Mục tiêu chính của Hướng dẫn Hadoop này là cung cấp cho bạn mô tả chi tiết về từng thành phần được sử dụng trong hoạt động của Hadoop. Trong hướng dẫn này, chúng tôi sẽ đề cập đến Trình phân vùng trong Hadoop.
Hadoop Partitioner là gì, nhu cầu của Partitioner trong Hadoop là gì, Partitioner mặc định trong MapReduce là gì, Có bao nhiêu MapReduce Partitioner được sử dụng trong Hadoop?
Chúng tôi sẽ trả lời tất cả những câu hỏi này trong hướng dẫn MapReduce này.
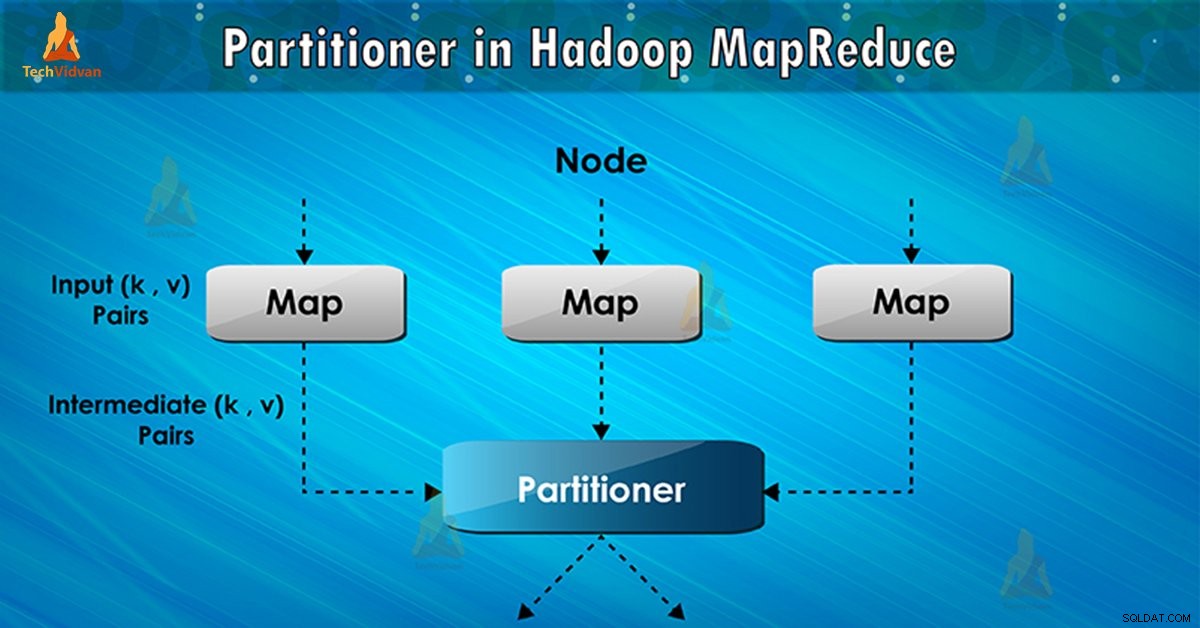
Hadoop Partitioner là gì?
Partitioner trong MapReduce thực thi công việc kiểm soát việc phân vùng các khóa của các đầu ra bản đồ trung gian. Với sự trợ giúp của hàm băm, khóa (hoặc một tập hợp con của khóa) dẫn xuất phân vùng. Tổng số phân vùng bằng số tác vụ thu gọn.
Trên cơ sở giá trị quan trọng , phân vùng khung, mỗi trình ánh xạ đầu ra. Các bản ghi có cùng giá trị khóa sẽ đi vào cùng một phân vùng (trong mỗi trình ánh xạ). Sau đó, mỗi phân vùng được gửi đến một trình giảm thiểu .
Lớp phân vùng quyết định phân vùng nào mà một cặp (khóa, giá trị) nhất định sẽ đi. Giai đoạn phân vùng trong luồng dữ liệu MapReduce diễn ra sau giai đoạn bản đồ và trước giai đoạn rút gọn.
Cần có MapReduce Partitioner trong Hadoop
Trong thực thi công việc MapReduce, nó lấy một tập dữ liệu đầu vào và tạo ra danh sách cặp giá trị khóa. Cặp khóa-giá trị này là kết quả của giai đoạn bản đồ. Trong đó dữ liệu đầu vào được phân tách và mỗi tác vụ sẽ xử lý quá trình phân tách và mỗi bản đồ, xuất ra danh sách các cặp giá trị chính.
Sau đó, khung công tác gửi đầu ra bản đồ để giảm tác vụ. Giảm các quy trình mà chức năng giảm do người dùng xác định trên kết quả đầu ra của bản đồ. Trước giai đoạn rút gọn, việc phân vùng đầu ra bản đồ diễn ra trên cơ sở khóa.
Phân vùng Hadoop chỉ định rằng tất cả các giá trị cho mỗi khóa được nhóm lại với nhau. Nó cũng đảm bảo rằng tất cả các giá trị của một khóa đi đến cùng một bộ giảm. Điều này cho phép phân phối đồng đều đầu ra bản đồ qua bộ giảm tốc.
Trình phân vùng trong một công việc MapReduce chuyển hướng đầu ra của trình ánh xạ tới trình giảm tốc bằng cách xác định trình giảm thiểu nào xử lý khóa cụ thể.
Trình phân vùng mặc định Hadoop
Trình phân vùng băm là Trình phân vùng mặc định. Nó tính giá trị băm cho khóa. Nó cũng chỉ định phân vùng dựa trên kết quả này.
Có bao nhiêu phân vùng trong Hadoop?
Tổng số Bộ phân vùng phụ thuộc vào số bộ giảm. Hadoop Partitioner phân chia dữ liệu theo số lượng bộ giảm. Nó được đặt bởi JobConf.setNumReduceTasks () phương pháp.
Do đó, bộ giảm tốc đơn xử lý dữ liệu từ bộ phân vùng duy nhất. Điều quan trọng cần lưu ý là khung công tác chỉ tạo bộ phân vùng khi có nhiều bộ giảm bớt.
Phân vùng kém trong Hadoop MapReduce
Nếu trong phần nhập dữ liệu trong công việc MapReduce, một phím xuất hiện nhiều hơn bất kỳ phím nào khác. Trong trường hợp này, để gửi dữ liệu đến phân vùng, chúng tôi sử dụng hai cơ chế như sau:
- Khóa xuất hiện nhiều lần hơn sẽ được gửi đến một phân vùng.
- Tất cả khóa khác sẽ được gửi đến các phân vùng trên cơ sở Mã băm () của chúng .
Nếu Mã băm () phương thức không phân phối dữ liệu quan trọng khác trên phạm vi phân vùng. Sau đó, dữ liệu sẽ không được gửi đến bộ giảm tốc.
Việc phân vùng dữ liệu kém có nghĩa là một số bộ giảm sẽ có nhiều dữ liệu đầu vào hơn so với bộ khác. Chúng sẽ có nhiều việc phải làm hơn các bộ giảm tốc khác. Do đó, toàn bộ công việc phải đợi một bộ giảm tốc hoàn thành phần tải cực lớn của nó.
Làm cách nào để khắc phục tình trạng phân vùng kém trong MapReduce?
Để khắc phục trình phân vùng kém trong Hadoop MapReduce, chúng ta có thể tạo Trình phân vùng tùy chỉnh. Điều này cho phép chia sẻ khối lượng công việc qua các bộ giảm khác nhau.
Kết luận
Tóm lại, Bộ phân vùng cho phép phân phối đồng nhất đầu ra bản đồ trên bộ giảm tốc. Trong MapReducer Partitioner, phân vùng đầu ra bản đồ diễn ra trên cơ sở khóa và giá trị.
Do đó, chúng tôi đã trình bày toàn bộ tổng quan về Partitioner trong blog này. Hy vọng bạn thích nó. Nếu bạn có bất kỳ nghi ngờ nào về Hadoop Partitioner, đừng quên chia sẻ với chúng tôi.



