ClusterControl được lập trình với một số thuật toán khôi phục để tự động phản hồi các loại lỗi phổ biến khác nhau ảnh hưởng đến hệ thống cơ sở dữ liệu của bạn. Nó hiểu các loại cấu trúc liên kết cơ sở dữ liệu khác nhau và quản lý quy trình liên quan đến cơ sở dữ liệu để giúp bạn xác định cách tốt nhất để khôi phục cụm. Theo một cách nào đó, ClusterControl cải thiện tính khả dụng của cơ sở dữ liệu của bạn.
Một số trình quản lý cấu trúc liên kết chỉ đề cập đến khôi phục cụm như MHA, Orchestrator và mysqlfailover nhưng bạn phải tự xử lý việc khôi phục nút. ClusterControl hỗ trợ khôi phục ở cả cấp độ cụm và nút.
Tùy chọn cấu hình
Có hai thành phần khôi phục được hỗ trợ bởi ClusterControl, đó là:
- Cụm - Cố gắng khôi phục một cụm về trạng thái hoạt động
- Nút - Cố gắng khôi phục một nút về trạng thái hoạt động
Hai thành phần này là những điều quan trọng nhất để đảm bảo tính khả dụng của dịch vụ càng cao càng tốt. Nếu bạn đã có trình quản lý cấu trúc liên kết trên ClusterControl, bạn có thể tắt tính năng khôi phục tự động và để trình quản lý cấu trúc liên kết khác xử lý giúp bạn. Bạn có tất cả các khả năng với ClusterControl.
Tính năng khôi phục tự động có thể được bật và tắt bằng cách BẬT / TẮT chuyển đổi đơn giản và nó hoạt động để khôi phục cụm hoặc nút. Các biểu tượng màu xanh lá cây có nghĩa là đã bật và các biểu tượng màu đỏ có nghĩa là đã bị vô hiệu hóa. Ảnh chụp màn hình sau cho thấy nơi bạn có thể tìm thấy nó trong danh sách cụm cơ sở dữ liệu:
Có 3 tham số ClusterControl có thể được sử dụng để kiểm soát hành vi khôi phục. Tất cả các tham số được mặc định thành true (được đặt bằng số nguyên boolean 0 hoặc 1):
- enable_autorecovery - Bật khôi phục cụm và nút. Tham số này là tập siêu của enable_cluster_recovery và enable_node_recovery. Nếu nó được đặt thành 0, các thông số của tập hợp con sẽ bị tắt.
- enable_cluster_recovery - ClusterControl sẽ thực hiện khôi phục cụm nếu được bật.
- enable_node_recovery - ClusterControl sẽ thực hiện khôi phục nút nếu được bật.
Khôi phục cụm bao gồm nỗ lực khôi phục để đưa ra cấu trúc liên kết toàn bộ cụm. Ví dụ:một bản sao master-slave phải có ít nhất một master còn sống tại bất kỳ thời điểm nào, bất kể số lượng nô lệ hiện có là bao nhiêu. ClusterControl cố gắng sửa cấu trúc liên kết ít nhất một lần cho các cụm sao chép, nhưng vô hạn đối với sao chép đa tổng thể như NDB Cluster và Galera Cluster.
Khôi phục nút bao gồm vấn đề khôi phục nút như nếu một nút đang bị dừng mà không có kiến thức về ClusterControl, ví dụ:thông qua lệnh dừng hệ thống từ bảng điều khiển SSH hoặc bị quá trình OOM giết.
Khôi phục nút
ClusterControl có thể khôi phục một nút cơ sở dữ liệu trong trường hợp lỗi không liên tục bằng cách theo dõi quá trình và kết nối với các nút cơ sở dữ liệu. Đối với quá trình này, nó hoạt động tương tự như systemd, nơi nó sẽ đảm bảo dịch vụ MySQL được khởi động và chạy trừ khi bạn cố ý dừng nó thông qua ClusterControl UI.
Nếu nút trực tuyến trở lại, ClusterControl sẽ thiết lập kết nối trở lại nút cơ sở dữ liệu và sẽ thực hiện các hành động cần thiết. Sau đây là những gì ClusterControl sẽ làm để khôi phục một nút:
- Nó sẽ đợi systemd / chkconfig / init khởi động các dịch vụ / quy trình được giám sát trong 30 giây
- Nếu các dịch vụ / quy trình được giám sát vẫn không hoạt động, ClusterControl sẽ cố gắng khởi động dịch vụ cơ sở dữ liệu tự động.
- Nếu ClusterControl không thể khôi phục các dịch vụ / quy trình được giám sát, một cảnh báo sẽ được đưa ra.
Lưu ý rằng nếu người dùng bắt đầu tắt cơ sở dữ liệu, ClusterControl sẽ không tìm cách khôi phục nút cụ thể. Nó yêu cầu người dùng khởi động lại thông qua ClusterControl UI bằng cách đi tới Node -> Node Actions -> Start Node hoặc sử dụng lệnh OS một cách rõ ràng.
Việc khôi phục bao gồm tất cả các dịch vụ liên quan đến cơ sở dữ liệu như ProxySQL, HAProxy, MaxScale, Keepalived, Prometheus exporters và garbd. Đặc biệt chú ý đến các nhà xuất khẩu Prometheus nơi ClusterControl sử dụng một chương trình có tên "daemon" để daemonize hóa quy trình xuất khẩu. ClusterControl sẽ cố gắng kết nối với cổng lắng nghe của nhà xuất khẩu để kiểm tra và xác minh tình trạng. Do đó, bạn nên mở các cổng xuất từ máy chủ ClusterControl và Prometheus để đảm bảo không có báo động giả trong quá trình khôi phục.
Khôi phục cụm
ClusterControl hiểu cấu trúc liên kết cơ sở dữ liệu và tuân theo các phương pháp hay nhất để thực hiện khôi phục. Đối với một cụm cơ sở dữ liệu đi kèm với khả năng chịu lỗi tích hợp như Galera Cluster, NDB Cluster và MongoDB Replicaset, quá trình chuyển đổi dự phòng sẽ được máy chủ cơ sở dữ liệu thực hiện tự động thông qua tính toán đại số, nhịp tim và chuyển đổi vai trò (nếu có). ClusterControl giám sát quá trình và thực hiện các điều chỉnh cần thiết đối với hình ảnh trực quan như phản ánh những thay đổi trong chế độ xem Topo và điều chỉnh thành phần quản lý và giám sát cho vai trò mới, ví dụ:nút chính mới trong một tập hợp bản sao.
Đối với các công nghệ cơ sở dữ liệu không có khả năng chịu lỗi tích hợp với khả năng phục hồi tự động như MySQL / MariaDB Replication và PostgreSQL / TimescaleDB Streaming Replication, ClusterControl sẽ thực hiện các quy trình khôi phục bằng cách làm theo các phương pháp hay nhất được cung cấp bởi nhà cung cấp cơ sở dữ liệu. Nếu quá trình khôi phục không thành công, cần phải có sự can thiệp của người dùng và tất nhiên bạn sẽ nhận được thông báo cảnh báo về việc này.
Trong cấu trúc liên kết hỗn hợp / kết hợp, chẳng hạn như một nô lệ không đồng bộ được gắn vào Cụm Galera hoặc Cụm NDB, nút sẽ được khôi phục bằng ClusterControl nếu tính năng khôi phục cụm được bật.
Khôi phục cụm không áp dụng cho máy chủ MySQL độc lập. Tuy nhiên, bạn nên bật tính năng khôi phục cả nút và cụm cho loại cụm này trong giao diện người dùng ClusterControl.
Bản sao MySQL / MariaDB
ClusterControl hỗ trợ khôi phục thiết lập sao chép MySQL / MariaDB sau:
- Master-slave với MySQL GTID
- Master-slave với MariaDB GTID
- Master-slave không có GTID (cả MySQL và MariaDB)
- Master-master với MySQL GTID
- Master-master với MariaDB GTID
- Nô lệ không đồng bộ được đính kèm vào Cụm Galera
ClusterControl sẽ tôn trọng các tham số sau khi thực hiện khôi phục cụm:
- enable_cluster_autorecovery
- auto_manage_readonly
- repl_password
- repl_user
- replication_auto_rebuild_slave
- replication_check_binlog_filtration_bf_failover
- replication_check_external_bf_failover
- replication_failed_reslave_failover_script
- replication_failover_blacklist
- replication_failover_events
- replication_failover_wait_to_apply_timeout
- replication_failover_whitelist
- replication_onfail_failover_script
- replication_post_failover_script
- replication_post_switchover_script
- replication_post_unsuccessful_failover_script
- replication_pre_failover_script
- replication_pre_switchover_script
- replication_skip_apply_missing_txs
- replication_stop_on_error
Để biết thêm chi tiết về từng tham số, hãy tham khảo trang tài liệu.
ClusterControl sẽ tuân theo các quy tắc sau khi giám sát và quản lý bản sao chủ-tớ:
- Tất cả các nút sẽ được bắt đầu với read_only =ON và super_read_only =ON (bất kể vai trò của nó là gì).
- Chỉ một bản gốc (read_only =OFF) được phép hoạt động tại bất kỳ thời điểm nào.
- Dựa vào biến report_host của MySQL để ánh xạ cấu trúc liên kết.
- Nếu có hai hoặc nhiều nút read_only =OFF tại một thời điểm, ClusterControl sẽ tự động đặt read_only =ON trên cả hai nút chính, để bảo vệ chúng khỏi việc ghi ngẫu nhiên. Cần có sự can thiệp của người dùng để chọn bản chính thực sự bằng cách tắt chế độ chỉ đọc. Đi tới Nodes -> Node Actions -> Disable Readonly.
Trong trường hợp chương trình chính hoạt động không hoạt động, ClusterControl sẽ cố gắng thực hiện chuyển đổi dự phòng chính theo thứ tự sau:
- Sau 3 giây không thể truy cập chính, ClusterControl sẽ báo động.
- Kiểm tra tính khả dụng của nô lệ, ít nhất một trong các nô lệ phải có thể truy cập được bằng ClusterControl.
- Chọn nô lệ làm ứng cử viên để trở thành chủ nhân.
- ClusterControl sẽ tính toán xác suất giao dịch sai nếu GTID được bật.
- Nếu không phát hiện thấy giao dịch sai sót nào, giao dịch đã chọn sẽ được thăng cấp là giao dịch chính mới.
- Tạo và cấp phép người dùng nhân bản để nô lệ sử dụng.
- Thay đổi chủ cho tất cả các nô lệ đã trỏ đến chủ cũ thành chủ mới được thăng cấp.
- Khởi động chế độ nô lệ và bật chế độ chỉ đọc.
- Xóa nhật ký trên tất cả các nút.
- Nếu quá trình xúc tiến nô lệ không thành công, ClusterControl sẽ hủy bỏ công việc khôi phục. Cần có sự can thiệp của người dùng hoặc khởi động lại dịch vụ cmon để kích hoạt lại công việc khôi phục.
- Khi bản gốc cũ khả dụng trở lại, bản gốc sẽ được bắt đầu ở chế độ chỉ đọc và sẽ không phải là một phần của bản sao. Cần có sự can thiệp của người dùng.
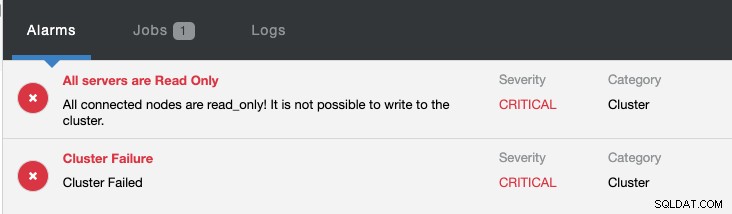
Đồng thời, các cảnh báo sau sẽ được nâng lên:
Hãy xem Giới thiệu về chuyển đổi dự phòng cho MySQL Replication - Blog 101 và Chuyển đổi dự phòng tự động của MySQL Replication - Mới trong ClusterControl 1.4 để biết thêm thông tin về cách cấu hình và quản lý chuyển đổi dự phòng sao chép MySQL với ClusterControl.
PostgreSQL / TimescaleDB sao chép truyền trực tuyến
ClusterControl hỗ trợ khôi phục thiết lập sao chép PostgreSQL sau:
- PostgreSQL Streaming Replication
- Nhân rộng phát trực tuyến TimescaleDB
ClusterControl sẽ tôn trọng các tham số sau khi thực hiện khôi phục cụm:
- enable_cluster_autorecovery
- repl_password
- repl_user
- replication_auto_rebuild_slave
- replication_failover_whitelist
- replication_failover_blacklist
Để biết thêm chi tiết về từng tham số, hãy tham khảo trang tài liệu.
ClusterControl sẽ tuân theo các quy tắc sau để quản lý và giám sát thiết lập sao chép luồng PostgreSQL:
- wal_level được đặt thành "bản sao" (hoặc "hot_standby" tùy thuộc vào phiên bản PostgreSQL).
- Chế độ lưu trữ biến được đặt thành BẬT trên trang cái.
- Đặt tệp recovery.conf trên các nút phụ, biến nút này thành chế độ chờ nóng khi bật chế độ chỉ đọc.
Trong trường hợp bản cái đang hoạt động bị hỏng, ClusterControl sẽ cố gắng thực hiện khôi phục cụm theo thứ tự sau:
- Sau 10 giây không thể truy cập chính, ClusterControl sẽ báo động.
- Sau 10 giây hết thời gian chờ duyên dáng, ClusterControl sẽ bắt đầu công việc chuyển đổi dự phòng chính.
- Lấy mẫu replayLocation và acceptLocation trên tất cả các nút có sẵn để xác định nút nâng cao nhất.
- Quảng cáo nút nâng cao nhất làm nút chính mới.
- Dừng nô lệ.
- Xác minh trạng thái đồng bộ hóa với pg_rewind.
- Khởi động lại nô lệ với chủ mới.
- Nếu quá trình xúc tiến nô lệ không thành công, ClusterControl sẽ hủy bỏ công việc khôi phục. Cần có sự can thiệp của người dùng hoặc khởi động lại dịch vụ cmon để kích hoạt lại công việc khôi phục.
- Khi bản gốc cũ khả dụng trở lại, nó sẽ bị buộc phải đóng cửa và sẽ không tham gia vào quá trình nhân rộng. Cần phải có sự can thiệp của người dùng. Xem thêm ở phía dưới.
Khi máy chủ cũ trực tuyến trở lại, nếu dịch vụ PostgreSQL đang chạy, ClusterControl sẽ buộc tắt dịch vụ PostgreSQL. Điều này là để bảo vệ máy chủ khỏi việc ghi ngẫu nhiên, vì nó sẽ được khởi động mà không có tệp khôi phục (recovery.conf), có nghĩa là nó sẽ có thể ghi được. Bạn sẽ mong đợi những dòng sau sẽ xuất hiện trong postgresql- {day} .log:
2019-11-27 05:06:10.091 UTC [2392] LOG: database system is ready to accept connections
2019-11-27 05:06:27.696 UTC [2392] LOG: received fast shutdown request
2019-11-27 05:06:27.700 UTC [2392] LOG: aborting any active transactions
2019-11-27 05:06:27.703 UTC [2766] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.704 UTC [2758] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.709 UTC [2392] LOG: background worker "logical replication launcher" (PID 2419) exited with exit code 1
2019-11-27 05:06:27.709 UTC [2414] LOG: shutting down
2019-11-27 05:06:27.735 UTC [2392] LOG: database system is shut downPostgreSQL được khởi động sau khi máy chủ trực tuyến trở lại vào khoảng 05:06:10 nhưng ClusterControl thực hiện tắt nhanh 17 giây sau đó vào khoảng 05:06:27. Nếu đây là điều bạn không muốn, bạn có thể tắt khôi phục nút cho cụm này trong giây lát.
Xem Tự động chuyển đổi dự phòng cho Postgres Replication và chuyển đổi dự phòng cho PostgreSQL Replication 101 để biết thêm thông tin về cách định cấu hình và quản lý chuyển đổi dự phòng sao chép PostgreSQL với ClusterControl.
Kết luận
Khôi phục tự động ClusterControl hiểu cấu trúc liên kết cụm cơ sở dữ liệu và có thể khôi phục một cụm bị hỏng hoặc xuống cấp thành một cụm hoạt động đầy đủ, điều này sẽ cải thiện rất nhiều thời gian hoạt động của dịch vụ cơ sở dữ liệu. Hãy thử ClusterControl ngay bây giờ và đạt được số chín của bạn trong SLA và tính khả dụng của cơ sở dữ liệu. Không biết số chín của bạn? Kiểm tra máy tính số chín thú vị này.



