Bài đăng này là một phần của hướng dẫn Oracle SQL và chúng ta sẽ thảo luận về các hàm Phân tích trong oracle (Theo phân vùng) với các ví dụ, giải thích chi tiết.
Chúng ta đã nghiên cứu về hàm Aggregate của Oracle như avg, sum, count. Hãy lấy một ví dụ
Đầu tiên, hãy tạo dữ liệu mẫu
CREATE TABLE "DEPT"
( "DEPTNO" NUMBER(2,0),
"DNAME" VARCHAR2(14),
"LOC" VARCHAR2(13),
CONSTRAINT "PK_DEPT" PRIMARY KEY ("DEPTNO")
)
CREATE TABLE "EMP"
( "EMPNO" NUMBER(4,0),
"ENAME" VARCHAR2(10),
"JOB" VARCHAR2(9),
"MGR" NUMBER(4,0),
"HIREDATE" DATE,
"SAL" NUMBER(7,2),
"COMM" NUMBER(7,2),
"DEPTNO" NUMBER(2,0),
CONSTRAINT "PK_EMP" PRIMARY KEY ("EMPNO"),
CONSTRAINT "FK_DEPTNO" FOREIGN KEY ("DEPTNO")
REFERENCES "DEPT" ("DEPTNO") ENABLE
);
SQL> desc emp
Name Null? Type
---- ---- -----
EMPNO NOT NULL NUMBER(4)
ENAME VARCHAR2(10)
JOB VARCHAR2(9)
MGR NUMBER(4)
HIREDATE DATE
SAL NUMBER(7,2)
COMM NUMBER(7,2)
DEPTNO NUMBER(2)
SQL> desc dept
Name Null? Type
---- ----- ----
DEPTNO NOT NULL NUMBER(2)
DNAME VARCHAR2(14)
LOC VARCHAR2(13)
insert into DEPT values(10, 'ACCOUNTING', 'NEW YORK');
insert into dept values(20, 'RESEARCH', 'DALLAS');
insert into dept values(30, 'RESEARCH', 'DELHI');
insert into dept values(40, 'RESEARCH', 'MUMBAI');
commit;
insert into emp values( 7839, 'Allen', 'MANAGER', 7839, to_date('17-11-1981','dd-mm-yyyy'), 20, null, 10 );
insert into emp values( 7782, 'CLARK', 'MANAGER', 7839, to_date('9-06-1981','dd-mm-yyyy'), 0, null, 10 );
insert into emp values( 7934, 'MILLER', 'MANAGER', 7839, to_date('23-01-1982','dd-mm-yyyy'), 0, null, 10 );
insert into emp values( 7788, 'SMITH', 'ANALYST', 7788, to_date('17-12-1980','dd-mm-yyyy'), 800, null, 20 );
insert into emp values( 7902, 'ADAM, 'ANALYST', 7832, to_date('23-05-1987','dd-mm-yyyy'), 1100, null, 20 );
insert into emp values( 7876, 'FORD', 'ANALYST', 7566, to_date('3-12-1981','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7369, 'SCOTT', 'ANALYST', 7566, to_date('19-04-1987','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7698, 'JAMES', 'ANALYST', 7788, to_date('03-12-1981','dd-mm-yyyy'), 950, null, 30 );
insert into emp values( 7499, 'MARTIN', 'ANALYST', 7698, to_date('28-09-1981','dd-mm-yyyy'), 1250, null, 30 );
insert into emp values( 7844, 'WARD', 'ANALYST', 7698, to_date('22-02-1981','dd-mm-yyyy'), 1250, null, 30 );
insert into emp values( 7654, 'TURNER', 'ANALYST', 7698, to_date('08-09-1981','dd-mm-yyyy'), 1500, null, 30 );
insert into emp values( 7521, 'ALLEN', 'ANALYST', 7698, to_date('20-02-1981','dd-mm-yyyy'), 1600, null, 30 );
insert into emp values( 7900, 'BLAKE', 'ANALYST', 77698, to_date('01-05-1981','dd-mm-yyyy'), 2850, null, 30 );
commit;
Bây giờ, ví dụ về các hàm tổng hợp sẽ được đưa ra như dưới đây
select count(*) from EMP; --------- 13 select sum (bytes) from dba_segments where tablespace_name='TOOLS'; ----- 100 SQL> select deptno ,count(*) from emp group by deptno; DEPTNO COUNT(*) ---------- ---------- 30 6 20 4 10 3
Ở đây chúng ta có thể thấy rằng nó làm giảm số hàng trong mỗi truy vấn. Bây giờ câu hỏi đặt ra là phải làm gì nếu chúng ta cần trả về tất cả các hàng với số đếm (*)
Đối với điều đó tiên tri đã cung cấp một tập hợp các hàm phân tích. Vì vậy, để giải quyết vấn đề cuối cùng, chúng ta có thể viết là
select empno ,deptno , count(*) over (partition by deptno) from emp group by deptno;
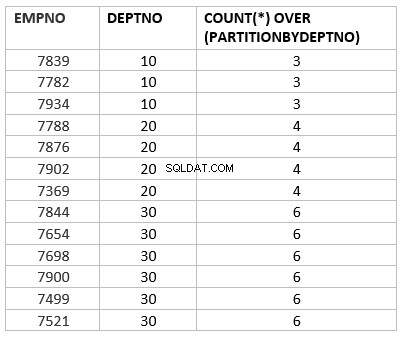
Ở đây count (*) over (phân vùng theo dept_no) là phiên bản phân tích của hàm tổng hợp đếm. Công việc chính khác nhau theo chức năng tổng hợp là vượt quá phân vùng theo
Các hàm phân tích tính toán giá trị tổng hợp dựa trên một nhóm hàng. Chúng khác với các hàm tổng hợp ở chỗ chúng trả về nhiều hàng cho mỗi nhóm. Nhóm các hàng được gọi là cửa sổ và được xác định bởi analytic_clause.
Đây là cú pháp chung
analytic_function([ arguments ]) OVER ([ query_partition_clause ] [ order_by_clause [ windowing_clause ] ])
Ví dụ
count(*) over (partition by deptno) avg(Sal) over (partition by deptno)
Hãy xem qua từng phần
query_partition_clause
Nó xác định nhóm hàng. Nó có thể như dưới đây
phân vùng theo deptno:nhóm các hàng của cùng một deptno
hoặc
():Tất cả các hàng
SQL> select empno ,deptno , count(*) over () from emp;
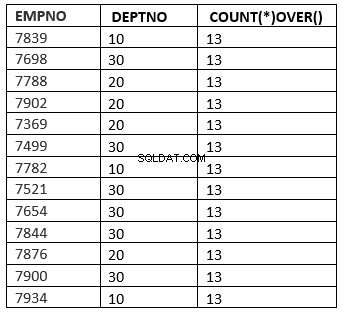
[order_by_clause [windowing_clause]]
Mệnh đề này được sử dụng khi bạn muốn sắp xếp các hàng trong phân vùng. Điều này đặc biệt hữu ích nếu bạn muốn chức năng phân tích xem xét thứ tự của các hàng.
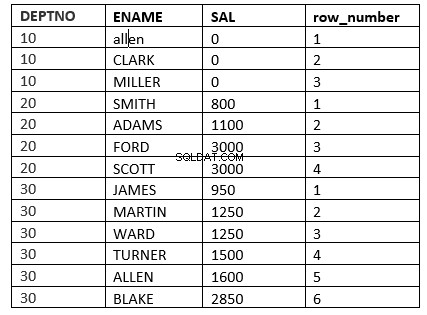
Ví dụ sẽ là hàm row_number
SQL> select deptno, ename, sal, row_number() over (partition by deptno order by sal) "row_number" from emp;
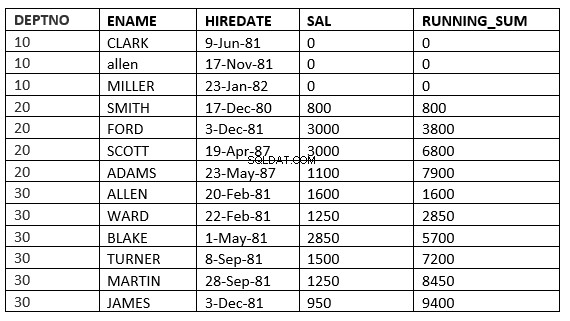
Một ví dụ khác sẽ là
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE) running_sum from emp;
Windowing_clause
Điều này luôn được sử dụng với mệnh đề theo thứ tự và cung cấp nhiều quyền kiểm soát hơn đối với tập hợp các hàng trong nhóm
Với mệnh đề Windowing, Đối với mỗi hàng, một cửa sổ trượt của các hàng được xác định. Cửa sổ xác định phạm vi hàng được sử dụng để thực hiện các phép tính cho hàng hiện tại. Kích thước cửa sổ có thể dựa trên số hàng vật lý hoặc khoảng thời gian hợp lý chẳng hạn như thời gian.
Khi sử dụng mệnh đề theo thứ tự và không có gì được cung cấp cho windowing_clause, giá trị mặc định dưới đây của windowing_clause sẽ được lấy
RANGE GIỮA ĐƯỜNG CHÍNH XÁC VÀ HIỆN TẠI hoặc RANGE UNBOUNDED PRECEDING
Nó có nghĩa là “Dòng hiện tại và hàng trước đó phân vùng là các hàng sẽ được sử dụng trong tính toán ”
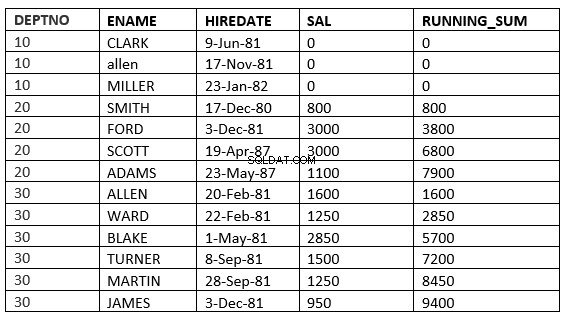
Ví dụ dưới đây nói rõ điều này. Đây là mức trung bình hoạt động trong bộ phận
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE) running_sum from emp;
Giờ đây, windowing_clause có thể được định nghĩa bằng một số cách
Trước tiên hãy hiểu thuật ngữ này
ROWS chỉ định cửa sổ theo đơn vị vật lý (hàng).
RANGE chỉ định cửa sổ như một độ lệch hợp lý. mệnh đề cửa sổ RANGE chỉ có thể được sử dụng với mệnh đề ORDER BY có chứa cột hoặc biểu thức của kiểu dữ liệu số hoặc ngày
PRECEDING - lấy các hàng trước hàng hiện tại.
THEO DÕI - lấy các hàng sau hàng hiện tại.
ĐÃ BỎ QUA - khi được sử dụng với PRECEDING hoặc F SAU, nó trả về tất cả trước hoặc sau. ROW HIỆN TẠI
Vì vậy, nó thường được định nghĩa là
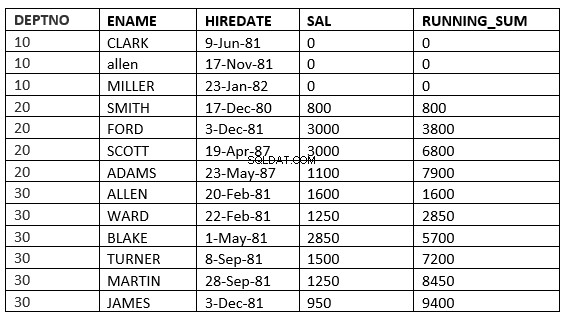
ROWS UNBOUNDED PRECEDING :Các hàng hiện tại và trước đó trong phân vùng hiện tại là các hàng sẽ được sử dụng trong tính toán
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS UNBOUNDED PRECEDING) running_sum from emp;
RANGE UNBOUNDED PRECEDING :Các hàng hiện tại và trước đó trong phân vùng hiện tại là các hàng sẽ được sử dụng trong tính toán. Ngoài ra, vì phạm vi được chỉ định, tất cả đều nhận các giá trị bằng với các hàng hiện tại.
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE UNBOUNDED PRECEDING) running_sum from emp;
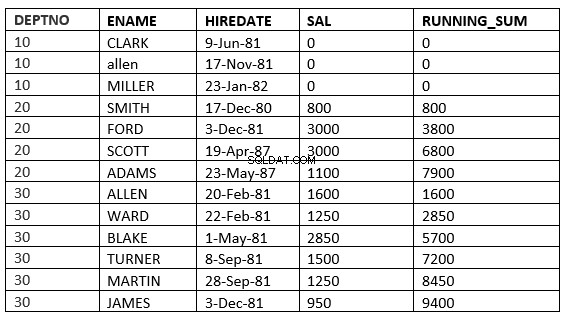
Bạn có thể không thấy sự khác biệt giữa phạm vi và các hàng vì ngày thuê là khác nhau cho tất cả. Sự khác biệt sẽ trở nên rõ ràng hơn nếu chúng ta sử dụng sal làm thứ tự theo mệnh đề
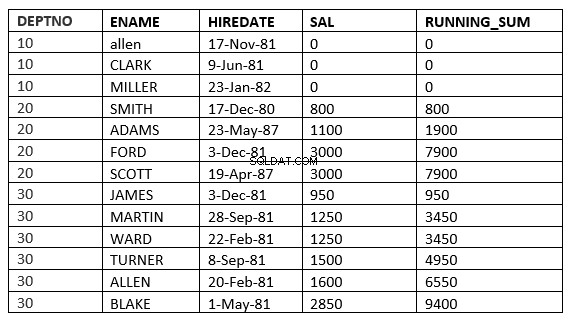
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by sal RANGE UNBOUNDED PRECEDING) running_sum from emp;
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by sal ROWS UNBOUNDED PRECEDING) running_sum from emp;
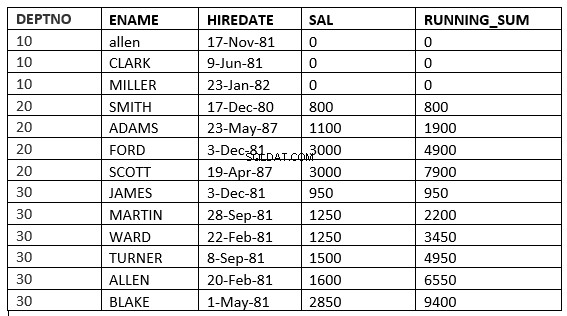
Bạn có thể tìm thấy sự khác biệt ở dòng 6
RANGE value_expr PRECEDING :Cửa sổ bắt đầu với hàng có giá trị ORDER BY là các hàng biểu thức số nhỏ hơn hoặc đứng trước hàng hiện tại và kết thúc bằng hàng hiện tại đang được xử lý.
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE 365 PRECEDING) running_sum from emp;
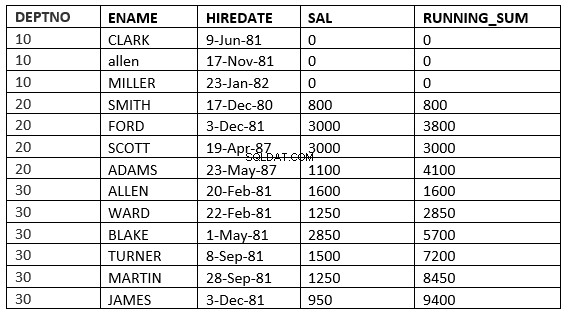
Ở đây, nó lấy tất cả các hàng trong đó giá trị thuê giảm trong vòng 365 ngày trước giá trị thuê của hàng hiện tại
ROWS value_expr PRECEDING :Cửa sổ bắt đầu với hàng đã cho và kết thúc với hàng hiện tại đang được xử lý
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS 2 PRECEDING) running_sum from emp;
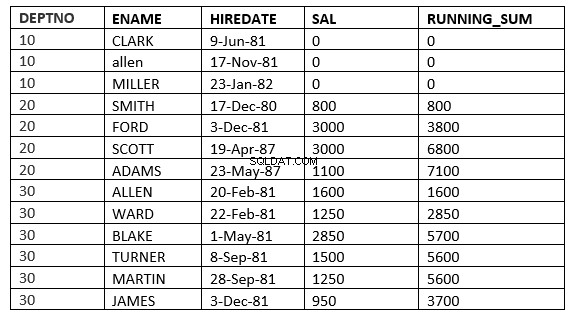
Ở đây, cửa sổ bắt đầu từ 2 hàng trước hàng hiện tại
RANGE GIỮA ROW HIỆN TẠI và value_expr SAU ĐÂY :Cửa sổ bắt đầu bằng hàng hiện tại và kết thúc bằng hàng có giá trị ORDER BY là các hàng biểu thức số nhỏ hơn hoặc theo sau
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS between current row and 1 FOLLOWING) running_sum from emp;
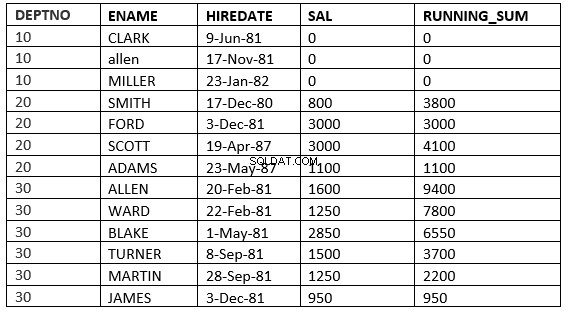
ROW GIỮA ROW HIỆN TẠI và value_expr SAU ĐÂY :Cửa sổ bắt đầu bằng hàng hiện tại và kết thúc bằng các hàng sau hàng hiện tại
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS between current row and 1 FOLLOWING) running_sum from emp;
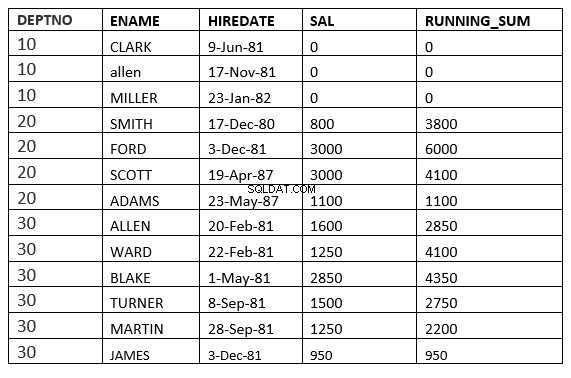
RANGE GIỮA KHI CHƯA ĐƯỢC CẬP NHẬT CHÍNH XÁC VÀ ĐOẠN SAU KHÔNG ĐƯỢC TỔ CHỨC
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE BETWEEN UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING ) running_sum from emp;
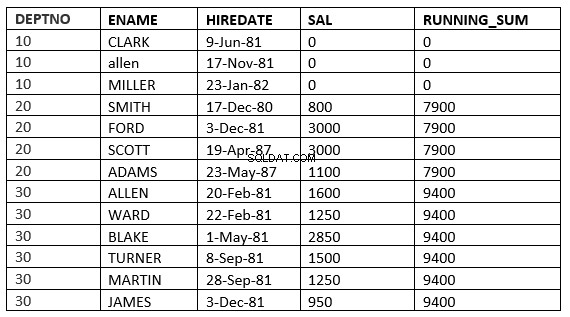
RANGE BETWEEN value_expr PRECEDING và value_expr THEO DÕI
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE BETWEEN 365 PRECEDING and 365 FOLLOWING ) running_sum from emp; 2 DEPTNO ENAME HIREDATE SAL RUNNING_SUM ---------- ---------- --------------- ---------- ----------- 10 CLARK 09-JUN-81 0 0 10 ALLEN 17-NOV-81 0 0 10 MILLER 23-JAN-82 0 0 20 SMITH 17-DEC-80 800 3800 20 FORD 03-DEC-81 3000 3800 20 SCOTT 19-APR-87 3000 4100 20 ADAMS 23-MAY-87 1100 4100 30 ALLEN 20-FEB-81 1600 9400 30 WARD 22-FEB-81 1250 9400 30 BLAKE 01-MAY-81 2850 9400 30 TURNER 08-SEP-81 1500 9400 30 MARTIN 28-SEP-81 1250 9400 30 JAMES 03-DEC-81 950 9400 13 rows selected.
Một số lưu ý quan trọng
(1) Các hàm phân tích là tập hợp các thao tác cuối cùng được thực hiện trong một truy vấn ngoại trừ mệnh đề ORDER BY cuối cùng. Tất cả các phép nối và tất cả các mệnh đề WHERE, GROUP BY và HAVING được hoàn thành trước khi các hàm phân tích được xử lý. Do đó, các hàm phân tích chỉ có thể xuất hiện trong danh sách lựa chọn hoặc mệnh đề ORDER BY.
(2) Các hàm phân tích thường được sử dụng để tính toán các tổng hợp tích lũy, di chuyển, căn giữa và báo cáo.
Tôi hy vọng bạn thích phần giải thích chi tiết này về các hàm Phân tích trong oracle (theo Điều khoản phân vùng)
Các bài viết có liên quan
Hàm LEAD trong Oracle
Hàm DENSE trong Oracle
Hàm LISTAGG của Oracle
Tổng hợp dữ liệu bằng các hàm nhóm
https://docs.oracle.com/cd/E11882_01/ máy chủ.112 / e41084 / functions004.htm