Giới thiệu
Có hai trường phái suy nghĩ về việc thực hiện các phép tính trong cơ sở dữ liệu của bạn:những người nghĩ rằng nó tuyệt vời và những người sai. Điều này không có nghĩa là thế giới của các hàm, các thủ tục được lưu trữ, các cột được tạo hoặc tính toán, và các trình kích hoạt đều là ánh nắng mặt trời và hoa hồng! Những công cụ này không có gì đáng ngạc nhiên và việc triển khai thiếu cân nhắc có thể hoạt động kém, gây tổn thương cho người bảo trì, v.v.
Nhưng theo định nghĩa, cơ sở dữ liệu rất tốt trong việc xử lý và thao tác thông tin, và hầu hết chúng đều cung cấp quyền kiểm soát và sức mạnh tương tự cho người dùng của chúng (SQLite và MS Access ở mức độ thấp hơn). Các chương trình xử lý dữ liệu bên ngoài bắt đầu từ việc phải lấy thông tin ra khỏi cơ sở dữ liệu, thường xuyên qua mạng, trước khi chúng có thể làm bất cứ điều gì. Và nơi các chương trình cơ sở dữ liệu có thể tận dụng tối đa các hoạt động tập hợp nguyên bản, lập chỉ mục, bảng tạm thời và các thành quả khác của nửa thế kỷ phát triển cơ sở dữ liệu, các chương trình bên ngoài có bất kỳ độ phức tạp nào có xu hướng liên quan đến một số cấp độ sáng tạo lại bánh xe. Vậy tại sao không đặt cơ sở dữ liệu hoạt động?
Đây là lý do tại sao bạn có thể không muốn lập trình cơ sở dữ liệu của bạn!
- Chức năng cơ sở dữ liệu có xu hướng trở nên vô hình - đặc biệt kích hoạt. Điểm yếu này có quy mô xấp xỉ với quy mô của các nhóm và / hoặc ứng dụng tương tác với cơ sở dữ liệu, vì ít người nhớ hoặc biết về lập trình trong cơ sở dữ liệu. Tài liệu hữu ích, nhưng chỉ rất nhiều.
- SQL là ngôn ngữ được xây dựng nhằm mục đích sử dụng các tập dữ liệu. Nó không đặc biệt giỏi ở những thứ không thao túng các tập dữ liệu và càng không tốt khi những thứ khác càng phức tạp hơn.
- Khả năng RDBMS và phương ngữ SQL khác nhau. Các cột được tạo đơn giản được hỗ trợ rộng rãi, nhưng việc chuyển logic cơ sở dữ liệu phức tạp hơn sang các cửa hàng khác sẽ tốn ít thời gian và công sức nhất.
- Nâng cấp giản đồ cơ sở dữ liệu thường nặng nề hơn nâng cấp ứng dụng. Tốt nhất nên duy trì logic thay đổi nhanh chóng ở nơi khác, mặc dù nó có thể đáng để xem xét lại một khi mọi thứ ổn định.
- Việc quản lý các chương trình cơ sở dữ liệu không đơn giản như người ta có thể hy vọng. Nhiều công cụ di chuyển giản đồ không làm được gì hoặc không có tác dụng gì đối với tổ chức, dẫn đến sự khác biệt lớn và đánh giá mã phức tạp (đồ thị phụ thuộc của sqitch và việc làm lại các đối tượng riêng lẻ khiến nó trở thành một ngoại lệ đáng chú ý và di chuyển tìm cách loại bỏ hoàn toàn vấn đề). Trong quá trình thử nghiệm, các khuôn khổ như pgTAP và utPLSQL cải thiện các bài kiểm tra tích hợp hộp đen nhưng cũng thể hiện cam kết hỗ trợ và bảo trì bổ sung.
- Với một cơ sở mã bên ngoài đã được thiết lập, bất kỳ thay đổi cấu trúc nào đều có xu hướng tốn nhiều công sức và rủi ro.
Mặt khác, đối với những tác vụ phù hợp, SQL cung cấp tốc độ, sự ngắn gọn, độ bền và cơ hội "chuẩn hóa" các quy trình làm việc tự động. Mô hình hóa dữ liệu không chỉ là ghim các thực thể như côn trùng vào bìa cứng, và sự phân biệt giữa dữ liệu đang chuyển động và dữ liệu ở trạng thái nghỉ là một điều khó khăn. Nghỉ ngơi thực sự là chuyển động chậm hơn ở cấp độ mịn hơn; thông tin luôn chảy từ đây đến đó và khả năng lập trình cơ sở dữ liệu là một công cụ mạnh mẽ để quản lý và chỉ đạo các luồng đó.
Một số công cụ cơ sở dữ liệu phân tách sự khác biệt giữa SQL và các ngôn ngữ lập trình khác bằng cách điều chỉnh các ngôn ngữ lập trình khác. SQL Server hỗ trợ các chức năng được viết bằng bất kỳ ngôn ngữ .NET Framework nào; Oracle có các thủ tục được lưu trữ bằng Java; PostgreSQL cho phép các tiện ích mở rộng bằng C và người dùng có thể lập trình bằng Python, Perl và Tcl, với các plugin bổ sung các tập lệnh shell, R, JavaScript, v.v. Làm tròn các nghi ngờ thông thường, đó là SQL hoặc không có gì cho MySQL và MariaDB, MS Access là chỉ có thể lập trình trong VBA và SQLite hoàn toàn không phải do người dùng lập trình.
Sử dụng ngôn ngữ không phải SQL là một tùy chọn nếu SQL không đủ cho một số tác vụ hoặc nếu bạn muốn sử dụng lại mã khác, nhưng nó sẽ không giúp bạn giải quyết các vấn đề khác khiến lập trình cơ sở dữ liệu trở thành con dao nhiều lưỡi. Nếu có bất cứ điều gì, việc sử dụng những điều này sẽ làm phức tạp thêm việc triển khai và khả năng tương tác. Trình viết kịch bản báo trước:hãy để người viết cẩn thận.
Hàm so với Thủ tục
Cũng như các khía cạnh khác của việc triển khai tiêu chuẩn SQL, các chi tiết chính xác khác nhau một chút từ RDBMS sang RDBMS. Nói chung:
- Các chức năng không thể kiểm soát các giao dịch.
- Các hàm trả về giá trị; các thủ tục có thể sửa đổi các tham số được chỉ định
OUThoặcINOUTsau đó có thể đọc được trong ngữ cảnh gọi nhưng không bao giờ trả về kết quả (ngoại trừ SQL Server). - Các hàm được gọi từ bên trong các câu lệnh SQL để thực hiện một số công việc trên các bản ghi đang được truy xuất hoặc lưu trữ, trong khi các thủ tục đứng độc lập.
Đặc biệt hơn, MySQL cũng không cho phép đệ quy và một số câu lệnh SQL bổ sung trong các hàm. SQL Server cấm các chức năng sửa đổi dữ liệu, thực thi SQL động và xử lý lỗi. PostgreSQL đã không tách các thủ tục được lưu trữ khỏi các hàm cho đến năm 2017 với phiên bản 11, vì vậy các hàm Postgres có thể thực hiện hầu hết mọi thứ có thể làm được của các thủ tục, trừ việc kiểm soát giao dịch.
Vì vậy, mà sử dụng khi nào? Các hàm phù hợp nhất với logic áp dụng ghi từng bản ghi khi dữ liệu được lưu trữ và truy xuất. Các quy trình công việc phức tạp hơn do chính chúng gọi ra và di chuyển dữ liệu xung quanh nội bộ sẽ tốt hơn dưới dạng các thủ tục.
Mặc định và tạo
Ngay cả những phép tính đơn giản cũng có thể gây rắc rối nếu chúng được thực hiện đủ thường xuyên hoặc nếu tồn tại nhiều triển khai cạnh tranh. Các phép toán trên các giá trị trong một hàng - hãy nghĩ đến việc chuyển đổi giữa các đơn vị đo lường và hệ đo lường Anh, nhân tỷ lệ với số giờ làm việc cho tổng phụ của hóa đơn, tính diện tích của một đa giác địa lý - có thể được khai báo trong định nghĩa bảng để giải quyết vấn đề này hoặc vấn đề khác :
CREATE TABLE pythag ( a INT NOT NULL, b INT NOT NULL, c DOUBLE PRECISION NOT NULL GENERATED ALWAYS AS (sqrt(pow(a, 2) + pow(b, 2))) STORED);
Hầu hết các RDBMS cung cấp sự lựa chọn giữa các cột được tạo "được lưu trữ" và "ảo". Trong trường hợp trước đây, giá trị được tính toán và lưu trữ khi hàng được chèn hoặc cập nhật. Đây là tùy chọn duy nhất với PostgreSQL, kể từ phiên bản 12 và MS Access. Các cột được tạo ảo được tính toán khi được truy vấn như trong dạng xem, vì vậy chúng không chiếm dung lượng nhưng sẽ được tính toán lại thường xuyên hơn. Cả hai loại đều bị ràng buộc chặt chẽ:các giá trị không thể phụ thuộc vào thông tin bên ngoài hàng mà chúng thuộc về, chúng không thể được cập nhật và các RDBMS riêng lẻ vẫn có thể có các giới hạn cụ thể hơn. Ví dụ:PostgreSQL cấm phân vùng bảng trên một cột được tạo.
Các cột được tạo là một công cụ chuyên dụng. Thông thường hơn, tất cả những gì cần thiết là mặc định trong trường hợp giá trị không được cung cấp trên chèn. Các hàm như now() hiển thị thường xuyên dưới dạng mặc định cột, nhưng hầu hết các cơ sở dữ liệu đều cho phép các chức năng tùy chỉnh cũng như tích hợp sẵn (ngoại trừ MySQL, trong đó chỉ current_timestamp có thể là một giá trị mặc định).
Hãy lấy ví dụ khá khô khan nhưng đơn giản về một số lô ở định dạng YYYYXXX, trong đó bốn chữ số đầu tiên đại diện cho năm hiện tại và ba chữ số sau là bộ đếm tăng dần:lô đầu tiên được sản xuất trong năm nay là 2020001, số thứ hai 2020002, v.v. . Không có loại mặc định hoặc hàm tích hợp nào tạo ra giá trị như thế này, nhưng một hàm do người dùng xác định có thể đánh số từng lô
CREATE SEQUENCE lot_counter;CREATE OR REPLACE FUNCTION next_lot_number () RETURNS TEXT AS $$BEGIN RETURN date_part('year', now())::TEXT || lpad(nextval('lot_counter'::REGCLASS)::TEXT, 2, '0');END;$$LANGUAGE plpgsql;CREATE TABLE lots ( lot_number TEXT NOT NULL DEFAULT next_lot_number () PRIMARY KEY, current_quantity INT NOT NULL DEFAULT 0, target_quantity INT NOT NULL, created_at TIMESTAMPTZ NOT NULL DEFAULT now(), completed_at TIMESTAMPTZ, CHECK (target_quantity > 0));
Tham chiếu dữ liệu trong hàm
Cách tiếp cận theo trình tự ở trên có một điểm yếu quan trọng (và lot_counter Tuy nhiên, sẽ vẫn có cùng giá trị mà nó đã có vào ngày 31 tháng 12. Có nhiều cách để theo dõi số lượng lô đã được tạo ra trong một năm và bằng cách truy vấn lots chính nó là next_lot_number hàm có thể đảm bảo một giá trị chính xác sau khi năm trôi qua.
CREATE OR REPLACE FUNCTION next_lot_number () RETURNS TEXT AS $$BEGIN RETURN ( SELECT date_part('year', now())::TEXT || lpad((count(*) + 1)::TEXT, 2, '0') FROM lots WHERE date_part('year', created_at) = date_part('year', now()) );END;$$LANGUAGE plpgsql;ALTER TABLE lots ALTER COLUMN lot_number SET DEFAULT next_lot_number();
Quy trình làm việc
Ngay cả một hàm câu lệnh đơn cũng có một lợi thế quan trọng so với mã bên ngoài:việc thực thi không bao giờ làm mất đi sự an toàn của các đảm bảo về ACID của cơ sở dữ liệu. So sánh next_lot_number trên các khả năng của ứng dụng khách hoặc thậm chí là quy trình thủ công, thực thi
Các chương trình được lưu trữ nhiều câu lệnh mở ra một không gian rộng lớn các khả năng, vì SQL bao gồm tất cả các công cụ bạn cần để viết mã thủ tục, từ xử lý ngoại lệ đến các điểm lưu (thậm chí nó còn hoàn chỉnh với các hàm cửa sổ và biểu thức bảng thông thường!). Toàn bộ quy trình xử lý dữ liệu có thể được thực hiện trong cơ sở dữ liệu, giảm thiểu việc tiếp xúc với các khu vực khác của hệ thống và loại bỏ các bước đi vòng tốn thời gian giữa cơ sở dữ liệu và các miền khác.
Phần lớn kiến trúc phần mềm nói chung là về quản lý và cô lập sự phức tạp, ngăn không cho nó tràn qua ranh giới giữa các hệ thống con. Nếu một số quy trình công việc phức tạp hơn hoặc ít phức tạp hơn liên quan đến việc kéo dữ liệu vào phần phụ trợ ứng dụng, tập lệnh hoặc công việc cron, tiêu hóa và thêm vào nó và lưu trữ kết quả - đã đến lúc hỏi điều gì thực sự cần thiết khi mạo hiểm bên ngoài cơ sở dữ liệu.
Như đã đề cập ở trên, đây là một lĩnh vực mà ở đó sự khác biệt giữa hương vị RDBMS và phương ngữ SQL xuất hiện hàng đầu. Một hàm hoặc thủ tục được phát triển cho một cơ sở dữ liệu có thể sẽ không chạy trên một cơ sở dữ liệu khác mà không có thay đổi, cho dù đó là thay thế cho TOP của SQL Server cho một LIMIT tiêu chuẩn mệnh đề hoặc hoàn toàn làm lại cách trạng thái tạm thời được lưu trữ trong một doanh nghiệp chuyển đổi Oracle sang PostgreSQL. Việc chuẩn hóa các quy trình công việc của bạn trong SQL cũng cam kết bạn tiếp cận với nền tảng hiện tại của mình và sử dụng phương ngữ kỹ lưỡng hơn hầu hết bất kỳ lựa chọn nào khác mà bạn có thể thực hiện.
Tính toán trong Truy vấn
Cho đến nay, chúng tôi đã xem xét việc sử dụng các hàm để lưu trữ và sửa đổi dữ liệu, cho dù bị ràng buộc với định nghĩa bảng hay quản lý quy trình làm việc nhiều bảng. Theo một nghĩa nào đó, đó là cách sử dụng mạnh mẽ hơn mà chúng có thể được sử dụng, nhưng các hàm cũng có một vị trí trong việc truy xuất dữ liệu. Nhiều công cụ bạn có thể đã sử dụng trong các truy vấn của mình được triển khai dưới dạng các hàm, từ các công cụ tích hợp tiêu chuẩn như count đến các phần mở rộng như Postgres 'jsonb_build_object , PostGIS 'ST_SnapToGrid , và hơn thế nữa. Tất nhiên, vì chúng được tích hợp chặt chẽ hơn với chính cơ sở dữ liệu, chúng hầu hết được viết bằng các ngôn ngữ khác ngoài SQL (ví dụ:C trong trường hợp của PostgreSQL và PostGIS).
Nếu bạn thường thấy mình (hoặc nghĩ rằng bạn có thể thấy mình) cần truy xuất dữ liệu và sau đó thực hiện một số thao tác trên mỗi bản ghi trước khi thực sự đã sẵn sàng, hãy xem xét việc chuyển đổi chúng trên đường ra khỏi cơ sở dữ liệu thay thế! Dự kiến một số ngày làm việc ngoài một ngày? Tạo sự khác biệt giữa hai JSONB lĩnh vực? Trên thực tế, bất kỳ phép tính nào chỉ phụ thuộc vào thông tin bạn đang truy vấn đều có thể được thực hiện trong SQL. Và những gì được thực hiện trong cơ sở dữ liệu - miễn là nó được truy cập nhất quán - là chuẩn khi có liên quan đến bất kỳ thứ gì được xây dựng trên cơ sở dữ liệu.
Cần phải nói rằng:nếu bạn đang làm việc với phần phụ trợ ứng dụng, bộ công cụ truy cập dữ liệu của nó có thể giới hạn quãng đường bạn nhận được từ việc tăng cường kết quả truy vấn bằng các hàm. Hầu hết các thư viện như vậy có thể thực thi SQL tùy ý, nhưng những thư viện tạo ra các câu lệnh SQL phổ biến dựa trên các lớp mô hình có thể cho phép hoặc không cho phép tùy chỉnh truy vấn SELECT danh sách. Các cột hoặc chế độ xem đã tạo có thể là câu trả lời ở đây.
Kích hoạt và hậu quả
Các hàm và thủ tục đủ gây tranh cãi giữa các nhà thiết kế cơ sở dữ liệu và người dùng, nhưng những điều thực sự cất cánh với các trình kích hoạt. Trình kích hoạt xác định một hành động tự động, thường là một thủ tục (SQLite chỉ cho phép một câu lệnh duy nhất), được thực thi trước, sau hoặc thay vì một hành động khác.
Hành động khởi tạo thường là chèn, cập nhật hoặc xóa vào bảng và thủ tục kích hoạt thường có thể được đặt để thực thi cho từng bản ghi hoặc cho toàn bộ câu lệnh. SQL Server cũng cho phép kích hoạt trên các dạng xem có thể cập nhật, hầu hết là một cách để thực thi các biện pháp bảo mật chi tiết hơn; và nó, PostgreSQL và Oracle đều cung cấp một số dạng sự kiện hoặc
Cách sử dụng có rủi ro thấp phổ biến cho các trình kích hoạt là như một ràng buộc cực kỳ mạnh mẽ ngăn không cho dữ liệu không hợp lệ được lưu trữ. Trong tất cả các cơ sở dữ liệu quan hệ chính, chỉ có khóa chính và khóa ngoại và UNIQUE ràng buộc có thể đánh giá thông tin bên ngoài hồ sơ ứng viên. Không thể khai báo trong định nghĩa bảng rằng, ví dụ:chỉ có hai lô có thể được tạo trong một tháng - và giải pháp mã và cơ sở dữ liệu đơn giản nhất dễ bị ảnh hưởng bởi điều kiện chủng tộc tương tự như phương pháp đếm-sau đó đặt đối với lot_number bên trên. Để thực thi bất kỳ ràng buộc nào khác liên quan đến toàn bộ bảng hoặc các bảng khác, bạn cần có
CREATE FUNCTION enforce_monthly_lot_limit () RETURNS TRIGGERAS $$DECLARE current_count BIGINT;BEGIN SELECT count(*) INTO current_count FROM lots WHERE date_trunc('month', created_at) = date_trunc('month', NEW.created_at); IF current_count >= 2 THEN RAISE EXCEPTION 'Two lots already created this month'; END IF; RETURN NEW;END;$$LANGUAGE plpgsql;CREATE TRIGGER monthly_lot_limitBEFORE INSERT ON lotsFOR EACH ROWEXECUTE PROCEDURE enforce_monthly_lot_limit();
Khi bạn bắt đầu thực thi lots bản thân nó có thể là hoạt động cuối cùng của trình kích hoạt được khởi tạo bởi chèn vào orders , không có người dùng con người hoặc phần phụ trợ ứng dụng được trao quyền để ghi vào lots trực tiếp. Hoặc dưới dạng items được thêm vào rất nhiều, một trình kích hoạt ở đó có thể xử lý việc cập nhật current_quantity và bắt đầu một số quá trình khác khi nó đạt đến target_quantity .
Các trình kích hoạt và chức năng có thể chạy ở cấp độ truy cập của trình định nghĩa của chúng (trong PostgreSQL, một SECURITY DEFINER khai báo bên cạnh LANGUAGE của một hàm ).
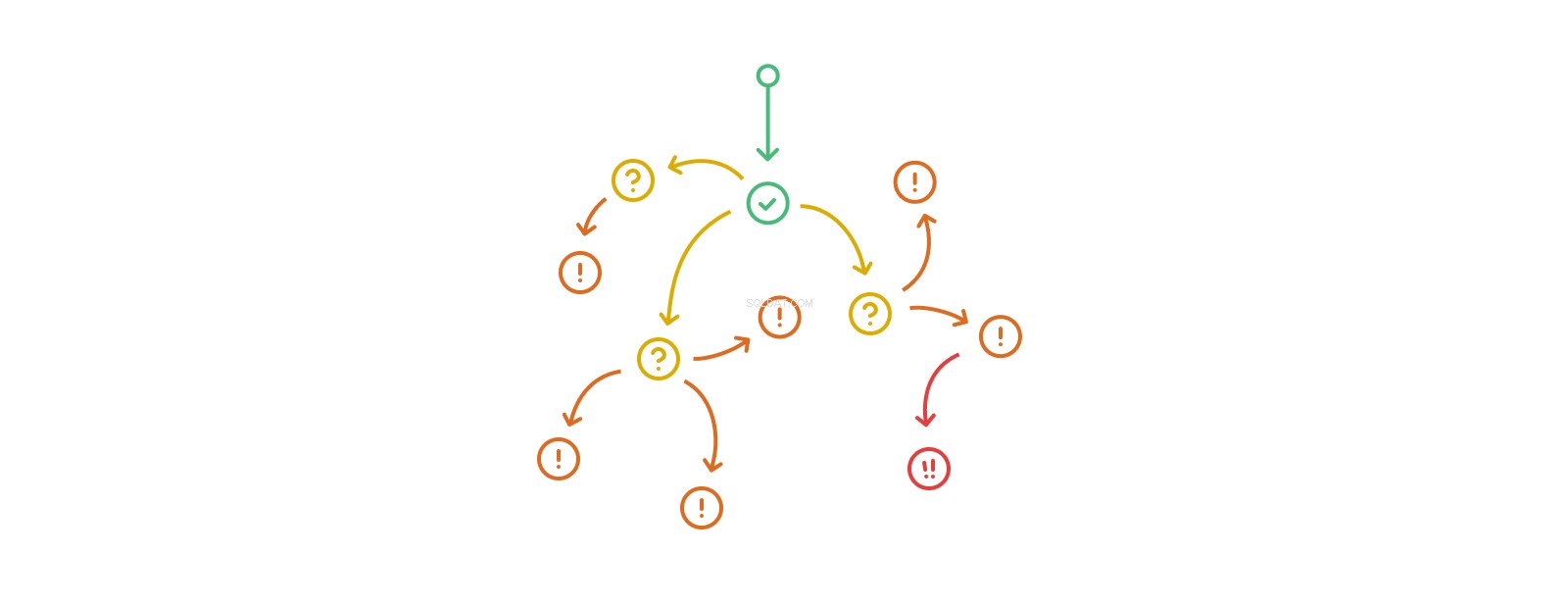
Ngăn xếp lệnh gọi trigger-action-trigger-action có thể trở nên dài tùy ý, mặc dù đệ quy thực sự dưới dạng sửa đổi các bảng hoặc bản ghi giống nhau nhiều lần trong bất kỳ luồng nào như vậy là bất hợp pháp trên một số nền tảng và nói chung là một ý tưởng tồi trong hầu hết mọi trường hợp. Kích hoạt làm tổ nhanh chóng vượt xa khả năng chúng ta hiểu được mức độ và tác động của nó. Cơ sở dữ liệu sử dụng nhiều các trình kích hoạt lồng nhau bắt đầu trôi từ lĩnh vực phức tạp sang lĩnh vực phức tạp, trở nên khó hoặc không thể phân tích, gỡ lỗi và dự đoán.
Khả năng lập trình thực tế
Các phép tính trong cơ sở dữ liệu không chỉ nhanh hơn và được diễn đạt ngắn gọn hơn:chúng loại bỏ sự mơ hồ và thiết lập các tiêu chuẩn. Các ví dụ trên, người dùng cơ sở dữ liệu miễn phí khỏi phải tự tính toán số lô, hoặc khỏi lo lắng về việc vô tình tạo ra nhiều lô hơn mức họ có thể xử lý. Các nhà phát triển ứng dụng nói riêng thường được đào tạo để coi cơ sở dữ liệu là "kho lưu trữ ngu ngốc", chỉ cung cấp cấu trúc và tính bền bỉ, và do đó, họ có thể thấy mình - hoặc tệ hơn, không nhận ra rằng họ đang - trình bày một cách vụng về bên ngoài cơ sở dữ liệu những gì họ có thể làm hiệu quả hơn trong SQL.
Khả năng lập trình là một tính năng bị bỏ qua một cách vô cớ của cơ sở dữ liệu quan hệ. Có những lý do để tránh nó và nhiều lý do khác để hạn chế việc sử dụng nó, nhưng các hàm, thủ tục và trình kích hoạt đều là những công cụ mạnh mẽ để hạn chế sự phức tạp mà mô hình dữ liệu của bạn áp đặt lên các hệ thống mà nó được nhúng.