Tổng quan
Khai thác dữ liệu Oracle (ODM) là một thành phần của Tùy chọn Cơ sở dữ liệu Phân tích Nâng cao Oracle. ODM chứa một bộ thuật toán khai thác dữ liệu nâng cao được nhúng trong cơ sở dữ liệu cho phép bạn thực hiện phân tích nâng cao trên dữ liệu của mình.
Oracle Data Miner là một phần mở rộng của Oracle SQL Developer, một môi trường phát triển đồ họa cho Oracle SQL. Oracle Data Miner sử dụng công nghệ khai thác dữ liệu được nhúng trong Cơ sở dữ liệu Oracle để tạo, thực thi và quản lý quy trình công việc đóng gói các hoạt động khai thác dữ liệu. Kiến trúc của ODM được minh họa trong hình 1.
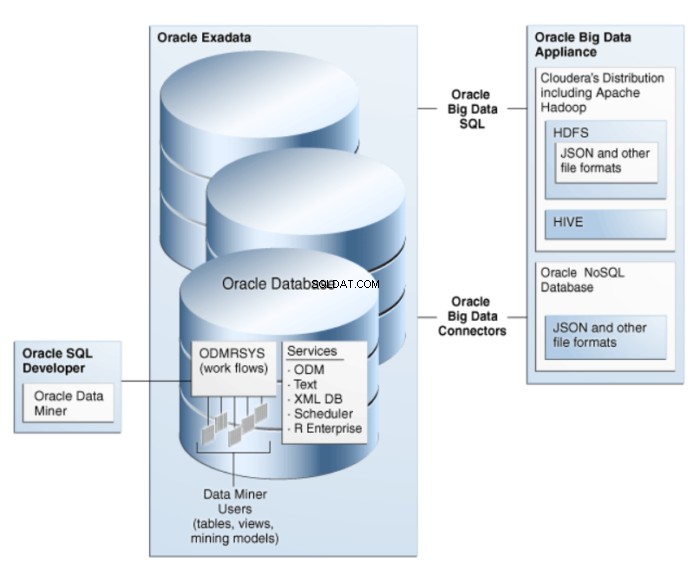
Hình 1:Kiến trúc khai thác dữ liệu của Oracle cho Dữ liệu lớn
Các thuật toán được triển khai dưới dạng các hàm SQL và tận dụng các điểm mạnh của Cơ sở dữ liệu Oracle. Các chức năng khai thác dữ liệu SQL có thể khai thác dữ liệu giao dịch, dữ liệu tổng hợp, dữ liệu phi cấu trúc, tức là kiểu dữ liệu CLOB (sử dụng Oracle Text) và dữ liệu không gian.
Mỗi hàm khai thác dữ liệu chỉ định một lớp vấn đề có thể được mô hình hóa và giải quyết. Các chức năng khai thác dữ liệu thường chia thành hai loại:được giám sát và không được giám sát.
Các khái niệm về học tập có giám sát và không giám sát bắt nguồn từ khoa học máy học, được gọi là một lĩnh vực phụ của trí tuệ nhân tạo.
Học tập có giám sát còn được gọi là học tập có định hướng. Quá trình học tập được định hướng bởi một thuộc tính hoặc mục tiêu phụ thuộc đã biết trước đó. Khai thác dữ liệu theo hướng cố gắng giải thích hành vi của mục tiêu như một chức năng của một tập hợp các thuộc tính hoặc yếu tố dự đoán độc lập.
Học không giám sát là không có định hướng. Không có sự phân biệt giữa các thuộc tính phụ thuộc và độc lập. Không có kết quả nào được biết trước đây để hướng dẫn thuật toán xây dựng mô hình. Học không giám sát có thể được sử dụng cho các mục đích mô tả.
Thuật toán được giám sát khai thác dữ liệu của Oracle
| Kỹ thuật | Khả năng áp dụng | Thuật toán (Mô tả ngắn gọn) |
|---|---|---|
Phân loại  | Kỹ thuật được sử dụng phổ biến nhất để dự đoán một kết quả cụ thể, chẳng hạn như xác định tế bào khối u ung thư, phân tích cảm xúc, phân loại thuốc, phát hiện spam. | Mô hình tuyến tính tổng quát hồi quy logistic - kỹ thuật thống kê cổ điển có sẵn bên trong Cơ sở dữ liệu Oracle với khả năng triển khai song song, có thể mở rộng, hiệu suất cao (áp dụng cho tất cả các thuật toán OAA ML). Hỗ trợ văn bản và dữ liệu giao dịch (áp dụng cho gần như tất cả các thuật toán ML của OAA) Naive Bayes - Nhanh chóng, đơn giản, thường được áp dụng. Hỗ trợ Vector Machine - Thuật toán học máy, hỗ trợ văn bản và dữ liệu rộng. Cây quyết định - Thuật toán ML phổ biến cho khả năng diễn giải. Cung cấp "quy tắc" mà con người có thể đọc được. |
Hồi quy  | Kỹ thuật dự đoán kết quả số liên tục như Phân tích dữ liệu thiên văn, Tạo ra thông tin chi tiết về hành vi người tiêu dùng, khả năng sinh lời và các yếu tố kinh doanh khác, Tính toán mối quan hệ nhân quả giữa các thông số trong hệ thống sinh học. | Mô hình tuyến tính tổng quát nhiều hồi quy - kỹ thuật thống kê cổ điển nhưng hiện đã có sẵn bên trong Cơ sở dữ liệu Oracle dưới dạng triển khai song song, có thể mở rộng, hiệu suất cao. Hỗ trợ hồi quy sườn núi, tạo tính năng và lựa chọn tính năng. Hỗ trợ văn bản và dữ liệu giao dịch. Hỗ trợ Vector Machine - Thuật toán học máy, hỗ trợ văn bản và dữ liệu rộng. |
Tầm quan trọng của thuộc tính 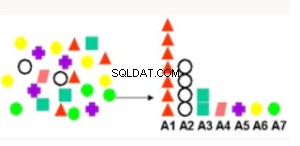 | Xếp hạng các thuộc tính theo độ mạnh của mối quan hệ với thuộc tính mục tiêu. Các trường hợp sử dụng bao gồm việc tìm kiếm các yếu tố liên quan nhiều nhất đến những khách hàng phản hồi một đề nghị, các yếu tố liên quan nhiều nhất đến những bệnh nhân khỏe mạnh. | Độ dài Mô tả Tối thiểu - Coi mỗi thuộc tính là một mô hình dự đoán đơn giản của lớp mục tiêu và cung cấp ảnh hưởng tương đối. |
Thuật toán không giám sát khai thác dữ liệu của Oracle
| Kỹ thuật | Khả năng áp dụng | Thuật toán |
|---|---|---|
Phân cụm 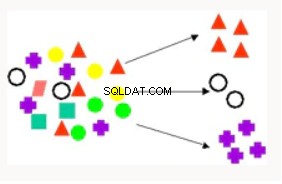 | Clustering được sử dụng để phân vùng các bản ghi của cơ sở dữ liệu thành các tập con hoặc cụm trong đó các phần tử trong một cụm chia sẻ một tập hợp các thuộc tính chung. Ví dụ bao gồm tìm phân khúc khách hàng mới và đề xuất Phim. | K-Means - Hỗ trợ khai thác văn bản, phân nhóm phân cấp, dựa trên khoảng cách. Orthogonal Partitioning Clustering - Phân cụm theo thứ bậc, dựa trên mật độ. Tối đa hóa kỳ vọng - Kỹ thuật phân cụm hoạt động tốt trong các vấn đề khai thác dữ liệu hỗn hợp (dày đặc và thưa thớt). |
Phát hiện Bất thường 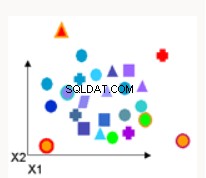 | Phát hiện bất thường xác định các điểm dữ liệu, sự kiện và / hoặc quan sát khác với hành vi bình thường của tập dữ liệu. Các ví dụ phổ biến bao gồm gian lận ngân hàng, khiếm khuyết về cấu trúc, các vấn đề y tế hoặc lỗi trong văn bản | Máy vectơ hỗ trợ một lớp - đào tạo dữ liệu chưa được gắn thẻ và cố gắng xác định xem điểm kiểm tra có thuộc phân phối dữ liệu đào tạo hay không. |
Lựa chọn và Trích xuất Tính năng 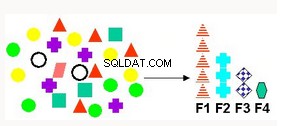 | Tạo ra các thuộc tính mới dưới dạng kết hợp tuyến tính của các thuộc tính hiện có. Có thể áp dụng cho dữ liệu văn bản, phân tích ngữ nghĩa tiềm ẩn (LSA), nén dữ liệu, phân rã và chiếu dữ liệu cũng như nhận dạng mẫu. | Dữ liệu gốc ma trận không phủ định - Ánh xạ dữ liệu ban đầu vào tập hợp các thuộc tính mới. thuộc tính. Phân hủy véc tơ đơn lẻ - phương pháp trích xuất tính năng được thiết lập có nhiều ứng dụng. |
Liên kết  | Tìm các quy tắc liên quan đến các mặt hàng thường xuyên xuất hiện, được sử dụng để phân tích giỏ thị trường, bán kèm, phân tích nguyên nhân gốc rễ. Hữu ích cho việc đóng gói sản phẩm và phân tích lỗi. | Apriori - Băm cây để thu thập thông tin trong cơ sở dữ liệu |
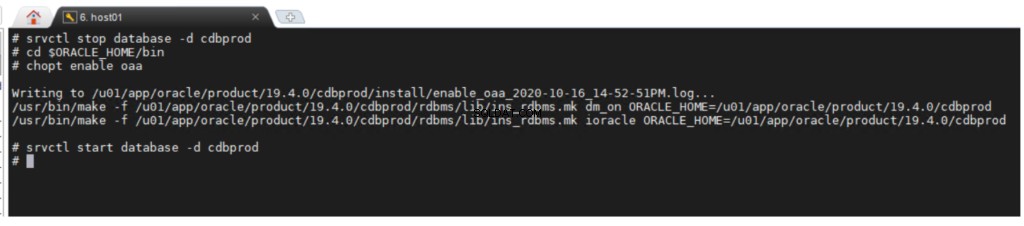
Bật tùy chọn khai thác dữ liệu Oracle
Từ 12c Release 2, Phân tích nâng cao của Oracle Tùy chọn bao gồm chức năng Khai thác dữ liệu và Oracle R.
Tùy chọn Oracle Advanced Analytics được bật theo mặc định trong khi cài đặt Oracle Database Enterprise Edition. Nếu bạn muốn bật hoặc tắt tùy chọn cơ sở dữ liệu, bạn có thể sử dụng tiện ích dòng lệnh chopt .
chopt [ enable | disable ] oaa
Để bật tùy chọn Phân tích nâng cao của Oracle:
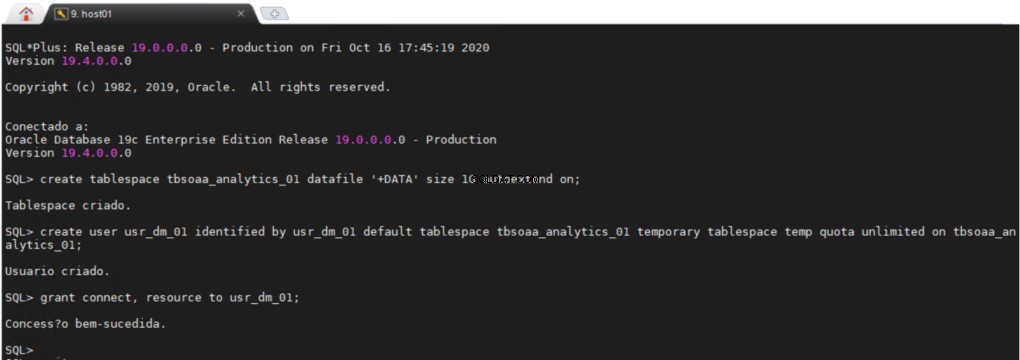
Tạo không gian bảng một lược đồ ODM
Tất cả người dùng yêu cầu một vùng bảng vĩnh viễn và một vùng bảng tạm thời để thực hiện công việc của họ, có thể rất hữu ích nếu có một vùng riêng biệt trong cơ sở dữ liệu của bạn, nơi bạn có thể tạo tất cả các đối tượng khai thác dữ liệu của mình.
usr_dm_01 lược đồ sẽ chứa tất cả các hoạt động Khai thác dữ liệu của bạn.
Tạo kho lưu trữ ODM
Bạn cần tạo Kho lưu trữ khai thác dữ liệu Oracle trong cơ sở dữ liệu. Đi tới Bộ điều hướng khai thác dữ liệu trong Nhà phát triển SQL.
Chọn Xem -> Công cụ khai thác dữ liệu -> Kết nối công cụ khai thác dữ liệu:
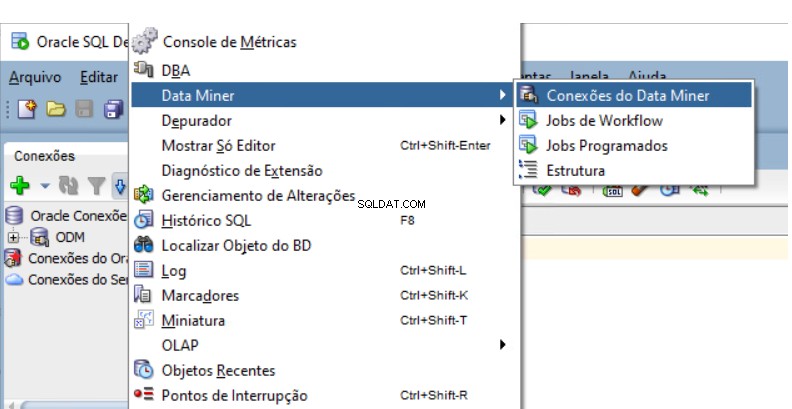
Một tab mới sẽ mở ra bên cạnh tab Kết nối hiện có của bạn:
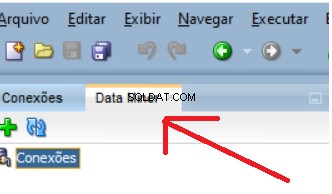
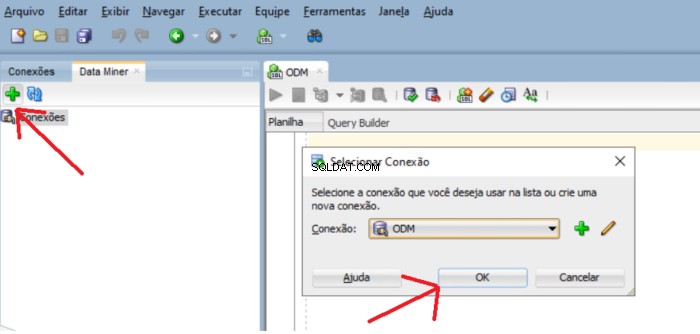
Để thêm usr_dm_01 lược đồ cho danh sách này, nhấp vào cửa sổ dấu cộng màu xanh lục và OK
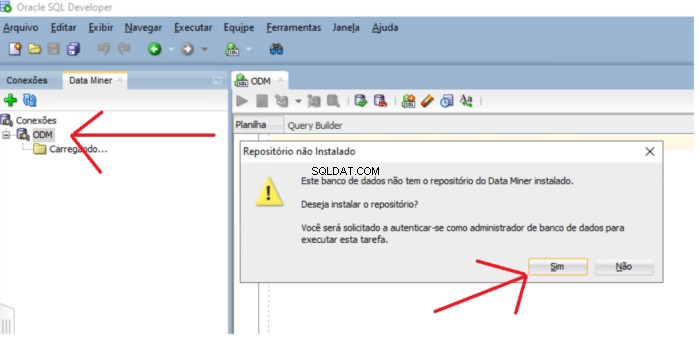
Nếu kho lưu trữ không tồn tại, một màn hình hiển thị thông báo hỏi bạn có muốn cài đặt kho lưu trữ hay không. Nhấp vào nút Có để tiếp tục cài đặt.
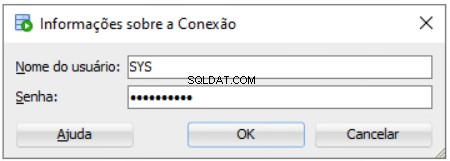
Bạn cần nhập mật khẩu SYS
Cài đặt Kho lưu trữ
Cài đặt cửa sổ tiến trình Kho lưu trữ Data Miner
Nhiệm vụ đã hoàn thành thành công
Tệp nhật ký
Các thành phần khai thác dữ liệu của Oracle
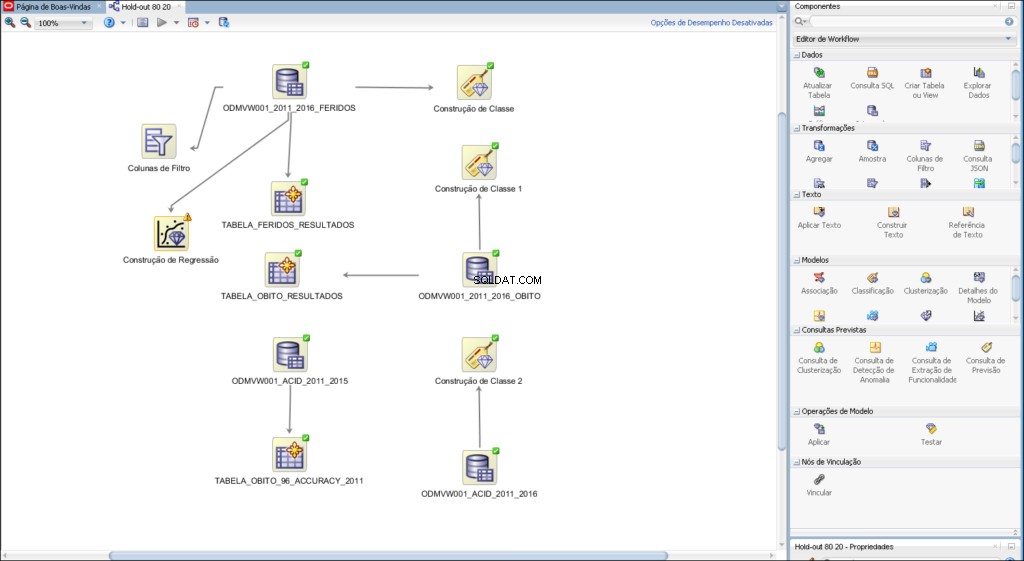
Quy trình làm việc cho phép bạn tạo một chuỗi các nút thực hiện tất cả các xử lý cần thiết trên dữ liệu của bạn.
Ví dụ về quy trình làm việc được phát triển cho phân tích dự đoán
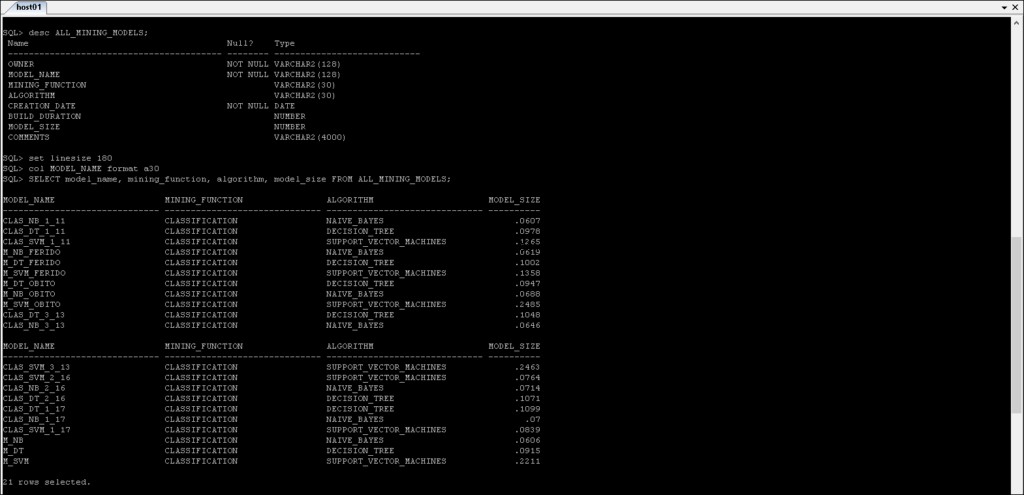
Chế độ xem từ điển dữ liệu ODM
Bạn có thể lấy thông tin về các mô hình khai thác từ từ điển dữ liệu.
Chế độ xem từ điển dữ liệu Khai thác dữ liệu được tóm tắt như sau:
Lưu ý: * có thể được thay thế bằng ALL_, USER_, DBA_ và CDB_
* _MINING_MODELS :Thông tin về các mô hình khai thác đã được tạo.
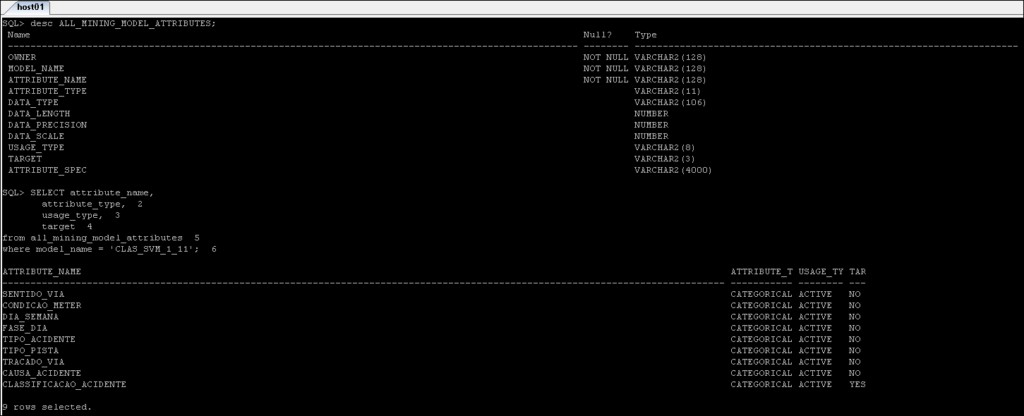
* _MINING_MODEL_ATTRIBUTES :Chứa chi tiết về các thuộc tính đã được sử dụng để tạo ra mô hình Khai thác dữ liệu Oracle.
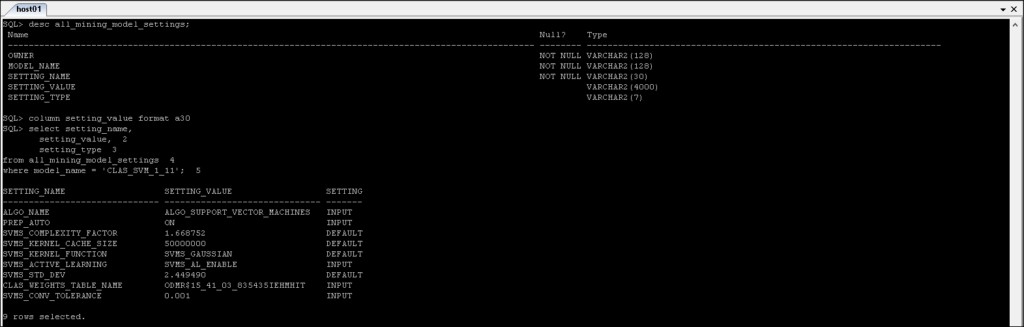
* _MINING_MODEL_SETTINGS :Trả về thông tin về cài đặt cho các mô hình khai thác mà bạn có quyền truy cập.
Tài liệu tham khảo
Hướng dẫn sử dụng khai thác dữ liệu Oracle. Có tại:https://docs.oracle.com/en/database/oracle/oracle-database/19/dmprg/lot.html
Khai thác dữ liệu Oracle - Phân tích dự đoán trong cơ sở dữ liệu có thể mở rộng. Có tại:https://www.oracle.com/database/technologies/advanced-analytics/odm.html
Tổng quan về Hệ thống Khai thác Dữ liệu Oracle. Có tại:https://docs.oracle.com/database/sql-developer-17.4/DMRIG/oracle-data-miner-overview.htm#DMRIG124