Nếu bạn muốn biết mọi thứ về Hadoop MapReduce, bạn đã đến đúng nơi. Hướng dẫn MapReduce này cung cấp cho bạn hướng dẫn đầy đủ về từng thứ và mọi thứ trong Hadoop MapReduce.
Trong phần Giới thiệu MapReduce này, bạn sẽ khám phá Hadoop MapReduce là gì, Cách thức hoạt động của khung MapReduce. Bài viết cũng đề cập đến MapReduce DataFlow, Các giai đoạn khác nhau trong MapReduce, Mapper, Reducer, Partitioner, Cominer, Shuffling, Sorting, Data Locality, và nhiều hơn nữa.
Chúng tôi cũng đã tận dụng những lợi thế của khung MapReduce.
Trước tiên, hãy cùng chúng tôi khám phá lý do tại sao chúng tôi cần Hadoop MapReduce.
Tại sao sử dụng MapReduce?
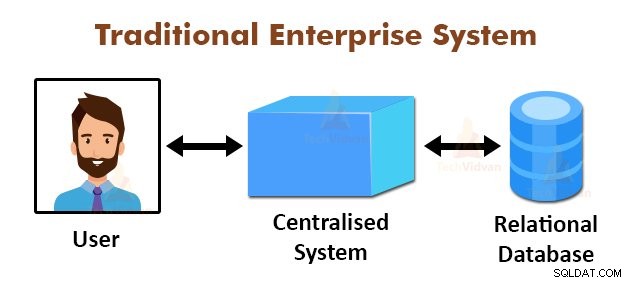
Hình trên mô tả sơ đồ hệ thống doanh nghiệp truyền thống. Các hệ thống truyền thống thường có một máy chủ tập trung để lưu trữ và xử lý dữ liệu. Mô hình này không phù hợp để xử lý lượng lớn dữ liệu có thể mở rộng.
Ngoài ra, mô hình này không thể được đáp ứng bởi các máy chủ cơ sở dữ liệu tiêu chuẩn. Ngoài ra, hệ thống tập trung tạo ra quá nhiều nút cổ chai trong khi xử lý nhiều tệp đồng thời.
Bằng cách sử dụng thuật toán MapReduce, Google đã giải quyết được vấn đề tắc nghẽn này. Khung MapReduce chia nhiệm vụ thành các phần nhỏ và giao nhiệm vụ cho nhiều máy tính.
Sau đó, kết quả được thu thập tại một địa điểm chung và sau đó được tích hợp để tạo thành tập dữ liệu kết quả.
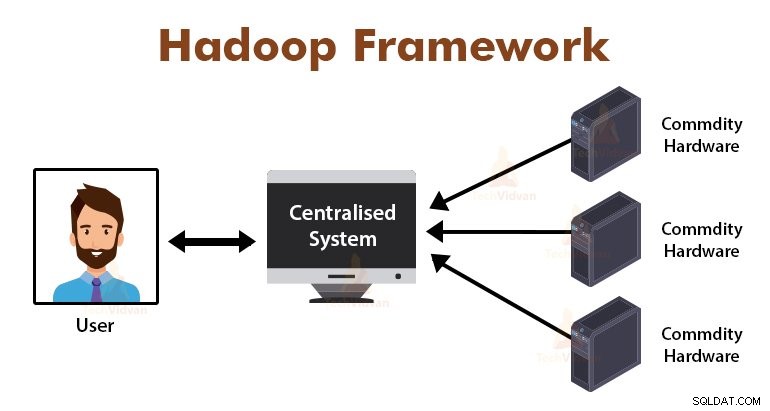
Giới thiệu về MapReduce Framework
MapReduce là lớp xử lý trong Hadoop. Đây là một khung phần mềm được thiết kế để xử lý song song khối lượng dữ liệu khổng lồ bằng cách chia nhiệm vụ thành một tập hợp các tác vụ độc lập.
Chúng ta chỉ cần đặt logic nghiệp vụ theo cách hoạt động của MapReduce và khung công tác sẽ đảm nhận những việc còn lại. Khung MapReduce hoạt động bằng cách chia công việc thành các nhiệm vụ nhỏ và giao các nhiệm vụ này cho các nô lệ.
Các chương trình MapReduce được viết theo một phong cách cụ thể chịu ảnh hưởng của các cấu trúc lập trình chức năng, các thành ngữ cụ thể để xử lý danh sách dữ liệu.
Trong MapReduce, các đầu vào ở dạng danh sách và đầu ra từ khung công tác cũng ở dạng danh sách. MapReduce là trung tâm của Hadoop. Hiệu quả và sức mạnh của Hadoop là do xử lý song song của khung MapReduce.
Bây giờ, hãy cùng chúng tôi khám phá cách hoạt động của Hadoop MapReduce.
Hadoop MapReduce hoạt động như thế nào?
Khung Hadoop MapReduce hoạt động bằng cách chia một công việc thành các tác vụ độc lập và thực thi các tác vụ này trên các máy phụ. Công việc MapReduce được thực hiện trong hai giai đoạn là giai đoạn lập bản đồ và giai đoạn thu gọn.
Đầu vào và đầu ra từ cả hai pha là các cặp giá trị, khóa. Khung MapReduce dựa trên nguyên tắc định vị dữ liệu (sẽ thảo luận ở phần sau), có nghĩa là nó gửi tính toán đến các nút nơi chứa dữ liệu.
- Giai đoạn lập bản đồ - Trong giai đoạn Bản đồ, chức năng bản đồ do người dùng xác định sẽ xử lý dữ liệu đầu vào. Trong chức năng bản đồ, người dùng đặt logic nghiệp vụ. Đầu ra từ giai đoạn Bản đồ là đầu ra trung gian và được lưu trữ trên đĩa cục bộ.
- Giảm giai đoạn - Giai đoạn này là sự kết hợp của giai đoạn xáo trộn và giai đoạn giảm. Trong giai đoạn Rút gọn, đầu ra từ giai đoạn bản đồ được chuyển đến Bộ giảm tốc nơi chúng được tổng hợp. Đầu ra của giai đoạn Giảm là đầu ra cuối cùng. Trong giai đoạn Rút gọn, chức năng rút gọn do người dùng xác định sẽ xử lý đầu ra của Người lập bản đồ và tạo ra kết quả cuối cùng.
Trong quá trình thực hiện công việc MapReduce, khung công tác Hadoop gửi các tác vụ Bản đồ và các tác vụ Rút gọn đến các máy thích hợp trong cụm.
Bản thân khung công tác quản lý tất cả các chi tiết của việc truyền dữ liệu, chẳng hạn như phát hành nhiệm vụ, xác minh việc hoàn thành nhiệm vụ và sao chép dữ liệu giữa các nút xung quanh cụm. Các tác vụ diễn ra trên các nút có dữ liệu để giảm lưu lượng mạng.
Luồng dữ liệu MapReduce
Tất cả các bạn có thể muốn biết cách tạo các cặp giá trị khóa này và cách MapReduce xử lý dữ liệu đầu vào. Phần này trả lời tất cả những câu hỏi này.
Hãy để chúng tôi xem Cách dữ liệu phải luân chuyển từ các giai đoạn khác nhau trong Hadoop MapReduce để xử lý dữ liệu sắp tới theo cách song song và phân tán.
1. InputFiles
Tập dữ liệu đầu vào sẽ được xử lý bởi chương trình MapReduce được lưu trữ trong InputFile. InputFile được lưu trữ trong Hệ thống tệp phân tán Hadoop.
2. InputSplit
Bản ghi trong InputFiles được tách thành mô hình logic. Kích thước phân chia thường bằng kích thước khối HDFS. Mỗi phần tách được xử lý bởi Người lập bản đồ riêng lẻ.
3. Định dạng đầu vào
InputFormat chỉ định đặc điểm kỹ thuật đầu vào của tệp. Nó xác định đường đến RecordReader trong đó bản ghi từ InputFile được chuyển đổi thành các cặp khóa, giá trị.
4. RecordReader
RecordReader đọc dữ liệu từ InputSplit và chuyển đổi các bản ghi thành các cặp khóa, giá trị và trình bày chúng cho Người lập bản đồ.
5. Người lập bản đồ
Người lập bản đồ lấy các cặp khóa, cặp giá trị làm đầu vào từ RecordReader và xử lý chúng bằng cách triển khai chức năng bản đồ do người dùng xác định. Trong mỗi Người lập bản đồ, tại một thời điểm, một phần tách riêng lẻ được xử lý.
Nhà phát triển đã đưa logic nghiệp vụ vào chức năng bản đồ. Đầu ra từ tất cả các trình ánh xạ là đầu ra trung gian, cũng ở dạng cặp khóa, giá trị.
6. Trộn và sắp xếp
Đầu ra trung gian do Người lập bản đồ tạo ra được sắp xếp trước khi chuyển đến Bộ giảm tốc để giảm tắc nghẽn mạng. Sau đó, các đầu ra trung gian được sắp xếp sẽ được trộn vào Bộ giảm tốc qua mạng.
7. Hộp giảm tốc
Quy trình Reduce và tổng hợp các đầu ra của Mapper bằng cách triển khai chức năng giảm do người dùng xác định. Đầu ra Reducers là đầu ra cuối cùng và được lưu trữ trong Hệ thống tệp phân tán Hadoop (HDFS).
Bây giờ chúng ta hãy nghiên cứu một số thuật ngữ và khái niệm nâng cao của khung Hadoop MapReduce.
Các cặp Khóa-Giá trị trong MapReduce
Khung MapReduce hoạt động trên các cặp khóa, giá trị vì nó xử lý lược đồ không tĩnh. Nó nhận dữ liệu ở dạng khóa, cặp giá trị và đầu ra được tạo cũng ở dạng cặp khóa, giá trị.
Khóa MapReduce Cặp giá trị là một thực thể bản ghi được nhận bởi công việc MapReduce để thực thi. Trong cặp khóa-giá trị:
- Khóa là độ lệch dòng so với đầu dòng trong tệp.
- Giá trị là nội dung dòng, không bao gồm các dấu chấm cuối dòng.
MapReduce Partitioner
Hadoop MapReduce Partitioner phân vùng keyspace. Không gian khóa phân vùng trong MapReduce chỉ định rằng tất cả các giá trị của mỗi khóa được nhóm lại với nhau và nó đảm bảo rằng tất cả các giá trị của khóa đơn phải đi đến cùng một Bộ giảm.
Việc phân vùng này cho phép phân phối đồng đều đầu ra của người lập bản đồ trên Bộ giảm tốc bằng cách đảm bảo rằng phím phù hợp đi đến Bộ giảm tốc phù hợp.
Trình phân vùng MapReducer mặc định là Trình phân vùng băm, phân vùng các không gian khóa trên cơ sở giá trị băm.
Bộ kết hợp MapReduce
MapReduce Combiner còn được gọi là "Semi-Reducer." Nó đóng một vai trò quan trọng trong việc giảm tắc nghẽn mạng. Khung MapReduce cung cấp chức năng để xác định Bộ kết hợp, kết hợp đầu ra trung gian từ Người lập bản đồ trước khi chuyển chúng đến Bộ giảm.
Việc tổng hợp các kết quả đầu ra của Mapper trước khi chuyển đến Reducer giúp khuôn khổ xáo trộn một lượng nhỏ dữ liệu, dẫn đến tình trạng tắc nghẽn mạng thấp.
Chức năng chính của Bộ kết hợp là tổng hợp kết quả đầu ra của các Mappers bằng cùng một khóa và chuyển nó cho Bộ giảm. Lớp Combiner được sử dụng giữa lớp Mapper và lớp Reducer.
Vị trí dữ liệu trong MapReduce
Vị trí dữ liệu đề cập đến “Di chuyển tính toán gần với dữ liệu hơn là di chuyển dữ liệu sang tính toán.” Sẽ hiệu quả hơn nhiều nếu tính toán mà ứng dụng yêu cầu được thực thi trên máy có dữ liệu được yêu cầu.
Điều này rất đúng trong trường hợp kích thước dữ liệu lớn. Đó là vì nó giảm thiểu tắc nghẽn mạng và tăng thông lượng tổng thể của hệ thống.
Giả định duy nhất đằng sau điều này là tốt hơn nên di chuyển máy tính đến gần máy có dữ liệu thay vì chuyển dữ liệu đến máy có ứng dụng đang chạy.
Apache Hadoop hoạt động trên một khối lượng lớn dữ liệu, vì vậy việc di chuyển dữ liệu khổng lồ như vậy qua mạng sẽ không hiệu quả. Do đó, khuôn khổ đã đưa ra nguyên tắc sáng tạo nhất đó là vị trí dữ liệu, nguyên tắc này chuyển logic tính toán sang dữ liệu thay vì chuyển dữ liệu sang các thuật toán tính toán. Đây được gọi là vùng dữ liệu.
Ưu điểm của MapReduce
1. Khả năng mở rộng: Khung công tác MapReduce có khả năng mở rộng cao. Nó cho phép các tổ chức chạy các ứng dụng từ các bộ máy lớn, có thể liên quan đến việc sử dụng hàng nghìn terabyte dữ liệu.
2. Tính linh hoạt: Khung MapReduce cung cấp sự linh hoạt cho tổ chức để xử lý dữ liệu ở bất kỳ kích thước nào và bất kỳ định dạng nào, có cấu trúc, bán cấu trúc hoặc phi cấu trúc.
3. Bảo mật và Xác thực: Mô hình lập trình MapReduce cung cấp tính bảo mật cao. Nó bảo vệ mọi truy cập trái phép vào dữ liệu và tăng cường bảo mật cụm.
4. Hiệu quả về chi phí: Khung xử lý dữ liệu trên toàn bộ cụm phần cứng hàng hóa, là những cỗ máy đắt tiền. Do đó, nó rất hiệu quả.
5. Nhanh chóng: MapReduce xử lý dữ liệu song song do đó nó rất nhanh. Chỉ mất vài phút để xử lý hàng terabyte dữ liệu.
6. Một mô hình đơn giản để lập trình: Các chương trình MapReduce có thể được viết bằng bất kỳ ngôn ngữ nào như Java, Python, Perl, R, v.v. Vì vậy, bất kỳ ai cũng có thể dễ dàng học và viết các chương trình MapReduce và đáp ứng nhu cầu xử lý dữ liệu của họ.
Cách sử dụng MapReduce
1. Phân tích nhật ký: MapReduce về cơ bản được sử dụng để phân tích các tệp nhật ký. Khung làm việc chia nhỏ các tệp nhật ký lớn thành phần tách và một trình ánh xạ tìm kiếm các trang web khác nhau đã được truy cập.
Mỗi khi một trang web được tìm thấy trong nhật ký, thì một cặp khóa, giá trị được chuyển đến bộ giảm tải nơi khóa là trang web và giá trị là “1”. Sau khi tạo ra một cặp khóa, giá trị cho Bộ giảm tốc, Bộ giảm tổng hợp số lượng cho các trang web nhất định.
Kết quả cuối cùng sẽ là tổng số lần truy cập cho mọi trang web.
2. Lập chỉ mục toàn văn: MapReduce cũng được sử dụng để thực hiện lập chỉ mục toàn văn bản. Trình lập bản đồ trong MapReduce sẽ ánh xạ mọi cụm từ hoặc từ trong một tài liệu vào tài liệu. Bộ giảm sẽ ghi các ánh xạ này vào một chỉ mục.
3. Google sử dụng MapReduce để tính Pagerank của họ.
4. Đồ thị liên kết web ngược: MapReduce cũng được sử dụng trong GRaph Reverse Web-Link. Hàm Bản đồ xuất ra đích và nguồn URL, lấy đầu vào từ trang web (nguồn).
Sau đó, hàm rút gọn sẽ nối danh sách tất cả các URL nguồn được liên kết với URL mục tiêu đã cho và nó trả về mục tiêu và danh sách các nguồn.
5. Số lượng từ trong tài liệu: Khung MapReduce có thể được sử dụng để đếm số lần từ xuất hiện trong tài liệu.
Tóm tắt
Đây là tất cả về Hướng dẫn Hadoop MapReduce. Khung xử lý song song khối lượng dữ liệu khổng lồ trên toàn bộ cụm phần cứng hàng hóa. Nó chia công việc thành các nhiệm vụ độc lập và thực hiện chúng song song trên các nút khác nhau trong cụm.
MapReduce khắc phục điểm nghẽn của hệ thống doanh nghiệp truyền thống. Khung làm việc dựa trên các cặp khóa, giá trị. Người dùng xác định hai chức năng là chức năng bản đồ và chức năng thu gọn.
Logic nghiệp vụ được đưa vào chức năng bản đồ. Bài viết đã giải thích các khái niệm nâng cao khác nhau của khung MapReduce.



