Cho đến bây giờ chúng tôi đã đề cập đến phần giới thiệu Hadoop và Hadoop HDFS chi tiết. Trong hướng dẫn này, chúng tôi sẽ cung cấp cho bạn mô tả chi tiết về Hộp giảm tốc Hadoop.
Ở đây sẽ thảo luận về Reduceer trong MapReduce là gì, cách hoạt động của Reducer trong Hadoop MapReduce, các giai đoạn khác nhau của Hadoop Reducer, cách chúng ta có thể thay đổi số lượng Giảm trong Hadoop MapReduce.
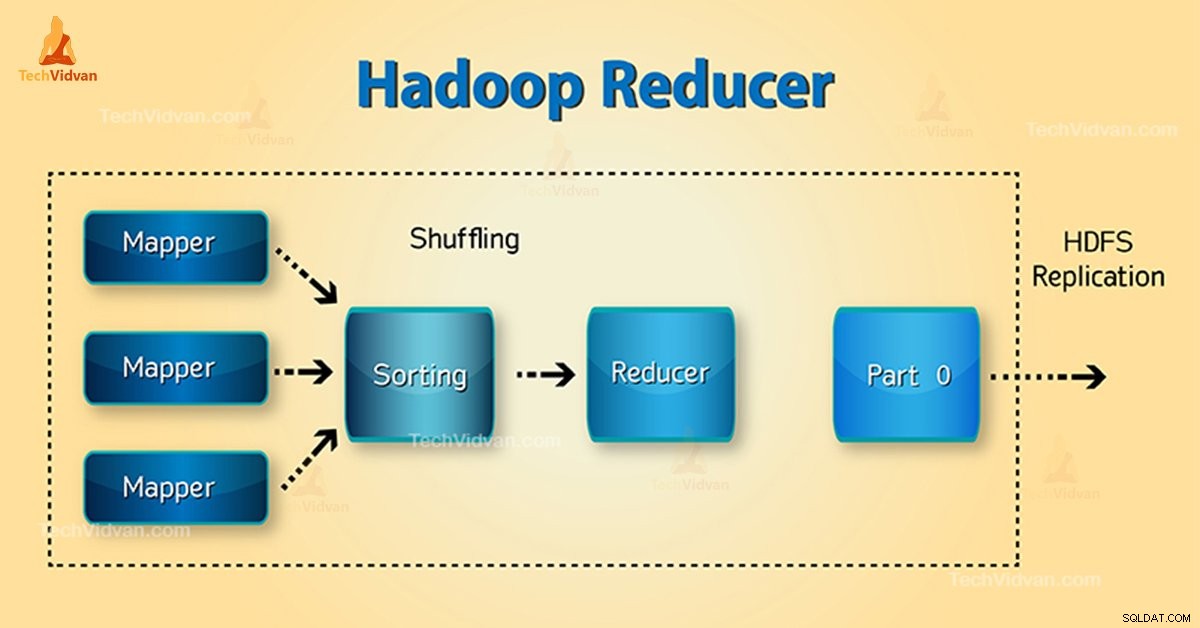
Hộp giảm tốc Hadoop là gì?
Hộp giảm tốc trong Hadoop MapReduce giảm một tập hợp các giá trị trung gian dùng chung khóa thành một tập giá trị nhỏ hơn.
Trong luồng thực thi công việc MapReduce, Reducer nhận một tập hợp cặp khóa-giá trị trung gian do người lập bản đồ sản xuất làm đầu vào. Sau đó, Bộ giảm tổng hợp, lọc và kết hợp các cặp khóa-giá trị và điều này đòi hỏi nhiều quá trình xử lý.
Ánh xạ một-một diễn ra giữa các phím và bộ giảm trong thực thi công việc MapReduce. Chúng chạy song song vì chúng độc lập với nhau. Người dùng quyết định số lượng bộ giảm trong MapReduce.
Các giai đoạn của Hộp giảm tốc Hadoop
Ba giai đoạn của Hộp giảm tốc như sau:
1. Giai đoạn ngẫu nhiên
Đây là giai đoạn trong đó đầu ra được sắp xếp từ bộ ánh xạ là đầu vào cho bộ giảm tốc. Khung với sự trợ giúp của HTTP tìm nạp phân vùng có liên quan của đầu ra của tất cả các trình ánh xạ trong giai đoạn này.
2. Giai đoạn sắp xếp
Đây là giai đoạn trong đó dữ liệu đầu vào từ các trình lập bản đồ khác nhau được sắp xếp lại dựa trên các khóa tương tự trong các trình lập bản đồ khác nhau.
Cả Xáo trộn và Sắp xếp xảy ra đồng thời.
3. Giảm giai đoạn
Giai đoạn này xảy ra sau khi xáo trộn và sắp xếp. Giảm tác vụ tổng hợp các cặp khóa-giá trị. Với OutputCollector.collect () thuộc tính, đầu ra của tác vụ thu gọn được ghi vào FileSystem. Đầu ra của bộ giảm tốc không được sắp xếp.
Số lượng bộ giảm trong Hadoop MapReduce
Người dùng đặt số lượng bộ giảm với sự trợ giúp của Job.setNumreduceTasks (int) bất động sản. Do đó, số lượng bộ giảm dần theo công thức:
0,95 hoặc 1,75 nhân với (
Vì vậy, với 0,95, tất cả các bộ giảm tốc ngay lập tức khởi chạy. Sau đó, bắt đầu chuyển kết quả đầu ra bản đồ khi bản đồ hoàn thành.
Nút nhanh hơn kết thúc vòng giảm đầu tiên với 1,75. Sau đó, nó khởi chạy làn sóng giảm tốc thứ hai, thực hiện công việc cân bằng tải tốt hơn nhiều.
Với sự gia tăng của số lượng bộ giảm:
- Tăng chi phí khung.
- Cân bằng tải tăng lên.
- Chi phí thất bại giảm xuống.
Kết luận
Do đó, Reducer lấy đầu ra của người lập bản đồ làm đầu vào. Sau đó, xử lý các cặp khóa-giá trị và tạo ra kết quả. Đầu ra của bộ giảm tốc là đầu ra cuối cùng. Nếu bạn thích blog này hoặc bạn có bất kỳ câu hỏi nào liên quan đến Hadoop Reducer, vui lòng chia sẻ với chúng tôi bằng cách để lại nhận xét.
Hy vọng chúng tôi sẽ giúp bạn.



