Đảm bảo hoạt động trơn tru của cơ sở dữ liệu sản xuất của bạn không phải là một nhiệm vụ tầm thường và có một số công cụ và tiện ích để trợ giúp công việc này. Có sẵn các công cụ để theo dõi sức khỏe, hiệu suất máy chủ, phân tích truy vấn, triển khai, quản lý chuyển đổi dự phòng, nâng cấp và danh sách tiếp tục. ClusterControl như một nền tảng quản lý và giám sát cho cơ sở hạ tầng cơ sở dữ liệu của bạn, nổi bật với khả năng quản lý toàn bộ vòng đời từ triển khai đến giám sát, quản lý liên tục và mở rộng.
Mặc dù ClusterControl cung cấp các tính năng quan trọng như chuyển đổi dự phòng cơ sở dữ liệu tự động, mã hóa khi đang chuyển / lúc nghỉ, quản lý sao lưu, khôi phục tại thời điểm, tích hợp Prometheus, mở rộng cơ sở dữ liệu, những tính năng này có thể được tìm thấy trong các công cụ giám sát / quản lý doanh nghiệp khác trên thị trường. Tuy nhiên, có một số tính năng mà bạn sẽ không dễ dàng tìm thấy. Trong bài đăng blog này, chúng tôi sẽ trình bày 9 tính năng mà bạn sẽ không tìm thấy trong bất kỳ công cụ quản lý và giám sát nào khác trên thị trường (tính đến thời điểm viết bài này).
Xác minh sao lưu
Mọi bản sao lưu thực sự không phải là bản sao lưu cho đến khi bạn biết rằng nó có thể được khôi phục - bằng cách thực sự xác minh rằng nó có thể được khôi phục. ClusterControl cho phép xác minh bản sao lưu sau khi bản sao lưu đã được thực hiện bằng cách quay một máy chủ mới và thử nghiệm khôi phục. Xác minh bản sao lưu là một quá trình quan trọng để đảm bảo bạn đáp ứng chính sách Mục tiêu điểm khôi phục (RPO) của mình trong trường hợp khôi phục sau thảm họa. Quá trình xác minh sẽ thực hiện khôi phục trên máy chủ độc lập mới (nơi ClusterControl sẽ cài đặt các gói cơ sở dữ liệu cần thiết trước khi khôi phục) hoặc trên máy chủ dành riêng cho xác minh sao lưu.
Để định cấu hình xác minh sao lưu, chỉ cần chọn một bản sao lưu hiện có và nhấp vào Khôi phục. Sẽ có một tùy chọn để Khôi phục và Xác minh:
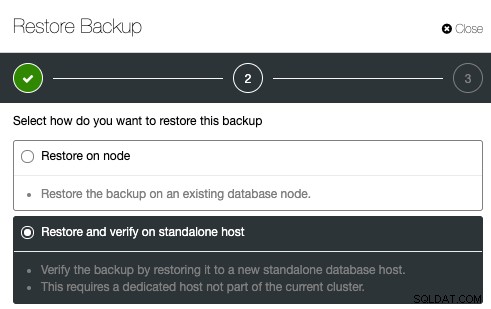
Sau đó, chỉ cần chỉ định địa chỉ IP của máy chủ mà bạn muốn khôi phục và xác minh:
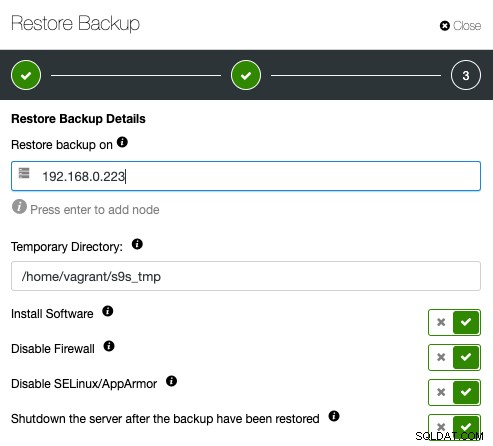
Đảm bảo trước đó máy chủ được chỉ định có thể truy cập thông qua SSH không cần mật khẩu. Bạn cũng có một số tùy chọn bên dưới cho quá trình cấp phép. Bạn cũng có thể tắt máy chủ xác minh sau khi khôi phục để tiết kiệm chi phí và tài nguyên sau khi bản sao lưu đã được xác minh. ClusterControl sẽ tìm mã thoát của quá trình khôi phục và quan sát nhật ký khôi phục để kiểm tra xem việc xác minh có thất bại hay thành công hay không.
Đơn giản hóa việc quản lý ProxySQL thông qua GUI
Nhiều người sẽ đồng ý rằng có giao diện người dùng đồ họa sẽ hiệu quả hơn và ít bị lỗi do con người hơn khi cấu hình hệ thống. ProxySQL là một phần của lớp cơ sở dữ liệu quan trọng (mặc dù nó nằm trên cùng) và phải đủ hiển thị cho mắt của DBA để phát hiện ra các vấn đề và sự cố thường gặp. ClusterControl cung cấp giao diện người dùng đồ họa toàn diện cho ProxySQL.
Các phiên bản ProxySQL có thể được triển khai trên các máy chủ mới hoặc các máy chủ hiện có có thể được nhập vào ClusterControl. ClusterControl có thể cấu hình ProxySQL được tích hợp với một địa chỉ IP ảo (do Keepalived cung cấp) để truy cập điểm cuối duy nhất vào các máy chủ cơ sở dữ liệu. Nó cũng cung cấp thông tin chi tiết về giám sát đối với các thành phần ProxySQL chính như Truy vấn phụ trợ, Truy vấn chậm, Truy vấn hàng đầu, Lượt truy vấn và một loạt các thống kê giám sát khác. Sau đây là ảnh chụp màn hình hiển thị cách thêm quy tắc truy vấn mới:
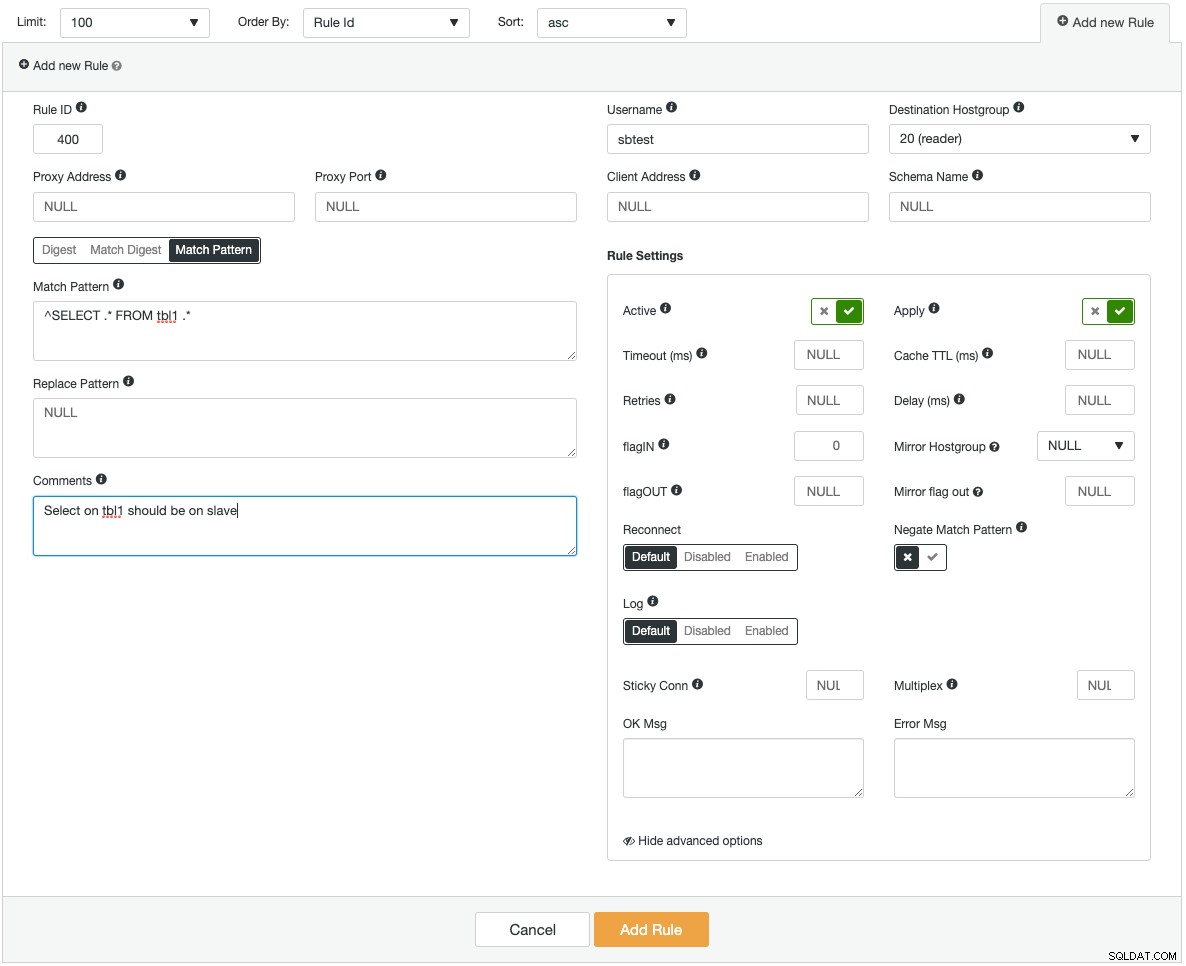
Nếu bạn đang thêm một quy tắc truy vấn rất phức tạp, bạn sẽ thấy thoải mái hơn khi thực hiện nó thông qua giao diện người dùng đồ họa. Mỗi trường đều có chú giải công cụ để hỗ trợ bạn khi điền vào biểu mẫu Quy tắc truy vấn. Khi thêm hoặc sửa đổi bất kỳ cấu hình ProxySQL nào, ClusterControl sẽ đảm bảo các thay đổi được thực hiện trong thời gian chạy và được lưu vào đĩa để duy trì lâu dài.
ClusterControl 1.7.4 hiện hỗ trợ cả ProxySQL 1.x và ProxySQL 2.x.
Báo cáo Hoạt động
Báo cáo Hoạt động là một tập hợp các báo cáo tóm tắt về cơ sở hạ tầng cơ sở dữ liệu của bạn có thể được tạo ngay lập tức hoặc có thể được lên lịch để gửi cho những người nhận khác nhau. Các báo cáo này bao gồm các kiểm tra khác nhau và giải quyết các nhiệm vụ DBA hàng ngày khác nhau. Ý tưởng đằng sau báo cáo hoạt động của ClusterControl là đưa tất cả dữ liệu có liên quan nhất vào một tài liệu duy nhất có thể được phân tích nhanh chóng để hiểu rõ về trạng thái của cơ sở dữ liệu và các quy trình của nó.
Với ClusterControl, bạn có thể lập lịch báo cáo môi trường liên cụm như Báo cáo hệ thống hàng ngày, Báo cáo nâng cấp gói, Báo cáo thay đổi lược đồ cũng như Bản sao lưu và tính khả dụng. Các báo cáo này sẽ giúp bạn giữ cho môi trường của bạn an toàn và hoạt động. Bạn cũng sẽ thấy các khuyến nghị về cách sửa các khoảng trống. Báo cáo có thể được gửi tới SysOps, DevOps hoặc thậm chí là những người quản lý muốn nhận thông tin cập nhật trạng thái thường xuyên về tình trạng của một hệ thống nhất định.
Sau đây là một mẫu báo cáo hoạt động hàng ngày được gửi đến hộp thư của bạn liên quan đến tính khả dụng:
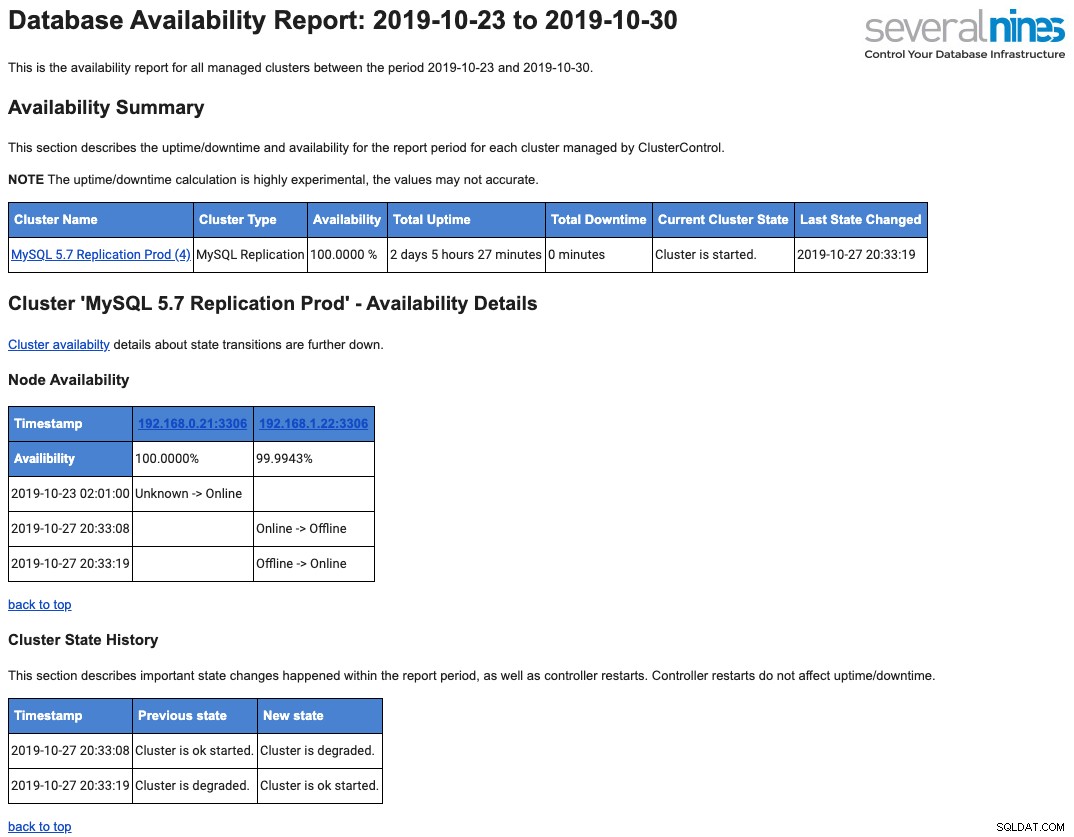
Chúng tôi đã trình bày chi tiết vấn đề này trong bài đăng blog này, Tổng quan về Báo cáo Hoạt động Cơ sở dữ liệu trong ClusterControl.
Đồng bộ hóa lại một Slave qua Sao lưu
ClusterControl cho phép tổ chức một nô lệ (cho dù một nô lệ mới hay một nô lệ bị hỏng) thông qua bản sao lưu đầy đủ hoặc tăng dần mới nhất. Nghe có vẻ không thú vị lắm, nhưng tính năng này rất lớn nếu bạn có bộ dữ liệu lớn từ 100GB trở lên. Thực hành phổ biến khi đồng bộ lại máy chủ phụ là truyền một bản sao lưu của máy chủ hiện tại, việc này sẽ mất một khoảng thời gian tùy thuộc vào kích thước cơ sở dữ liệu. Điều này sẽ tạo thêm gánh nặng cho bản chính, có thể gây nguy hiểm cho hiệu suất của bản chính.
Để đồng bộ lại nô lệ thông qua bản sao lưu, hãy chọn nút nô lệ trong trang Node và đi tới Node Actions -> Rebuild Replication Slave -> Rebuild from backup. Chỉ sao lưu tương thích với PITR mới được liệt kê trong menu thả xuống:
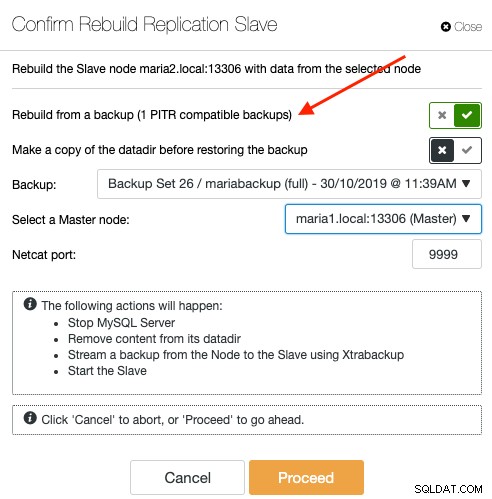
Đồng bộ lại nô lệ từ bản sao lưu sẽ không mang lại bất kỳ chi phí bổ sung nào cho máy chủ, trong đó ClusterControl trích xuất và truyền trực tuyến sao lưu từ vị trí lưu trữ dự phòng vào máy chủ và cuối cùng định cấu hình liên kết sao chép giữa máy chủ với máy chủ. Sau này, nô lệ sẽ bắt kịp với chủ khi liên kết nhân rộng được thiết lập. Bản gốc không bị ảnh hưởng trong toàn bộ quá trình và bạn có thể theo dõi toàn bộ tiến trình trong Hoạt động -> Công việc.
Khởi động Cụm Galera
Galera Cluster rất phổ biến khi triển khai tính khả dụng cao cho MySQL hoặc MariaDB, nhưng các lệnh quản lý sai có thể dẫn đến hậu quả tai hại. Hãy xem bài đăng trên blog này về cách khởi động Cụm Galera trong các điều kiện khác nhau. Điều này minh họa rằng việc khởi động một Cụm Galera có nhiều biến và phải được thực hiện hết sức cẩn thận. Nếu không, bạn có thể mất dữ liệu hoặc gây ra hiện tượng phân chia não bộ. ClusterControl hiểu cấu trúc liên kết cơ sở dữ liệu và biết chính xác những gì cần làm để khởi động cụm cơ sở dữ liệu đúng cách. Để khởi động một cụm thông qua ClusterControl, hãy nhấp vào Hành động cụm -> Cụm khởi động:
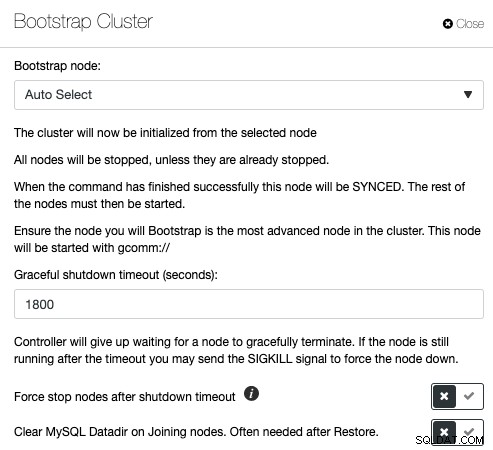
Bạn sẽ có tùy chọn để ClusterControl tự động chọn nút bootstrap bên phải hoặc thực hiện khởi động ban đầu trong đó bạn chọn một trong các nút cơ sở dữ liệu từ danh sách để trở thành nút tham chiếu và xóa sạch MySQL datadir trên các nút nối để buộc SST khỏi nút khởi động. Nếu quá trình khởi động không thành công, ClusterControl sẽ kéo nhật ký lỗi MySQL.
Nếu bạn muốn thực hiện bootstrap thủ công, bạn cũng có thể sử dụng tính năng "Find Most Advanced Node" và thực hiện hoạt động cluster bootstrap trên nút nâng cao nhất do ClusterControl báo cáo.
Cấu hình tập trung và ghi nhật ký
ClusterControl kéo một số tệp ghi nhật ký và cấu hình quan trọng và hiển thị chúng trong cấu trúc cây trong ClusterControl. Chế độ xem tập trung của các tệp này là chìa khóa để hiểu và khắc phục sự cố thiết lập cơ sở dữ liệu phân tán một cách hiệu quả. Cách truyền thống để gắn thẻ / gắn các tệp này đã không còn tồn tại với ClusterControl. Ảnh chụp màn hình sau cho thấy trình quản lý tệp cấu hình của ClusterControl liệt kê tất cả các tệp cấu hình liên quan cho cụm này trong một chế độ xem duy nhất (tất nhiên là có đánh dấu cú pháp):
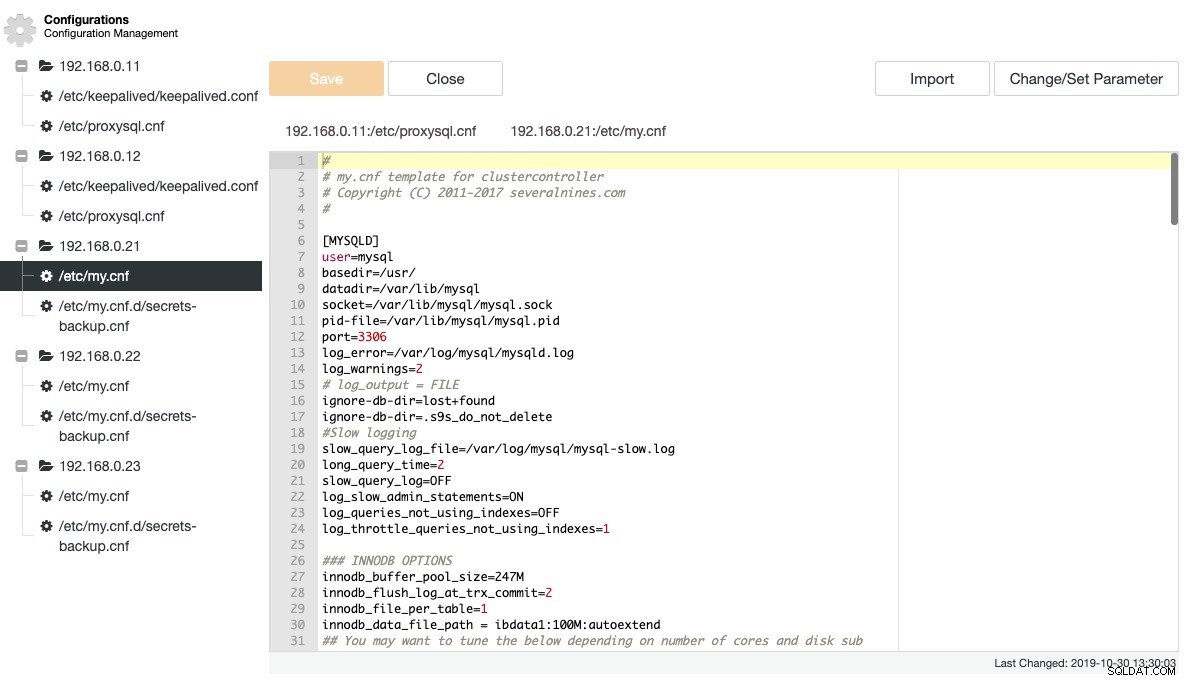
ClusterControl loại bỏ sự lặp lại khi thay đổi tùy chọn cấu hình của một cụm cơ sở dữ liệu. Thay đổi tùy chọn cấu hình trên nhiều nút có thể được thực hiện thông qua một giao diện duy nhất và sẽ được áp dụng cho nút cơ sở dữ liệu tương ứng. Khi bạn nhấp vào "Thay đổi / Đặt tham số", bạn có thể chọn các trường hợp cơ sở dữ liệu mà bạn muốn thay đổi và chỉ định nhóm cấu hình, tham số và giá trị:
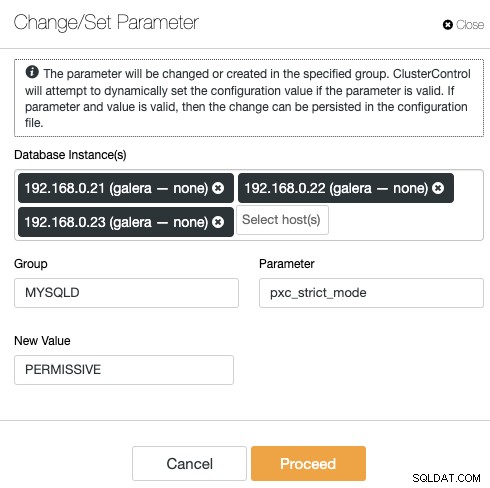
Bạn có thể thêm một tham số mới vào tệp cấu hình hoặc sửa đổi một tham số hiện có . Tham số sẽ được áp dụng cho thời gian chạy của các nút cơ sở dữ liệu đã chọn và vào tệp cấu hình nếu tùy chọn vượt qua quá trình xác nhận biến. Một số biến có thể yêu cầu khởi động lại máy chủ, điều này sau đó sẽ được ClusterControl thông báo.
Sao chép Cụm Cơ sở dữ liệu
Với ClusterControl, bạn có thể nhanh chóng sao chép MySQL Galera Cluster hiện có để bạn có một bản sao chính xác của tập dữ liệu trên cụm khác. ClusterControl thực hiện thao tác nhân bản trực tuyến mà không có bất kỳ khóa hoặc mang lại thời gian chết cho cụm hiện có. Nó giống như một hoạt động mở rộng quy mô cụm ngoại trừ cả hai cụm đều độc lập với nhau sau khi quá trình đồng bộ hóa hoàn tất. Cụm sao chép không nhất thiết phải có cùng kích thước cụm với cụm hiện có. Chúng tôi có thể bắt đầu với “cụm một nút” và mở rộng quy mô với nhiều nút cơ sở dữ liệu hơn ở giai đoạn sau.
Một tính năng tương tự khác được cung cấp bởi ClusterControl là "Tạo cụm từ sao lưu". Tính năng này đã được giới thiệu trong ClusterControl 1.7.1, đặc biệt cho các cụm Galera Cluster và PostgreSQL nơi người ta có thể tạo một cụm mới từ bản sao lưu hiện có. Trái ngược với sao chép cụm, hoạt động này không mang lại tải bổ sung cho cụm nguồn với sự cân bằng rằng cụm được sao chép sẽ không ở cùng trạng thái với cụm nguồn.
Chúng tôi đã trình bày chi tiết về chủ đề này trong bài đăng blog này, Cách tạo một bản sao của Cụm cơ sở dữ liệu MySQL hoặc PostgreSQL của bạn.
Khôi phục Bản sao lưu vật lý
Hầu hết các công cụ quản lý cơ sở dữ liệu đều cho phép sao lưu cơ sở dữ liệu và chỉ một số ít trong số chúng hỗ trợ khôi phục cơ sở dữ liệu chỉ sao lưu logic. ClusterControl hỗ trợ khôi phục toàn bộ không chỉ cho các bản sao lưu lôgic mà còn cả các bản sao lưu vật lý, cho dù đó là bản sao lưu đầy đủ hay tăng dần. Khôi phục bản sao lưu vật lý yêu cầu một số bước quan trọng (đặc biệt là sao lưu gia tăng), về cơ bản bao gồm việc chuẩn bị sao lưu, sao chép dữ liệu đã chuẩn bị vào thư mục dữ liệu, gán quyền / quyền sở hữu chính xác và khởi động nút theo đúng thứ tự để duy trì tính nhất quán của dữ liệu trên tất cả các thành viên trong cụm. ClusterControl thực hiện tất cả các hoạt động này một cách tự động.
Bạn cũng có thể khôi phục một bản sao lưu vật lý vào một nút khác không phải là một phần của cụm. Trong ClusterControl, tùy chọn cho điều này được gọi là "Tạo cụm từ sao lưu". Bạn có thể bắt đầu với “cụm một nút” để kiểm tra quá trình khôi phục trên một máy chủ khác hoặc để sao chép cụm cơ sở dữ liệu của bạn sang một vị trí khác.
ClusterControl cũng hỗ trợ khôi phục một bản sao lưu bên ngoài, một bản sao lưu đã được thực hiện không thông qua ClusterControl. Bạn chỉ cần tải bản sao lưu lên máy chủ ClusterControl và chỉ định đường dẫn vật lý đến tệp sao lưu khi khôi phục. ClusterControl sẽ lo phần còn lại.
Sao chép theo cụm
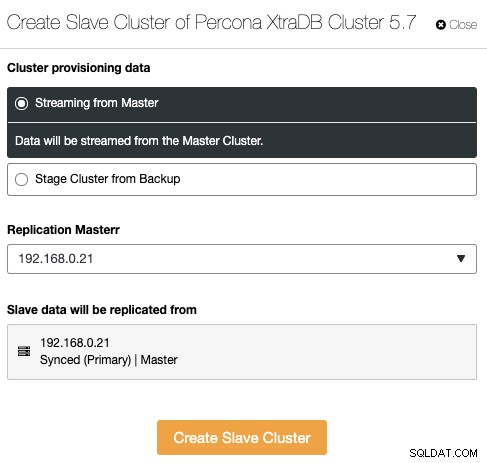
Đây là một tính năng mới được giới thiệu trong ClusterControl 1.7.4. ClusterControl hiện có thể xử lý và giám sát sao chép cụm-cụm, về cơ bản mở rộng việc sao chép cơ sở dữ liệu không đồng bộ giữa nhiều nhóm cụm ở nhiều vị trí địa lý. Một cụm có thể được đặt làm cụm chính (cụm hoạt động xử lý đọc / ghi) và cụm phụ có thể được đặt làm cụm chỉ đọc (cụm chờ cũng có thể xử lý đọc). ClusterControl hỗ trợ sao chép cụm-cụm không đồng bộ cho Galera Cluster (nhật ký nhị phân phải được bật) và cũng sao chép master-slave cho PostgreSQL Streaming Replication.
Để tạo một cụm mới, các bản sao từ một cụm khác, hãy đi tới Tác vụ cụm -> Tạo cụm nô lệ:
Kết quả của việc triển khai ở trên được trình bày rõ ràng trên trang tổng quan Danh sách cụm cơ sở dữ liệu :
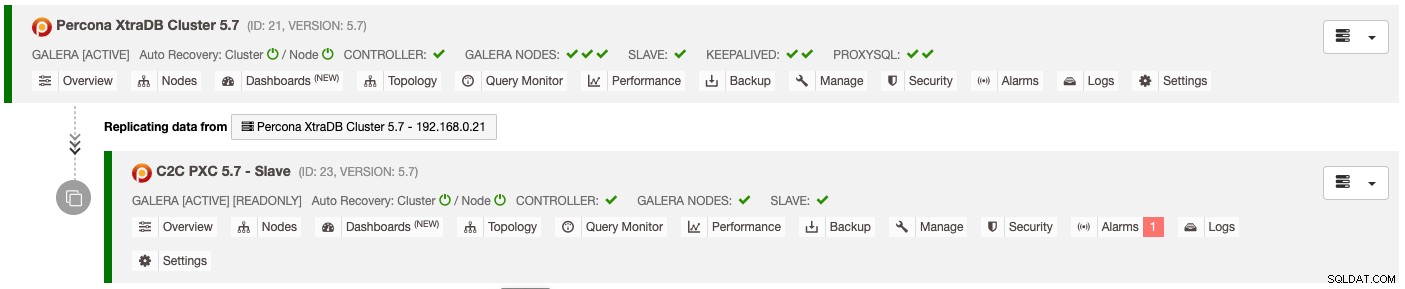
Cụm phụ được tự động định cấu hình ở dạng chỉ đọc, sao chép từ cụm chính và hoạt động như một cụm dự phòng. Nếu thảm họa xảy ra với cụm chính và bạn muốn kích hoạt trang web phụ, chỉ cần chọn trình đơn "Tắt chỉ đọc" có sẵn trong trình đơn thả xuống Nodes -> Node Actions để quảng bá nó như một cụm đang hoạt động.



