Bài viết này là phần thứ tư trong loạt bài về biểu thức bảng. Trong Phần 1 và Phần 2, tôi đã đề cập đến cách xử lý khái niệm của các bảng dẫn xuất. Trong Phần 3, tôi đã bắt đầu đề cập đến các cân nhắc tối ưu hóa của các bảng dẫn xuất. Tháng này, tôi đề cập đến các khía cạnh khác của việc tối ưu hóa các bảng dẫn xuất; đặc biệt, tôi tập trung vào việc thay thế / bỏ ghi chú các bảng dẫn xuất.
Trong các ví dụ của mình, tôi sẽ sử dụng cơ sở dữ liệu mẫu có tên là TSQLV5 và PerformanceV5. Bạn có thể tìm thấy tập lệnh tạo và điền TSQLV5 tại đây và sơ đồ ER của nó tại đây. Bạn có thể tìm thấy tập lệnh tạo và điền PerformanceV5 tại đây.
Bỏ chọn / thay thế
Bỏ chọn / thay thế các biểu thức bảng là một quá trình thực hiện một truy vấn liên quan đến việc lồng các biểu thức bảng và như thể thay thế nó bằng một truy vấn trong đó logic lồng nhau bị loại bỏ. Tôi nên nhấn mạnh rằng trên thực tế, không có quy trình thực tế nào trong đó SQL Server chuyển đổi chuỗi truy vấn ban đầu với logic lồng nhau thành chuỗi truy vấn mới mà không có chuỗi lồng nhau. Điều thực sự xảy ra là quá trình phân tích cú pháp truy vấn tạo ra một cây ban đầu gồm các toán tử logic phản ánh chặt chẽ truy vấn ban đầu. Sau đó, SQL Server áp dụng các phép biến đổi cho cây truy vấn này, loại bỏ một số bước không cần thiết, thu gọn nhiều bước thành ít bước hơn và di chuyển các toán tử xung quanh. Trong các phép biến đổi của nó, miễn là đáp ứng các điều kiện nhất định, SQL Server có thể thay đổi mọi thứ xung quanh những gì ban đầu là ranh giới biểu thức bảng — đôi khi hiệu quả như thể loại bỏ các đơn vị lồng nhau. Tất cả những điều này nhằm tìm ra một phương án tối ưu.
Trong bài viết này, tôi đề cập đến cả hai trường hợp mà việc hủy đăng ký đó diễn ra, cũng như các chất ức chế hủy đăng ký. Nghĩa là, khi bạn sử dụng các phần tử truy vấn nhất định, nó ngăn SQL Server không thể di chuyển các toán tử logic trong cây truy vấn, buộc nó phải xử lý các toán tử dựa trên ranh giới của các biểu thức bảng được sử dụng trong truy vấn ban đầu.
Tôi sẽ bắt đầu bằng cách trình bày một ví dụ đơn giản trong đó các bảng dẫn xuất không được xếp hạng. Tôi cũng sẽ chứng minh một ví dụ cho chất ức chế unnesting. Sau đó, tôi sẽ nói về các trường hợp bất thường trong đó việc hủy đăng ký có thể không mong muốn, dẫn đến lỗi hoặc suy giảm hiệu suất và trình bày cách ngăn chặn việc hủy đăng ký trong những trường hợp đó bằng cách sử dụng trình ức chế không đăng ký.
Truy vấn sau (chúng tôi sẽ gọi là Truy vấn 1) sử dụng nhiều lớp bảng dẫn xuất lồng nhau, trong đó mỗi biểu thức bảng áp dụng logic lọc cơ bản dựa trên các hằng số:
SELECT orderid, orderdateFROM (SELECT * FROM (SELECT * FROM (SELECT * FROM Sales.Orders WHERE orderdate> ='20180101') AS D1 WHERE orderdate> ='20180201') AS D2 WHERE orderdate> ='20180301') AS D3WHERE orderdate> ='20180401';
Như bạn có thể thấy, mỗi biểu thức trong bảng lọc một phạm vi ngày đặt hàng bắt đầu bằng một ngày khác. SQL Server bỏ logic truy vấn nhiều lớp này, cho phép nó sau đó hợp nhất bốn vị từ lọc thành một vị từ duy nhất đại diện cho giao điểm của cả bốn vị từ.
Kiểm tra kế hoạch cho Truy vấn 1 được hiển thị trong Hình 1.
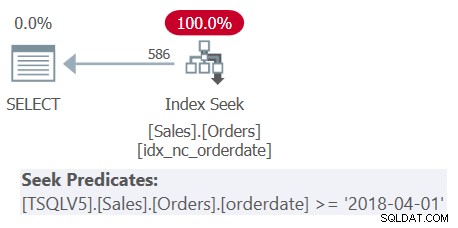 Hình 1:Kế hoạch cho Truy vấn 1
Hình 1:Kế hoạch cho Truy vấn 1
Quan sát rằng tất cả bốn vị từ lọc đã được hợp nhất thành một vị từ duy nhất đại diện cho giao điểm của bốn vị từ. Kế hoạch áp dụng một tìm kiếm trong chỉ mục idx_nc_orderdate dựa trên một vị từ hợp nhất duy nhất làm vị từ tìm kiếm. Chỉ mục này được xác định trên orderdate (rõ ràng), orderid (ngầm hiểu là do sự hiện diện của một chỉ mục nhóm trên orderid) làm các khóa chỉ mục.
Cũng lưu ý rằng mặc dù tất cả các biểu thức bảng đều sử dụng SELECT * và chỉ truy vấn ngoài cùng chiếu hai cột quan tâm:orderdate và orderid, chỉ mục nói trên được coi là bao trùm. Như tôi đã giải thích trong Phần 3, vì mục đích tối ưu hóa chẳng hạn như lựa chọn chỉ mục, SQL Server bỏ qua các cột từ các biểu thức bảng mà cuối cùng không có liên quan. Hãy nhớ rằng bạn cần phải có quyền truy vấn các cột đó.
Như đã đề cập, SQL Server sẽ cố gắng hủy bỏ biểu thức bảng, nhưng sẽ tránh được điều này nếu nó tình cờ trở thành một trình ức chế unnesting. Với một ngoại lệ nhất định mà tôi sẽ mô tả sau, việc sử dụng TOP hoặc OFFSET FETCH sẽ hạn chế việc bỏ ghi chú. Lý do là việc cố gắng hủy thiết lập một biểu thức bảng với TOP hoặc OFFSET FETCH có thể dẫn đến thay đổi ý nghĩa của truy vấn ban đầu.
Ví dụ:hãy xem xét truy vấn sau (chúng tôi sẽ gọi nó là Truy vấn 2):
SELECT orderid, orderdateFROM (SELECT TOP (9223372036854775807) * FROM (SELECT TOP (9223372036854775807) * FROM (SELECT TOP (9223372036854775807) * FROM Sales.Orders WHERE orderdate> ='20180101') AS D1 WHERE orderdate> ='20180201 ') AS D2 WHERE orderdate> =' 20180301 ') AS D3WHERE orderdate> =' 20180401 ';
Số hàng đầu vào của bộ lọc TOP là một giá trị được nhập BIGINT. Trong ví dụ này, tôi đang sử dụng giá trị BIGINT tối đa (2 ^ 63 - 1, tính toán trong T-SQL bằng cách sử dụng SELECT POWER (2., 63) - 1). Mặc dù bạn và tôi biết rằng bảng Đơn hàng của chúng ta sẽ không bao giờ có nhiều hàng như vậy và do đó bộ lọc TOP thực sự vô nghĩa, SQL Server phải tính đến khả năng lý thuyết để bộ lọc có ý nghĩa. Do đó, SQL Server không hủy hợp nhất các biểu thức bảng trong truy vấn này. Kế hoạch cho Truy vấn 2 được thể hiện trong Hình 2.
 Hình 2:Kế hoạch cho Truy vấn 2
Hình 2:Kế hoạch cho Truy vấn 2
Các trình ức chế unnesting đã ngăn SQL Server có thể hợp nhất các vị từ lọc, khiến hình dạng kế hoạch gần giống với truy vấn khái niệm hơn. Tuy nhiên, điều thú vị là SQL Server vẫn bỏ qua các cột cuối cùng không liên quan đến truy vấn ngoài cùng và do đó có thể sử dụng chỉ mục bao gồm trên orderdate, orderid.
Để minh họa lý do tại sao TOP và OFFSET-FETCH là những chất ức chế đáng chú ý, chúng ta hãy thực hiện một kỹ thuật tối ưu hóa vị từ đẩy xuống đơn giản. Vị từ đẩy xuống có nghĩa là trình tối ưu hóa đẩy một vị từ bộ lọc đến một điểm sớm hơn so với điểm ban đầu mà nó xuất hiện trong quá trình xử lý truy vấn logic. Ví dụ:giả sử rằng bạn có một truy vấn với cả phép nối bên trong và bộ lọc WHERE dựa trên một cột từ một trong các phía của phép nối. Về mặt xử lý truy vấn logic, bộ lọc WHERE phải được đánh giá sau khi kết hợp. Nhưng thường thì trình tối ưu hóa sẽ đẩy vị từ bộ lọc lên một bước trước khi tham gia, vì điều này khiến liên kết có ít hàng hơn để làm việc, thường dẫn đến một kế hoạch tối ưu hơn. Hãy nhớ rằng mặc dù các phép biến đổi như vậy chỉ được phép trong trường hợp ý nghĩa của truy vấn ban đầu được giữ nguyên, theo nghĩa là bạn được đảm bảo nhận được tập hợp kết quả chính xác.
Hãy xem xét đoạn mã sau, có một truy vấn bên ngoài với bộ lọc WHERE đối với bảng dẫn xuất, lần lượt dựa trên biểu thức bảng với bộ lọc TOP:
SELECT orderid, orderdateFROM (SELECT TOP (3) * FROM Sales.Orders) AS DWHERE orderdate> ='20180101';
Tất nhiên truy vấn này là không xác định do thiếu mệnh đề ORDER BY trong biểu thức bảng. Khi tôi chạy nó, SQL Server đã tình cờ truy cập ba hàng đầu tiên có ngày đặt hàng sớm hơn năm 2018, vì vậy tôi nhận được một tập hợp trống làm đầu ra:
orderid orderdate ----------- (0 hàng bị ảnh hưởng)
Như đã đề cập, việc sử dụng TOP trong biểu thức bảng đã ngăn chặn việc bỏ ghi chú / thay thế biểu thức bảng ở đây. Nếu SQL Server đã hủy thiết lập biểu thức bảng, thì quá trình thay thế sẽ dẫn đến kết quả tương đương với truy vấn sau:
SELECT TOP (3) orderid, orderdateFROM Sales.OrdersWHERE orderdate> ='20180101';
Truy vấn này cũng không xác định do thiếu mệnh đề ORDER BY, nhưng rõ ràng, nó có ý nghĩa khác với truy vấn ban đầu. Nếu bảng Sales.Orders có ít nhất ba đơn đặt hàng được đặt từ năm 2018 trở lên — và đúng như vậy — thì truy vấn này nhất thiết sẽ trả về ba hàng, không giống như truy vấn ban đầu. Đây là kết quả mà tôi nhận được khi chạy truy vấn này:
orderid orderdate ------------- 10400 2018-01-0110401 2018-01-0110402 2018-01-02 (3 hàng bị ảnh hưởng)
Trong trường hợp tính chất không xác định của hai truy vấn trên làm bạn bối rối, thì đây là một ví dụ về truy vấn xác định:
CHỌN orderid, orderdateFROM (CHỌN ĐẦU (3) * TỪ Sales.Orders ORDER BY orderid) AS DWHERE orderdate> ='20170708'ORDER BY orderid;
Biểu thức bảng lọc ba đơn đặt hàng có ID đơn đặt hàng thấp nhất. Sau đó, truy vấn bên ngoài chỉ lọc những đơn đặt hàng được đặt vào hoặc sau ngày 8 tháng 7 năm 2017. Hóa ra chỉ có một đơn đặt hàng đủ điều kiện. Truy vấn này tạo ra kết quả sau:
orderid orderdate ngày ------------ 10250 2017-07-08 (1 hàng bị ảnh hưởng)
Giả sử rằng SQL Server đã hủy thiết lập biểu thức bảng trong truy vấn ban đầu, với quá trình thay thế dẫn đến truy vấn tương đương sau:
SELECT TOP (3) orderid, orderdateFROM Sales.OrdersWHERE orderdate> ='20170708'ORDER BY orderid;
Ý nghĩa của truy vấn này khác với truy vấn ban đầu. Trước tiên, truy vấn này lọc các đơn hàng được đặt vào hoặc sau ngày 8 tháng 7 năm 2017, sau đó lọc ba đơn hàng hàng đầu trong số những đơn hàng có ID đơn hàng thấp nhất. Truy vấn này tạo ra kết quả sau:
orderid orderdate ----------- 10250 2017-07-0810251 2017-07-0810252 2017-07-09 (3 hàng bị ảnh hưởng)
Để tránh thay đổi ý nghĩa của truy vấn ban đầu, SQL Server không áp dụng tính năng hủy ghi chú / thay thế tại đây.
Hai ví dụ cuối cùng liên quan đến sự kết hợp đơn giản của lọc WHERE và TOP, nhưng có thể có các yếu tố xung đột bổ sung do không lưu ý. Ví dụ:điều gì sẽ xảy ra nếu bạn có các đặc tả thứ tự khác nhau trong biểu thức bảng và truy vấn bên ngoài, như trong ví dụ sau:
CHỌN orderid, orderdateFROM (CHỌN ĐẦU (3) * TỪ Sales.Orders ORDER BY orderdate DESC, orderid DESC) AS DORDER BY orderid;
Bạn nhận ra rằng nếu SQL Server hủy thiết lập biểu thức bảng, thu gọn hai đặc tả thứ tự khác nhau thành một, thì truy vấn kết quả sẽ có ý nghĩa khác với truy vấn ban đầu. Nó có thể đã lọc các hàng sai hoặc trình bày các hàng kết quả theo thứ tự trình bày sai. Tóm lại, bạn nhận ra tại sao điều an toàn đối với SQL Server cần làm là tránh bỏ ghi chú / thay thế các biểu thức bảng dựa trên các truy vấn TOP và OFFSET-FETCH.
Tôi đã đề cập trước đó rằng có một ngoại lệ đối với quy tắc rằng việc sử dụng TOP và OFFSET-FETCH ngăn chặn việc bỏ ghi chú. Đó là khi bạn sử dụng TOP (100) PERCENT trong một biểu thức bảng lồng nhau, có hoặc không có mệnh đề ORDER BY. SQL Server nhận ra rằng không có bộ lọc thực sự nào đang diễn ra và tối ưu hóa tùy chọn này. Dưới đây là một ví dụ chứng minh điều này:
SELECT orderid, orderdateFROM (SELECT TOP (100) PERCENT * FROM (SELECT TOP (100) PERCENT * FROM (SELECT TOP (100) PERCENT * FROM Sales.Orders WHERE orderdate> ='20180101') AS D1 WHERE orderdate> ='20180201') AS D2 WHERE orderdate> ='20180301') AS D3WHERE orderdate> ='20180401';
Bộ lọc TOP bị bỏ qua, quá trình hủy ghi chú diễn ra và bạn sẽ nhận được kế hoạch giống như kế hoạch được hiển thị trước đó cho Truy vấn 1 trong Hình 1.
Khi sử dụng OFFSET 0 ROWS không có mệnh đề FETCH trong biểu thức bảng lồng nhau, thì cũng không có quá trình lọc thực sự nào diễn ra. Vì vậy, về mặt lý thuyết, SQL Server cũng có thể đã tối ưu hóa tùy chọn này và cho phép tính năng unnesting, nhưng vào ngày viết bài này thì không. Dưới đây là một ví dụ chứng minh điều này:
SELECT orderid, orderdateFROM (SELECT * FROM (SELECT * FROM (SELECT * FROM Sales.Orders WHERE orderdate> ='20180101' ORDER BY (SELECT NULL) OFFSET 0 ROWS) AS D1 WHERE orderdate> ='20180201' ORDER BY (CHỌN NULL) OFFSET 0 ROWS) AS D2 WHERE orderdate> ='20180301' ORDER BY (SELECT NULL) OFFSET 0 ROWS) AS D3WHERE orderdate> ='20180401';
Bạn nhận được cùng một kế hoạch như kế hoạch được hiển thị trước đó cho Truy vấn 2 trong Hình 2, cho thấy rằng không có quá trình hủy đăng ký nào diễn ra.
Trước đó, tôi đã giải thích rằng quy trình hủy đăng ký / thay thế không thực sự tạo ra một chuỗi truy vấn mới sau đó được tối ưu hóa, thay vào đó phải thực hiện với các phép biến đổi mà SQL Server áp dụng cho cây toán tử logic. Có sự khác biệt giữa cách SQL Server tối ưu hóa truy vấn với các biểu thức bảng lồng nhau so với truy vấn tương đương về mặt logic thực tế mà không cần lồng. Việc sử dụng các biểu thức bảng như bảng dẫn xuất, cũng như các truy vấn con ngăn cản việc tham số hóa đơn giản. Truy vấn nhớ lại 1 được hiển thị trước đó trong bài viết:
SELECT orderid, orderdateFROM (SELECT * FROM (SELECT * FROM (SELECT * FROM Sales.Orders WHERE orderdate> ='20180101') AS D1 WHERE orderdate> ='20180201') AS D2 WHERE orderdate> ='20180301') AS D3WHERE orderdate> ='20180401';
Vì truy vấn sử dụng các bảng dẫn xuất nên việc tham số hóa đơn giản không diễn ra. Nghĩa là, SQL Server không thay thế các hằng số bằng các tham số và sau đó tối ưu hóa truy vấn, mà là tối ưu hóa truy vấn bằng các hằng số. Với các vị từ dựa trên hằng số, SQL Server có thể hợp nhất các khoảng thời gian giao nhau, trong trường hợp của chúng tôi, điều này dẫn đến một vị từ duy nhất trong kế hoạch, như được hiển thị trước đó trong Hình 1.
Tiếp theo, hãy xem xét truy vấn sau (chúng tôi sẽ gọi nó là Truy vấn 3), tương đương logic với Truy vấn 1, nhưng khi bạn tự áp dụng cách bỏ ghi chú:
SELECT orderid, orderdateFROM Sales.OrdersWHERE orderdate> ='20180101' AND orderdate> ='20180201' AND orderdate> ='20180301' AND orderdate> ='20180401';
Kế hoạch cho truy vấn này được thể hiện trong Hình 3.
 Hình 3:Kế hoạch cho Truy vấn 3
Hình 3:Kế hoạch cho Truy vấn 3
Phương án này được coi là an toàn cho việc tham số hóa đơn giản, vì vậy các hằng số được thay thế bằng các tham số và do đó, các biến vị ngữ không được hợp nhất. Động lực cho tham số hóa tất nhiên là tăng khả năng tái sử dụng kế hoạch khi thực hiện các truy vấn tương tự chỉ khác nhau về các hằng số mà chúng sử dụng.
Như đã đề cập, việc sử dụng các bảng dẫn xuất trong Truy vấn 1 đã ngăn cản việc tham số hóa đơn giản. Tương tự, việc sử dụng các truy vấn con sẽ ngăn cản việc tham số hóa đơn giản. Ví dụ:đây là Truy vấn 3 trước đây của chúng tôi với một vị từ vô nghĩa dựa trên một truy vấn con được thêm vào mệnh đề WHERE:
SELECT orderid, orderdateFROM Sales.OrdersWHERE orderdate> ='20180101' AND orderdate> ='20180201' AND orderdate> ='20180301' AND orderdate> ='20180401' AND (SELECT 42) =42;
Lần này, quá trình tham số hóa đơn giản không diễn ra, cho phép SQL Server hợp nhất các khoảng thời gian giao nhau được đại diện bởi các vị từ với các hằng số, dẫn đến cùng một kế hoạch như được hiển thị trước đó trong Hình 1.
Nếu bạn có các truy vấn với biểu thức bảng sử dụng hằng số và điều quan trọng đối với bạn là SQL Server đã tham số hóa mã và vì lý do nào đó mà bạn không thể tự tham số hóa nó, hãy nhớ rằng bạn có tùy chọn sử dụng tham số bắt buộc với hướng dẫn gói. Ví dụ, đoạn mã sau tạo một hướng dẫn kế hoạch như vậy cho Truy vấn 3:
DECLARE @stmt AS NVARCHAR (MAX), @params AS NVARCHAR (MAX); EXEC sys.sp_get_query_template @querytext =N'SELECT orderid, orderdateFROM (SELECT * FROM (SELECT * FROM (SELECT * FROM Sales.Orders WHERE orderdate> ='' 20180101 '') AS D1 WHERE orderdate> ='' 20180201 '') AS D2 WHERE orderdate> ='' 20180301 '') AS D3WHERE orderdate> ='' 20180401 ''; ', @templatetext =@stmt OUTPUT, @parameters =@params OUTPUT; EXEC sys.sp_create_plan_guide @name =N'TG1 ', @stmt =@stmt, @type =N'TEMPLATE', @module_or_batch =NULL, @params =@params, @hints =N'OPTION (PARAMETERIZATION FORCED) ';
Chạy lại Truy vấn 3 sau khi tạo hướng dẫn kế hoạch:
SELECT orderid, orderdateFROM (SELECT * FROM (SELECT * FROM (SELECT * FROM Sales.Orders WHERE orderdate> ='20180101') AS D1 WHERE orderdate> ='20180201') AS D2 WHERE orderdate> ='20180301') AS D3WHERE orderdate> ='20180401';
Bạn nhận được cùng một kế hoạch như kế hoạch được hiển thị trước đó trong Hình 3 với các vị từ được tham số hóa.
Khi bạn hoàn tất, hãy chạy mã sau để xem hướng dẫn kế hoạch:
EXEC sys.sp_control_plan_guide @operation =N'DROP ', @name =N'TG1';
Ngăn chặn việc bỏ ghi chú
Hãy nhớ rằng SQL Server bỏ yêu cầu biểu thức bảng vì lý do tối ưu hóa. Mục đích là để tăng khả năng tìm được một kế hoạch với chi phí thấp hơn so với việc không có unnesting. Điều đó đúng với hầu hết các quy tắc chuyển đổi được trình tối ưu hóa áp dụng. Tuy nhiên, có thể có một số trường hợp bất thường mà bạn muốn ngăn chặn việc bỏ ghi chú. Điều này có thể là để tránh lỗi (có trong một số trường hợp bất thường, việc bỏ ghi chú có thể dẫn đến lỗi) hoặc vì lý do hiệu suất để buộc một hình dạng kế hoạch nhất định, tương tự như sử dụng các gợi ý hiệu suất khác. Hãy nhớ rằng bạn có một cách đơn giản để ngăn chặn việc bỏ quên bằng cách sử dụng TOP với một số lượng rất lớn.
Ví dụ để tránh lỗi
Tôi sẽ bắt đầu với một trường hợp mà việc bỏ ghi chú các biểu thức bảng có thể dẫn đến lỗi.
Hãy xem xét truy vấn sau (chúng tôi sẽ gọi nó là Truy vấn 4):
CHỌN orderid, sản phẩm, chiết khấuVí dụ này hơi ngụy tạo theo nghĩa là có thể dễ dàng viết lại vị từ bộ lọc thứ hai để nó không bao giờ dẫn đến lỗi (chiết khấu <0,1), nhưng đó là một ví dụ thuận tiện để tôi minh họa quan điểm của mình. Giảm giá là không âm. Vì vậy, ngay cả khi có các dòng đặt hàng có chiết khấu bằng 0, truy vấn vẫn phải lọc ra các dòng đó (vị từ bộ lọc đầu tiên nói rằng chiết khấu phải lớn hơn chiết khấu tối thiểu trong bảng). Tuy nhiên, không có gì đảm bảo rằng SQL Server sẽ đánh giá các vị từ theo thứ tự đã viết, vì vậy bạn không thể tin tưởng vào một đoạn ngắn mạch.
Kiểm tra kế hoạch cho Truy vấn 4 được hiển thị trong Hình 4.
Hình 4:Kế hoạch cho Truy vấn 4
Quan sát rằng trong kế hoạch, vị từ 1.0 / chiết khấu> 10.0 (thứ hai trong mệnh đề WHERE) được đánh giá trước vị ngữ chiết khấu>
(đầu tiên trong mệnh đề WHERE). Do đó, truy vấn này tạo ra lỗi chia cho 0: Msg 8134, Cấp 16, Trạng thái 1 Đã gặp lỗi chia nhỏ bằng không.Có lẽ bạn đang nghĩ rằng mình có thể tránh được lỗi bằng cách sử dụng bảng dẫn xuất, tách các nhiệm vụ lọc thành một nhiệm vụ bên trong và một nhiệm vụ bên ngoài, như vậy:
SELECT orderid, yitid, discountFROM (SELECT * FROM Sales.OrderDetails WHERE giảm giá> (CHỌN MIN (giảm giá) FROM Sales.OrderDetails)) AS DWHERE 1.0 / chiết khấu> 10.0;Tuy nhiên, SQL Server áp dụng việc hủy ghi chú bảng dẫn xuất, dẫn đến cùng một kế hoạch được hiển thị trước đó trong Hình 4 và do đó, mã này cũng không thành công với lỗi chia cho 0:
Msg 8134, Cấp 16, Trạng thái 1 Đã gặp lỗi chia nhỏ bằng không.Một cách khắc phục đơn giản ở đây là giới thiệu một chất ức chế unnesting, giống như vậy (chúng tôi sẽ gọi giải pháp này là Truy vấn 5):
CHỌN orderid ,osystemtid, chiết khấuKế hoạch cho Truy vấn 5 được thể hiện trong Hình 5.
Hình 5:Kế hoạch cho Truy vấn 5
Đừng bối rối bởi thực tế là biểu thức 1.0 / chiết khấu xuất hiện trong phần bên trong của toán tử Vòng lặp lồng nhau, như thể được đánh giá đầu tiên. Đây chỉ là định nghĩa của thành viên Expr1006. Đánh giá thực tế của vị từ Expr1006> 10.0 được áp dụng bởi toán tử Bộ lọc như là bước cuối cùng trong kế hoạch sau khi các hàng có chiết khấu tối thiểu đã được lọc ra bởi toán tử Vòng lặp lồng nhau trước đó. Giải pháp này chạy thành công mà không có lỗi.
Ví dụ về lý do hiệu suất
Tôi sẽ tiếp tục với một trường hợp mà việc bỏ ghi chú các biểu thức bảng có thể ảnh hưởng đến hiệu suất.
Bắt đầu bằng cách chạy đoạn mã sau để chuyển ngữ cảnh sang cơ sở dữ liệu PerformanceV5 và bật STATISTICS IO và TIME:
SỬ DỤNG PerformanceV5; ĐẶT THỐNG KÊ IO, BẬT THỜI GIAN;Hãy xem xét truy vấn sau (chúng tôi sẽ gọi nó là Truy vấn 6):
CHỌN shipperid, MAX (ngày đặt hàng) AS maxodFROM dbo.OrdersGROUP BY shipperid;Trình tối ưu hóa xác định chỉ mục bao phủ hỗ trợ với shipperid và orderdate là các khóa hàng đầu. Vì vậy, nó tạo ra một kế hoạch với việc quét chỉ mục theo thứ tự, theo sau là toán tử Tổng hợp Luồng dựa trên thứ tự, như thể hiện trong kế hoạch cho Truy vấn 6 trong Hình 6.
Hình 6:Kế hoạch cho Truy vấn 6
Bảng Đơn hàng có 1.000.000 hàng và shipperid cột nhóm rất dày đặc — chỉ có 5 ID người gửi hàng riêng biệt, dẫn đến mật độ 20% (phần trăm trung bình trên mỗi giá trị riêng biệt). Áp dụng quét toàn bộ lá chỉ mục bao gồm việc đọc vài nghìn trang, dẫn đến thời gian chạy khoảng một phần ba giây trên hệ thống của tôi. Dưới đây là thống kê hiệu suất mà tôi nhận được để thực hiện truy vấn này:
CPU time =344 mili giây, thời gian trôi qua =346 mili giây, số lần đọc logic =3854Cây chỉ mục hiện ở sâu ba cấp.
Hãy mở rộng số lượng đơn đặt hàng theo hệ số từ 1.000 đến 1.000.000.000, nhưng vẫn chỉ có 5 người gửi hàng riêng biệt. Số lượng trang trong lá chỉ mục sẽ tăng lên theo hệ số 1.000 và cây chỉ mục có thể dẫn đến thêm một cấp (sâu bốn cấp). Kế hoạch này có quy mô tuyến tính. Bạn sẽ có gần 4.000.000 lượt đọc logic và thời gian chạy là vài phút.
Khi bạn cần tính toán tổng hợp MIN hoặc MAX dựa trên một bảng lớn, với mật độ rất cao trong cột nhóm (quan trọng!) Và chỉ mục cây B hỗ trợ được khóa trên cột nhóm và cột tổng hợp, có một cách tối ưu hơn nhiều hình dạng kế hoạch hơn hình dạng trong Hình 6. Hãy tưởng tượng một hình dạng kế hoạch quét một tập hợp nhỏ ID người gửi hàng từ một số chỉ mục trên bảng Người gửi hàng và trong một vòng lặp áp dụng cho mỗi người gửi hàng tìm kiếm so với chỉ mục hỗ trợ trên Đơn đặt hàng để lấy tổng hợp. Với 1.000.000 hàng trong bảng, 5 lần tìm kiếm sẽ liên quan đến 15 lần đọc. Với 1.000.000.000 hàng, 5 lượt tìm kiếm sẽ liên quan đến 20 lượt đọc. Với một nghìn tỷ hàng, tổng cộng 25 lần đọc. Rõ ràng là một phương án tối ưu hơn rất nhiều. Bạn thực sự có thể đạt được kế hoạch như vậy bằng cách truy vấn bảng Người gửi hàng và lấy tổng hợp bằng cách sử dụng truy vấn con tổng hợp vô hướng đối với Đơn hàng, như vậy (chúng tôi sẽ gọi giải pháp này là Truy vấn 7):
CHỌN S.shipperid, (CHỌN TỐI ĐA (O.orderdate) TỪ dbo. Đơn đặt hàng AS O WHERE O.shipperid =S.shipperid) AS maxodFROM dbo.Shippers AS S;Kế hoạch cho truy vấn này được thể hiện trong Hình 7.
Hình 7:Kế hoạch cho Truy vấn 7
Hình dạng kế hoạch mong muốn đạt được và số hiệu suất để thực hiện truy vấn này là không đáng kể như mong đợi:
CPU time =0 mili giây, thời gian trôi qua =0 mili giây, số lần đọc logic =15Miễn là cột nhóm quá dày đặc, kích thước của bảng Đơn hàng hầu như không đáng kể.
Nhưng hãy đợi một chút trước khi bạn ăn mừng. Có một yêu cầu là chỉ giữ lại những người gửi hàng có ngày đặt hàng liên quan tối đa trong bảng Đơn đặt hàng là vào hoặc sau năm 2018. Nghe có vẻ như là một sự bổ sung đủ đơn giản. Xác định bảng dẫn xuất dựa trên Truy vấn 7 và áp dụng bộ lọc trong truy vấn bên ngoài, giống như vậy (chúng tôi sẽ gọi giải pháp này là Truy vấn 8):
CHỌN shipperid, maxodFROM (CHỌN S.shipperid, (CHỌN TỐI ĐA (O.orderdate) TỪ dbo. Đơn hàng AS O WHERE O.shipperid =S.shipperid) AS maxod FROM dbo.Shippers AS S) AS DWHERE maxod> ='20180101';Than ôi, SQL Server giải phóng truy vấn bảng dẫn xuất, cũng như truy vấn con, chuyển đổi logic tổng hợp thành tương đương với logic truy vấn được nhóm, với shipperid làm cột nhóm. Và cách SQL Server biết để tối ưu hóa một truy vấn được nhóm là dựa trên một lần chuyển dữ liệu đầu vào, dẫn đến một kế hoạch rất giống với kế hoạch được hiển thị trước đó trong Hình 6, chỉ với bộ lọc bổ sung. Kế hoạch cho Truy vấn 8 được thể hiện trong Hình 8.
Hình 8:Kế hoạch cho Truy vấn 8
Do đó, tỷ lệ là tuyến tính và số hiệu suất tương tự như số hiệu suất cho Truy vấn 6:
Thời gian CPU =328 mili giây, thời gian trôi qua =325 mili giây, số lần đọc logic =3854Cách khắc phục là đưa vào một chất ức chế unnesting. Điều này có thể được thực hiện bằng cách thêm bộ lọc TOP vào biểu thức bảng mà bảng dẫn xuất dựa trên, như vậy (chúng tôi sẽ gọi giải pháp này là Truy vấn 9):
CHỌN shipperid, maxodFROM (CHỌN ĐẦU (9223372036854775807) S.shipperid, (CHỌN TỐI ĐA (O.orderdate) TỪ dbo. Đơn hàng AS O WHERE O.shipperid =S.shipperid) NHƯ maxod TỪ dbo.Shippers AS S) AS DWHERE maxod> ='20180101';Kế hoạch cho truy vấn này được hiển thị trong Hình 9 và có hình dạng kế hoạch mong muốn với các tìm kiếm:
Hình 9:Kế hoạch cho Truy vấn 9
Tất nhiên, số hiệu suất cho việc thực thi này là không đáng kể:
CPU time =0 mili giây, thời gian trôi qua =0 mili giây, số lần đọc logic =15Tuy nhiên, một tùy chọn khác là ngăn chặn việc bỏ ghi truy vấn con, bằng cách thay thế tổng hợp MAX bằng một bộ lọc TOP (1) tương đương, như vậy (chúng tôi sẽ gọi giải pháp này là Truy vấn 10):
SELECT shipperid, maxodFROM (SELECT S.shipperid, (SELECT TOP (1) O.orderdate FROM dbo. Oorder AS O WHERE O.shipperid =S.shipperid ORDER BY O.orderdate DESC) AS maxod FROM dbo.Shippers AS S) AS DWHERE maxod> ='20180101';Kế hoạch cho truy vấn này được hiển thị trong Hình 10 và một lần nữa, có hình dạng mong muốn với các tìm kiếm.
Hình 10:Kế hoạch cho Truy vấn 10
Tôi đã nhận được các con số hiệu suất không đáng kể quen thuộc cho việc thực thi này:
CPU time =0 mili giây, thời gian trôi qua =0 mili giây, số lần đọc logic =15Khi bạn hoàn tất, hãy chạy mã sau để ngừng báo cáo thống kê hiệu suất:
ĐẶT THỐNG KÊ IO, THỜI GIAN TẮT;Tóm tắt
Trong bài viết này, tôi tiếp tục cuộc thảo luận mà tôi đã bắt đầu vào tháng trước về việc tối ưu hóa các bảng dẫn xuất. Tháng này, tôi tập trung vào việc bỏ ghi chú các bảng dẫn xuất. Tôi đã giải thích rằng việc bỏ ghi chú thường dẫn đến một kế hoạch tối ưu hơn so với không ghi chú thích, nhưng cũng bao gồm các ví dụ không mong muốn. Tôi đã đưa ra một ví dụ trong đó việc hủy lưu trữ dẫn đến lỗi cũng như một ví dụ dẫn đến giảm hiệu suất. Tôi đã trình bày cách ngăn chặn tình trạng bỏ nhớ bằng cách áp dụng chất ức chế không tăng như TOP.
Tháng tới, tôi sẽ tiếp tục khám phá các biểu thức bảng đã đặt tên, chuyển trọng tâm sang CTE.



