Bài đăng trên blog này sẽ trình bày một loại ví dụ đơn giản “xin chào thế giới” về cách lấy dữ liệu được lưu trữ trong S3 được lập chỉ mục và cung cấp bởi dịch vụ Apache Solr được lưu trữ trong cụm Khám phá và Khám phá dữ liệu trong CDP. Đối với những người tò mò:DDE là một tùy chọn triển khai cụm được tối ưu hóa cho Solr được xây dựng trước trong CDP và gần đây đã được phát hành trong bản xem trước công nghệ . Chúng tôi sẽ chỉ đề cập đến môi trường AWS và S3 trong blog này. Các tùy chọn triển khai Azure và ADLS cũng có sẵn trong bản xem trước công nghệ, nhưng sẽ được đề cập trong một bài đăng blog trong tương lai.
Chúng tôi sẽ mô tả kịch bản đơn giản nhất để giúp bạn dễ dàng bắt đầu. Tất nhiên có thể có nhiều thiết lập đường ống dữ liệu nâng cao hơn và nhiều lược đồ phong phú hơn, nhưng đây là một điểm khởi đầu tốt cho người mới bắt đầu.
Các giả định:
- Bạn đã có tài khoản CDP và có quyền người dùng hoặc quản trị viên cấp cao đối với môi trường mà bạn định phát triển dịch vụ này.
Nếu bạn chưa có tài khoản CDP AWS, vui lòng liên hệ với đại diện Cloudera yêu thích của bạn hoặc đăng ký dùng thử CDP tại đây. - Bạn có môi trường và danh tính được lập bản đồ và định cấu hình. Rõ ràng hơn, tất cả những gì bạn cần là ánh xạ Người dùng CDP tới Vai trò AWS cấp quyền truy cập vào nhóm s3 cụ thể mà bạn muốn đọc (và ghi vào).
- Bạn đã đặt mật khẩu khối lượng công việc (FreeIPA).
- Bạn có một cụm DDE đang chạy. Bạn cũng có thể tìm thêm thông tin về cách sử dụng các mẫu trong Trung tâm dữ liệu CDP tại đây.
- Bạn có quyền truy cập CLI vào cụm đó.
- Cổng SSH được mở trên AWS đối với địa chỉ IP của bạn. Bạn có thể lấy địa chỉ IP công cộng cho một trong các nút Solr trong chi tiết cụm Datahub. Tìm hiểu tại đây cách SSH tới một cụm AWS.
- Bạn có tệp nhật ký trong nhóm S3 mà người dùng của bạn có thể truy cập được (
/sample.log trong ví dụ này). Nếu bạn chưa có, đây là liên kết đến liên kết mà chúng tôi đã sử dụng.
Quy trình làm việc
Các phần sau sẽ hướng dẫn bạn các bước để lập chỉ mục dữ liệu bằng cách sử dụng Công cụ lập chỉ mục Crunch đi kèm với DDE.

Tạo một bộ sưu tập để lưu giữ chỉ mục của bạn
Ở HUẾ có một nhà thiết kế chỉ mục; tuy nhiên, với điều kiện là DDE ở chế độ Xem trước Công nghệ, nó sẽ được xây dựng lại một chút và không được khuyến khích vào thời điểm này. Nhưng hãy thử nó sau khi DDE chuyển sang GA và cho chúng tôi biết suy nghĩ của bạn.
Hiện tại, bạn có thể tạo lược đồ Solr và cấu hình bằng công cụ CLI ‘solrctl’. Tạo một cấu hình có tên là ‘my-own-logs-config’ và một bộ sưu tập có tên là ‘my-own-logs’. Điều này yêu cầu bạn có quyền truy cập CLI.
1. SSH cho bất kỳ nút công nhân nào trong cụm của bạn.
2. kinit với tư cách là người dùng có quyền tạo cấu hình bộ sưu tập:
kinit
3. Đảm bảo rằng biến môi trường SOLR_ZK_ENSEMBLE được đặt trong /etc/solr/conf/solr-env.sh. Lưu giá trị của nó vì điều này sẽ được yêu cầu trong các bước tiếp theo.
Nhấn Enter và nhập mật khẩu khối lượng công việc (FreeIPA) của bạn.
Ví dụ:
cat /etc/solr/conf/solr-env.sh
Sản lượng mong đợi:
export SOLR_ZK_ENSEMBLE=zk01.example.com:2181,zk02.example.com:2181,zk03.example.com:2181/solr
Điều này được đặt tự động trên các máy chủ có vai trò Máy chủ Solr hoặc Cổng trong Trình quản lý Cloudera.
4. Để tạo tệp cấu hình cho bộ sưu tập, hãy chạy lệnh sau:
solrctl config --create my-own-logs-config schemalessTemplate -p immutable=false
schemalessTemplate là một trong những mẫu mặc định được vận chuyển cùng với Solr trong CDP nhưng, là một mẫu, nó là bất biến. Với mục đích của dòng công việc này, bạn cần sao chép nó và do đó tạo một dòng mới có thể thay đổi được (đây là những gì tùy chọn Immutable =false thực hiện). Điều này cung cấp cho bạn một cấu hình linh hoạt, không có schemaless. Tạo một lược đồ được thiết kế tốt là điều đáng để đầu tư thời gian thiết kế vào, nhưng không cần thiết cho việc sử dụng khám phá. Vì lý do này, nó nằm ngoài phạm vi của bài đăng trên blog này. Tuy nhiên, trong môi trường sản xuất thực tế, chúng tôi thực sự khuyên bạn nên sử dụng các lược đồ được thiết kế tốt - và chúng tôi sẵn lòng cung cấp trợ giúp từ chuyên gia nếu cần!
5. Tạo một bộ sưu tập mới bằng lệnh sau:
solrctl collection --create my-own-logs -s 1 -c my-own-logs-config
Điều này tạo ra bộ sưu tập “my-own-log” dựa trên cấu hình bộ sưu tập “my-own-logs-config” trên một phân đoạn.
6. Để xác thực bộ sưu tập đã được tạo, bạn có thể điều hướng đến Giao diện người dùng quản trị Solr. Bộ sưu tập cho “nhật ký của riêng tôi” sẽ có sẵn qua menu thả xuống ở điều hướng bên trái.

Lập chỉ mục Dữ liệu của bạn
Ở đây chúng tôi mô tả bằng cách sử dụng một ví dụ đơn giản về cách định cấu hình và chạy Công cụ lập chỉ mục Crunch tích hợp để nhanh chóng lập chỉ mục dữ liệu trong S3 và phân phát thông qua Solr trong DDE. Vì việc bảo mật cụm có thể sử dụng CM Auto TLS, Knox, Kerberos và Ranger, "Spark submit" có thể phụ thuộc vào các khía cạnh không được đề cập trong bài đăng này.
Dữ liệu lập chỉ mục từ S3 cũng giống như lập chỉ mục từ HDFS.
Thực hiện các bước này trên nút Yarn worker (được gọi là “Yarnworker” trên webUI của Bảng điều khiển quản lý).
1. SSH tới nút Yarn worker chuyên dụng của cụm DDE với tư cách là người dùng quản trị Solr.
Để tìm ra địa chỉ IP của nút Yarn worker, hãy nhấp vào Phần cứng trên trang chi tiết cụm, sau đó cuộn đến nút “Yarnworker”.

2. Đi tới thư mục tài nguyên của bạn (hoặc tạo một thư mục nếu bạn chưa có:
cd
Sử dụng thư mục chính của người dùng quản trị viên làm thư mục tài nguyên (
3. Thu hút người dùng của bạn:
kinit
Nhấn Enter và nhập mật khẩu khối lượng công việc (FreeIPA) của bạn.
4. Chạy lệnh curl sau, thay thế cho
curl --negotiate -u: "https://<SOLR_HOST>:<SOLR_PORT>/solr/admin?op=GETDELEGATIONTOKEN" --insecure > tokenFile.txt
5. Tạo tệp cấu hình Morphline cho Công cụ lập chỉ mục Crunch, read-log-morphline.conf trong ví dụ này. Thay thế
SOLR_LOCATOR : {
# Name of solr collection
collection : my-own-logs
#zk ensemble
zkHost : <SOLR_ZK_ENSEMBLE>
}
morphlines : [
{
id : loadLogs
importCommands : ["org.kitesdk.**", "org.apache.solr.**"]
commands : [
{
readMultiLine {
regex : "(^.+Exception: .+)|(^\\s+at .+)|(^\\s+\\.\\.\\. \\d+ more)|(^\\s*Caused by:.+)"
what : previous
charset : UTF-8
}
}
{ logDebug { format : "output record: {}", args : ["@{}"] } }
{
loadSolr {
solrLocator : ${SOLR_LOCATOR}
}
}
]
}
] Morphline này đọc các dấu vết ngăn xếp từ tệp nhật ký đã cho, sau đó ghi nhật ký mục gỡ lỗi và tải nó vào Solr được chỉ định.
6. Tạo tệp log4j.properties để cấu hình nhật ký:
log4j.rootLogger=INFO, A1 # A1 is set to be a ConsoleAppender. log4j.appender.A1=org.apache.log4j.ConsoleAppender # A1 uses PatternLayout. log4j.appender.A1.layout=org.apache.log4j.PatternLayout log4j.appender.A1.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
7. Kiểm tra xem tệp bạn muốn đọc có tồn tại trên S3 hay không (nếu bạn không có, đây là liên kết đến tệp mà chúng tôi đã sử dụng cho ví dụ đơn giản này:
aws s3 ls s3://<S3_BUCKET>/sample.log
8. Chạy lệnh spark-submit:
Thay thế trình giữ chỗ trong
export myDriverJarDir=/opt/cloudera/parcels/CDH/lib/solr/contrib/crunch export myDependencyJarDir=/opt/cloudera/parcels/CDH/lib/search/lib/search-crunch export myDriverJar=$(find $myDriverJarDir -maxdepth 1 -name 'search-crunch-*.jar' ! -name '*-job.jar' ! -name '*-sources.jar') export myDependencyJarFiles=$(find $myDependencyJarDir -name '*.jar' | sort | tr '\n' ',' | head -c -1) export myDependencyJarPaths=$(find $myDependencyJarDir -name '*.jar' | sort | tr '\n' ':' | head -c -1) export myJVMOptions="-DmaxConnectionsPerHost=10000 -DmaxConnections=10000 -Djava.io.tmpdir=/tmp/dir/ " export myResourcesDir="<RESOURCE_DIR>" export HADOOP_CONF_DIR="/etc/hadoop/conf" spark-submit \ --master yarn \ --deploy-mode cluster \ --jars $myDependencyJarFiles \ --executor-memory 1024M \ --conf "spark.executor.extraJavaOptions=$myJVMOptions" \ --driver-java-options "$myJVMOptions" \ --class org.apache.solr.crunch.CrunchIndexerTool \ --files $(ls $myResourcesDir/log4j.properties),$(ls $myResourcesDir/read-log-morphline.conf),tokenFile.txt \ $myDriverJar \ -Dhadoop.tmp.dir=/tmp \ -DtokenFile=tokenFile.txt \ --morphline-file read-log-morphline.conf \ --morphline-id loadLogs \ --pipeline-type spark \ --chatty \ --log4j log4j.properties \ s3a://<S3_BUCKET>/sample.log
Nếu bạn gặp một thông báo tương tự, bạn có thể bỏ qua nó:
WARN metadata.Hive: Failed to register all functions. org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.thrift.transport.TTransportException
9. Để giám sát việc thực thi lệnh, hãy chuyển đến Trình quản lý tài nguyên.

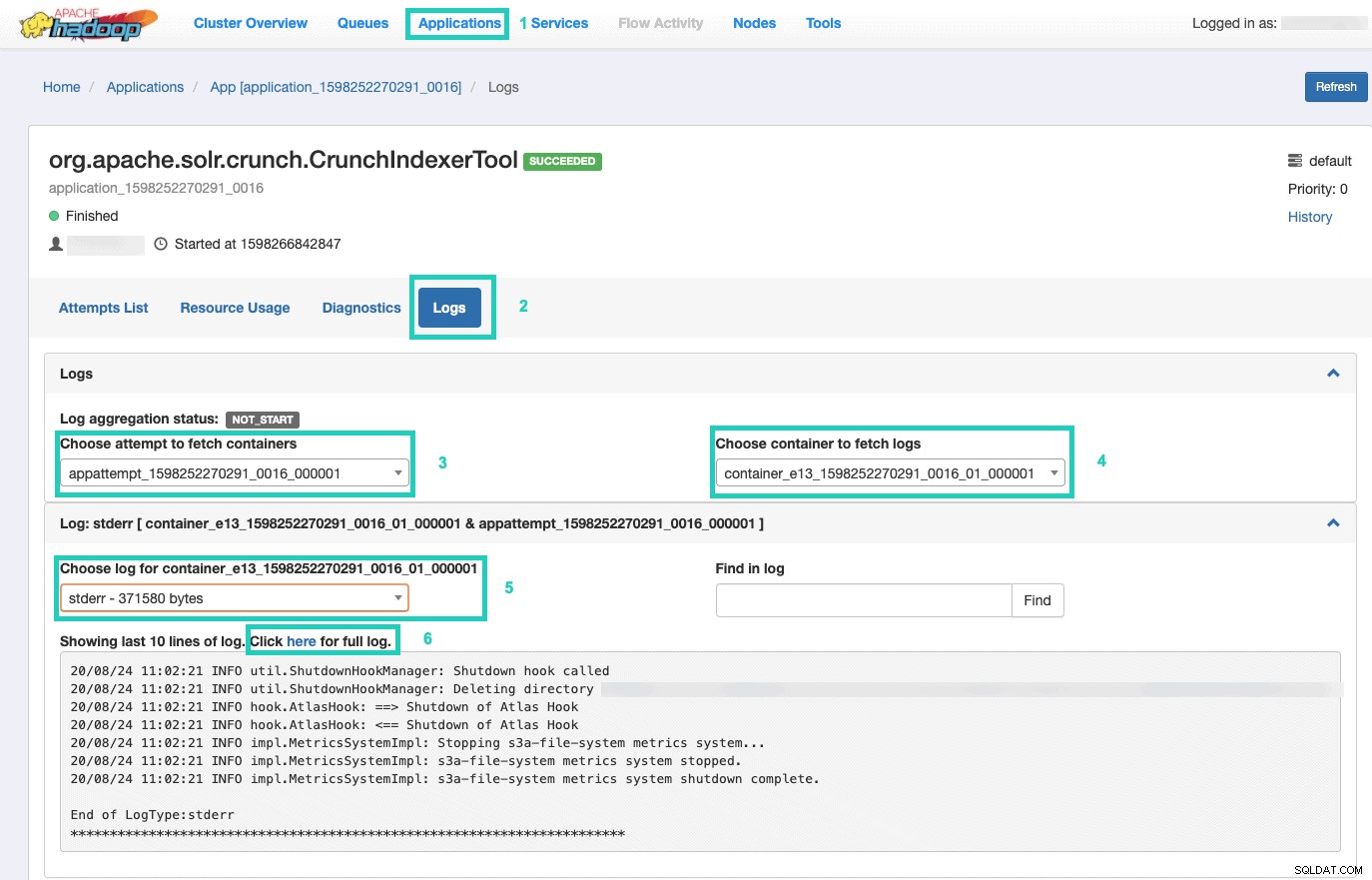
Khi đó, hãy chọn Ứng dụng tab > Nhấp vào ID ứng dụng về nỗ lực ứng dụng mà bạn muốn theo dõi > Chọn Nhật ký> Chọn nỗ lực tìm nạp vùng chứa> Chọn vùng chứa để tìm nạp nhật ký> Chọn nhật ký cho vùng chứa> Chọn stderr nhật ký> Nhấp vào Nhấp vào đây để xem nhật ký đầy đủ .
Phục vụ chỉ mục của bạn
Bạn có nhiều tùy chọn về cách phân phát dữ liệu được lập chỉ mục có thể tìm kiếm cho người dùng cuối. Bạn có thể tạo ứng dụng phong phú của riêng mình dựa trên các API phong phú của Solr (rất phổ biến). Bạn có thể kết nối công cụ bên thứ 3 yêu thích của mình, chẳng hạn như Qlik, Tableau, v.v. qua kết nối Solr được chứng nhận của họ. Bạn có thể sử dụng bảng điều khiển solr đơn giản của Hue để tạo các ứng dụng nguyên mẫu.
Để làm điều sau:
1. Đến Huế.

2. Trong chế độ xem trang tổng quan, điều hướng đến tệp chỉ mục bạn chọn (ví dụ:tệp bạn vừa tạo).
3. Bắt đầu kéo và thả các phần tử trang tổng quan khác nhau và chọn các trường từ chỉ mục để điền dữ liệu cho trực quan.
Bạn có thể tìm thấy video hướng dẫn nhanh về bảng điều khiển trước đây tại đây để lấy cảm hứng.
Chúng tôi sẽ đi sâu hơn cho một bài đăng blog trong tương lai.
Tóm tắt
Chúng tôi hy vọng bạn đã học được nhiều điều từ bài đăng trên blog này về cách lấy dữ liệu trong S3 được Solr lập chỉ mục trong DDE bằng cách sử dụng Công cụ lập chỉ mục Crunch. Tất nhiên có nhiều cách khác (Spark trong trải nghiệm Kỹ thuật dữ liệu, Nifi trong trải nghiệm Luồng dữ liệu, Kafka trong trải nghiệm Quản lý luồng, v.v.), nhưng những cách đó sẽ được đề cập trong các bài đăng blog trong tương lai. Chúng tôi hy vọng rằng bạn sẽ rất thành công trong hành trình tiếp tục xây dựng các ứng dụng thông tin chi tiết mạnh mẽ liên quan đến văn bản và dữ liệu phi cấu trúc khác. Nếu bạn quyết định thử DDE trong CDP, vui lòng cho chúng tôi biết mọi việc diễn ra như thế nào!



