MongoDB là cơ sở dữ liệu NoSQL hỗ trợ nhiều nguồn tập dữ liệu đầu vào. Nó có thể lưu trữ dữ liệu trong các tài liệu giống JSON linh hoạt, có nghĩa là các trường hoặc siêu dữ liệu có thể khác nhau giữa các tài liệu và cấu trúc dữ liệu có thể thay đổi theo thời gian. Mô hình tài liệu giúp dữ liệu dễ làm việc bằng cách ánh xạ tới các đối tượng trong mã ứng dụng. MongoDB còn được gọi là cơ sở dữ liệu phân tán ở cốt lõi của nó, do đó tính khả dụng cao, khả năng mở rộng theo chiều ngang và phân phối địa lý được tích hợp sẵn và dễ sử dụng. Nó đi kèm với khả năng sửa đổi liên tục các thông số để đào tạo mô hình. Các nhà khoa học dữ liệu có thể dễ dàng hợp nhất cấu trúc dữ liệu với việc tạo mô hình này.
Học máy là gì?
Machine Learning là khoa học giúp máy tính học và hoạt động giống như con người và cải thiện việc học của chúng theo thời gian theo cách tự trị. Quá trình học tập bắt đầu với các quan sát hoặc dữ liệu, chẳng hạn như ví dụ, kinh nghiệm trực tiếp hoặc hướng dẫn, để tìm kiếm các mẫu trong dữ liệu và đưa ra quyết định tốt hơn trong tương lai dựa trên các ví dụ mà chúng tôi cung cấp. Mục đích chính là cho phép máy tính học tự động mà không cần sự can thiệp hoặc trợ giúp của con người và điều chỉnh các hành động cho phù hợp.
Mô hình truy vấn và lập trình phong phú
MongoDB cung cấp cả trình điều khiển gốc và trình kết nối được chứng nhận cho các nhà phát triển và nhà khoa học dữ liệu xây dựng mô hình học máy với dữ liệu từ MongoDB. PyMongo là một thư viện tuyệt vời để nhúng cú pháp MongoDB vào mã Python. Chúng tôi có thể nhập tất cả các chức năng và phương thức của MongoDB để sử dụng chúng trong mã học máy của chúng tôi. Đó là một kỹ thuật tuyệt vời để có được chức năng đa ngôn ngữ trong một mã duy nhất. Lợi thế bổ sung là bạn có thể sử dụng các tính năng thiết yếu của các ngôn ngữ lập trình đó để tạo một ứng dụng hiệu quả.
Ngôn ngữ truy vấn MongoDB với các chỉ mục phụ phong phú cho phép các nhà phát triển xây dựng các ứng dụng có thể truy vấn và phân tích dữ liệu theo nhiều chiều. Dữ liệu có thể được truy cập bằng các khóa đơn, phạm vi, tìm kiếm văn bản, biểu đồ và truy vấn không gian địa lý thông qua các tổng hợp phức tạp và công việc MapReduce, trả lại phản hồi trong mili giây.
Để xử lý dữ liệu song song trên một cụm cơ sở dữ liệu phân tán, MongoDB cung cấp đường dẫn tổng hợp và MapReduce. Đường ống tổng hợp MongoDB được mô hình hóa theo khái niệm đường ống xử lý dữ liệu. Tài liệu đi vào một đường dẫn nhiều giai đoạn để chuyển tài liệu thành kết quả tổng hợp bằng cách sử dụng các phép toán gốc được thực thi trong MongoDB. Các giai đoạn đường ống cơ bản nhất cung cấp các bộ lọc hoạt động giống như các truy vấn và các phép biến đổi tài liệu để sửa đổi hình thức của tài liệu đầu ra. Các hoạt động đường ống khác cung cấp các công cụ để nhóm và phân loại tài liệu theo các trường cụ thể cũng như các công cụ để tổng hợp nội dung của mảng, bao gồm cả mảng tài liệu. Ngoài ra, các giai đoạn đường ống có thể sử dụng các toán tử cho các tác vụ như tính giá trị trung bình hoặc độ lệch chuẩn trên các bộ sưu tập tài liệu và thao tác với các chuỗi. MongoDB cũng cung cấp các hoạt động MapReduce nguyên bản trong cơ sở dữ liệu, sử dụng các hàm JavaScript tùy chỉnh để thực hiện lập bản đồ và giảm bớt các giai đoạn.
Ngoài khung truy vấn gốc, MongoDB cũng cung cấp trình kết nối hiệu suất cao cho Apache Spark. Trình kết nối hiển thị tất cả các thư viện của Spark, bao gồm Python, R, Scala và Java. Dữ liệu MongoDB được hiện thực hóa dưới dạng DataFrames và Datasets để phân tích với học máy, đồ thị, luồng và API SQL.
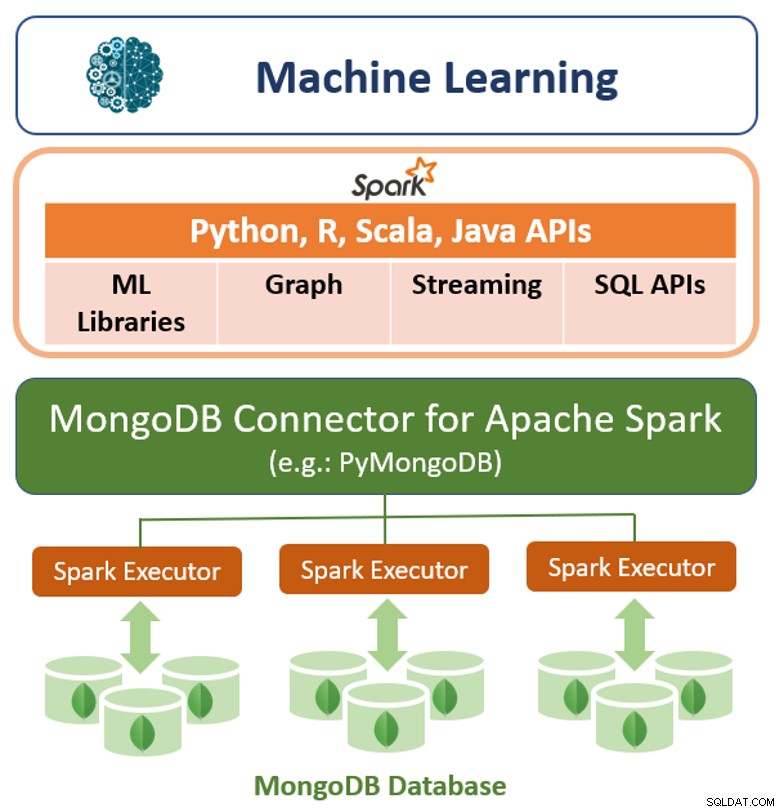
Trình kết nối MongoDB cho Apache Spark có thể tận dụng kênh tổng hợp của MongoDB và thứ cấp lập chỉ mục để chỉ trích xuất, lọc và xử lý phạm vi dữ liệu mà nó cần - ví dụ:phân tích tất cả khách hàng ở một khu vực địa lý cụ thể. Điều này rất khác với các kho dữ liệu NoSQL đơn giản không hỗ trợ chỉ mục phụ hoặc tổng hợp trong cơ sở dữ liệu. Trong những trường hợp này, Spark sẽ cần trích xuất tất cả dữ liệu dựa trên một khóa chính đơn giản, ngay cả khi chỉ cần một tập hợp con của dữ liệu đó cho quy trình Spark. Điều này có nghĩa là chi phí xử lý nhiều hơn, nhiều phần cứng hơn và thời gian tìm hiểu sâu hơn cho các nhà khoa học và kỹ sư dữ liệu. Để tối đa hóa hiệu suất trên các tập dữ liệu phân tán, lớn, Trình kết nối MongoDB dành cho Apache Spark có thể đồng định vị Tập dữ liệu phân tán có khả năng phục hồi (RDD) với nút MongoDB nguồn, do đó giảm thiểu việc di chuyển dữ liệu trên toàn cụm và giảm độ trễ.
Hiệu suất, Khả năng mở rộng &Dự phòng
Thời gian đào tạo mô hình có thể được giảm bớt bằng cách xây dựng nền tảng học máy trên lớp cơ sở dữ liệu hiệu quả và có thể mở rộng. MongoDB cung cấp một số cải tiến để tối đa hóa thông lượng và giảm thiểu độ trễ của khối lượng công việc học máy:
- WiredTiger được biết đến là công cụ lưu trữ mặc định cho MongoDB, được phát triển bởi các kiến trúc sư của Berkeley DB, phần mềm quản lý dữ liệu nhúng được triển khai rộng rãi nhất trên thế giới. WiredTiger mở rộng quy mô trên các kiến trúc đa lõi, hiện đại. Sử dụng nhiều kỹ thuật lập trình khác nhau như con trỏ nguy hiểm, thuật toán không khóa, chốt nhanh và truyền thông báo, WiredTiger tối đa hóa công việc tính toán trên mỗi lõi CPU và chu kỳ xung nhịp. Để giảm thiểu chi phí đầu vào và I / O trên đĩa, WiredTiger sử dụng các định dạng tệp nhỏ gọn và nén bộ nhớ.
- Đối với các ứng dụng học máy nhạy cảm với độ trễ nhất, MongoDB có thể được định cấu hình bằng công cụ lưu trữ Trong bộ nhớ. Dựa trên WiredTiger, công cụ lưu trữ này mang lại cho người dùng những lợi ích của tính toán trong bộ nhớ mà không phải đánh đổi tính linh hoạt truy vấn phong phú, phân tích thời gian thực và dung lượng có thể mở rộng được cung cấp bởi cơ sở dữ liệu dựa trên đĩa thông thường.
- Để song song đào tạo mô hình và mở rộng tập dữ liệu đầu vào ngoài một nút duy nhất, MongoDB sử dụng một kỹ thuật gọi là sharding, phân phối quá trình xử lý và dữ liệu trên các cụm phần cứng hàng hóa. Sharding MongoDB hoàn toàn có thể co giãn, tự động cân bằng lại dữ liệu trên toàn cụm khi tập dữ liệu đầu vào phát triển hoặc khi các nút được thêm và xóa.
- Trong một cụm MongoDB, dữ liệu từ mỗi phân đoạn được tự động phân phối cho nhiều bản sao được lưu trữ trên các nút riêng biệt. Các bộ bản sao MongoDB cung cấp khả năng dự phòng để khôi phục dữ liệu đào tạo trong trường hợp bị lỗi, giảm chi phí kiểm tra.
Tính nhất quán có thể điều chỉnh được của MongoDB
MongoDB rất nhất quán theo mặc định, cho phép các ứng dụng học máy đọc ngay lập tức những gì đã được ghi vào cơ sở dữ liệu, do đó tránh được sự phức tạp của nhà phát triển do các hệ thống nhất quán áp đặt. Tính nhất quán mạnh mẽ sẽ cung cấp kết quả chính xác nhất cho các thuật toán học máy; tuy nhiên, trong một số trường hợp, có thể chấp nhận tính nhất quán đối với các mục tiêu hiệu suất cụ thể bằng cách phân phối các truy vấn trên một nhóm các thành viên tập hợp bản sao thứ cấp MongoDB.
Mô hình Dữ liệu Linh hoạt trong MongoDB
Mô hình dữ liệu tài liệu của MongoDB giúp các nhà phát triển và nhà khoa học dữ liệu dễ dàng lưu trữ và tổng hợp dữ liệu thuộc bất kỳ dạng cấu trúc nào bên trong cơ sở dữ liệu mà không phải từ bỏ các quy tắc xác thực phức tạp để chi phối chất lượng dữ liệu. Lược đồ có thể được sửa đổi động mà không có ứng dụng hoặc cơ sở dữ liệu thời gian ngừng hoạt động do sửa đổi lược đồ tốn kém hoặc thiết kế lại do hệ thống cơ sở dữ liệu quan hệ phát sinh.
Lưu các mô hình trong cơ sở dữ liệu và tải chúng, sử dụng python, cũng là một phương pháp dễ dàng và được yêu cầu nhiều. Lựa chọn MongoDB cũng là một lợi thế vì đây là cơ sở dữ liệu tài liệu mã nguồn mở và cũng là cơ sở dữ liệu NoSQL hàng đầu. MongoDB cũng đóng vai trò như một trình kết nối cho khung phân tán apache spark.
Bản chất Động của MongoDB
Bản chất năng động của MongoDB cho phép sử dụng nó trong các tác vụ thao tác cơ sở dữ liệu trong việc phát triển các ứng dụng Học máy. Đó là một cách rất hiệu quả và dễ dàng để thực hiện phân tích các tập dữ liệu và cơ sở dữ liệu. Đầu ra của phân tích có thể được sử dụng trong đào tạo các mô hình học máy. Chúng tôi khuyến nghị rằng các nhà phân tích dữ liệu và lập trình Máy học phải nắm vững MongoDB và áp dụng nó trong nhiều ứng dụng khác nhau. Khung tổng hợp của MongoDB được sử dụng cho quy trình khoa học dữ liệu để thực hiện phân tích dữ liệu cho nhiều ứng dụng.
Kết luận
MongoDB cung cấp một số khả năng khác nhau như:mô hình dữ liệu linh hoạt, lập trình phong phú, mô hình dữ liệu, mô hình truy vấn và tính nhất quán có thể điều chỉnh của nó giúp việc đào tạo và sử dụng các thuật toán học máy dễ dàng hơn nhiều so với cơ sở dữ liệu quan hệ truyền thống. Chạy MongoDB làm cơ sở dữ liệu phụ trợ sẽ cho phép lưu trữ và làm phong phú thêm dữ liệu học máy cho phép duy trì sự bền bỉ và tăng hiệu quả.



