Trong Hadoop trước đây của chúng tôi blog mà chúng tôi đã nghiên cứu từng thành phần của Hadoop Quy trình MapReduce chi tiết. Trong phần này, chúng ta sẽ thảo luận về chủ đề rất thú vị, đó là công việc Chỉ bản đồ trong Hadoop.
Trước tiên, chúng tôi sẽ giới thiệu ngắn gọn về Bản đồ và Giảm trong Hadoop Mapreduce, sau đó chúng ta sẽ thảo luận về công việc Chỉ bản đồ trong Hadoop MapReduce là gì.
Cuối cùng, chúng ta cũng sẽ thảo luận về những ưu điểm và nhược điểm của công việc Hadoop Map Only trong hướng dẫn này.
Hadoop Map Only Job là gì?
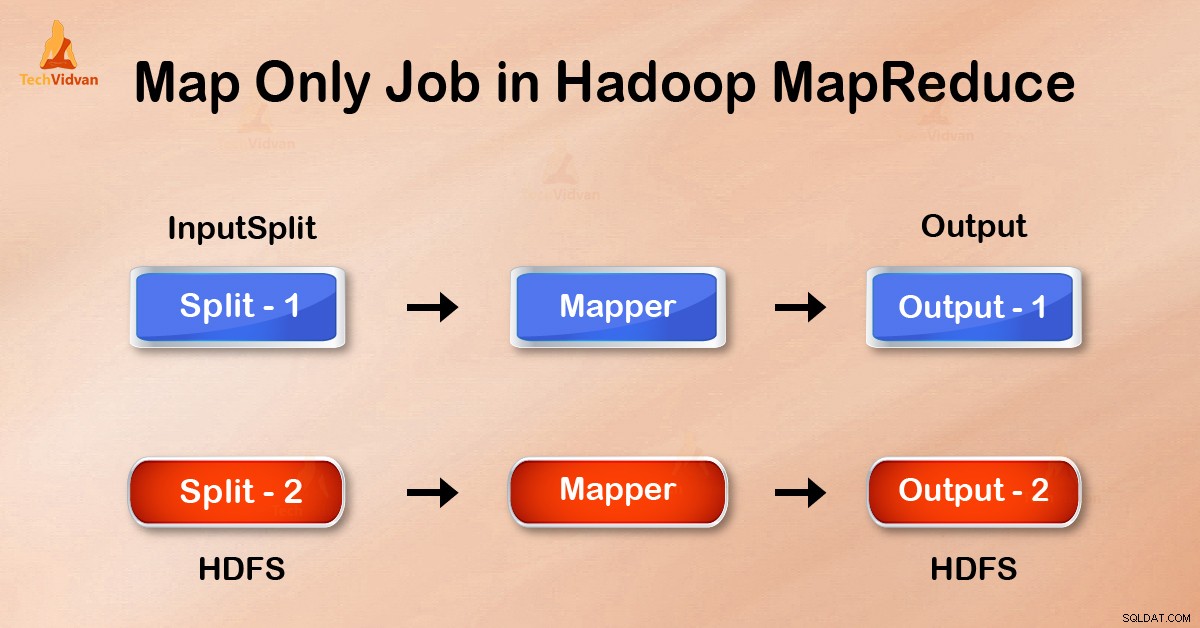
Công việc chỉ trên bản đồ trong Hadoop là quá trình trong đó người lập bản đồ thực hiện tất cả các nhiệm vụ. Không có tác vụ nào được thực hiện bởi bộ giảm tốc . Đầu ra của người lập bản đồ là đầu ra cuối cùng.
MapReduce là lớp xử lý dữ liệu của Hadoop. Nó xử lý dữ liệu lớn có cấu trúc và không có cấu trúc được lưu trữ trong HDFS . MapReduce cũng xử lý song song một lượng lớn dữ liệu.
Nó thực hiện điều này bằng cách chia công việc (công việc đã nộp) thành một tập hợp các nhiệm vụ độc lập (công việc phụ). Trong Hadoop, MapReduce hoạt động bằng cách chia quá trình thành các giai đoạn: Bản đồ và Giảm .
- Bản đồ: Đây là giai đoạn đầu tiên của quá trình xử lý, nơi chúng tôi chỉ định tất cả các mã logic phức tạp. Nó nhận một tập hợp dữ liệu và chuyển đổi thành một tập dữ liệu khác. Nó chia từng phần tử riêng lẻ thành các bộ giá trị ( cặp khóa-giá trị ).
- Giảm: Đây là giai đoạn thứ hai của quá trình xử lý. Ở đây chúng tôi chỉ định xử lý trọng lượng nhẹ như tổng hợp / tổng kết. Nó lấy đầu ra từ bản đồ làm đầu vào. Sau đó, nó kết hợp các bộ giá trị đó dựa trên khóa.
Từ ví dụ đếm từ này, chúng ta có thể nói rằng có hai nhóm quy trình song song, bản đồ và giảm bớt. Trong quá trình lập bản đồ, đầu vào đầu tiên được tách ra để phân phối công việc giữa tất cả các nút bản đồ như được hiển thị ở trên.
Sau đó, khung công tác xác định từng từ và ánh xạ tới số 1. Do đó, nó tạo ra các cặp được gọi là cặp bộ giá trị (khóa-giá trị).
Trong nút ánh xạ đầu tiên, nó chuyển ba từ sư tử, hổ và sông. Do đó, nó tạo ra 3 cặp khóa-giá trị như là đầu ra của nút. Ba khóa và giá trị khác nhau được đặt thành 1 và quá trình tương tự lặp lại cho tất cả các nút.
Sau đó, nó chuyển các bộ giá trị này đến các nút giảm tốc. Trình phân vùng thực hiện xáo trộn để tất cả các bộ giá trị có cùng một khóa đi đến cùng một nút.
Trong quá trình rút gọn, điều cơ bản xảy ra là tập hợp các giá trị hay đúng hơn là một phép toán trên các giá trị có cùng khóa.
Bây giờ, chúng ta hãy xem xét một kịch bản mà chúng ta chỉ cần thực hiện thao tác. Chúng tôi không cần tổng hợp, trong trường hợp như vậy, chúng tôi sẽ thích ‘ công việc Chỉ bản đồ '.
Trong công việc Chỉ bản đồ, bản đồ thực hiện tất cả các tác vụ với InputSplit . Hộp giảm tốc không hoạt động. Đầu ra của người lập bản đồ là đầu ra cuối cùng.
Làm cách nào để tránh Giảm pha trong MapReduce?
Bằng cách đặt job.setNumreduceTasks (0) trong cấu hình trong trình điều khiển, chúng tôi có thể tránh giảm giai đoạn. Điều này sẽ làm cho một số giảm bớt là 0 . Do đó, người lập bản đồ duy nhất sẽ thực hiện nhiệm vụ hoàn chỉnh.
Ưu điểm của công việc Chỉ bản đồ trong Hadoop
Trong MapReduce thực hiện công việc giữa các giai đoạn của bản đồ và giảm có giai đoạn chính, sắp xếp và xáo trộn. Xáo trộn – Sắp xếp chịu trách nhiệm sắp xếp các khóa theo thứ tự tăng dần. Sau đó, nhóm các giá trị dựa trên các khóa giống nhau. Giai đoạn này rất tốn kém.
Nếu pha giảm là không cần thiết, chúng ta nên tránh nó. Vì tránh pha giảm cũng sẽ loại bỏ giai đoạn sắp xếp và xáo trộn. Do đó, điều này cũng sẽ giúp giảm tắc nghẽn mạng.
Lý do là trong quá trình xáo trộn, một đầu ra của trình ánh xạ sẽ giảm. Và khi kích thước dữ liệu lớn, dữ liệu lớn cần được chuyển đến bộ giảm tốc.
Đầu ra của trình ánh xạ được ghi vào đĩa cục bộ trước khi gửi để giảm bớt. Nhưng trong công việc chỉ bản đồ, đầu ra này được ghi trực tiếp vào HDFS. Điều này tiếp tục tiết kiệm thời gian cũng như giảm chi phí.
Kết luận
Do đó, chúng tôi đã thấy rằng công việc Map-only làm giảm tắc nghẽn mạng bằng cách tránh xáo trộn, sắp xếp và giảm giai đoạn. Bản đồ một mình đảm nhận việc xử lý tổng thể và tạo ra đầu ra. BẰNG CÁCH sử dụng job.setNumreduceTasks (0) điều này đạt được.
Tôi hy vọng bạn đã hiểu công việc của Chỉ bản đồ Hadoop và tầm quan trọng của nó vì chúng tôi đã đề cập đến mọi thứ về công việc Chỉ bản đồ trong Hadoop. Nhưng nếu bạn có bất kỳ thắc mắc nào, bạn có thể chia sẻ với chúng tôi trong phần bình luận.



