Trong Hướng dẫn Hadoop trước đây của chúng tôi o rial , chúng tôi đã cung cấp cho bạn mô tả chi tiết về InputFormat. Bây giờ trong blog này, chúng ta sẽ đề cập đến Hadoop OutputFormat.
Chúng ta sẽ thảo luận về OutputFormat trong Hadoop là gì, RecordWritter trong MapReduce OutputFormat là gì. Chúng tôi cũng sẽ đề cập đến các loại OutputFormat trong MapReduce.
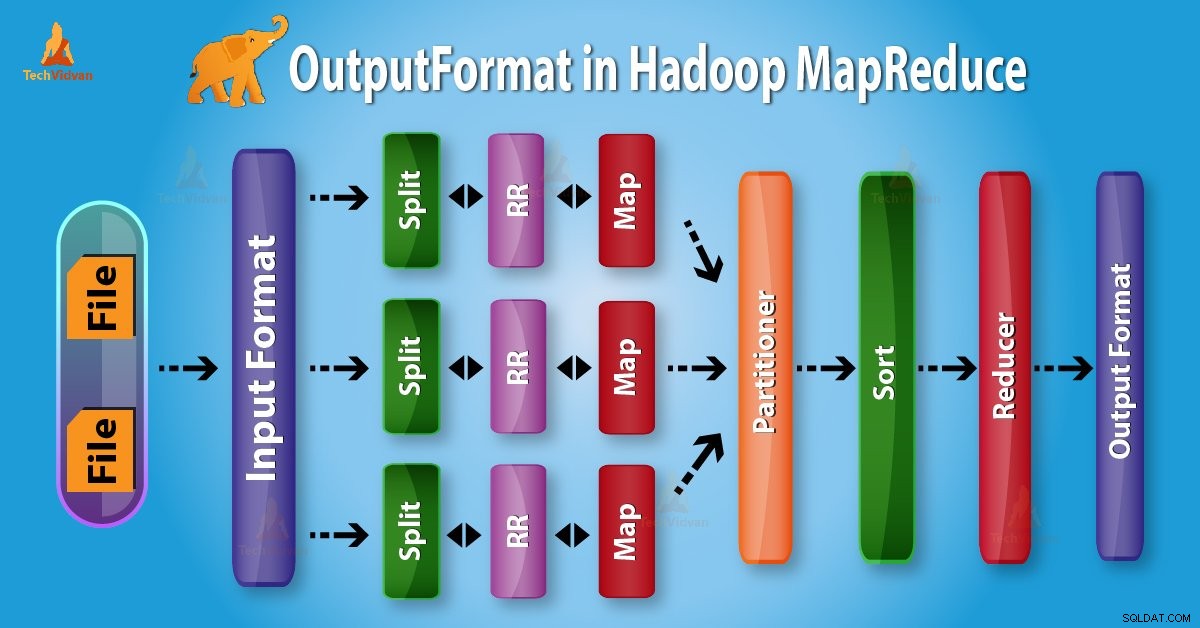
Giới thiệu về Hadoop OutputFormat
Định dạng đầu ra kiểm tra đặc tả đầu ra để thực hiện công việc Map-Reduce. Nó mô tả cách triển khai RecordWriter được sử dụng để ghi đầu ra vào các tệp đầu ra.
Trước khi bắt đầu với OutputFormat, trước tiên chúng ta hãy tìm hiểu RecordWriter là gì và công việc của RecordWriter trong MapReduce là gì?
1. RecordWriter trong Hadoop MapReduce
Như chúng ta đã biết, Hộp giảm tốc lấy Người lập bản đồ đầu ra trung gian như đầu vào. Sau đó, nó chạy một hàm giảm thiểu trên chúng để tạo ra kết quả đầu ra một lần nữa bằng không hoặc nhiều cặp khóa-giá trị.
Vì vậy, RecordWriter trong thực thi công việc MapReduce ghi các cặp khóa-giá trị đầu ra này từ giai đoạn Bộ giảm để xuất tệp.
2. Hadoop OutputFormat
Từ trên, rõ ràng là RecordWriter lấy dữ liệu đầu ra từ Reducer. Sau đó, nó ghi dữ liệu này vào các tệp đầu ra. OutputFormat xác định cách các cặp khóa-giá trị đầu ra này được ghi trong tệp đầu ra bởi RecordWriter.
Các chức năng OutputFormat và InputFormat tương tự nhau. Các phiên bản OutputFormat được sử dụng để ghi vào tệp trên đĩa cục bộ hoặc trong HDFS. Trong MapReduce thực hiện công việc trên cơ sở đặc tả đầu ra;
- Công việc Hadoop MapReduce kiểm tra xem thư mục đầu ra chưa có mặt.
- OutputFormat trong công việc MapReduce cung cấp triển khai RecordWriter được sử dụng để ghi các tệp đầu ra của công việc. Sau đó, các tệp đầu ra được lưu trữ trong Hệ thống tệp.
Khung sử dụng FileOutputFormat.setOutputPath () phương pháp đặt thư mục đầu ra.
Các loại định dạng đầu ra trong MapReduce
Có nhiều loại OutputFormat như sau:
1. TextOutputFormat
OutputFormat mặc định là TextOutputFormat. Nó ghi các cặp (khóa, giá trị) trên các dòng riêng lẻ của tệp văn bản. Các khóa và giá trị của nó có thể thuộc bất kỳ loại nào. Lý do đằng sau là TextOutputFormat biến chúng thành chuỗi bằng cách gọi toString () trên chúng.
Nó phân tách cặp khóa-giá trị bằng một ký tự tab. Bằng cách sử dụng MapReduce.output.textoutputformat.separator chúng tôi cũng có thể thay đổi nó.
KeyValueTextOutputFormat cũng được sử dụng để đọc các tệp văn bản đầu ra này.
2. SequenceFileOutputFormat
OutputFormat này ghi các tệp tuần tự cho đầu ra của nó. SequenceFileInputFormat cũng là định dạng trung gian sử dụng giữa các công việc MapReduce. Nó tuần tự hóa các kiểu dữ liệu tùy ý vào tệp.
Và SequenceFileInputFormat tương ứng sẽ giải mã hóa tệp thành các loại giống nhau. Nó trình bày dữ liệu cho người lập bản đồ tiếp theo theo cách tương tự như nó được phát ra bởi bộ giảm tốc trước đó. Các phương thức tĩnh cũng kiểm soát quá trình nén.
3. SequenceFileAsBinaryOutputFormat
Nó là một biến thể khác của SequenceFileInputFormat. Nó cũng ghi các khóa và giá trị vào tệp chuỗi ở định dạng nhị phân.
4. MapFileOutputFormat
Nó là một dạng khác của FileOutputFormat. Nó cũng ghi đầu ra dưới dạng tệp bản đồ. Khung công tác thêm một khóa trong MapFile theo thứ tự. Vì vậy, chúng tôi cần đảm bảo rằng trình giảm tốc phát ra các khóa theo thứ tự được sắp xếp.
5. MultipleOutputs
Định dạng này cho phép ghi dữ liệu vào các tệp có tên bắt nguồn từ các khóa và giá trị đầu ra.
6. LazyOutputFormat
Trong thực thi công việc MapReduce, đôi khi FileOutputFormat tạo các tệp đầu ra, ngay cả khi chúng trống. LazyOutputFormat cũng là một OutputFormat bao bọc.
7. DBOutputFormat
Nó là OutputFormat để ghi vào cơ sở dữ liệu quan hệ và HBase. Định dạng này cũng gửi kết quả giảm xuống một bảng SQL. Nó cũng chấp nhận các cặp khóa-giá trị. Trong đó, khóa có kiểu mở rộng DBw Khả năng ghi.
Kết luận
Do đó, các Định dạng đầu ra khác nhau được sử dụng tùy theo nhu cầu. Hy vọng bạn thấy blog này hữu ích. Nếu bạn có bất kỳ câu hỏi nào về Hadoop OutputFormat, vì vậy hãy để lại nhận xét trong một khung bình luận. Chúng tôi sẽ rất vui khi giải quyết chúng.



