Đánh giá mẫu kiến trúc phát trực tuyến nào phù hợp nhất với trường hợp sử dụng của bạn là điều kiện tiên quyết để triển khai sản xuất thành công.
Hệ sinh thái Apache Hadoop đã trở thành một nền tảng ưa thích cho các doanh nghiệp muốn xử lý và hiểu dữ liệu quy mô lớn trong thời gian thực. Các công nghệ như Apache Kafka, Apache Flume, Apache Spark, Apache Storm và Apache Samza đang ngày càng thúc đẩy những gì có thể xảy ra. Người ta thường muốn gộp các trường hợp sử dụng phát trực tuyến quy mô lớn lại với nhau nhưng trên thực tế, chúng có xu hướng chia nhỏ thành một vài mẫu kiến trúc khác nhau, với các thành phần khác nhau của hệ sinh thái phù hợp hơn với các vấn đề khác nhau.
Trong bài đăng này, tôi sẽ phác thảo bốn mô hình phát trực tuyến chính mà chúng tôi đã gặp phải với những khách hàng đang chạy trung tâm dữ liệu doanh nghiệp trong quá trình sản xuất và giải thích cách triển khai các mô hình đó theo kiến trúc trên Hadoop.
Các mẫu truyền trực tuyến
Bốn mô hình phát trực tuyến cơ bản (thường được sử dụng song song) là:
- Nhập luồng: Liên quan đến độ trễ thấp liên tục của các sự kiện đối với HDFS, Apache HBase và Apache Solr.
- Xử lý sự kiện gần thời gian thực (NRT) với bối cảnh bên ngoài: Thực hiện các hành động như cảnh báo, gắn cờ, chuyển đổi và lọc các sự kiện khi chúng đến. Các hành động có thể được thực hiện dựa trên các tiêu chí phức tạp, chẳng hạn như các mô hình phát hiện bất thường. Các trường hợp sử dụng phổ biến, chẳng hạn như đề xuất và phát hiện gian lận NRT, thường yêu cầu độ trễ thấp dưới 100 mili giây.
- Xử lý theo phân vùng sự kiện NRT: Tương tự như xử lý sự kiện NRT, nhưng thu được lợi ích từ việc phân vùng dữ liệu — như lưu trữ nhiều thông tin bên ngoài có liên quan hơn trong bộ nhớ. Mẫu này cũng yêu cầu độ trễ xử lý dưới 100 mili giây.
- Cấu trúc liên kết phức tạp cho các tổng hợp hoặc ML: Chén thánh xử lý luồng:nhận câu trả lời theo thời gian thực từ dữ liệu với một tập hợp hoạt động phức tạp và linh hoạt. Ở đây, vì kết quả thường phụ thuộc vào các phép tính trong cửa sổ và yêu cầu dữ liệu hoạt động nhiều hơn, trọng tâm sẽ chuyển từ độ trễ cực thấp sang chức năng và độ chính xác.
Trong các phần sau, chúng ta sẽ tìm hiểu các cách được đề xuất để triển khai các mẫu như vậy theo cách đã được thử nghiệm, chứng minh và có thể duy trì.
Nhập trực tuyến
Theo truyền thống, Flume là hệ thống được khuyến nghị để nhập trực tuyến. Thư viện lớn các nguồn và bồn rửa của nó bao gồm tất cả các cơ sở về những gì cần tiêu thụ và nơi để viết. (Để biết chi tiết về cách định cấu hình và quản lý Flume, Sử dụng Flume , cuốn sách O’Reilly Media của Kỹ sư phần mềm Cloudera / Hari Shreedharan, thành viên của Flume PMC, là một nguồn tài liệu tuyệt vời.)
Trong năm ngoái, Kafka cũng đã trở nên phổ biến vì các tính năng mạnh mẽ như phát lại và sao chép. Vì sự trùng lặp giữa các mục tiêu của Flume và Kafka, mối quan hệ của họ thường gây nhầm lẫn. Làm thế nào để chúng phù hợp với nhau? Câu trả lời rất đơn giản:Kafka là một đường ống tương tự như sự trừu tượng của Flume’s Channel, mặc dù là một đường ống tốt hơn vì nó hỗ trợ các tính năng được đề cập ở trên. Một cách tiếp cận phổ biến là sử dụng Flume cho nguồn và bồn rửa và Kafka cho đường ống giữa chúng.
Sơ đồ dưới đây minh họa cách Kafka có thể đóng vai trò là Nguồn dữ liệu luồng lên cho Flume, đích đến DownStream của Flume hoặc Kênh Flume.
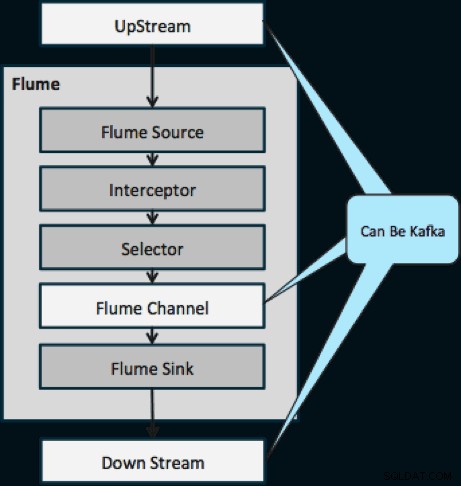
Thiết kế minh họa bên dưới có thể mở rộng quy mô lớn, chiến đấu mạnh mẽ, được giám sát tập trung thông qua Trình quản lý Cloudera, khả năng chịu lỗi và hỗ trợ phát lại.
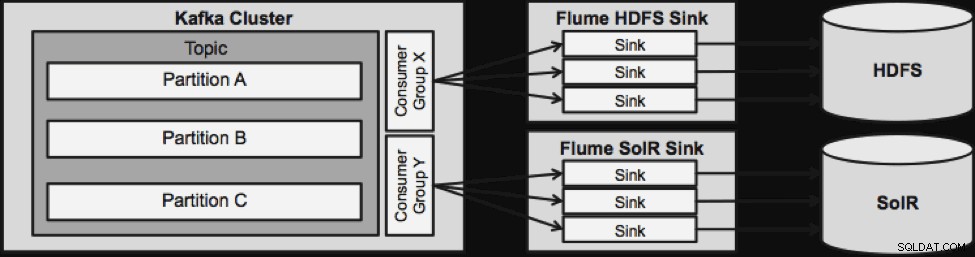
Một điều cần lưu ý trước khi chúng ta đi đến kiến trúc phát trực tuyến tiếp theo là cách thiết kế này xử lý lỗi một cách duyên dáng. Flume Sinks lấy từ Nhóm người tiêu dùng Kafka. Nhóm Người tiêu dùng theo dõi phần bù của Chủ đề với sự trợ giúp từ Apache ZooKeeper. Nếu một Chậu rửa chén bị mất, Người tiêu dùng Kafka sẽ phân phối lại tải cho các chậu rửa còn lại. Khi Flume Sink hoạt động trở lại, nhóm Người tiêu dùng sẽ phân phối lại một lần nữa.
Xử lý sự kiện NRT với ngữ cảnh bên ngoài
Để nhắc lại, một trường hợp sử dụng phổ biến cho mẫu này là xem xét các sự kiện đang diễn ra và đưa ra quyết định ngay lập tức, để chuyển đổi dữ liệu hoặc thực hiện một số loại hành động bên ngoài. Logic quyết định thường phụ thuộc vào cấu hình bên ngoài hoặc siêu dữ liệu. Một cách dễ dàng và có thể mở rộng để thực hiện phương pháp này là thêm một bộ đánh chặn Nguồn hoặc Chậu rửa vào kiến trúc Kafka / Flume của bạn. Với mức điều chỉnh khiêm tốn, không khó để đạt được độ trễ trong phần nghìn giây thấp.
Flume Interceptors nhận các sự kiện hoặc lô sự kiện và cho phép mã người dùng sửa đổi hoặc thực hiện các hành động dựa trên chúng. Mã người dùng có thể tương tác với bộ nhớ cục bộ hoặc hệ thống lưu trữ bên ngoài như HBase để lấy thông tin hồ sơ cần thiết cho các quyết định. HBase thường có thể cung cấp cho chúng tôi thông tin của chúng tôi trong khoảng 4-25 mili giây tùy thuộc vào mạng, thiết kế lược đồ và cấu hình. Bạn cũng có thể thiết lập HBase theo cách không bao giờ ngừng hoạt động hoặc bị gián đoạn, ngay cả trong trường hợp không thành công.
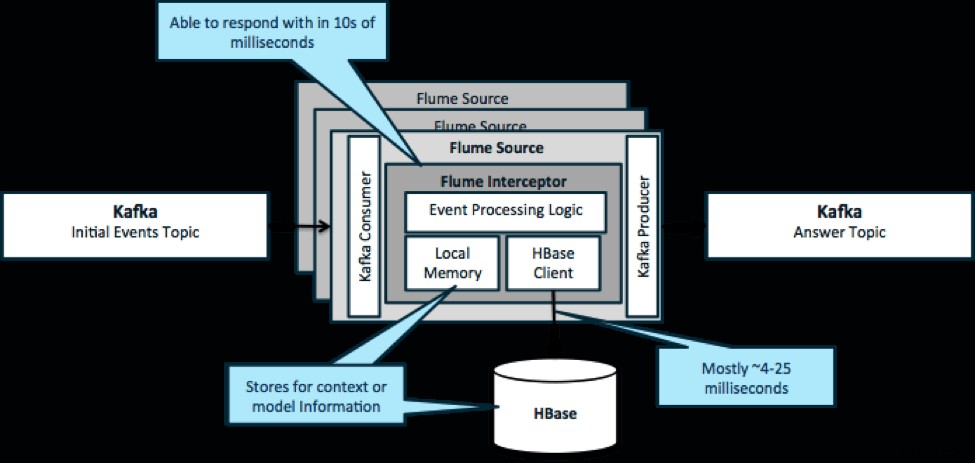
Việc triển khai gần như không yêu cầu mã hóa ngoài logic dành riêng cho ứng dụng trong bộ đánh chặn. Trình quản lý Cloudera cung cấp giao diện người dùng trực quan để triển khai logic này thông qua các bưu kiện cũng như kết nối, định cấu hình và giám sát các dịch vụ.
Xử lý sự kiện được phân vùng NRT với ngữ cảnh bên ngoài
Trong kiến trúc được minh họa bên dưới (giải pháp không phân vùng), bạn sẽ cần thường xuyên gọi đến HBase vì ngữ cảnh bên ngoài liên quan đến các sự kiện cụ thể không phù hợp với bộ nhớ cục bộ trên các bộ đánh chặn Flume.
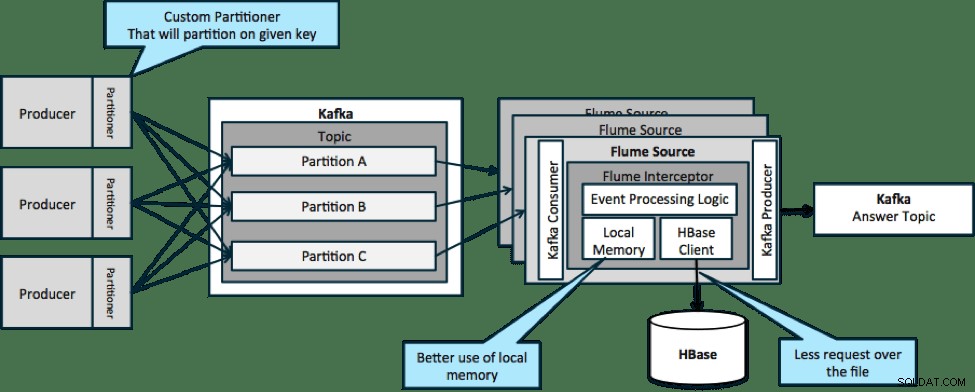
Tuy nhiên, nếu bạn xác định khóa để phân vùng dữ liệu của mình, bạn có thể khớp dữ liệu đến với tập hợp con dữ liệu ngữ cảnh có liên quan đến nó. Nếu bạn phân vùng dữ liệu 10 lần, thì bạn chỉ cần giữ 1/10 cấu hình trong bộ nhớ. HBase nhanh, nhưng bộ nhớ cục bộ nhanh hơn. Kafka cho phép bạn xác định một trình phân vùng tùy chỉnh mà nó sử dụng để chia nhỏ dữ liệu của bạn.
Lưu ý rằng Flume không hoàn toàn cần thiết ở đây; giải pháp gốc ở đây chỉ là người tiêu dùng Kafka. Vì vậy, bạn có thể chỉ sử dụng một người tiêu dùng trong YARN hoặc ứng dụng MapReduce chỉ dành cho Bản đồ.
Cấu trúc liên kết phức tạp cho tổng hợp hoặc ML
Cho đến thời điểm này, chúng tôi đang khám phá các hoạt động cấp sự kiện. Tuy nhiên, đôi khi bạn cần các hoạt động phức tạp hơn như số đếm, số trung bình, sự phân loại hoặc xây dựng mô hình học máy hoạt động trên các lô dữ liệu. Trong trường hợp này, Spark Streaming là công cụ lý tưởng vì một số lý do:
- Nó dễ phát triển so với các công cụ khác. Các API ngắn gọn và phong phú của Spark giúp việc xây dựng các cấu trúc liên kết phức tạp trở nên dễ dàng.
- Mã tương tự để phát trực tuyến và xử lý hàng loạt. Với một vài thay đổi, mã cho các lô nhỏ trong thời gian thực có thể được sử dụng cho các lô lớn ngoại tuyến. Ngoài việc giảm kích thước mã, phương pháp này còn giảm thời gian cần thiết để kiểm tra và tích hợp.
- Có một động cơ cần biết. Có một khoản chi phí dành cho việc đào tạo nhân viên về những điều kỳ quặc và nội bộ của các động cơ xử lý phân tán. Việc tiêu chuẩn hóa trên Spark sẽ hợp nhất chi phí này cho cả phát trực tuyến và hàng loạt.
- Theo dõi vi mô giúp bạn mở rộng quy mô một cách đáng tin cậy. Việc xác nhận ở cấp độ hàng loạt cho phép tăng thông lượng và cho phép đưa ra các giải pháp mà không sợ gửi hai lần. Tính năng phân phối vi mô cũng giúp gửi các thay đổi đối với HDFS hoặc HBase về hiệu suất trên quy mô lớn.
- Tích hợp hệ sinh thái Hadoop đã được triển khai. Spark tích hợp sâu với HDFS, HBase và Kafka.
- Không có nguy cơ mất dữ liệu. Nhờ có WAL và Kafka, Spark Streaming tránh được việc mất dữ liệu trong trường hợp bị lỗi.
- Dễ dàng gỡ lỗi và chạy. Bạn có thể gỡ lỗi và thực hiện từng bước trong mã Spark Streaming trong IDE cục bộ mà không cần cụm. Ngoài ra, mã này trông giống như mã lập trình chức năng bình thường nên không mất nhiều thời gian để nhà phát triển Java hoặc Scala thực hiện bước nhảy. (Python cũng được hỗ trợ.)
- Truyền trực tuyến ở trạng thái nguyên bản. Trong Spark Streaming, trạng thái là công dân hạng nhất, có nghĩa là bạn có thể dễ dàng viết các ứng dụng phát trực tuyến trạng thái có khả năng chống lại các lỗi nút.
- Theo tiêu chuẩn thực tế, Spark đang nhận được khoản đầu tư dài hạn từ khắp hệ sinh thái.
Tại thời điểm viết bài này, có khoảng 700 cam kết đối với Spark nói chung trong 30 ngày qua — so với các khung phát trực tuyến khác như Storm, với 15 cam kết trong cùng thời gian. - Bạn có quyền truy cập vào các thư viện ML.
Spark’s MLlib đang trở nên cực kỳ phổ biến và chức năng của nó sẽ ngày càng tăng lên. - Bạn có thể sử dụng SQL nếu cần.
Với Spark SQL, bạn có thể thêm logic SQL vào ứng dụng phát trực tuyến của mình để giảm độ phức tạp của mã.
Kết luận
Có rất nhiều sức mạnh trong việc phát trực tuyến và một số mẫu khả thi, nhưng như bạn đã học trong bài đăng này, bạn có thể làm những điều thực sự mạnh mẽ với mã hóa tối thiểu nếu bạn biết mẫu nào phù hợp nhất với trường hợp sử dụng của mình.
Ted Malaska là Kiến trúc sư giải pháp tại Cloudera, người đóng góp cho Spark, Flume và HBase, đồng thời là đồng tác giả của cuốn sách O’Reilly, Kiến trúc ứng dụng Hadoop .



