Bài viết này là phần thứ năm trong loạt bài về các biểu thức bảng. Trong Phần 1, tôi đã cung cấp nền tảng cho các biểu thức bảng. Trong Phần 2, Phần 3 và Phần 4, tôi đã đề cập đến cả khía cạnh logic và tối ưu hóa của các bảng dẫn xuất. Tháng này, tôi bắt đầu đề cập đến các biểu thức bảng phổ biến (CTE). Giống như với các bảng dẫn xuất, trước tiên tôi sẽ đề cập đến việc xử lý hợp lý các CTE và trong tương lai, tôi sẽ xem xét việc tối ưu hóa.
Trong các ví dụ của mình, tôi sẽ sử dụng cơ sở dữ liệu mẫu có tên là TSQLV5. Bạn có thể tìm thấy tập lệnh tạo và điền nó tại đây và sơ đồ ER của nó tại đây.
CTE
Hãy bắt đầu với thuật ngữ biểu thức bảng thông thường . Thuật ngữ này cũng như từ viết tắt CTE của nó đều không xuất hiện trong thông số kỹ thuật tiêu chuẩn SQL ISO / IEC. Vì vậy, có thể thuật ngữ này bắt nguồn từ một trong những sản phẩm cơ sở dữ liệu và sau đó được một số nhà cung cấp cơ sở dữ liệu khác chấp nhận. Bạn có thể tìm thấy nó trong tài liệu của Microsoft SQL Server và Azure SQL Database. T-SQL hỗ trợ nó bắt đầu với SQL Server 2005. Tiêu chuẩn sử dụng thuật ngữ biểu thức truy vấn để biểu diễn một biểu thức xác định một hoặc nhiều CTE, bao gồm cả truy vấn bên ngoài. Nó sử dụng thuật ngữ với phần tử danh sách để đại diện cho cái mà T-SQL gọi là CTE. Tôi sẽ sớm cung cấp cú pháp cho biểu thức truy vấn.
Nguồn của thuật ngữ sang một bên, biểu thức bảng chung hoặc CTE , là thuật ngữ thường được các học viên T-SQL sử dụng cho cấu trúc là trọng tâm của bài viết này. Vì vậy, trước tiên, hãy giải quyết xem đó có phải là một thuật ngữ thích hợp hay không. Chúng tôi đã kết luận rằng thuật ngữ biểu thức bảng thích hợp cho một biểu thức trả về một bảng về mặt khái niệm. Bảng gốc, CTE, dạng xem và các hàm có giá trị trong bảng nội tuyến là tất cả các loại biểu thức bảng được đặt tên mà T-SQL hỗ trợ. Vì vậy, biểu thức bảng một phần của biểu thức bảng chung chắc chắn có vẻ thích hợp. Về phần chung một phần của thuật ngữ, nó có thể liên quan đến một trong những ưu điểm thiết kế của CTE so với các bảng dẫn xuất. Hãy nhớ rằng bạn không thể sử dụng lại tên bảng dẫn xuất (hoặc chính xác hơn là tên biến phạm vi) nhiều lần trong truy vấn bên ngoài. Ngược lại, tên CTE có thể được sử dụng nhiều lần trong truy vấn bên ngoài. Nói cách khác, tên CTE là phổ biến cho truy vấn bên ngoài. Tất nhiên, tôi sẽ trình bày khía cạnh thiết kế này trong bài viết này.
CTE cung cấp cho bạn những lợi ích tương tự đối với các bảng dẫn xuất, bao gồm cho phép phát triển các giải pháp mô-đun, sử dụng lại bí danh cột, tương tác gián tiếp với các hàm cửa sổ trong các mệnh đề thường không cho phép chúng, hỗ trợ các sửa đổi gián tiếp dựa vào TOP hoặc OFFSET FETCH với đặc điểm thứ tự, và những người khác. Nhưng có một số ưu điểm về thiết kế so với các bảng dẫn xuất, mà tôi sẽ trình bày chi tiết sau khi tôi cung cấp cú pháp cho cấu trúc.
Cú pháp
Đây là cú pháp tiêu chuẩn cho một biểu thức truy vấn:
7.17
Chức năng
Chỉ định một bảng.
Định dạng
[
[
AS
|
[
|
[
|
[
|
[
<đặc tả truy vấn> |
GÓP LẠI [BẰNG
FETCH {FIRST | NEXT} [
|
7.18
Chức năng
Chỉ định việc tạo thông tin phát hiện thứ tự và chu trình trong kết quả của biểu thức truy vấn đệ quy.
Định dạng
TÌM KIẾM
CHẾT ĐẦU BẰNG
CYCLE
DEFAULT
7.3
Chức năng
Chỉ định một tập hợp các
Thuật ngữ chuẩn biểu thức truy vấn đại diện cho một biểu thức liên quan đến mệnh đề WITH, một với danh sách , được tạo từ một hoặc nhiều với các phần tử danh sách và một truy vấn bên ngoài. T-SQL đề cập đến tiêu chuẩn với phần tử danh sách với tư cách là một CTE.
T-SQL không hỗ trợ tất cả các phần tử cú pháp chuẩn. Ví dụ:nó không hỗ trợ một số phần tử truy vấn đệ quy nâng cao hơn cho phép bạn kiểm soát hướng tìm kiếm và xử lý các chu trình trong cấu trúc đồ thị. Truy vấn đệ quy là trọng tâm của bài viết tháng tới.
Đây là cú pháp T-SQL cho một truy vấn đơn giản đối với CTE:
Dưới đây là ví dụ cho một truy vấn đơn giản đối với một CTE đại diện cho khách hàng Hoa Kỳ:
Bạn sẽ tìm thấy ba phần giống nhau trong một câu lệnh đối với CTE giống như cách bạn làm với một câu lệnh đối với bảng dẫn xuất:
Điều khác biệt về thiết kế của CTE so với các bảng dẫn xuất là vị trí của ba phần tử này trong mã. Với các bảng dẫn xuất, truy vấn bên trong được lồng trong mệnh đề FROM của truy vấn bên ngoài và tên của biểu thức bảng được chỉ định sau chính biểu thức bảng. Các yếu tố được sắp xếp đan xen vào nhau. Ngược lại, với CTE, mã phân tách ba phần tử:đầu tiên bạn gán tên biểu thức bảng; thứ hai, bạn chỉ định biểu thức bảng — từ đầu đến cuối không bị gián đoạn; thứ ba, bạn chỉ định truy vấn bên ngoài — từ đầu đến cuối mà không bị gián đoạn. Sau đó, trong phần “Cân nhắc về thiết kế”, tôi sẽ giải thích ý nghĩa của những khác biệt về thiết kế này.
Một từ về CTE và việc sử dụng dấu chấm phẩy làm dấu chấm câu lệnh. Thật không may, không giống như SQL tiêu chuẩn, T-SQL không buộc bạn phải kết thúc tất cả các câu lệnh bằng dấu chấm phẩy. Tuy nhiên, có rất ít trường hợp trong T-SQL mà không có dấu chấm dứt thì mã không rõ ràng. Trong những trường hợp đó, việc chấm dứt hợp đồng là bắt buộc. Một trường hợp như vậy liên quan đến thực tế là mệnh đề WITH được sử dụng cho nhiều mục đích. Một là xác định CTE, một là xác định gợi ý bảng cho một truy vấn và có một vài trường hợp sử dụng bổ sung. Ví dụ, trong câu lệnh sau, mệnh đề WITH được sử dụng để buộc mức cách ly có thể nối tiếp hóa với gợi ý bảng:
Khả năng mơ hồ là khi bạn có một câu lệnh chưa kết thúc trước định nghĩa CTE, trong trường hợp đó, trình phân tích cú pháp có thể không biết liệu mệnh đề WITH thuộc câu lệnh thứ nhất hay thứ hai. Dưới đây là một ví dụ chứng minh điều này:
Ở đây trình phân tích cú pháp không thể cho biết mệnh đề WITH được sử dụng để xác định gợi ý bảng cho bảng Khách hàng trong câu lệnh đầu tiên hay bắt đầu định nghĩa CTE. Bạn gặp lỗi sau:
Tất nhiên, bản sửa lỗi là chấm dứt câu lệnh trước định nghĩa CTE, nhưng như một phương pháp hay nhất, bạn thực sự nên chấm dứt tất cả các câu lệnh của mình:
Bạn có thể nhận thấy rằng một số người bắt đầu định nghĩa CTE của họ bằng dấu chấm phẩy như một cách thực hành, như sau:
Mục đích của phương pháp này là giảm thiểu khả năng xảy ra lỗi trong tương lai. Điều gì sẽ xảy ra nếu sau đó, ai đó thêm một câu lệnh chưa kết thúc ngay trước định nghĩa CTE của bạn trong tập lệnh và không bận tâm đến việc kiểm tra tập lệnh hoàn chỉnh, thay vì chỉ phát biểu của họ? Dấu chấm phẩy của bạn ngay trước mệnh đề WITH trở thành dấu chấm dứt câu lệnh của chúng. Bạn chắc chắn có thể thấy tính thực tế của cách làm này, nhưng nó hơi mất tự nhiên. Điều được khuyến nghị, mặc dù khó đạt được hơn, là áp dụng các phương pháp lập trình tốt trong tổ chức, bao gồm cả việc chấm dứt tất cả các tuyên bố.
Về mặt các quy tắc cú pháp áp dụng cho biểu thức bảng được sử dụng làm truy vấn bên trong trong định nghĩa CTE, chúng giống như các quy tắc áp dụng cho biểu thức bảng được sử dụng làm truy vấn bên trong trong định nghĩa bảng dẫn xuất. Đó là:
Để biết chi tiết, hãy xem phần “Biểu thức bảng là một bảng” trong Phần 2 của loạt bài này.
Nếu bạn khảo sát các nhà phát triển T-SQL có kinh nghiệm về việc họ thích sử dụng bảng dẫn xuất hay CTE, thì không phải ai cũng đồng ý về cách nào tốt hơn. Đương nhiên, những người khác nhau có sở thích tạo kiểu tóc khác nhau. Đôi khi tôi sử dụng các bảng dẫn xuất và đôi khi là CTE. Sẽ rất tốt nếu bạn có thể xác định một cách có ý thức sự khác biệt về thiết kế ngôn ngữ cụ thể giữa hai công cụ và lựa chọn dựa trên mức độ ưu tiên của bạn trong bất kỳ giải pháp nhất định nào. Với thời gian và kinh nghiệm, bạn đưa ra lựa chọn của mình một cách trực quan hơn.
Hơn nữa, điều quan trọng là không được nhầm lẫn giữa việc sử dụng các biểu thức bảng và bảng tạm thời, mà đó là một cuộc thảo luận liên quan đến hiệu suất mà tôi sẽ đề cập trong một bài viết trong tương lai.
CTE có khả năng truy vấn đệ quy và các bảng dẫn xuất thì không. Vì vậy, nếu bạn cần dựa vào những thứ đó, bạn sẽ sử dụng CTE một cách tự nhiên. Truy vấn đệ quy là trọng tâm của bài viết tháng tới.
Trong Phần 2, tôi đã giải thích rằng tôi thấy việc lồng các bảng dẫn xuất làm tăng thêm độ phức tạp cho mã, vì nó làm cho nó khó tuân theo logic. Tôi đã cung cấp ví dụ sau, xác định các năm đặt hàng trong đó hơn 70 khách hàng đã đặt hàng:
CTE không hỗ trợ lồng ghép. Vì vậy, khi bạn xem xét hoặc khắc phục sự cố một giải pháp dựa trên CTE, bạn sẽ không bị lạc vào logic lồng ghép. Thay vì lồng vào nhau, bạn xây dựng nhiều giải pháp mô-đun hơn bằng cách xác định nhiều CTE trong cùng một câu lệnh WITH, được phân tách bằng dấu phẩy. Mỗi CTE dựa trên một truy vấn được viết từ đầu đến cuối mà không bị gián đoạn. Tôi thấy đó là một điều tốt từ góc độ mã rõ ràng và khả năng bảo trì.
Đây là một giải pháp cho nhiệm vụ nói trên bằng cách sử dụng CTE:
Tôi thích giải pháp dựa trên CTE hơn. Nhưng một lần nữa, hãy hỏi các nhà phát triển có kinh nghiệm xem họ thích giải pháp nào trong số hai giải pháp trên và họ sẽ không đồng ý. Một số thực sự thích logic lồng nhau hơn và có thể xem mọi thứ ở một nơi.
Một lợi thế rất rõ ràng của CTE so với các bảng dẫn xuất, là khi bạn cần tương tác với nhiều trường hợp của cùng một biểu thức bảng trong giải pháp của mình. Hãy nhớ ví dụ sau dựa trên các bảng dẫn xuất từ Phần 2 trong loạt bài này:
Giải pháp này trả về số năm đặt hàng, số lượng đơn đặt hàng mỗi năm và sự khác biệt giữa số năm hiện tại và năm trước. Có, bạn có thể làm điều đó dễ dàng hơn với hàm LAG, nhưng trọng tâm của tôi ở đây không phải là tìm ra cách tốt nhất để đạt được nhiệm vụ rất cụ thể này. Tôi sử dụng ví dụ này để minh họa các khía cạnh thiết kế ngôn ngữ nhất định của các biểu thức bảng được đặt tên.
Vấn đề với giải pháp này là bạn không thể gán tên cho biểu thức bảng và sử dụng lại nó trong cùng một bước xử lý truy vấn logic. Bạn đặt tên một bảng dẫn xuất sau chính biểu thức bảng trong mệnh đề FROM. Nếu bạn xác định và đặt tên một bảng dẫn xuất làm đầu vào đầu tiên của một phép nối, bạn cũng không thể sử dụng lại tên bảng dẫn xuất đó làm đầu vào thứ hai của cùng một phép nối. Nếu bạn cần tự nối hai phiên bản của cùng một biểu thức bảng, với các bảng dẫn xuất, bạn không có lựa chọn nào khác ngoài việc sao chép mã. Đó là những gì bạn đã làm trong ví dụ trên. Ngược lại, tên CTE được chỉ định làm phần tử đầu tiên của mã trong số ba phần tử nói trên (tên CTE, truy vấn bên trong, truy vấn bên ngoài). Theo thuật ngữ xử lý truy vấn lôgic, vào thời điểm bạn truy cập vào truy vấn bên ngoài, tên CTE đã được xác định và có sẵn. Điều này có nghĩa là bạn có thể tương tác với nhiều trường hợp của tên CTE trong truy vấn bên ngoài, như sau:
Giải pháp này có lợi thế về khả năng lập trình rõ ràng so với giải pháp dựa trên các bảng dẫn xuất ở chỗ bạn không cần phải duy trì hai bản sao của cùng một biểu thức bảng. Còn nhiều điều cần nói từ góc độ xử lý vật lý và so sánh với việc sử dụng các bảng tạm thời, nhưng tôi sẽ làm như vậy trong một bài viết tập trung vào hiệu suất trong tương lai.
Một lợi thế mà mã dựa trên các bảng dẫn xuất có được so với mã dựa trên CTE là có thuộc tính đóng mà một biểu thức bảng được cho là có. Hãy nhớ rằng thuộc tính đóng của một biểu thức quan hệ nói rằng cả đầu vào và đầu ra đều là quan hệ và do đó, một biểu thức quan hệ có thể được sử dụng khi một quan hệ được mong đợi, làm đầu vào cho một biểu thức quan hệ khác. Tương tự, một biểu thức bảng trả về một bảng và được cho là sẵn dùng làm bảng đầu vào cho một biểu thức bảng khác. Điều này đúng với một truy vấn dựa trên các bảng dẫn xuất — bạn có thể sử dụng nó khi một bảng được mong đợi. Ví dụ:bạn có thể sử dụng truy vấn dựa trên các bảng dẫn xuất làm truy vấn bên trong của định nghĩa CTE, như trong ví dụ sau:
Tuy nhiên, điều này không đúng đối với một truy vấn dựa trên CTE. Mặc dù về mặt khái niệm nó được coi là một biểu thức bảng, bạn không thể sử dụng nó làm truy vấn bên trong trong các định nghĩa bảng dẫn xuất, truy vấn con và chính CTE. Ví dụ:mã sau không hợp lệ trong T-SQL:
Tin tốt là bạn có thể sử dụng truy vấn dựa trên CTE làm truy vấn bên trong trong các chế độ xem và các hàm có giá trị bảng nội tuyến, mà tôi sẽ đề cập trong các bài viết trong tương lai.
Ngoài ra, hãy nhớ rằng bạn luôn có thể xác định một CTE khác dựa trên truy vấn cuối cùng và sau đó yêu cầu truy vấn ngoài cùng tương tác với CTE đó:
Từ quan điểm khắc phục sự cố, như đã đề cập, tôi thường thấy việc tuân theo logic của mã dựa trên CTE dễ dàng hơn so với mã dựa trên bảng dẫn xuất. Tuy nhiên, các giải pháp dựa trên các bảng dẫn xuất có một lợi thế là bạn có thể đánh dấu bất kỳ mức lồng ghép nào và chạy nó một cách độc lập, như thể hiện trong Hình 1.
Với CTEs, mọi thứ phức tạp hơn. Để mã liên quan đến CTE có thể chạy được, nó phải bắt đầu bằng mệnh đề WITH, theo sau là một hoặc nhiều biểu thức bảng được đặt tên trong ngoặc đơn được phân tách bằng dấu phẩy, theo sau là truy vấn không dấu ngoặc đơn không có dấu phẩy đứng trước. Bạn có thể đánh dấu và chạy bất kỳ truy vấn bên trong nào thực sự độc lập, cũng như mã của giải pháp hoàn chỉnh; tuy nhiên, bạn không thể đánh dấu và chạy thành công bất kỳ phần trung gian nào khác của giải pháp. Ví dụ:Hình 2 cho thấy một nỗ lực không thành công để chạy mã đại diện cho C2.
Vì vậy, với CTE, bạn phải sử dụng các phương tiện hơi khó xử để có thể khắc phục sự cố ở bước trung gian của giải pháp. Ví dụ:một giải pháp phổ biến là tạm thời đưa vào một truy vấn SELECT * FROM your_cte ngay bên dưới CTE có liên quan. Sau đó, bạn đánh dấu và chạy mã bao gồm cả truy vấn được đưa vào và khi hoàn tất, bạn xóa truy vấn được chèn. Hình 3 thể hiện kỹ thuật này.
Vấn đề là bất cứ khi nào bạn thực hiện các thay đổi đối với mã — ngay cả những thay đổi nhỏ tạm thời như ở trên — có khả năng khi bạn cố gắng hoàn nguyên về mã ban đầu, bạn sẽ gặp phải một lỗi mới.
Một tùy chọn khác là tạo kiểu mã của bạn hơi khác một chút, sao cho mỗi định nghĩa CTE không phải đầu tiên bắt đầu bằng một dòng mã riêng biệt trông giống như sau:
Sau đó, bất cứ khi nào bạn muốn chạy một phần trung gian của mã xuống một CTE nhất định, bạn có thể làm như vậy với những thay đổi tối thiểu đối với mã của mình. Sử dụng nhận xét dòng, bạn chỉ nhận xét một dòng mã tương ứng với CTE đó. Sau đó, bạn đánh dấu và chạy mã xuống và bao gồm cả truy vấn bên trong của CTE, hiện được coi là truy vấn ngoài cùng, như được minh họa trong Hình 4.
Nếu không hài lòng với phong cách này, bạn vẫn có một lựa chọn khác. Bạn có thể sử dụng một nhận xét khối bắt đầu ngay trước dấu phẩy đứng trước CTE quan tâm và kết thúc sau dấu ngoặc đơn mở, như được minh họa trong Hình 5.
Nó phụ thuộc vào sở thích cá nhân. Tôi thường sử dụng kỹ thuật truy vấn SELECT * được chèn tạm thời.
Có một hạn chế nhất định trong hỗ trợ của T-SQL cho các hàm tạo giá trị bảng so với tiêu chuẩn. Nếu bạn không quen thuộc với cấu trúc, hãy nhớ xem Phần 2 của loạt bài trước, nơi tôi mô tả chi tiết về cấu trúc này. Trong khi T-SQL cho phép bạn xác định bảng dẫn xuất dựa trên phương thức tạo giá trị bảng, nó không cho phép bạn xác định CTE dựa trên phương thức tạo giá trị bảng.
Dưới đây là một ví dụ được hỗ trợ sử dụng bảng dẫn xuất:
Rất tiếc, mã tương tự sử dụng CTE không được hỗ trợ:
Mã này tạo ra lỗi sau:
Tuy nhiên, có một số cách giải quyết. Một là sử dụng truy vấn chống lại bảng dẫn xuất, đến lượt nó lại dựa trên hàm tạo giá trị bảng, như truy vấn bên trong của CTE, như sau:
Một phương pháp khác là sử dụng kỹ thuật mà mọi người đã sử dụng trước khi các hàm tạo giá trị bảng được đưa vào T-SQL — sử dụng một loạt các truy vấn FROMless được phân tách bằng các toán tử UNION ALL, như sau:
Lưu ý rằng bí danh cột được gán ngay sau tên CTE.
Hai phương pháp được đại số hóa và tối ưu hóa giống nhau, vì vậy hãy sử dụng phương pháp nào bạn cảm thấy thoải mái hơn.
Một công cụ mà tôi sử dụng khá thường xuyên trong các giải pháp của mình là một bảng số bổ trợ. Một tùy chọn là tạo một bảng số thực trong cơ sở dữ liệu của bạn và điền nó bằng một chuỗi có kích thước hợp lý. Một giải pháp khác là phát triển một giải pháp tạo ra một chuỗi số đang bay. Đối với tùy chọn thứ hai, bạn muốn các đầu vào là dấu phân cách của phạm vi mong muốn (chúng tôi sẽ gọi chúng là
Mã này tạo ra kết quả sau:
CTE đầu tiên được gọi là L0 dựa trên một hàm tạo giá trị bảng có hai hàng. Các giá trị thực tế ở đó là không đáng kể; điều quan trọng là nó có hai hàng. Sau đó, có một chuỗi năm CTE bổ sung được đặt tên từ L1 đến L5, mỗi CTE áp dụng phép nối chéo giữa hai phiên bản của CTE trước đó. Đoạn mã sau sẽ tính toán số hàng có thể được tạo bởi mỗi CTE, trong đó @L là số cấp CTE:
Dưới đây là những con số mà bạn nhận được cho mỗi CTE:
Lên đến cấp độ 5 cung cấp cho bạn hơn bốn tỷ hàng. Điều này là đủ cho bất kỳ trường hợp sử dụng thực tế nào mà tôi có thể nghĩ đến. Bước tiếp theo diễn ra trong CTE được gọi là Nums. Bạn sử dụng hàm ROW_NUMBER để tạo một chuỗi các số nguyên bắt đầu bằng 1 dựa trên không có thứ tự xác định (ORDER BY (SELECT NULL)) và đặt tên cho cột kết quả là rownum. Cuối cùng, truy vấn bên ngoài sử dụng bộ lọc TOP dựa trên thứ tự rownum để lọc bao nhiêu số theo thứ tự mong muốn (@high - @low + 1) và tính số kết quả n là @low + rownum - 1.
Tại đây, bạn thực sự có thể đánh giá cao vẻ đẹp trong thiết kế CTE và sự tiết kiệm mà nó mang lại khi bạn xây dựng các giải pháp theo kiểu mô-đun. Cuối cùng, quá trình unnesting giải nén 32 bảng, mỗi bảng bao gồm hai hàng dựa trên các hằng số. Có thể thấy rõ điều này trong kế hoạch thực thi cho đoạn mã này, như trong Hình 6 bằng cách sử dụng SentryOne Plan Explorer.
Mỗi toán tử quét hằng đại diện cho một bảng hằng số có hai hàng. Vấn đề là, toán tử Top là người yêu cầu các hàng đó và nó ngắn mạch sau khi nhận được số lượng mong muốn. Lưu ý 10 hàng được chỉ ra phía trên mũi tên chảy vào toán tử Trên cùng.
Tôi biết rằng trọng tâm của bài viết này là việc xử lý khái niệm CTE chứ không phải xem xét vật lý / hiệu suất, nhưng bằng cách nhìn vào kế hoạch, bạn thực sự có thể đánh giá cao tính ngắn gọn của mã so với độ dài dòng của những gì nó chuyển sang hậu trường.
Sử dụng các bảng dẫn xuất, bạn thực sự có thể viết một giải pháp thay thế mỗi tham chiếu CTE bằng truy vấn cơ bản mà nó đại diện. Những gì bạn nhận được khá đáng sợ:
Obviously, you don’t want to write a solution like this, but it’s a good way to illustrate what SQL Server does behind the scenes with your CTE code.
If you were really planning to write a solution based on derived tables, instead of using the above nested approach, you’d be better off simplifying the logic to a single query with 31 cross joins between 32 table value constructors, each based on two rows, like so:
Still, the solution based on CTEs is obviously significantly simpler. The plans are identical.
CTEs can be used as the source and target tables in INSERT, UPDATE, DELETE and MERGE statements. They cannot be used in the TRUNCATE statement.
The syntax is pretty straightforward. You start the statement as usual with a WITH clause, followed by one or more CTEs separated by commas. Then you specify the outer modification statement, which interacts with the CTEs that were defined under the WITH clause as the source tables, target table, or both. Just like I explained in Part 2 about derived tables, also with CTEs what really gets modified is the underlying base table that the table expression uses. I’ll show a couple of examples using DELETE and UPDATE statements, but remember that you can use CTEs in MERGE and INSERT statements as well.
Here’s the general syntax of a DELETE statement against a CTE:
As an example (don’t actually run it), the following code deletes the 10 oldest orders:
Here’s the general syntax of an UPDATE statement against a CTE:
As an example, the following code updates the 10 oldest unshipped orders that have an overdue required date, increasing the required date to 10 days from today:
The code applies the update in a transaction that it then rolls back so that the change won’t stick.
This code generates the following output, showing both the old and the new required dates:
Of course you will get a different new required date based on when you run this code.
I like CTEs. They have a few advantages compared to derived tables. Instead of nesting the code, you define multiple CTEs separated by commas, typically leading to a more modular solution that is easier to review and maintain. Also, you can have multiple references to the same CTE name in the outer statement, so you don’t need to repeat the inner table expression’s code. However, unlike derived tables, CTEs cannot be defined directly based on a table value constructor, and you cannot highlight and execute some of the intermediate parts of the code. The following table summarizes the differences between derived tables and CTEs:
As the last item says, derived tables do not support recursive capabilities, whereas CTEs do. Recursive queries are the focus of next month’s article.
Định dạng
GIÁ TRỊ
[{WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
SELECT < select list >
FROM < table name >;
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
SELECT custid, country FROM Sales.Customers WITH (SERIALIZABLE);
SELECT custid, country FROM Sales.Customers
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC
Sai cú pháp gần 'UC'. Nếu đây là một biểu thức bảng thông thường, bạn cần phải kết thúc rõ ràng câu lệnh trước đó bằng dấu chấm phẩy. SELECT custid, country FROM Sales.Customers;
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
;WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
Cân nhắc thiết kế
SELECT orderyear, numcusts
FROM ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM ( SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders ) AS D1
GROUP BY orderyear ) AS D2
WHERE numcusts > 70; WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70;
SELECT CUR.orderyear, CUR.numorders,
CUR.numorders - PRV.numorders AS diff
FROM ( SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate) ) AS CUR
LEFT OUTER JOIN
( SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate) ) AS PRV
ON CUR.orderyear = PRV.orderyear + 1; WITH OrdCount AS
(
SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate)
)
SELECT CUR.orderyear, CUR.numorders,
CUR.numorders - PRV.numorders AS diff
FROM OrdCount AS CUR
LEFT OUTER JOIN OrdCount AS PRV
ON CUR.orderyear = PRV.orderyear + 1; WITH C AS
(
SELECT orderyear, numcusts
FROM ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM ( SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders ) AS D1
GROUP BY orderyear ) AS D2
WHERE numcusts > 70
)
SELECT orderyear, numcusts
FROM C; SELECT orderyear, custid
FROM (WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70) AS D; WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
),
C3 AS
(
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70
)
SELECT orderyear, numcusts
FROM C3;
 Hình 1:Có thể đánh dấu và chạy một phần mã với các bảng dẫn xuất
Hình 1:Có thể đánh dấu và chạy một phần mã với các bảng dẫn xuất  Hình 2:Không thể đánh dấu và chạy một phần mã bằng CTE
Hình 2:Không thể đánh dấu và chạy một phần mã bằng CTE  Hình 3:Chèn SELECT * bên dưới CTE có liên quan
Hình 3:Chèn SELECT * bên dưới CTE có liên quan , cte_name AS (
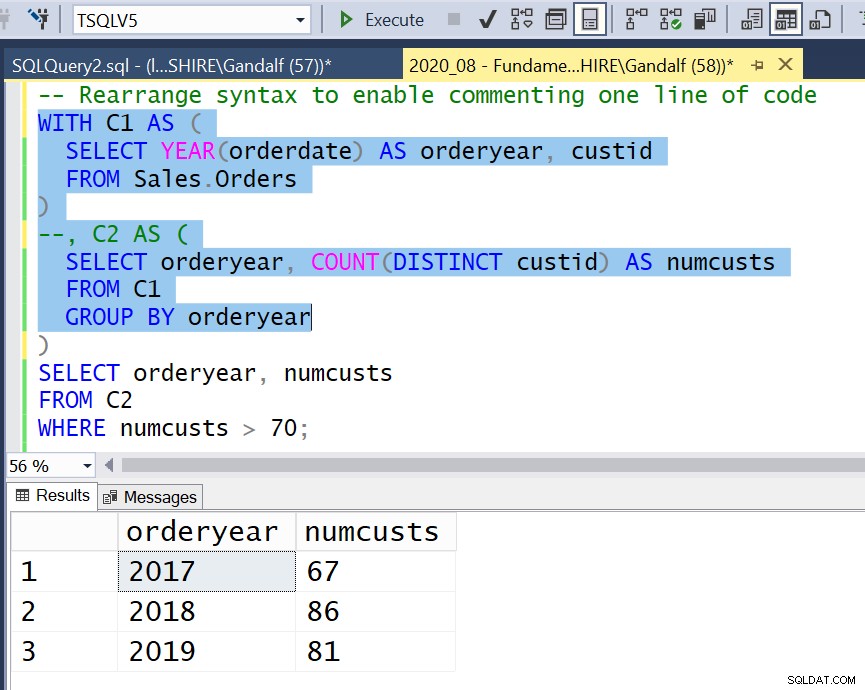 Hình 4:Sắp xếp lại cú pháp để cho phép nhận xét một dòng mã
Hình 4:Sắp xếp lại cú pháp để cho phép nhận xét một dòng mã  Hình 5:Sử dụng nhận xét khối
Hình 5:Sử dụng nhận xét khối Hàm tạo giá trị bảng
SELECT custid, companyname, contractdate
FROM ( VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' ) )
AS MyCusts(custid, companyname, contractdate); WITH MyCusts(custid, companyname, contractdate) AS
(
VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' )
)
SELECT custid, companyname, contractdate
FROM MyCusts;
Cú pháp không chính xác gần từ khóa 'VALUES'. WITH MyCusts AS
(
SELECT *
FROM ( VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' ) )
AS MyCusts(custid, companyname, contractdate)
)
SELECT custid, companyname, contractdate
FROM MyCusts; WITH MyCusts(custid, companyname, contractdate) AS
(
SELECT 2, 'Cust 2', '20200212'
UNION ALL SELECT 3, 'Cust 3', '20200118'
UNION ALL SELECT 5, 'Cust 5', '20200401'
)
SELECT custid, companyname, contractdate
FROM MyCusts; Tạo một dãy số
@low và @high ). Bạn muốn giải pháp của mình hỗ trợ các phạm vi tiềm năng lớn. Đây là giải pháp của tôi cho mục đích này, sử dụng CTE, với yêu cầu cho phạm vi 1001 đến 1010 trong ví dụ cụ thể sau:DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; n
-----
1001
1002
1003
1004
1005
1006
1007
1008
1009
1010
DECLARE @L AS INT = 5;
SELECT POWER(2., POWER(2., @L));
CTE Bản số L0 2 L1 4 L2 16 L3 256 L4 65.536 L5 4.294.967.296  Hình 6:Kế hoạch tạo truy vấn chuỗi số
Hình 6:Kế hoạch tạo truy vấn chuỗi số DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D7
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D8 ) AS D9
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D7
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D8 ) AS D10 ) AS Nums
ORDER BY rownum; DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN (VALUES(1),(1)) AS D02(c)
CROSS JOIN (VALUES(1),(1)) AS D03(c)
CROSS JOIN (VALUES(1),(1)) AS D04(c)
CROSS JOIN (VALUES(1),(1)) AS D05(c)
CROSS JOIN (VALUES(1),(1)) AS D06(c)
CROSS JOIN (VALUES(1),(1)) AS D07(c)
CROSS JOIN (VALUES(1),(1)) AS D08(c)
CROSS JOIN (VALUES(1),(1)) AS D09(c)
CROSS JOIN (VALUES(1),(1)) AS D10(c)
CROSS JOIN (VALUES(1),(1)) AS D11(c)
CROSS JOIN (VALUES(1),(1)) AS D12(c)
CROSS JOIN (VALUES(1),(1)) AS D13(c)
CROSS JOIN (VALUES(1),(1)) AS D14(c)
CROSS JOIN (VALUES(1),(1)) AS D15(c)
CROSS JOIN (VALUES(1),(1)) AS D16(c)
CROSS JOIN (VALUES(1),(1)) AS D17(c)
CROSS JOIN (VALUES(1),(1)) AS D18(c)
CROSS JOIN (VALUES(1),(1)) AS D19(c)
CROSS JOIN (VALUES(1),(1)) AS D20(c)
CROSS JOIN (VALUES(1),(1)) AS D21(c)
CROSS JOIN (VALUES(1),(1)) AS D22(c)
CROSS JOIN (VALUES(1),(1)) AS D23(c)
CROSS JOIN (VALUES(1),(1)) AS D24(c)
CROSS JOIN (VALUES(1),(1)) AS D25(c)
CROSS JOIN (VALUES(1),(1)) AS D26(c)
CROSS JOIN (VALUES(1),(1)) AS D27(c)
CROSS JOIN (VALUES(1),(1)) AS D28(c)
CROSS JOIN (VALUES(1),(1)) AS D29(c)
CROSS JOIN (VALUES(1),(1)) AS D30(c)
CROSS JOIN (VALUES(1),(1)) AS D31(c)
CROSS JOIN (VALUES(1),(1)) AS D32(c) ) AS Nums
ORDER BY rownum; Used in modification statements
WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
DELETE [ FROM ] <table name>
[ WHERE <filter predicate> ];
WITH OldestOrders AS
(
SELECT TOP (10) *
FROM Sales.Orders
ORDER BY orderdate, orderid
)
DELETE FROM OldestOrders;
WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
UPDATE <table name>
SET <assignments>
[ WHERE <filter predicate> ];
BEGIN TRAN;
WITH OldestUnshippedOrders AS
(
SELECT TOP (10) orderid, requireddate,
DATEADD(day, 10, CAST(SYSDATETIME() AS DATE)) AS newrequireddate
FROM Sales.Orders
WHERE shippeddate IS NULL
AND requireddate < CAST(SYSDATETIME() AS DATE)
ORDER BY orderdate, orderid
)
UPDATE OldestUnshippedOrders
SET requireddate = newrequireddate
OUTPUT
inserted.orderid,
deleted.requireddate AS oldrequireddate,
inserted.requireddate AS newrequireddate;
ROLLBACK TRAN; orderid oldrequireddate newrequireddate
----------- --------------- ---------------
11008 2019-05-06 2020-07-16
11019 2019-05-11 2020-07-16
11039 2019-05-19 2020-07-16
11040 2019-05-20 2020-07-16
11045 2019-05-21 2020-07-16
11051 2019-05-25 2020-07-16
11054 2019-05-26 2020-07-16
11058 2019-05-27 2020-07-16
11059 2019-06-10 2020-07-16
11061 2019-06-11 2020-07-16
(10 rows affected)
Tóm tắt
Item Derived table CTE Supports nesting Yes No Supports multiple references No Yes Supports table value constructor Yes No Can highlight and run part of code Yes No Supports recursion No Yes



