Giới thiệu
Lưu trữ dữ liệu là một chuyện; lưu trữ có ý nghĩa, hữu ích, đúng dữ liệu hoàn toàn khác. Mặc dù bản thân ý nghĩa và công dụng là những phẩm chất chủ quan, nhưng tính đúng đắn ít nhất có thể được xác định và thực thi một cách hợp lý. Các loại đã đảm bảo rằng số là số và ngày là ngày, nhưng không thể đảm bảo rằng trọng số hoặc khoảng cách là số dương hoặc ngăn phạm vi ngày chồng chéo. Các ràng buộc tuple, bảng và cơ sở dữ liệu áp dụng quy tắc cho dữ liệu đang được lưu trữ và từ chối các giá trị hoặc kết hợp các giá trị không vượt qua tập hợp.
Các ràng buộc không làm cho các kỹ thuật xác nhận đầu vào khác trở nên vô dụng bằng bất kỳ phương tiện nào, ngay cả khi chúng kiểm tra các xác nhận tương tự. Thời gian dành cho việc cố gắng và không lưu trữ dữ liệu không hợp lệ là thời gian lãng phí. Tin nhắn vi phạm, như assert trong hệ thống và ngôn ngữ lập trình ứng dụng, chỉ tiết lộ vấn đề đầu tiên với hồ sơ ứng viên đầu tiên chi tiết hơn nhiều so với bất kỳ ai không liên quan ngay đến nhu cầu cơ sở dữ liệu. Nhưng liên quan đến tính đúng đắn của dữ liệu, các ràng buộc là luật, dù tốt hay xấu; bất cứ điều gì khác là lời khuyên.
Trên Tuples:Not Null, Default và Check
Ràng buộc không rỗng là danh mục đơn giản nhất. Một bộ giá trị phải có một giá trị cho thuộc tính bị ràng buộc, hay nói cách khác, bộ giá trị được phép cho cột không còn bao gồm bộ trống. Không có giá trị nghĩa là không có bộ giá trị nào:việc chèn hoặc cập nhật bị từ chối.
Bảo vệ chống lại giá trị null dễ dàng như khai báo column_name COLUMN_TYPE NOT NULL trong CREATE TABLE hoặc ADD COLUMN . Giá trị rỗng gây ra toàn bộ các loại vấn đề giữa cơ sở dữ liệu và người dùng cuối, vì vậy việc xác định các ràng buộc không null theo phản xạ trên bất kỳ cột nào mà không có lý do chính đáng để cho phép null là một thói quen tốt.
Việc cung cấp giá trị mặc định nếu không có gì được chỉ định (do bỏ sót hoặc NULL rõ ràng ) trong phần chèn hoặc bản cập nhật không phải lúc nào cũng được coi là một ràng buộc, vì các bản ghi ứng viên được sửa đổi và lưu trữ thay vì bị từ chối. Trong nhiều DBMS, các giá trị mặc định có thể được tạo bởi một hàm, mặc dù MySQL không cho phép các hàm do người dùng xác định cho mục đích này.
Bất kỳ quy tắc xác thực nào khác chỉ phụ thuộc vào các giá trị trong một bộ giá trị duy nhất đều có thể được triển khai dưới dạng CHECK hạn chế. Theo một nghĩa nào đó, NOT NULL chính nó là cách viết tắt của CHECK (column_name IS NOT NULL); thông báo lỗi nhận được do vi phạm tạo ra hầu hết sự khác biệt. CHECK tuy nhiên, có thể áp dụng và thực thi chân lý của bất kỳ vị từ Boolean nào trên một bộ giá trị duy nhất. Ví dụ:một bảng lưu trữ các vị trí địa lý phải CHECK (latitude >= -90 AND latitude < 90) và tương tự đối với kinh độ từ -180 đến 180 - hoặc, nếu có, hãy sử dụng và xác thực GEOGRAPHY kiểu dữ liệu.
Trên bảng:Duy nhất và Loại trừ
Các ràng buộc mức bảng kiểm tra các bộ giá trị với nhau. Trong một ràng buộc duy nhất, chỉ một bản ghi có thể có bất kỳ bộ giá trị đã cho nào cho các cột bị ràng buộc. Tính vô hiệu có thể gây ra sự cố ở đây, vì NULL không bao giờ bằng bất kỳ thứ gì khác, tối đa và bao gồm NULL chinh no. Một ràng buộc duy nhất trên (batman, robin) do đó cho phép tạo ra các bản sao vô hạn của bất kỳ Người dơi không có Robin nào.
Các ràng buộc loại trừ chỉ được hỗ trợ trong PostgreSQL và DB2, nhưng lấp đầy một ngách rất hữu ích:chúng có thể ngăn chặn sự chồng chéo. Chỉ định các trường bị ràng buộc và các hoạt động mà mỗi trường sẽ được đánh giá và bản ghi mới sẽ chỉ được chấp nhận nếu không có bản ghi hiện có nào so sánh thành công với từng trường và thao tác. Ví dụ:một schedules bảng có thể được định cấu hình để từ chối xung đột:
-- text, int, etc. comparisons in exclusion constraints require this-- Postgres extensionCREATE EXTENSION btree_gist;CREATE TABLE schedules ( schedule_id SERIAL NOT NULL PRIMARY KEY, room_number TEXT NOT NULL, -- a range of TIMESTAMP WITH TIME ZONE provides both start and end duration TSTZRANGE, -- table-level constraints imply an index, since otherwise they'd -- have to search the entire table to validate a candidate record; -- GiST (generalized search tree) indexes are usually used in -- Postgres EXCLUDE USING GIST ( room_number WITH =, duration WITH && ));INSERT INTO schedules (room_number, duration)VALUES ('32A', '[2020-08-20T10:00:00Z,2020-08-20T11:00:00Z)');-- the same time in a different room: acceptedINSERT INTO schedules (room_number, duration)VALUES ('32B', '[2020-08-20T10:00:00Z,2020-08-20T11:00:00Z)');-- a half-hour overlap for an already-scheduled room: rejectedINSERT INTO schedules (room_number, duration)VALUES ('32A', '[2020-08-20T10:30:00Z,2020-08-20T11:30:00Z)');
Nâng cấp các hoạt động như ON CONFLICT của PostgreSQL mệnh đề hoặc ON DUPLICATE KEY UPDATE của MySQL sử dụng ràng buộc mức bảng để phát hiện xung đột. Và giống như các ràng buộc không null có thể được biểu thị dưới dạng CHECK ràng buộc, một ràng buộc duy nhất có thể được biểu thị như một ràng buộc loại trừ đối với bình đẳng.
Khóa chính
Các ràng buộc duy nhất có một trường hợp đặc biệt hữu ích. Với một ràng buộc bổ sung không rỗng trên cột hoặc các cột duy nhất, mỗi bản ghi trong bảng có thể được xác định riêng bởi các giá trị của nó cho các cột bị ràng buộc, được gọi chung là khóa . Nhiều khóa ứng viên có thể cùng tồn tại trong một bảng, chẳng hạn như users đôi khi vẫn có email email s và username S; nhưng việc khai báo một khóa chính thiết lập một tiêu chí duy nhất mà các bản ghi được biết đến một cách công khai và độc quyền. Một số RDBMS thậm chí còn tổ chức các hàng trên các trang bằng khóa chính, được gọi cho mục đích này là chỉ mục được phân cụm , để giúp tìm kiếm theo giá trị khóa chính nhanh nhất có thể.
Có hai loại khóa chính. Khóa tự nhiên được xác định trên một cột hoặc các cột "tự nhiên" được đưa vào dữ liệu của bảng, trong khi khóa thay thế hoặc khóa tổng hợp chỉ được phát minh với mục đích trở thành khóa. Các khóa tự nhiên đòi hỏi sự cẩn thận - nhiều thứ có thể thay đổi hơn những gì mà các nhà thiết kế cơ sở dữ liệu thường ghi nhận, từ tên đến lược đồ đánh số. Bảng tra cứu chứa tên quốc gia và khu vực có thể sử dụng mã ISO 3166 tương ứng của chúng làm khóa chính tự nhiên an toàn, nhưng users bảng có khóa tự nhiên dựa trên các giá trị có thể thay đổi như tên hoặc địa chỉ email sẽ dẫn đến rắc rối. Khi nghi ngờ, hãy tạo một khóa thay thế.
Nếu một khóa tự nhiên kéo dài nhiều cột, thì ít nhất một khóa thay thế phải luôn được xem xét vì các khóa nhiều cột tốn nhiều công sức hơn để quản lý. Tuy nhiên, nếu khóa tự nhiên phù hợp, các cột phải được sắp xếp theo thứ tự tăng dần độ cụ thể giống như chúng nằm trong chỉ mục:mã quốc gia then mã vùng, thay vì ngược lại.
Khóa thay thế trước đây là một cột số nguyên duy nhất hoặc BIGINT nơi hàng tỷ cuối cùng sẽ được chỉ định. Cơ sở dữ liệu quan hệ có thể tự động điền các khóa thay thế bằng số nguyên tiếp theo trong một chuỗi, một tính năng thường được gọi là SERIAL hoặc IDENTITY .
Bộ đếm số tự động tăng thêm không phải là không có nhược điểm:việc thêm vào các bản ghi bằng các khóa được tạo trước có thể gây ra xung đột và nếu các giá trị tuần tự được hiển thị cho người dùng, họ dễ dàng đoán được các khóa hợp lệ khác có thể là gì. Số nhận dạng duy nhất phổ biến hoặc UUID, tránh những điểm yếu này và đã trở thành lựa chọn phổ biến cho các khóa thay thế, mặc dù chúng cũng lớn hơn nhiều trong trang so với một số đơn giản. Loại UUID v1 (dựa trên địa chỉ MAC) và v4 (giả ngẫu nhiên) được sử dụng thường xuyên nhất.
Trên Cơ sở dữ liệu:Khóa ngoại
Cơ sở dữ liệu quan hệ chỉ triển khai một lớp ràng buộc đa bảng,
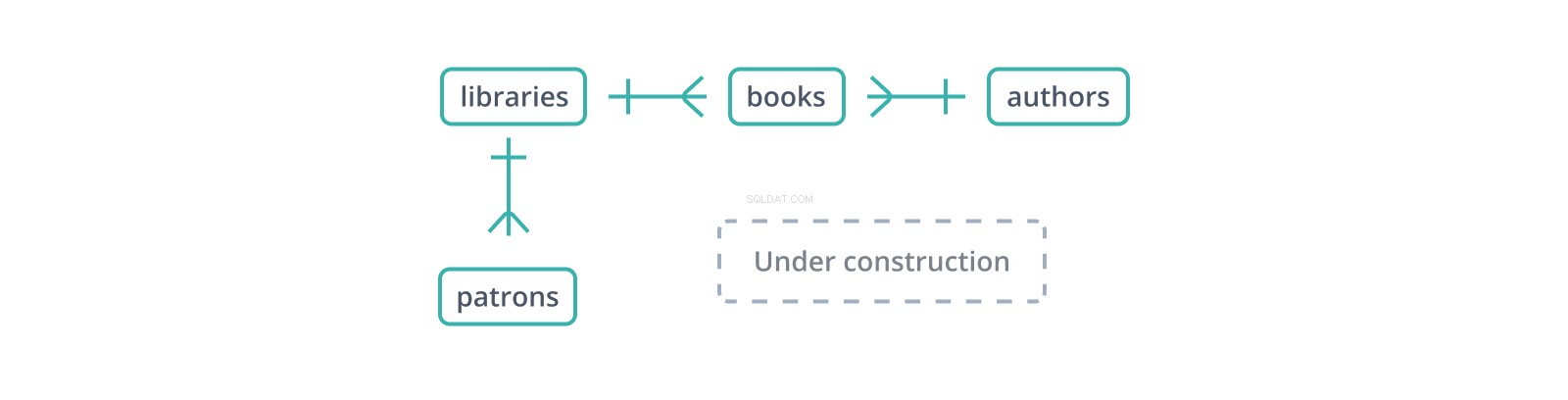
"Sơ đồ mối quan hệ thực thể" hoặc ERD không chính thức này cho thấy phần đầu của một lược đồ cho cơ sở dữ liệu các thư viện và bộ sưu tập cũng như khách hàng của họ. Mỗi cạnh đại diện cho một mối quan hệ giữa các bảng mà nó kết nối. Các | glyph biểu thị một bản ghi duy nhất trên mặt của nó, trong khi glyph "vết chân chim" đại diện cho nhiều bản ghi:một thư viện chứa nhiều sách và có nhiều khách hàng quen.
Khóa ngoại là bản sao của khóa chính của bảng khác, cột cho cột (một điểm có lợi cho khóa thay thế:chỉ một cột để sao chép và tham chiếu), với các giá trị liên kết các bản ghi trong bảng này với các bản ghi "mẹ" trong đó. Trong lược đồ trên, books bảng duy trì một library_id khóa ngoại vào các thư viện libraries , nơi chứa sách và author_id tới authors , người viết chúng. Nhưng điều gì sẽ xảy ra nếu một cuốn sách được chèn bằng author_id không tồn tại trong authors ?
Nếu khóa ngoài không bị ràng buộc - tức là nó chỉ là một cột hoặc các cột khác - một cuốn sách có thể có tác giả không tồn tại. Đây là sự cố:nếu ai đó cố theo liên kết giữa books và authors , chúng không biến đi đâu cả. Nếu authors.author_id là một số nguyên nối tiếp, cũng có khả năng không ai nhận ra cho đến khi author_id giả mạo cuối cùng được chỉ định và bạn kết thúc với một bản sao cụ thể của Don Quixote trước hết là do không ai biết đến và sau đó là Pierre Menard, không tìm thấy Miguel Cervantes.
Việc ràng buộc khóa ngoại không thể ngăn sách bị phân phối sai nếu author_id sai trỏ đến bản ghi hiện có trong authors , vì vậy các kiểm tra và thử nghiệm khác vẫn quan trọng. Tuy nhiên, tập hợp các giá trị khóa ngoại còn tồn tại hầu như luôn là một tập hợp con nhỏ của các giá trị có thể các giá trị khóa ngoại, vì vậy các ràng buộc khóa ngoại sẽ bắt và ngăn chặn hầu hết các giá trị sai. Với ràng buộc khóa ngoại, Quixote với một tác giả không tồn tại sẽ bị từ chối thay vì được ghi lại.
Đây có phải là "Mối quan hệ" trong "Cơ sở dữ liệu quan hệ" đến từ đâu?
Các khóa ngoại tạo ra các mối quan hệ giữa các bảng, nhưng các bảng như chúng ta biết về mặt toán học là quan hệ trong số các bộ giá trị có thể có cho mỗi thuộc tính. Một bộ giá trị liên quan một giá trị cho cột A với một giá trị cho cột B trở đi. Bài báo gốc của E.F. Codd sử dụng "quan hệ" theo nghĩa này.
Điều này không gây ra sự nhầm lẫn và có thể sẽ tiếp tục như vậy vĩnh viễn.
Đối với một số giá trị chính xác
Có nhiều cách khác mà dữ liệu có thể không chính xác hơn được giải quyết ở đây. Ràng buộc giúp đỡ, nhưng thậm chí chúng chỉ rất linh hoạt; nhiều thông số kỹ thuật nội bộ phổ biến, chẳng hạn như giới hạn hai hoặc cao hơn về số lần một giá trị được phép xuất hiện trong một cột, chỉ có thể được thực thi với trình kích hoạt.
Nhưng cũng có những cách mà chính cấu trúc của một bảng có thể dẫn đến sự mâu thuẫn. Để ngăn chặn những điều này, chúng tôi sẽ cần điều chỉnh cả khóa chính và khóa ngoài không chỉ để xác định và xác thực mà còn để chuẩn hóa mối quan hệ giữa các bảng. Tuy nhiên, trước tiên, chúng tôi mới chỉ sơ lược về cách mối quan hệ giữa các bảng xác định cấu trúc của chính cơ sở dữ liệu.