Vì bạn đang sử dụng lò xo. Bạn có thể sử dụng MultipartFile để lấy tệp trong bộ điều khiển của bạn và sau đó sử dụng Binary trong tổng số org.bson để lưu trữ tệp vào MongoDB, Nếu kích thước hình ảnh của bạn <16MB (nếu kích thước hình ảnh> 16 MB, bạn có thể sử dụng GridFs
).
Bạn chỉ cần thêm một phần phụ thuộc vào dự án của mình - spring-data-mongoDB
Hãy lấy một ví dụ về tập hợp Người dùng trông giống như sau:
@Document
public class User {
@Id
private String id;
private String name;
private Binary image;
// getters and setters
}
Tại đây, bạn có thể thấy Binary image đại diện cho tệp hình ảnh của bạn.
Bây giờ, hãy tạo một kho lưu trữ cho bộ sưu tập Người dùng này bằng cách sử dụng MongoRepository
public interface UserRepository extends MongoRepository<User, String>{
}
Tạo Bộ điều khiển cho mục đích demo. Sử dụng tệp @RequestParam MultipartFile file để tải tệp vào bộ điều khiển của bạn, lấy byte từ tệp và đặt nó thành đối tượng người dùng user.setImage(new Binary(file.getBytes())); đầy đủ ví dụ dưới đây:
@RestController
public class UserController {
@Autowired
private UserRepository userRepository;
@PostMapping("/users")
User createUser(@RequestParam String name, @RequestParam MultipartFile file) throws IOException {
User user = new User();
user.setName(name);
user.setImage(new Binary(file.getBytes()));
return userRepository.save(user);
}
@GetMapping("/users")
String getImage(@RequestParam String id) {
Optional<User> user = userRepository.findById(id);
Encoder encoder = Base64.getEncoder();
return encoder.encodeToString(user.get().getImage().getData());
}
}
Khởi động máy chủ và đến điểm cuối như được hiển thị trong ảnh chụp màn hình người đưa thư bên dưới
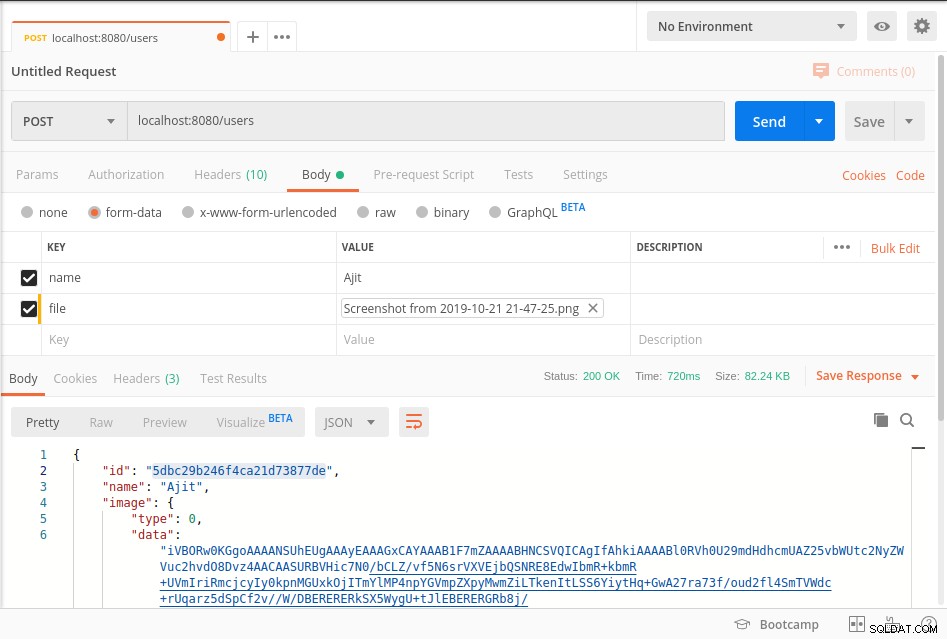
Dữ liệu của bạn được lưu trữ trong mongoDb trong BinData định dạng và để lấy dữ liệu từ cơ sở dữ liệu, vui lòng tham khảo getImage phương pháp của mã trên.
CHỈNH SỬA:
Người đặt câu hỏi đang sử dụng tess4j thư viện để trích xuất văn bản từ hình ảnh và doOCR là một phương thức trong thư viện này. Tôi đã làm theo các bước sau để trích xuất văn bản từ hình ảnh trong ứng dụng khởi động mùa xuân của mình.
-
Cài đặt
tesseract-ocrvào hệ thống của bạn:sudo apt-get install tesseract-ocr -
Tải xuống
eng.traineddatadữ liệu đào tạo từ https://github.com/tesseract-ocr/tessdata và di chuyển nó vào thư mục gốc của dự án. -
Thêm phần phụ thuộc bên dưới vào dự án của bạn:
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>3.2.1</version>
</dependency>
- Thêm mã bên dưới vào dự án hiện có:
@GetMapping("/image-text")
String getImageText(@RequestParam String id) {
Optional<User> user = userRepository.findById(id);
ITesseract instance = new Tesseract();
try {
ByteArrayInputStream bais = new ByteArrayInputStream(user.get().getImage().getData());
BufferedImage bufferImg = ImageIO.read(bais);
String imgText = instance.doOCR(bufferImg);
return imgText;
} catch (Exception e) {
return "Error while reading image";
}
}