Hướng dẫn Hadoop này là tất cả về MapReduce Shuffling and Sorting. Tại đây, chúng tôi sẽ cung cấp cho bạn mô tả chi tiết về giai đoạn Xáo trộn và Sắp xếp Hadoop.
Đầu tiên chúng ta sẽ thảo luận về MapReduce Shuffling là gì, tiếp theo với MapReduce Sorting, sau đó chúng ta sẽ trình bày chi tiết về giai đoạn sắp xếp thứ cấp của MapReduce.
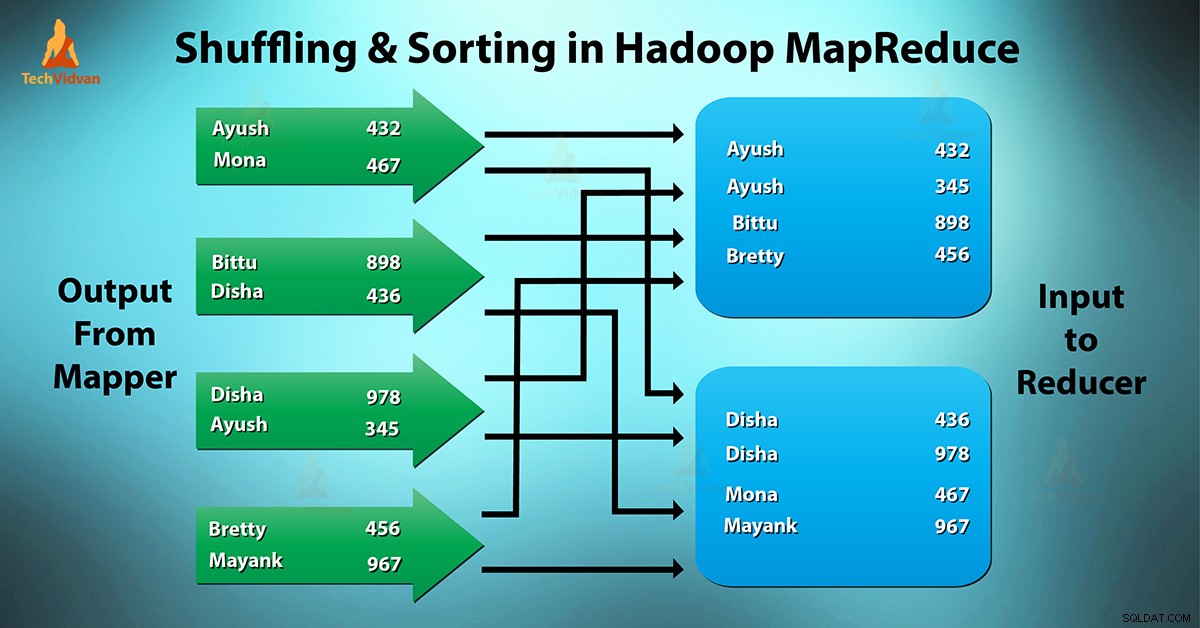
MapReduce Shuffling and Sorting là gì?
Phát ngẫu nhiên là quá trình nó chuyển người lập bản đồ đầu ra trung gian cho bộ giảm tốc. Bộ giảm tốc nhận được 1 hoặc nhiều khóa và các giá trị liên quan trên cơ sở bộ giảm tốc.
Khóa trung gian - giá trị do trình ánh xạ tạo ra được sắp xếp tự động theo khóa. Trong giai đoạn Sắp xếp, việc hợp nhất và sắp xếp đầu ra bản đồ diễn ra.
Xáo trộn và Sắp xếp trong Hadoop xảy ra đồng thời.
Xáo trộn trong MapReduce
Quá trình chuyển dữ liệu từ bộ lập bản đồ sang bộ giảm thiểu đang xáo trộn. Nó cũng là quá trình hệ thống thực hiện việc sắp xếp. Sau đó, nó chuyển đầu ra bản đồ đến bộ giảm tốc như đầu vào. Đây là lý do giai đoạn xáo trộn là cần thiết cho các bộ giảm tốc.
Nếu không, họ sẽ không có bất kỳ đầu vào nào (hoặc đầu vào từ mọi người lập bản đồ). Vì xáo trộn có thể bắt đầu ngay cả trước khi giai đoạn bản đồ kết thúc. Vì vậy, điều này giúp tiết kiệm một chút thời gian và hoàn thành nhiệm vụ trong thời gian ngắn hơn.
Sắp xếp trong MapReduce
MapReduce Framework tự động sắp xếp các khóa do trình ánh xạ tạo ra. Do đó, trước khi bắt đầu giảm tốc, tất cả các cặp khóa-giá trị trung gian được sắp xếp theo khóa chứ không phải theo giá trị. Nó không sắp xếp các giá trị được truyền cho mỗi bộ giảm tốc. Chúng có thể theo bất kỳ thứ tự nào.
Việc sắp xếp trong một công việc MapReduce giúp bộ giảm thiểu dễ dàng phân biệt khi nào một tác vụ giảm mới sẽ bắt đầu.
Điều này giúp tiết kiệm thời gian cho bộ giảm tốc. Giảm trong MapReduce bắt đầu một tác vụ giảm mới khi khóa tiếp theo trong dữ liệu đầu vào được sắp xếp khác với khóa trước đó. Mỗi tác vụ giảm nhận các cặp giá trị khóa làm đầu vào và tạo cặp khóa-giá trị làm đầu ra.
Điều quan trọng cần lưu ý là việc xáo trộn và sắp xếp trong Hadoop MapReduce sẽ hoàn toàn không diễn ra nếu bạn chỉ định 0 bộ giảm (setNumReduceTasks (0)).
Nếu bộ giảm tốc bằng 0, thì công việc MapReduce dừng lại ở giai đoạn bản đồ. Và giai đoạn bản đồ không bao gồm bất kỳ loại sắp xếp nào (thậm chí giai đoạn bản đồ còn nhanh hơn).
Sắp xếp thứ cấp trong MapReduce
Nếu chúng ta muốn sắp xếp các giá trị rút gọn, thì chúng ta sử dụng kỹ thuật sắp xếp thứ cấp. Kỹ thuật này cho phép chúng tôi sắp xếp các giá trị (theo thứ tự tăng dần hoặc giảm dần) được chuyển cho mỗi bộ giảm thiểu.
Kết luận
Tóm lại, MapReduce Shuffling và Sorting xảy ra đồng thời để tóm tắt kết quả trung gian của Mapper. Hadoop Shuffling-Sorting sẽ không diễn ra nếu bạn chỉ định 0 bộ giảm (setNumReduceTasks (0)).
Framework sắp xếp tất cả các cặp khóa-giá trị trung gian theo khóa, không phải theo giá trị. Nó sử dụng phân loại thứ cấp để phân loại theo giá trị. Nếu bạn có bất kỳ đề xuất hoặc truy vấn nào liên quan đến giai đoạn Phát ngẫu nhiên và Sắp xếp MapReduce, vui lòng để lại nhận xét trong ô bình luận.
Chúng tôi sẽ sẵn lòng giải quyết chúng.



