Apache Hadoop là một khung phần mềm xử lý và lưu trữ dữ liệu lớn trên toàn bộ nhóm phần cứng hàng hóa. Hadoop dựa trên mô hình MapReduce để xử lý lượng dữ liệu khổng lồ theo cách phân tán.
Hướng dẫn MapReduce này giới thiệu một số tính năng của MapReduce. Sau khi đọc phần này, bạn sẽ hiểu rõ ràng lý do tại sao MapReduce phù hợp nhất để xử lý một lượng lớn dữ liệu.
Đầu tiên, chúng ta sẽ xem một phần giới thiệu nhỏ về khung công tác MapReduce. Sau đó, chúng ta sẽ khám phá các tính năng khác nhau của MapReduce.
Chúng ta hãy bắt đầu với phần giới thiệu về khung MapReduce.
Giới thiệu về MapReduce
MapReduce là một khung phần mềm để viết các ứng dụng có thể xử lý lượng dữ liệu khổng lồ trên các cụm nút đắt tiền. Hadoop MapReduce là phần xử lý của Apache Hadoop.
Nó còn được gọi là trái tim của Hadoop. Nó là ứng dụng xử lý dữ liệu được ưa thích nhất. Một số người chơi trong lĩnh vực thương mại điện tử như Amazon, Yahoo và Zuventus, v.v. đang sử dụng khung MapReduce để xử lý dữ liệu khối lượng lớn.
Bây giờ chúng ta hãy nghiên cứu các tính năng khác nhau của Hadoop MapReduce.
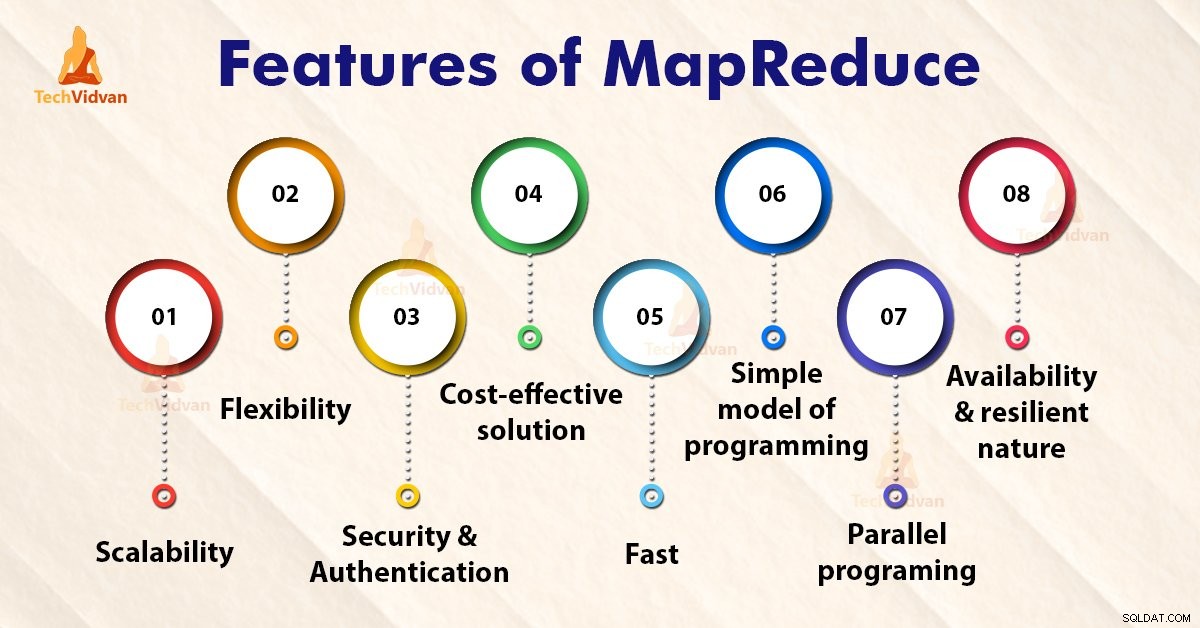
Các tính năng của MapReduce
1. Khả năng mở rộng
Apache Hadoop là một khung công tác có khả năng mở rộng cao. Điều này là do khả năng lưu trữ và phân phối dữ liệu khổng lồ trên nhiều máy chủ. Tất cả các máy chủ này không đắt và có thể hoạt động song song. Chúng tôi có thể dễ dàng mở rộng quy mô lưu trữ và sức mạnh tính toán bằng cách thêm máy chủ vào cụm.
Lập trình Hadoop MapReduce cho phép các tổ chức chạy các ứng dụng từ các tập hợp lớn các nút có thể liên quan đến việc sử dụng hàng nghìn terabyte dữ liệu.
Lập trình Hadoop MapReduce cho phép các tổ chức kinh doanh chạy các ứng dụng từ các tập hợp lớn các nút. Điều này có thể sử dụng hàng nghìn terabyte dữ liệu.
2. Tính linh hoạt
Lập trình MapReduce cho phép các công ty truy cập các nguồn dữ liệu mới. Nó cho phép các công ty hoạt động trên các loại dữ liệu khác nhau. Nó cho phép các doanh nghiệp truy cập vào dữ liệu có cấu trúc cũng như không có cấu trúc và thu được giá trị đáng kể bằng cách thu thập thông tin chi tiết từ nhiều nguồn dữ liệu.
Ngoài ra, khung MapReduce cũng cung cấp hỗ trợ cho nhiều ngôn ngữ và dữ liệu từ các nguồn khác nhau, từ email, phương tiện truyền thông xã hội đến dòng nhấp chuột.
MapReduce xử lý dữ liệu theo các cặp khóa-giá trị đơn giản, do đó hỗ trợ kiểu dữ liệu bao gồm siêu dữ liệu, hình ảnh và tệp lớn. Do đó, MapReduce linh hoạt để xử lý dữ liệu hơn là DBMS truyền thống.
3. Bảo mật và xác thực
Mô hình lập trình MapReduce sử dụng nền tảng bảo mật HBase và HDFS cho phép chỉ những người dùng đã xác thực truy cập để thao tác trên dữ liệu. Do đó, nó bảo vệ việc truy cập trái phép vào dữ liệu hệ thống và tăng cường bảo mật hệ thống.
4. Giải pháp hiệu quả về chi phí
Kiến trúc có thể mở rộng của Hadoop với khung lập trình MapReduce cho phép lưu trữ và xử lý các tập dữ liệu lớn theo cách rất hợp lý.
5. Nhanh chóng
Hadoop sử dụng phương thức lưu trữ phân tán được gọi là Hệ thống tệp phân tán Hadoop về cơ bản triển khai hệ thống ánh xạ để định vị dữ liệu trong một cụm.
Các công cụ được sử dụng để xử lý dữ liệu, chẳng hạn như lập trình MapReduce, thường được đặt trên cùng một máy chủ cho phép xử lý dữ liệu nhanh hơn.
Vì vậy, ngay cả khi chúng tôi đang xử lý khối lượng lớn dữ liệu phi cấu trúc, Hadoop MapReduce chỉ mất vài phút để xử lý hàng terabyte dữ liệu. Nó có thể xử lý hàng petabyte dữ liệu chỉ trong một giờ.
6. Mô hình lập trình đơn giản
Trong số các tính năng khác nhau của Hadoop MapReduce, một trong những tính năng quan trọng nhất là nó dựa trên một mô hình lập trình đơn giản. Về cơ bản, điều này cho phép các lập trình viên phát triển các chương trình MapReduce có thể xử lý các tác vụ một cách dễ dàng và hiệu quả.
Các chương trình MapReduce có thể được viết bằng Java, không khó để chọn và cũng được sử dụng rộng rãi. Vì vậy, bất kỳ ai cũng có thể dễ dàng học và viết các chương trình MapReduce và đáp ứng nhu cầu xử lý dữ liệu của họ.
7. Lập trình song song
Một trong những khía cạnh chính của hoạt động của lập trình MapReduce là xử lý song song của nó. Nó phân chia các tác vụ theo cách cho phép chúng thực hiện song song.
Quá trình xử lý song song cho phép nhiều bộ xử lý thực hiện các tác vụ được chia này. Vì vậy, toàn bộ chương trình được chạy trong thời gian ngắn hơn.
8. Tính sẵn có và khả năng phục hồi
Bất cứ khi nào dữ liệu được gửi đến một nút riêng lẻ, cùng một tập dữ liệu sẽ được chuyển tiếp đến một số nút khác trong một cụm. Vì vậy, nếu bất kỳ nút cụ thể nào bị lỗi, thì luôn có các bản sao khác hiện diện trên các nút khác mà vẫn có thể được truy cập bất cứ khi nào cần. Điều này đảm bảo tính khả dụng cao của dữ liệu.
Một trong những tính năng chính được Apache Hadoop cung cấp là khả năng chịu lỗi của nó. Khung Hadoop MapReduce có khả năng nhanh chóng nhận ra các lỗi xảy ra.
Sau đó, nó áp dụng một giải pháp khôi phục nhanh chóng và tự động. Tính năng này khiến nó trở thành người thay đổi cuộc chơi trong thế giới xử lý dữ liệu lớn.
Tóm tắt
Tôi hy vọng sau khi đọc bài viết này, bạn đã hiểu rõ ràng về các tính năng khác nhau của Hadoop MapReduce. Bài báo đã giới thiệu các tính năng khác nhau của MapReduce. Khung MapReduce là hệ thống có thể mở rộng, linh hoạt, tiết kiệm chi phí và xử lý nhanh chóng.
Nó cung cấp bảo mật, khả năng chịu lỗi và xác thực. MapReduce là một mô hình lập trình đơn giản và cung cấp lập trình song song.



