Nắm bắt kiến thức về tương lai của khuôn khổ không thể thay thế, Apache Hadoop.
Nếu không có phân tích Dữ liệu lớn, các công ty sẽ mù và điếc, lang thang trên web như những con nai trên xa lộ. - của Geoffrey Moore, Tác giả và Tư vấn Quản lý người Mỹ.
Trong bài viết này, chúng ta sẽ thấy tương lai của Hadoop trong phân tích dữ liệu lớn. Bài báo đưa ra các dự đoán của các chuyên gia liên quan đến cơ hội việc làm tại Hadoop. Bạn cũng sẽ thấy danh sách các Công ty sử dụng Hadoop và các lĩnh vực khác nhau như lĩnh vực tài chính, lĩnh vực chăm sóc sức khỏe sử dụng Hadoop.
Bài viết liệt kê các hồ sơ công việc khác nhau được cung cấp trong Big Data Hadoop.
Trước tiên, chúng ta hãy xem sự gia tăng của Dữ liệu lớn khiến các Công ty áp dụng Hadoop.
Dữ liệu lớn gia tăng
Các dự đoán cho rằng vào năm 2025, 463 exabyte dữ liệu sẽ được tạo ra mỗi ngày trên toàn cầu, tương đương với 212.765.957 DVD mỗi ngày!
Mỗi ngày có 500 triệu tweet, 294 tỷ email được gửi, 4 petabyte dữ liệu được tạo trên Facebook, 4 terabyte dữ liệu được tạo từ mỗi chiếc xe được kết nối, 65 tỷ tin nhắn được gửi trên WhatsApp và nhiều hơn nữa. Do đó, vào năm 2020, mỗi người đang tạo ra 1,7 megabyte chỉ trong một giây.
Bạn có thể tưởng tượng rằng mỗi ngày chúng ta đang tạo ra 2,5 nghìn tỷ byte dữ liệu không !!
Dữ liệu lớn mà không có thông tin là vô nghĩa. Các công ty khởi nghiệp và các công ty trong danh sách Fortune 500 đang áp dụng Dữ liệu lớn để đạt được tốc độ tăng trưởng theo cấp số nhân.
Các tổ chức hiện đã nhận ra lợi ích của phân tích Dữ liệu lớn, giúp họ có được thông tin chi tiết về doanh nghiệp, giúp nâng cao khả năng ra quyết định của họ.
Người ta dự đoán rằng thị trường Dữ liệu lớn, vào năm 2023, đạt 103 tỷ đô la.
Vào năm 2020, lượng dữ liệu toàn cầu được phân tích dữ liệu sẽ tăng lên 40 zettabyte, theo dự đoán.
Các cơ sở dữ liệu truyền thống không đủ khả năng để xử lý và phân tích một khối lượng lớn dữ liệu phi cấu trúc như vậy. Các công ty đang áp dụng Hadoop để phân tích Dữ liệu lớn.
Bây giờ chúng ta hãy xem chính xác Hadoop là gì và tại sao lại có nhu cầu về Hadoop, trước khi khám phá tương lai của Hadoop.
Hadoop là gì và tại sao nhu cầu của nó lại xuất hiện?
Với sự phát triển của thế giới Dữ liệu lớn, nảy sinh nhu cầu về các hệ thống hoàn hảo có thể xử lý, phân tích cú pháp, lưu trữ và truy xuất Dữ liệu lớn ngày càng tăng như vậy.
Cơ sở dữ liệu truyền thống không đủ khả năng để lưu trữ dữ liệu được tạo ra trong thời điểm hiện tại từ các nguồn không đồng nhất. Ngoài ra, chúng không có khả năng xử lý nhanh chóng lượng lớn dữ liệu này.
Hadoop xuất hiện như một tia sáng trong thế giới của Phân tích dữ liệu lớn.
Năm 2008, Apache Software Foundation đã phát triển Hadoop như một khung phần mềm mã nguồn mở để lưu trữ và xử lý một lượng lớn dữ liệu. Nó có sức mạnh xử lý khổng lồ cùng với khả năng xử lý song song và xử lý số lượng tác vụ / công việc không giới hạn.
Vì các tính năng độc đáo của Hadoop , chẳng hạn như khả năng lưu trữ dữ liệu lớn, khả năng xử lý nhanh, khả năng chịu lỗi, khả năng mở rộng và hiệu quả chi phí, thu hút các Công ty sử dụng Hadoop.
Ngoài ra, Hadoop không phải là một từ duy nhất; nó là một hệ sinh thái hoàn chỉnh được gọi là Hệ sinh thái Hadoop điều đó mang lại một điểm bổ sung cho Hadoop để được các Tổ chức sử dụng để thu thập dữ liệu lớn. Hadoop cung cấp tất cả những gì họ cần dưới một cái ô.
Do đó, thị trường Hadoop đang phát triển từng ngày và có một tương lai tươi sáng ở phía trước.
Phạm vi tương lai của Hadoop
Theo báo cáo của Forbes, Hadoop và thị trường Dữ liệu lớn sẽ đạt 99,31 tỷ đô la vào năm 2022, đạt CAGR 28,5%.
Hình ảnh dưới đây mô tả quy mô của Hadoop và Thị trường dữ liệu lớn trên toàn thế giới từ năm 2017 đến năm 2022.
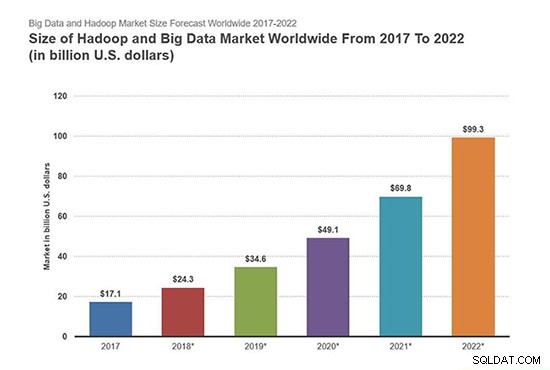
Nguồn hình ảnh - Forbes
Từ hình ảnh trên, chúng ta có thể dễ dàng nhận thấy sự trỗi dậy của Hadoop và thị trường dữ liệu lớn. Vì vậy, học Hadoop là cột mốc để thúc đẩy sự nghiệp trong lĩnh vực CNTT cũng như trong nhiều lĩnh vực khác.
Các công ty sử dụng Hadoop
Nghiên cứu chỉ ra rằng Hadoop có triển vọng thị trường tốt trong nhiều ngành. Với sự xuất hiện của vũ trụ kỹ thuật số, chúng ta đang đối phó với sự bùng nổ dữ liệu. Theo thời gian, các công nghệ mới liên tục xuất hiện, đóng góp một lượng lớn dữ liệu.
Hadoop đã nổi lên như một giải pháp tiên phong để xử lý và lưu trữ một lượng lớn dữ liệu. Thị trường Hadoop phân bổ theo các ngành dọc khác nhau.
Chúng tôi có thể nói rằng không có ngành nào bị loại bỏ khỏi việc trở thành một phần của thị trường Hadoop. Từ các ngành trong lĩnh vực CNTT Máy tính đến các ngành như bệnh viện và chăm sóc sức khỏe, giáo dục, tài chính, viễn thông, bán lẻ, v.v. đều có ứng dụng Hadoop chạy trên đó.
Với việc nhận ra những lợi thế của phân tích dữ liệu lớn, việc áp dụng Hadoop ngày càng tăng theo cấp số nhân.
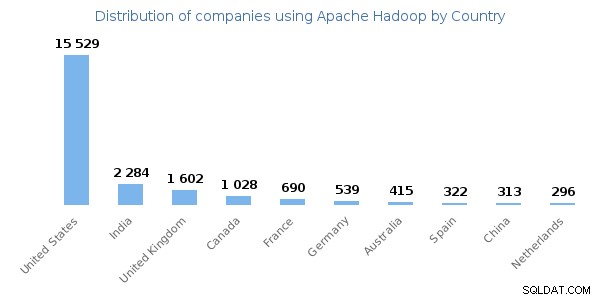
Nguồn hình ảnh - enlyft
Hình ảnh trên cho thấy sự phân bố của các công ty sử dụng nước Hadoop khôn ngoan. Hoa Kỳ là nước sử dụng công nghệ Hadoop chính.
Lý do cho thị trường Hadoop ngày càng phát triển là tính hiệu quả về chi phí, tính khả dụng cao, khả năng chịu lỗi và phân tích dữ liệu nhanh chóng.
Mặc dù có nhiều công cụ Phân tích dữ liệu lớn khác như Apache Spark , Flink, v.v. đang phát triển để đối phó với những thách thức về Dữ liệu lớn, nhưng không ai có thể thay thế Hadoop trong những năm tới vì họ không có bộ nhớ riêng, họ phụ thuộc vào Hadoop vì điều đó.
Ngay cả sau hơn 20 năm, có lẽ vẫn sẽ không có công nghệ nào phù hợp với sự ra đời của Dữ liệu lớn hơn Hadoop.
Dữ liệu lớn và Hadoop ở các miền khác nhau
Bây giờ, hãy cùng chúng tôi xem cách Hadoop đang giúp các doanh nghiệp giải quyết vấn đề của họ và các ứng dụng Hadoop trên các miền khác nhau đang được chạy như thế nào.
a. Lĩnh vực tài chính ngân hàng
Ngành tài chính và ngân hàng phải đối mặt với một số thách thức như gian lận thẻ, phân tích đánh dấu, lưu trữ dấu vết kiểm toán, báo cáo rủi ro tín dụng doanh nghiệp, v.v.
Họ sử dụng Hadoop để nhận được cảnh báo sớm về gian lận bảo mật và khả năng hiển thị thương mại. Họ sử dụng Hadoop để chuyển đổi và phân tích dữ liệu khách hàng để có thông tin chi tiết tốt hơn, phân tích hỗ trợ quyết định trước giao dịch, v.v.
b. Truyền thông, Truyền thông và Giải trí
Các ngành công nghiệp truyền thông, truyền thông và giải trí phải đối mặt với một số thách thức như thu thập và phân tích dữ liệu người tiêu dùng để có thông tin chi tiết, tìm ra các mô hình sử dụng phương tiện truyền thông trong thời gian thực, sử dụng mạng xã hội và nội dung di động.
Sử dụng Hadoop, các công ty này phân tích dữ liệu của khách hàng để có thông tin chi tiết tốt hơn, tạo nội dung cho các đối tượng mục tiêu khác nhau.
Ví dụ:Giải vô địch Wimbledon sử dụng dữ liệu lớn để phân tích cảm xúc chi tiết về các trận đấu quần vợt cho người dùng trong thời gian thực.
c. Nhà cung cấp dịch vụ chăm sóc sức khỏe
Các lĩnh vực Chăm sóc sức khỏe bằng cách sử dụng Hadoop phân tích định dạng dữ liệu không có cấu trúc bao gồm lịch sử bệnh nhân, lịch sử trường hợp bệnh. Điều này giúp họ có thể điều trị hiệu quả cho bệnh nhân dựa trên tiền sử ca bệnh trước đó.
Ngoài ra, bằng cách xác định căn bệnh phổ biến ở một khu vực cụ thể, có thể thực hiện các biện pháp phòng ngừa và có thể cung cấp thuốc cho những khu vực đó.
Đại học Florida sử dụng dữ liệu sức khỏe cộng đồng miễn phí và Google Maps để trực quan hóa dữ liệu cho phép xác định nhanh hơn sự lây lan của bệnh mãn tính.
d. Giáo dục
Ngành giáo dục sử dụng dữ liệu lớn một cách đáng kể. Đại học Tasmania có 26000 sinh viên đã triển khai LMS (Hệ thống quản lý học tập) để theo dõi thời gian ghi nhật ký, lượng thời gian sinh viên dành cho các trang khác nhau và tiến độ tổng thể của sinh viên theo thời gian.
e. Chính phủ
Có nhiều kế hoạch khác nhau của chính phủ đang được thực hiện và đang tạo ra rất nhiều dữ liệu. Cơ quan Quản lý Thực phẩm và Dược phẩm (FDA) đang sử dụng Dữ liệu lớn để phát hiện và nghiên cứu các dạng bệnh liên quan đến thực phẩm, cho phép đáp ứng điều trị nhanh hơn
Dự đoán công việc trong phân tích dữ liệu lớn
Vào năm 2023, thị trường phân tích dữ liệu lớn sẽ đạt 103 tỷ đô la theo dự đoán. IBM dự đoán rằng nhu cầu đối với nhà khoa học dữ liệu sẽ tăng vọt 28%.
Hơn 97,2% tổ chức đang đầu tư vào dữ liệu lớn và AI.
Theo báo cáo của PwC, đến năm 2022, ở Mỹ sẽ chỉ có khoảng 2,7 triệu vị trí tuyển dụng cho ngành phân tích dữ liệu và khoa học dữ liệu. Các công ty lớn nhất như Cisco, Dell, EY, IBM, Google, Siemens, Twitter, ngân hàng OCBC, đang tìm kiếm các chuyên gia Hadoop để xử lý và kiếm lợi từ biển dữ liệu có sẵn.
Đặc biệt trong ngành tài chính, ngành bảo hiểm và ngành CNTT đòi hỏi 59% tổng số việc làm của các nhà khoa học dữ liệu.
Hình ảnh dưới đây cho thấy mức lương trung bình cho các chuyên gia có kỹ năng phân tích tương ứng. 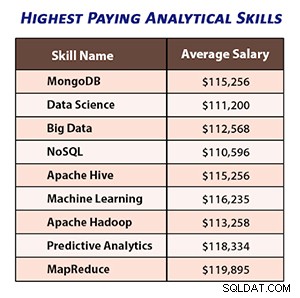
Nguồn hình ảnh - thực sự
Theo báo cáo gần đây của IBM, các chuyên gia Khoa học dữ liệu và Phân tích dữ liệu có kỹ năng MapReduce đang kiếm được trung bình $ 115,907 một năm, khiến MapReduce trở thành kỹ năng được yêu cầu nhiều nhất.
Khoa học dữ liệu và các chuyên gia phân tích có chuyên môn về Apache Hadoop, Hive và Pig đang cạnh tranh cho các công việc được trả trên 100 nghìn đô la.
Mức lương và chức danh công việc cho Phân tích dữ liệu lớn
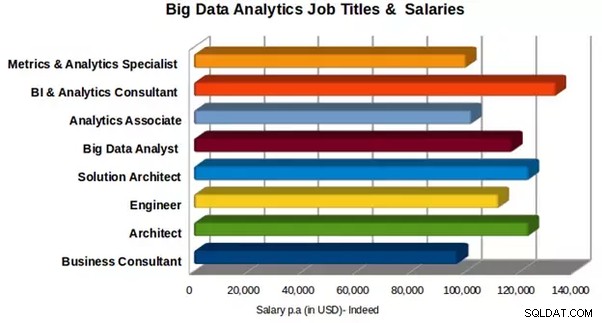
Mức lương trung bình hàng năm ở Vương quốc Anh là £ 66,250- £ 66,750 cho các công việc Hadoop và $ 92,512 đến $ 102,679 cho các nhà phát triển Hadoop, theo Thật vậy.
Có nhiều hồ sơ công việc khác nhau dành cho người có các kỹ năng liên quan trong Hadoop. Một số trong số đó là:
Quản trị viên Hadoop
Quản trị viên Hadoop thiết lập cụm Hadoop và giám sát nó bằng các công cụ giám sát. Nó theo dõi kết nối cụm và bảo mật.
Mức lương được đề nghị từ INR 10-15 LPA .
Kiến trúc sư Hadoop
Hadoop Architect là người lập kế hoạch và thiết kế kiến trúc Big Data Hadoop. Anh ấy tạo ra phân tích yêu cầu và quản lý việc phát triển và triển khai trên các ứng dụng Hadoop. Mức lương được đề nghị nằm trong khoảng 9-11 INR LPA .
Nhà phân tích dữ liệu lớn
Big Data Analyst phân tích dữ liệu lớn để đánh giá hiệu suất kỹ thuật của các công ty và đưa ra các khuyến nghị về cải tiến hệ thống. Chúng thực thi các quy trình dữ liệu lớn như chú thích văn bản, phân tích cú pháp, lọc làm giàu. Mức lương định dạng trước là INR 7-10 LPA .
Nhà phát triển Hadoop
Nhiệm vụ chính của nhà phát triển Hadoop là phát triển các công nghệ Hadoop sử dụng Java, HQL và các ngôn ngữ kịch bản. Mức lương được đề nghị nằm trong khoảng INR 5-10 LPA tùy thuộc vào hồ sơ công việc ở Ấn Độ.
Hadoop Tester
Trình kiểm tra Hadoop kiểm tra lỗi và lỗi và sửa lỗi. Anh ấy đảm bảo rằng MapReduce các công việc, tập lệnh HiveQL và tập lệnh Pig Latin hoạt động bình thường. Mức lương của Hadoop Tester là từ INR 5-10 LPA .
Tóm tắt
Tôi hy vọng sau khi đọc bài viết này, bạn đã nhận thức rõ về tương lai của Hadoop. Không có công nghệ nào kể cả sau 20 năm sẽ thay thế được Apache Hadoop. Vì vậy, một người đang tìm kiếm sự nghiệp của mình trong lĩnh vực không bao giờ lỗi mốt, Hadoop là sự lựa chọn tốt nhất cho họ.
Bạn ngạc nhiên với tương lai của Hadoop?
Bạn đang chờ đợi điều gì? Bắt đầu học Hadoop và đạt được công việc mơ ước và trọn gói ở các quốc gia yêu thích của bạn.
Theo dõi TechVidvan Left Sidebar và bắt đầu học Hadoop.
Tiếp tục học tập !!



