Trong blog này, chúng tôi sẽ cung cấp cho bạn phần giới thiệu đầy đủ về Hadoop Mapper . Tôi
Trong blog này, chúng tôi sẽ giải đáp về Mapper trong Hadoop MapReduce là gì, cách hoạt động của trình lập bản đồ hadoop, quy trình của ánh xạ trong Mapreduce là gì, cách Hadoop tạo ra cặp Key-value trong MapReduce.
Giới thiệu về Hadoop Mapper
Hadoop Mapper xử lý bản ghi đầu vào do RecordReader tạo và tạo các cặp khóa-giá trị trung gian. Đầu ra trung gian hoàn toàn khác với cặp đầu vào.
Đầu ra của trình ánh xạ là tập hợp đầy đủ các cặp khóa-giá trị. Trước khi ghi đầu ra cho mỗi tác vụ ánh xạ, việc phân vùng đầu ra diễn ra trên cơ sở khóa. Do đó, phân vùng thành từng mục mà tất cả các giá trị cho mỗi khóa được nhóm lại với nhau.
Hadoop MapReduce tạo một nhiệm vụ bản đồ cho mỗi InputSplit.
Hadoop MapReduce chỉ hiểu các cặp dữ liệu khóa-giá trị. Vì vậy, trước khi gửi dữ liệu tới trình liên kết, khung Hadoop nên giấu dữ liệu vào cặp khóa-giá trị.
Cặp khóa-giá trị được tạo như thế nào trong Hadoop?
Như chúng ta đã hiểu ánh xạ trong hadoop là gì, bây giờ chúng ta sẽ thảo luận về cách Hadoop tạo cặp khóa-giá trị?
- InputSplit - Đây là biểu diễn logic của dữ liệu được tạo bởi Định dạng đầu vào. Trong chương trình MapReduce, nó mô tả một đơn vị công việc chứa một nhiệm vụ bản đồ.
- RecordReader- Nó giao tiếp với inputSplit. Và sau đó chuyển đổi dữ liệu thành các cặp khóa-giá trị phù hợp để Mapper đọc. RecordReader theo mặc định sử dụng TextInputFormat để chuyển đổi dữ liệu thành cặp khóa-giá trị.
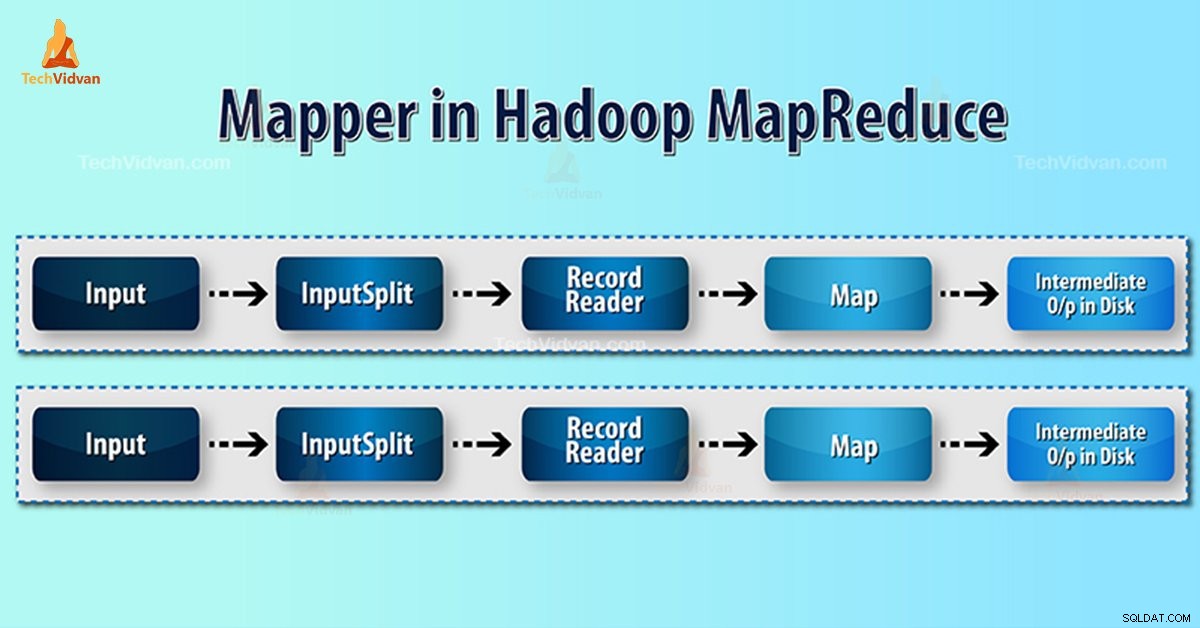
Quy trình lập bản đồ trong Hadoop MapReduce
InputSplit chuyển đổi biểu diễn vật lý của các khối thành lôgic cho Người lập bản đồ. Ví dụ, để đọc tệp 100MB, nó sẽ yêu cầu 2 InputSplit. Đối với mỗi khối, khung công tác tạo một InputSplit. Mỗi InputSplit tạo một ánh xạ.
MapReduce InputSplit không phải lúc nào cũng phụ thuộc vào số lượng khối dữ liệu . Chúng tôi có thể thay đổi số lượng phân tách bằng cách đặt thuộc tính mapred.max.split.size trong quá trình thực hiện công việc.
MapReduce RecordReader chịu trách nhiệm đọc / chuyển đổi dữ liệu thành các cặp khóa-giá trị cho đến cuối tệp. RecordReader chỉ định độ lệch Byte cho mỗi dòng có trong tệp.
Sau đó Mapper nhận được cặp khóa này. Người lập bản đồ tạo ra đầu ra trung gian (các cặp khóa-giá trị có thể hiểu được để giảm bớt).
Có bao nhiêu tác vụ Bản đồ trong Hadoop?
Số lượng nhiệm vụ bản đồ phụ thuộc vào tổng số khối của các tệp đầu vào. Trong bản đồ MapReduce, mức độ song song phù hợp dường như là khoảng 10-100 bản đồ / nút. Nhưng có 300 bản đồ cho các tác vụ bản đồ nhẹ CPU.
Ví dụ:chúng tôi có kích thước khối là 128 MB. Và chúng tôi mong đợi 10TB dữ liệu đầu vào. Do đó, nó tạo ra 82.000 bản đồ. Do đó, số lượng bản đồ phụ thuộc vào InputFormat.
Mapper =(tổng kích thước dữ liệu) / (kích thước phân chia đầu vào)
Ví dụ - kích thước dữ liệu là 1 TB. Kích thước phân chia đầu vào là 100 MB.
Người lập bản đồ =(1000 * 1000) / 100 =10.000
Kết luận
Do đó, Mapper trong Hadoop lấy một tập dữ liệu và chuyển đổi nó thành một tập dữ liệu khác. Do đó, nó chia các phần tử riêng lẻ thành các bộ giá trị (cặp khóa / giá trị).
Hy vọng bạn thích khối này, nếu bạn có bất kỳ câu hỏi nào về trình lập bản đồ Hadoop, vui lòng để lại nhận xét trong phần được đưa ra bên dưới. Chúng tôi sẽ sẵn lòng giải quyết chúng.



