Trong hướng dẫn Hadoop này , chúng tôi sẽ cung cấp cho bạn phần giới thiệu đầy đủ về Cặp giá trị chính của MapReduce.
Trước hết chúng ta sẽ thảo luận về cặp giá trị khóa trong Hadoop là gì, Cách tạo cặp giá trị khóa trong MapReduce. Cuối cùng, chúng tôi sẽ giải thích việc tạo cặp giá trị khóa MapReduce với các ví dụ.
Cặp giá trị chính trong Hadoop là gì?
Cặp khóa-giá trị trong MapReduce là thực thể bản ghi mà Hadoop MapReduce chấp nhận để thực thi.
Chúng tôi sử dụng Hadoop chủ yếu để phân tích dữ liệu. Nó xử lý dữ liệu có cấu trúc, phi cấu trúc và bán cấu trúc. Với Hadoop, nếu lược đồ là tĩnh, chúng ta có thể làm việc trực tiếp trên cột thay vì giá trị khóa. Tuy nhiên, nếu lược đồ không tĩnh, chúng tôi sẽ làm việc trên một giá trị khóa.
Giá trị khóa không phải là thuộc tính nội tại của dữ liệu. Nhưng chúng được chọn bởi người dùng phân tích dữ liệu.
MapReduce là thành phần cốt lõi của Hadoop, cung cấp khả năng xử lý dữ liệu. Nó thực hiện xử lý bằng cách chia công việc thành hai giai đoạn: Giai đoạn lập bản đồ và Giảm giai đoạn . Mỗi pha có khóa-giá trị làm đầu vào và đầu ra.
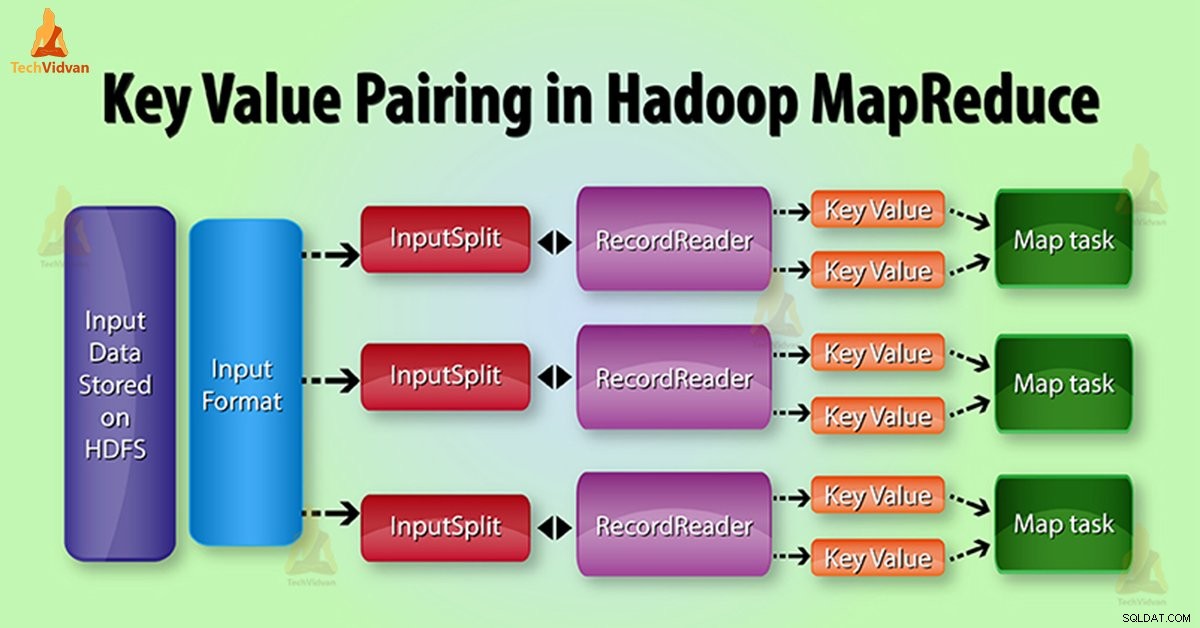
MapReduce Tạo cặp giá trị khóa trong Hadoop
Trong thực thi công việc MapReduce, trước khi gửi dữ liệu đến trình ánh xạ , trước tiên hãy chuyển nó thành các cặp khóa-giá trị. Bởi vì ánh xạ chỉ các cặp dữ liệu khóa-giá trị.
Cặp khóa-giá trị trong MapReduce được tạo như sau:
InputSplit - Đây là biểu diễn logic của dữ liệu mà InputFormat tạo ra. Trong chương trình MapReduce, nó mô tả một đơn vị công việc có chứa một nhiệm vụ bản đồ duy nhất.
RecordReader - Nó giao tiếp với InputSplit. Sau đó, nó chuyển đổi dữ liệu thành các cặp giá trị khóa phù hợp để Mapper đọc. RecordReader theo mặc định sử dụng TextInputFormat để chuyển đổi dữ liệu thành các cặp giá trị khóa.
Trong thực thi công việc MapReduce, hàm bản đồ xử lý một cặp khóa-giá trị nhất định. Sau đó, phát ra một số cặp khóa-giá trị nhất định. Hàm Reduce xử lý các giá trị được nhóm theo cùng một khóa.
Sau đó, phát ra một tập hợp các cặp khóa-giá trị khác làm đầu ra. Các loại đầu ra của Bản đồ phải khớp với các loại đầu vào của Reduce như được hiển thị bên dưới:
- Bản đồ: (K1, V1) -> danh sách (K2, V2)
- Giảm: {(K2, danh sách (V2}) -> danh sách (K3, V3)
Cặp khóa-giá trị được tạo trong Hadoop trên cơ sở nào?
MapReduce Việc tạo cặp khóa-giá trị hoàn toàn phụ thuộc vào tập dữ liệu. Cũng phụ thuộc vào sản lượng yêu cầu. Khung chỉ định cặp khóa-giá trị ở 4 vị trí:Đầu vào / đầu ra của bản đồ, Giảm đầu vào / đầu ra.
1. Nhập bản đồ
Nhập bản đồ theo mặc định lấy độ lệch dòng làm khóa. Nội dung của dòng có giá trị là Văn bản. Chúng tôi có thể sửa đổi chúng; bằng cách sử dụng định dạng đầu vào tùy chỉnh.
2. Đầu ra bản đồ
Bản đồ có nhiệm vụ lọc dữ liệu. Nó cũng cung cấp môi trường để nhóm dữ liệu trên cơ sở khóa.
- Chìa khóa– Đây là trường / văn bản / đối tượng mà trên đó các nhóm dữ liệu và tổng hợp trên trình thu gọn .
- Giá trị– Đây là trường / văn bản / đối tượng mà mỗi cá nhân giảm bớt phương thức xử lý.
3. Giảm đầu vào
Đầu ra bản đồ là đầu vào để giảm bớt. Vì vậy, nó giống với Map-Output.
4. Giảm sản lượng
Nó hoàn toàn phụ thuộc vào đầu ra được yêu cầu.
Ví dụ về cặp khóa-giá trị MapReduce
Ví dụ:nội dung của tệp HDFS cửa hàng là Chandler là Joey Mark là John . Vì vậy, bây giờ bằng cách sử dụng InputFormat, chúng tôi sẽ xác định cách tệp này sẽ phân chia và đọc. Theo mặc định, RecordReader sử dụng TextInputFormat để chuyển đổi tệp này thành một cặp khóa-giá trị.
- Chìa khóa - Nó được bù vào đầu dòng trong tệp.
- Giá trị - Đó là nội dung của dòng, không bao gồm các dấu cuối dòng.
Đây, Chìa khóa là 0 và Giá trị là Chandler là Joey Mark là John.
Kết luận
Tóm lại, chúng ta có thể nói rằng, khóa-giá trị chỉ là một thực thể bản ghi mà MapReduce chấp nhận để thực thi. InputSplit và RecordReader tạo ra cặp Khóa-giá trị. Do đó, khóa là độ lệch byte và giá trị là nội dung của dòng.
Hy vọng bạn thích blog này. Nếu bạn có bất kỳ đề xuất hoặc truy vấn nào liên quan đến cặp giá trị khóa MapReduce, vui lòng để lại nhận xét trong phần đưa ra bên dưới.



