao lưu dự phòng logic hoặc vật lý. Trong ClusterControl, bạn có thể tận dụng các bản sao lưu PostgreSQL của mình bằng cách chọn pg_dump hoặc pg_basebackup. pg_basebackup sẽ không hoạt động đối với các phiên bản cũ hơn 9.3.
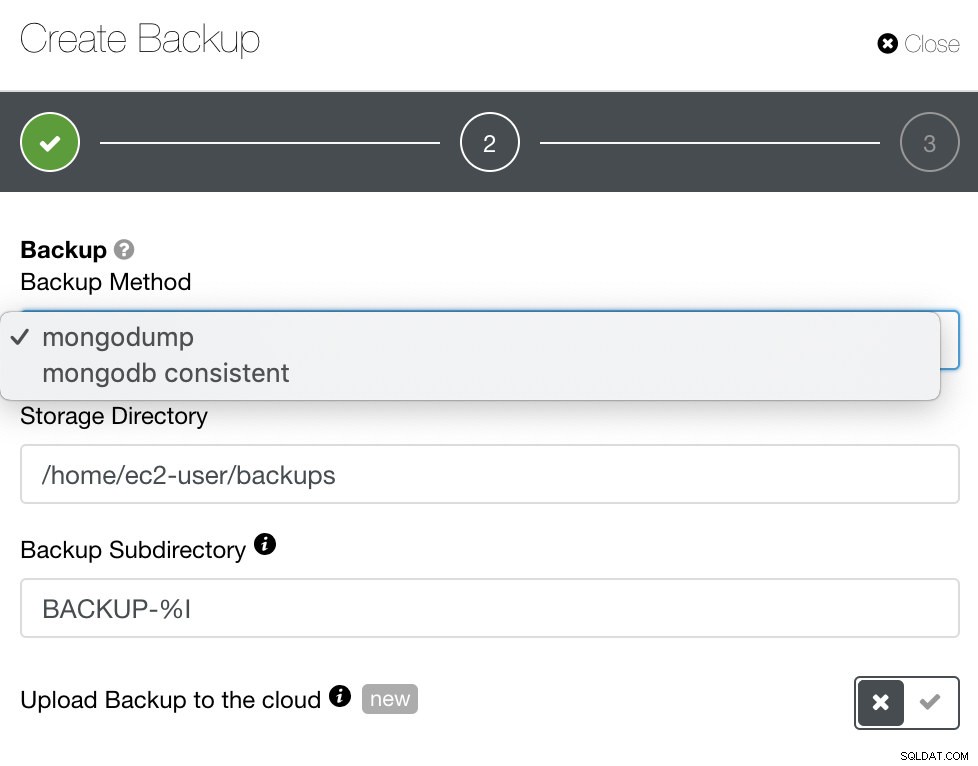
Đối với MongoDB, ClusterControl cung cấp mongodump hoặc mongodb nhất quán. Bạn có thể phải lưu ý rằng mongodb phù hợp không hỗ trợ RHEL 7 nhưng bạn có thể cài đặt nó theo cách thủ công.
Theo mặc định, ClusterControl sẽ liệt kê một báo cáo cho tất cả các bản sao lưu đã được thực hiện, thành công hay thất bại. Xem bên dưới:
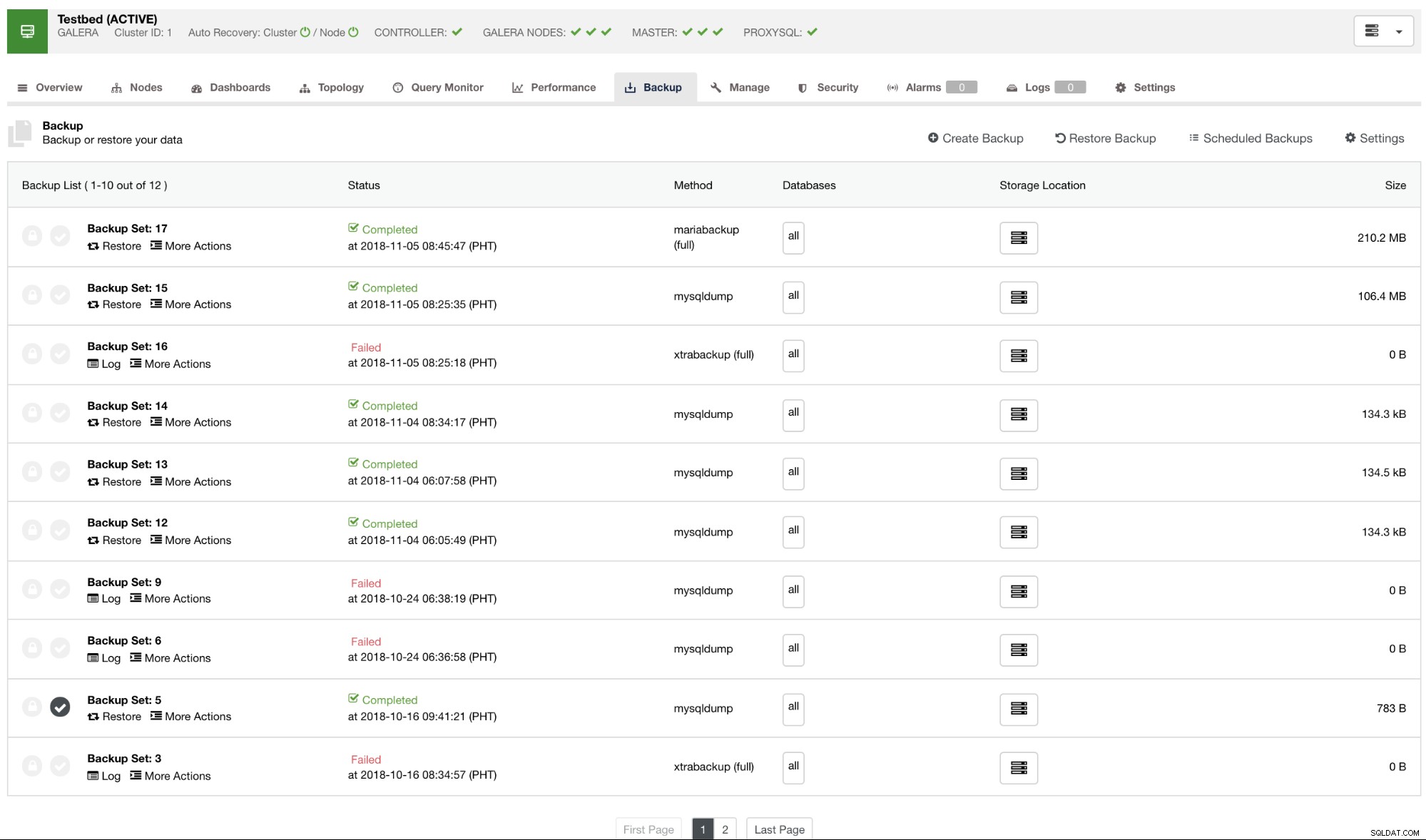
Bạn có thể kiểm tra danh sách các báo cáo sao lưu đã được tạo hoặc lập lịch sử dụng ClusterControl. Trong danh sách, bạn có thể xem nhật ký để điều tra và chẩn đoán thêm. Ví dụ:nếu quá trình sao lưu đã hoàn tất chính xác theo chính sách sao lưu mong muốn của bạn, liệu nén và mã hóa có được đặt chính xác hay không hoặc kích thước dữ liệu sao lưu mong muốn có chính xác hay không. Đây là một cách tốt để thực hiện kiểm tra nhanh - nếu tập dữ liệu của bạn có kích thước khoảng 1GB, thì không có cách nào mà một bản sao lưu đầy đủ có thể nhỏ đến 100KB - chắc chắn đã xảy ra lỗi vào một lúc nào đó.
Khôi phục sau thảm họa
Lưu trữ các bản sao lưu trong cụm (trực tiếp trên nút cơ sở dữ liệu hoặc trên máy chủ ClusterControl) rất hữu ích khi bạn muốn nhanh chóng khôi phục dữ liệu của mình:tất cả các tệp sao lưu đều có sẵn và có thể được giải nén và khôi phục ngay lập tức. Khi nói đến Khôi phục thảm họa (DR), đây có thể không phải là lựa chọn tốt nhất. Các vấn đề khác nhau có thể xảy ra - máy chủ có thể bị sập, mạng có thể hoạt động không ổn định, thậm chí toàn bộ trung tâm dữ liệu có thể không truy cập được do một số loại ngừng hoạt động. Nó có thể xảy ra cho dù bạn làm việc với một nhà cung cấp dịch vụ nhỏ hơn với một trung tâm dữ liệu duy nhất hay một nhà cung cấp toàn cầu như Amazon Web Services. Do đó, không an toàn khi giữ tất cả trứng của bạn trong một giỏ duy nhất - bạn nên đảm bảo rằng bạn có một bản sao dự phòng của mình được lưu trữ ở một số vị trí bên ngoài. ClusterControl hỗ trợ Amazon S3, Google Storage và Azure Cloud Storage.
Đối với những người muốn triển khai các chính sách DR của riêng mình, các bản sao lưu của ClusterControl được lưu trữ trong một thư mục có cấu trúc độc đáo. Bạn cũng có tùy chọn tải bản sao lưu của mình lên đám mây. Xem hình ảnh bên dưới:
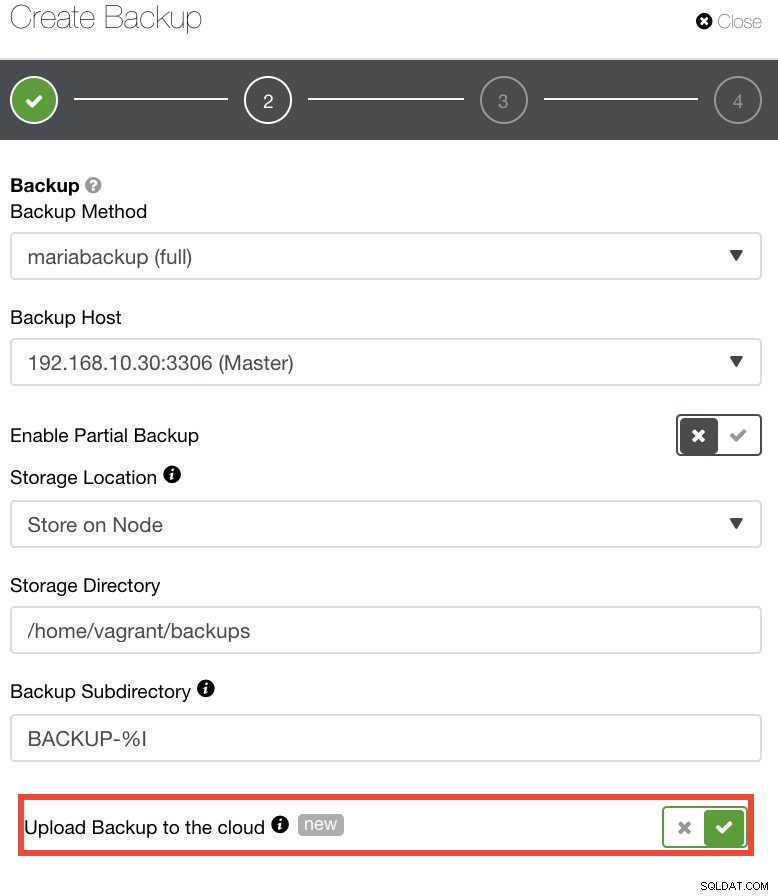
Bạn có thể chọn và tải lên Amazon Web Services, Google Cloud và Microsoft Azure. Xem hình ảnh bên dưới:
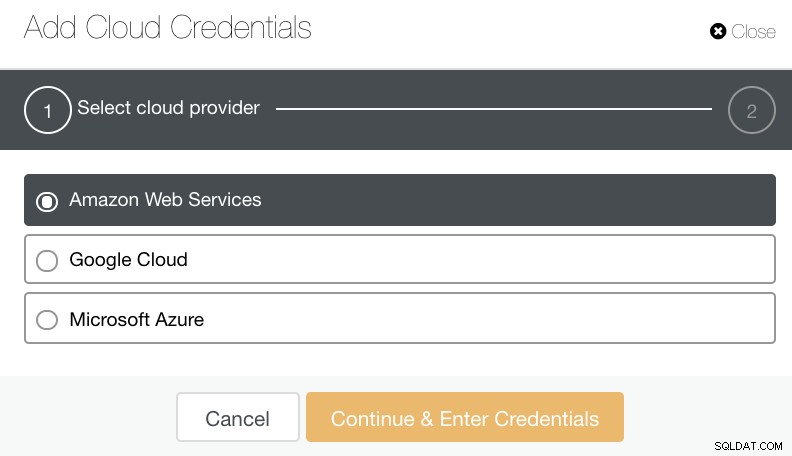
Một phương pháp hay khi lưu trữ các bản sao lưu cơ sở dữ liệu của bạn, hãy đảm bảo rằng đích đến đám mây mục tiêu của bạn dựa trên cùng một khu vực với các máy chủ cơ sở dữ liệu của bạn hoặc ít nhất là gần nhất. Đảm bảo rằng nó cung cấp tính khả dụng, độ bền và khả năng mở rộng cao; vì bạn phải xem xét mức độ thường xuyên và tức thì bạn cần dữ liệu của mình.
Ngoài việc tạo bản sao lưu hợp lý hoặc vật lý cho DR của bạn, việc tạo ảnh chụp nhanh toàn bộ dữ liệu của bạn (ví dụ:sử dụng Ảnh chụp nhanh LVM, Ảnh chụp nhanh Amazon EBS hoặc Ảnh chụp nhanh khối lượng nếu sử dụng hệ thống tệp Veritas) trên nút cụ thể có thể tăng khả năng khôi phục sao lưu của bạn. Bạn cũng có thể sử dụng WAL (cho Postgres) để khôi phục điểm trong thời gian (PITR) hoặc nhật ký nhị phân MySQL cho PITR của bạn. Do đó, bạn phải xem xét rằng bạn có thể cần tạo lưu trữ riêng cho PITR của mình. Vì vậy, hoàn toàn ổn nếu bạn xây dựng và triển khai bộ tập lệnh của riêng mình và xử lý DR theo yêu cầu chính xác của bạn.
Một cách tuyệt vời khác để triển khai chính sách Khôi phục sau thảm họa là sử dụng nô lệ sao chép không đồng bộ - điều mà chúng tôi đã đề cập trước đó trong bài đăng trên blog này. Bạn có thể triển khai nô lệ không đồng bộ như vậy ở một vị trí từ xa, một số trung tâm dữ liệu khác có thể, sau đó sử dụng nó để sao lưu và lưu trữ cục bộ trên nô lệ đó. Tất nhiên, bạn muốn tạo một bản sao lưu cục bộ của cụm của mình để lưu nó cục bộ nếu bạn cần khôi phục cụm. Việc di chuyển dữ liệu giữa các trung tâm dữ liệu có thể mất nhiều thời gian, vì vậy việc có sẵn các tệp sao lưu cục bộ có thể giúp bạn tiết kiệm thời gian. Trong trường hợp bạn mất quyền truy cập vào cụm sản xuất chính của mình, bạn vẫn có thể có quyền truy cập vào nô lệ. Thiết lập này rất linh hoạt - trước tiên, bạn có một máy chủ MySQL đang chạy cùng với dữ liệu sản xuất của mình, vì vậy sẽ không quá khó để triển khai ứng dụng đầy đủ của bạn trong trang DR. Bạn cũng sẽ có các bản sao lưu dữ liệu sản xuất mà bạn có thể sử dụng để mở rộng môi trường DR của mình.
Cuối cùng và quan trọng nhất, một bản sao lưu chưa được kiểm tra vẫn là một bản sao lưu chưa được xác minh, hay còn gọi là Schroedinger Backup. Để đảm bảo bạn có một bản sao lưu đang hoạt động, bạn cần thực hiện kiểm tra khôi phục. ClusterControl cung cấp một cách để tự động xác minh và kiểm tra bản sao lưu của bạn.
Chúng tôi hy vọng điều này cung cấp cho bạn đủ thông tin để xây dựng quy trình sao lưu an toàn và đáng tin cậy cho cơ sở dữ liệu nguồn mở của bạn.



