Tháng 10 năm ngoái, chúng tôi đã thách thức đối tượng PyBites của mình tạo một ứng dụng web để điều hướng tốt hơn nguồn cấp dữ liệu Mẹo Python hàng ngày. Trong bài viết này, tôi sẽ chia sẻ những gì tôi đã xây dựng và học được trong suốt quá trình.
Trong bài viết này, bạn sẽ tìm hiểu:
- Cách sao chép repo dự án và thiết lập ứng dụng.
- Cách sử dụng API Twitter qua mô-đun Tweepy để tải các tweet.
- Cách sử dụng SQLAlchemy để lưu trữ và quản lý dữ liệu (mẹo và thẻ bắt đầu bằng #).
- Cách tạo một ứng dụng web đơn giản với Bottle, một khuôn khổ web siêu nhỏ tương tự như Flask.
- Cách sử dụng khung pytest để thêm các bài kiểm tra.
- Hướng dẫn của Trung tâm mã tốt hơn đã dẫn đến mã dễ bảo trì hơn như thế nào.
Nếu bạn muốn làm theo, đọc mã chi tiết (và có thể đóng góp), tôi khuyên bạn nên fork repo. Hãy bắt đầu.
Thiết lập dự án
Đầu tiên, Không gian tên là một trong những ý tưởng tuyệt vời vì vậy chúng ta hãy thực hiện công việc của mình trong môi trường ảo. Sử dụng Anaconda, tôi tạo nó như vậy:
$ virtualenv -p <path-to-python-to-use> ~/virtualenvs/pytip
Tạo cơ sở dữ liệu sản xuất và thử nghiệm trong Postgres:
$ psql
psql (9.6.5, server 9.6.2)
Type "help" for help.
# create database pytip;
CREATE DATABASE
# create database pytip_test;
CREATE DATABASE
Chúng tôi sẽ cần thông tin đăng nhập để kết nối với cơ sở dữ liệu và API Twitter (trước tiên hãy tạo một ứng dụng mới). Theo phương pháp hay nhất, cấu hình nên được lưu trữ trong môi trường, không phải mã. Đặt các biến env sau vào cuối ~ / virtualenvs / pytip / bin / active , tập lệnh xử lý việc kích hoạt / hủy kích hoạt môi trường ảo của bạn, đảm bảo cập nhật các biến cho môi trường của bạn:
export DATABASE_URL='postgres://postgres:password@localhost:5432/pytip'
# twitter
export CONSUMER_KEY='xyz'
export CONSUMER_SECRET='xyz'
export ACCESS_TOKEN='xyz'
export ACCESS_SECRET='xyz'
# if deploying it set this to 'heroku'
export APP_LOCATION=local
Trong chức năng hủy kích hoạt của cùng một tập lệnh, tôi bỏ đặt chúng để chúng tôi giữ mọi thứ nằm ngoài phạm vi trình bao khi hủy kích hoạt (rời khỏi) môi trường ảo:
unset DATABASE_URL
unset CONSUMER_KEY
unset CONSUMER_SECRET
unset ACCESS_TOKEN
unset ACCESS_SECRET
unset APP_LOCATION
Bây giờ là thời điểm tốt để kích hoạt môi trường ảo:
$ source ~/virtualenvs/pytip/bin/activate
Sao chép repo và với môi trường ảo được kích hoạt, hãy cài đặt các yêu cầu:
$ git clone https://github.com/pybites/pytip && cd pytip
$ pip install -r requirements.txt
Tiếp theo, chúng tôi nhập bộ sưu tập các tweet với:
$ python tasks/import_tweets.py
Sau đó, xác minh rằng các bảng đã được tạo và các tweet đã được thêm vào:
$ psql
\c pytip
pytip=# \dt
List of relations
Schema | Name | Type | Owner
--------+----------+-------+----------
public | hashtags | table | postgres
public | tips | table | postgres
(2 rows)
pytip=# select count(*) from tips;
count
-------
222
(1 row)
pytip=# select count(*) from hashtags;
count
-------
27
(1 row)
pytip=# \q
Bây giờ chúng ta hãy chạy các bài kiểm tra:
$ pytest
========================== test session starts ==========================
platform darwin -- Python 3.6.2, pytest-3.2.3, py-1.4.34, pluggy-0.4.0
rootdir: realpython/pytip, inifile:
collected 5 items
tests/test_tasks.py .
tests/test_tips.py ....
========================== 5 passed in 0.61 seconds ==========================
Và cuối cùng chạy ứng dụng Chai với:
$ python app.py
Duyệt đến https:// localhost:8080 và voilà:bạn sẽ thấy các mẹo được sắp xếp giảm dần theo mức độ phổ biến. Nhấp vào liên kết thẻ bắt đầu bằng # ở bên trái hoặc sử dụng hộp tìm kiếm, bạn có thể dễ dàng lọc chúng. Ở đây chúng tôi thấy gấu trúc các mẹo cho ví dụ:
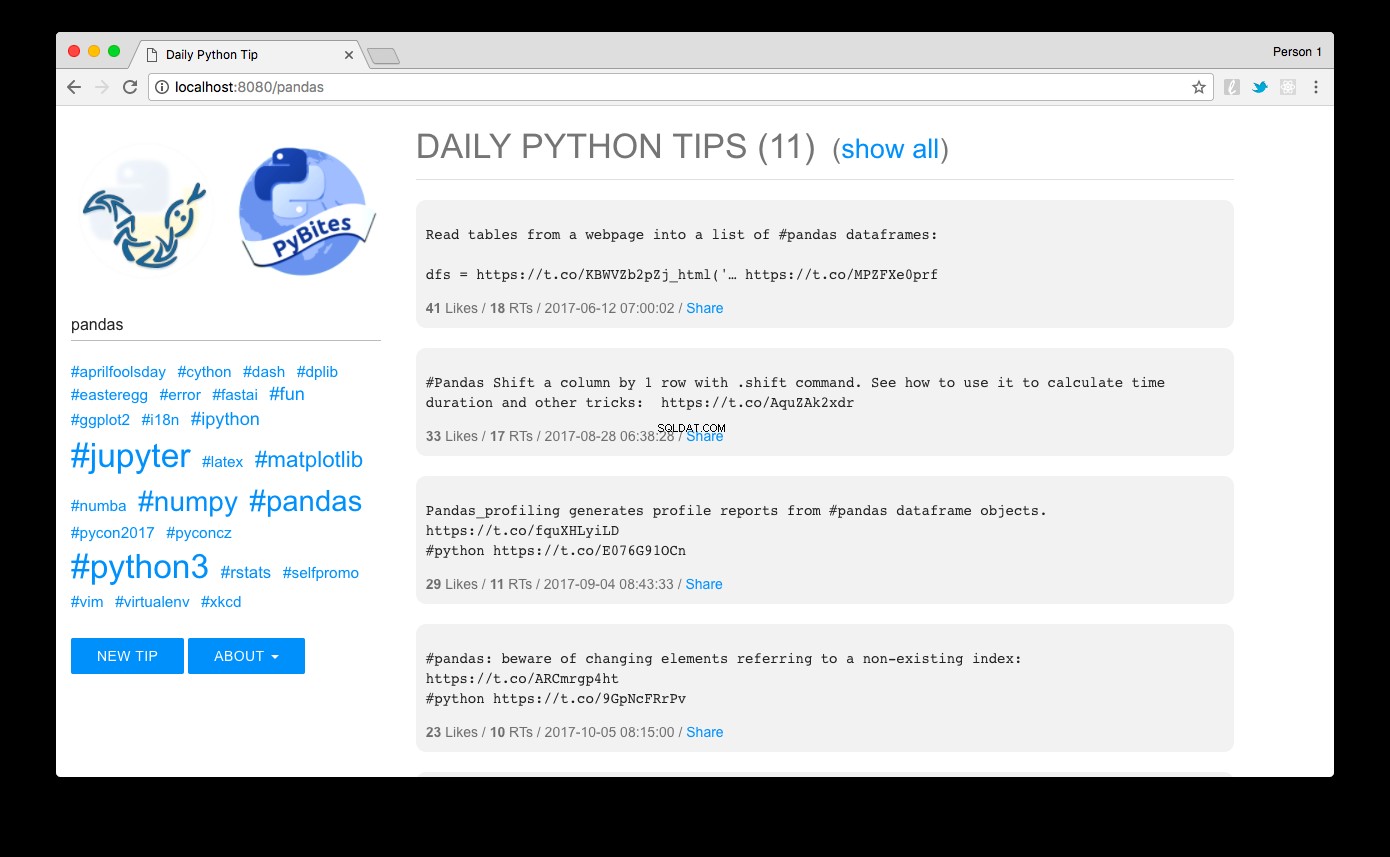
Thiết kế mà tôi đã thực hiện với MUI - một khung CSS nhẹ tuân theo các nguyên tắc Thiết kế Vật liệu của Google.
Chi tiết Triển khai
DB và SQLAlchemy
Tôi đã sử dụng SQLAlchemy để giao tiếp với DB để tránh phải viết nhiều SQL (dư thừa).
Trong mẹo / mô hình.py , chúng tôi xác định các mô hình của mình - Hashtag và Tip - SQLAlchemy đó sẽ ánh xạ tới các bảng DB:
from sqlalchemy import Column, Sequence, Integer, String, DateTime
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Hashtag(Base):
__tablename__ = 'hashtags'
id = Column(Integer, Sequence('id_seq'), primary_key=True)
name = Column(String(20))
count = Column(Integer)
def __repr__(self):
return "<Hashtag('%s', '%d')>" % (self.name, self.count)
class Tip(Base):
__tablename__ = 'tips'
id = Column(Integer, Sequence('id_seq'), primary_key=True)
tweetid = Column(String(22))
text = Column(String(300))
created = Column(DateTime)
likes = Column(Integer)
retweets = Column(Integer)
def __repr__(self):
return "<Tip('%d', '%s')>" % (self.id, self.text)
Trong mẹo / db.py , chúng tôi nhập các mô hình này và giờ đây thật dễ dàng làm việc với DB, chẳng hạn như giao diện với Hashtag mô hình:
def get_hashtags():
return session.query(Hashtag).order_by(Hashtag.name.asc()).all()
Và:
def add_hashtags(hashtags_cnt):
for tag, count in hashtags_cnt.items():
session.add(Hashtag(name=tag, count=count))
session.commit()
Truy vấn API Twitter
Chúng tôi cần lấy dữ liệu từ Twitter. Vì vậy, tôi đã tạo task / import_tweets.py . Tôi đã đóng gói điều này trong nhiệm vụ bởi vì nó nên được chạy trong cronjob hàng ngày để tìm kiếm các mẹo mới và cập nhật số liệu thống kê (số lượt thích và lượt retweet) trên các tweet hiện có. Vì đơn giản, tôi có các bảng được tạo lại hàng ngày. Nếu chúng ta bắt đầu dựa vào quan hệ FK với các bảng khác, chúng ta chắc chắn nên chọn câu lệnh cập nhật thay vì xóa + thêm.
Chúng tôi đã sử dụng tập lệnh này trong Thiết lập dự án. Hãy xem nó làm gì chi tiết hơn.
Đầu tiên, chúng tôi tạo một đối tượng phiên API mà chúng tôi chuyển tới tweepy.Cursor. Tính năng này của API thực sự rất hay:nó giải quyết vấn đề phân trang, lặp lại qua dòng thời gian. Đối với số tiền tip - 222 tại thời điểm tôi viết bài này - nó thực sự nhanh chóng. exclude_replies=True và include_rts=False đối số thuận tiện vì chúng tôi chỉ muốn các tweet của riêng Daily Python Tip (không phải tweet lại).
Việc trích xuất các thẻ bắt đầu bằng # từ các mẹo yêu cầu rất ít mã.
Đầu tiên, tôi đã xác định regex cho thẻ:
TAG = re.compile(r'#([a-z0-9]{3,})')
Sau đó, tôi đã sử dụng findall để nhận tất cả các thẻ.
Tôi đã chuyển chúng vào bộ sưu tập.Counter trả về một đối tượng giống như dict với các thẻ là khóa và được tính là giá trị, được sắp xếp theo thứ tự giảm dần theo giá trị (phổ biến nhất). Tôi đã loại trừ thẻ python quá phổ biến sẽ làm sai lệch kết quả.
def get_hashtag_counter(tips):
blob = ' '.join(t.text.lower() for t in tips)
cnt = Counter(TAG.findall(blob))
if EXCLUDE_PYTHON_HASHTAG:
cnt.pop('python', None)
return cnt
Cuối cùng, import_* các chức năng trong task / import_tweets.py thực hiện việc nhập thực tế các tweet và thẻ bắt đầu bằng #, gọi add_* Phương pháp DB của mẹo thư mục / gói.
Tạo ứng dụng web đơn giản với Chai
Với công việc chuẩn bị này, việc tạo một ứng dụng web trở nên dễ dàng một cách đáng ngạc nhiên (hoặc không quá ngạc nhiên nếu bạn đã sử dụng Flask trước đây).
Trước hết hãy gặp Chai:
Chai là một khuôn khổ web vi mô WSGI nhanh, đơn giản và nhẹ cho Python. Nó được phân phối dưới dạng một mô-đun tệp duy nhất và không có phụ thuộc nào ngoài Thư viện chuẩn Python.
Tốt đẹp. Ứng dụng web kết quả bao gồm <30 LOC và có thể được tìm thấy trong app.py.
Đối với ứng dụng đơn giản này, chỉ cần một phương thức với đối số thẻ tùy chọn là đủ. Tương tự như Flask, việc định tuyến được xử lý bằng decorator. Nếu được gọi bằng thẻ, nó sẽ lọc các mẹo trên thẻ, nếu không nó sẽ hiển thị tất cả. Trình trang trí dạng xem xác định mẫu để sử dụng. Giống như Flask (và Django), chúng tôi trả về một dict để sử dụng trong mẫu.
@route('/')
@route('/<tag>')
@view('index')
def index(tag=None):
tag = tag or request.query.get('tag') or None
tags = get_hashtags()
tips = get_tips(tag)
return {'search_tag': tag or '',
'tags': tags,
'tips': tips}
Theo tài liệu, để làm việc với các tệp tĩnh, bạn thêm đoạn mã này ở trên cùng, sau khi nhập:
@route('/static/<filename:path>')
def send_static(filename):
return static_file(filename, root='static')
Cuối cùng, chúng tôi muốn đảm bảo rằng chúng tôi chỉ chạy ở chế độ gỡ lỗi trên localhost, do đó APP_LOCATION biến env mà chúng tôi đã xác định trong Thiết lập dự án:
if os.environ.get('APP_LOCATION') == 'heroku':
run(host="0.0.0.0", port=int(os.environ.get("PORT", 5000)))
else:
run(host='localhost', port=8080, debug=True, reloader=True)
Mẫu chai
Chai đi kèm với một công cụ tạo mẫu tích hợp nhanh, mạnh mẽ và dễ học có tên là SimpleTemplate.
Trong thư mục con của chế độ xem, tôi đã xác định một header.tpl , index.tpl và footer.tpl . Đối với đám mây thẻ, tôi đã sử dụng một số CSS nội tuyến đơn giản để tăng kích thước thẻ theo số lượng, hãy xem header.tpl :
% for tag in tags:
<a style="font-size: {{ tag.count/10 + 1 }}em;" href="/{{ tag.name }}">#{{ tag.name }}</a>
% end
Trong index.tpl chúng tôi lặp lại các mẹo:
% for tip in tips:
<div class='tip'>
<pre>{{ !tip.text }}</pre>
<div class="mui--text-dark-secondary"><strong>{{ tip.likes }}</strong> Likes / <strong>{{ tip.retweets }}</strong> RTs / {{ tip.created }} / <a href="https://twitter.com/python_tip/status/{{ tip.tweetid }}" target="_blank">Share</a></div>
</div>
% end
Nếu bạn đã quen với Flask và Jinja2, điều này sẽ trông rất quen thuộc. Nhúng Python thậm chí còn dễ dàng hơn, với việc nhập ít hơn— (% ... so với {% ... %} ).
Tất cả css, hình ảnh (và JS nếu chúng tôi muốn sử dụng) sẽ đi vào thư mục con tĩnh.
Và đó là tất cả những gì cần làm để tạo một ứng dụng web cơ bản với Chai. Khi bạn đã xác định đúng lớp dữ liệu, lớp dữ liệu sẽ khá đơn giản.
Thêm các bài kiểm tra với pytest
Bây giờ, hãy làm cho dự án này mạnh mẽ hơn một chút bằng cách thêm một số thử nghiệm. Thử nghiệm DB yêu cầu đào sâu hơn một chút vào khung công tác pytest, nhưng cuối cùng tôi đã sử dụng trình trang trí pytest.fixture để thiết lập và chia nhỏ cơ sở dữ liệu với một số tweet thử nghiệm.
Thay vì gọi API Twitter, tôi đã sử dụng một số dữ liệu tĩnh được cung cấp trong tweets.json Và, thay vì sử dụng DB trực tiếp, trong tips / db.py , Tôi kiểm tra xem pytest có phải là trình gọi không (sys.argv[0] ). Nếu vậy, tôi sử dụng DB thử nghiệm. Tôi có thể sẽ cấu trúc lại cái này, vì Chai hỗ trợ làm việc với các tệp cấu hình.
Phần hashtag dễ kiểm tra hơn (test_get_hashtag_counter ) bởi vì tôi chỉ có thể thêm một số thẻ bắt đầu bằng # vào một chuỗi nhiều dòng. Không cần thiết bị cố định.
Chất lượng mã là vấn đề - Trung tâm mã tốt hơn
Trung tâm mã tốt hơn hướng dẫn bạn bằng văn bản, tốt, mã tốt hơn. Trước khi viết các bài kiểm tra, dự án đã đạt điểm 7:
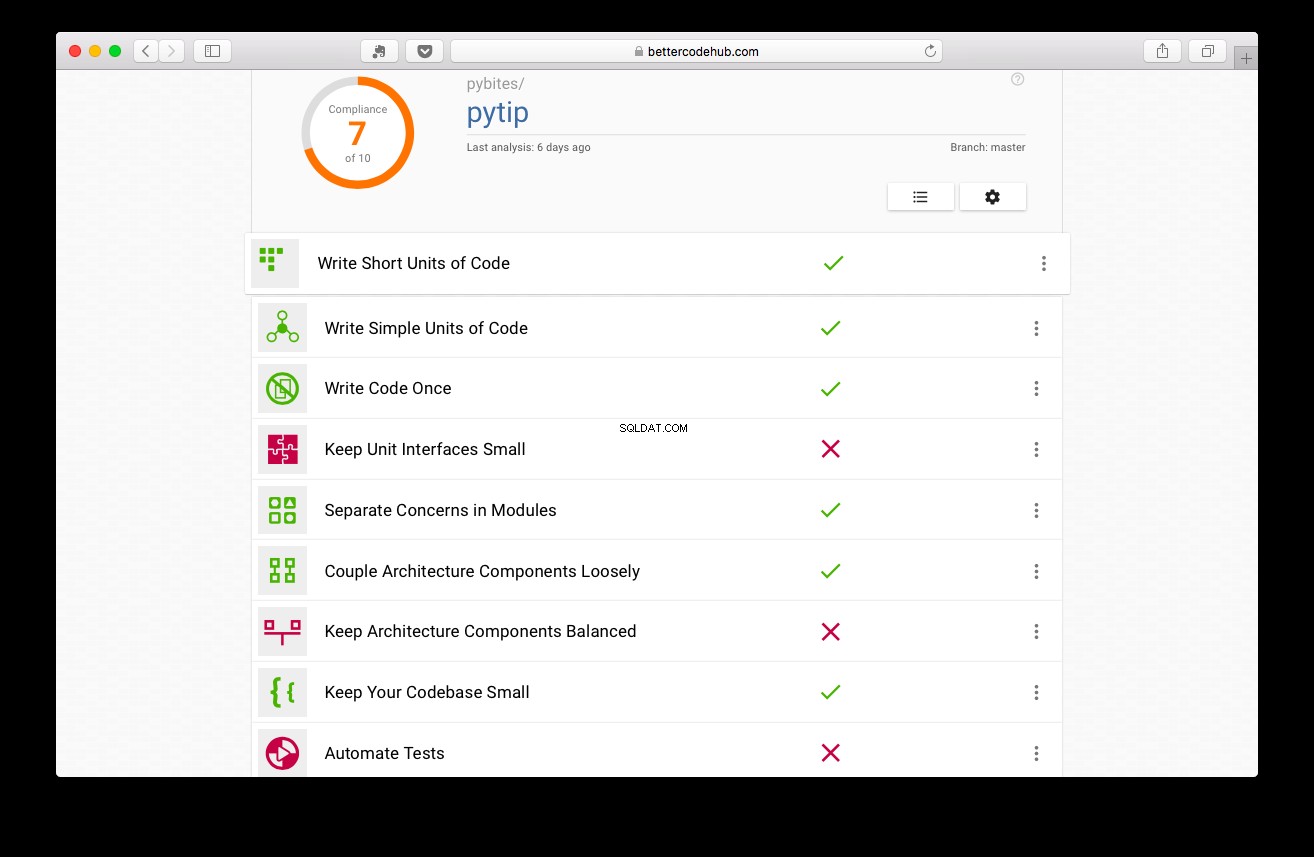
Không tệ, nhưng chúng tôi có thể làm tốt hơn:
-
Tôi đã nâng nó lên điểm 9 bằng cách làm cho mã mô-đun hơn, lấy logic DB ra khỏi app.py (ứng dụng web), đưa nó vào thư mục mẹo / gói (tái cấu trúc 1 và 2)
-
Sau đó, với các bài kiểm tra tại chỗ, dự án đã đạt điểm 10:
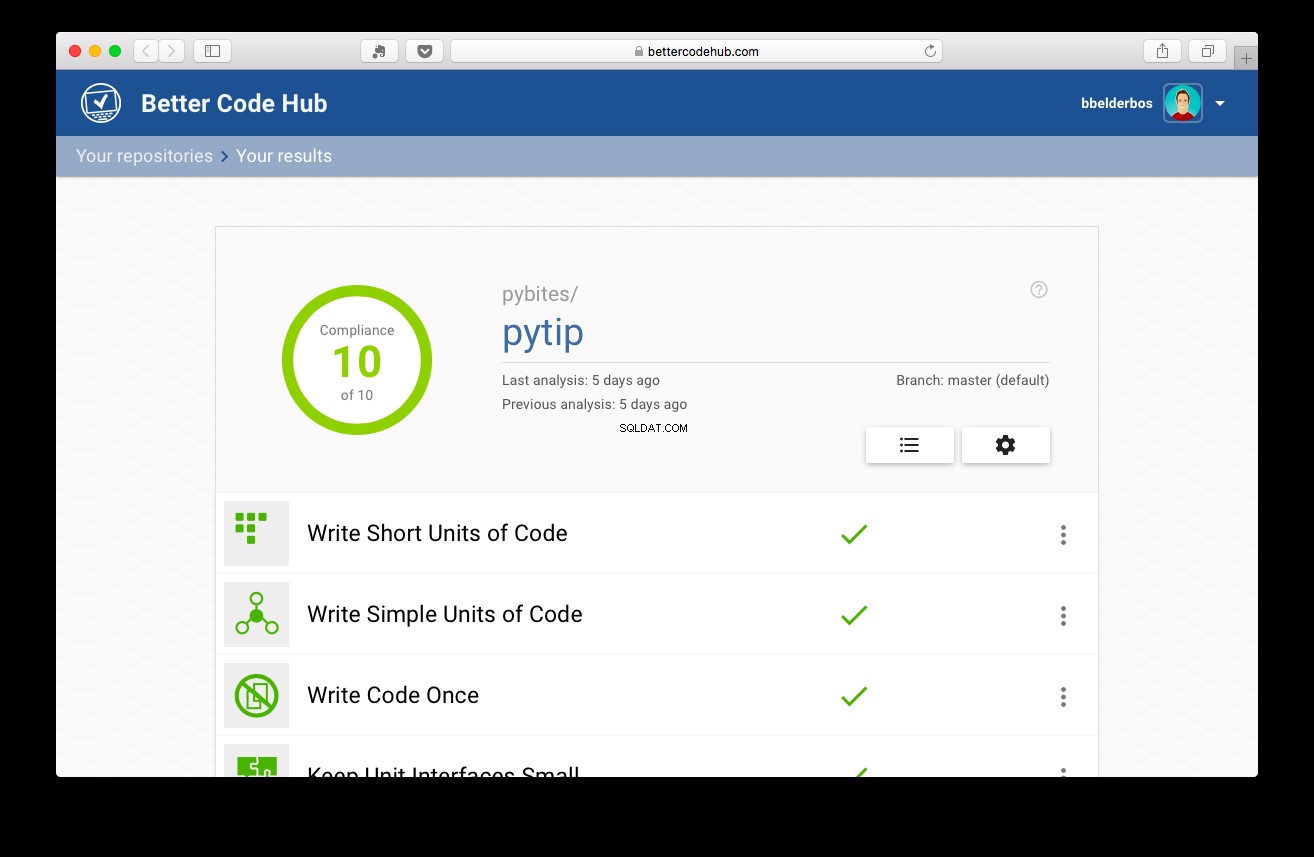
Kết luận và Học hỏi
Thử thách lập trình số 40 của chúng tôi cung cấp một số phương pháp hay:
- Tôi đã tạo một ứng dụng hữu ích có thể mở rộng (tôi muốn thêm một API).
- Tôi đã sử dụng một số mô-đun thú vị đáng để khám phá:Tweepy, SQLAlchemy và Bottle.
- Tôi đã học thêm được một số pytest vì tôi cần các thiết bị cố định để kiểm tra khả năng tương tác với DB.
- Trên hết, phải làm cho mã có thể kiểm tra được, ứng dụng trở nên mô-đun hơn, giúp dễ bảo trì hơn. Trung tâm mã tốt hơn đã giúp ích rất nhiều trong quá trình này.
- Tôi đã triển khai ứng dụng cho Heroku bằng hướng dẫn từng bước của chúng tôi.
Chúng tôi thách thức bạn
Cách tốt nhất để học và cải thiện kỹ năng viết mã của bạn là thực hành. Tại PyBites, chúng tôi củng cố khái niệm này bằng cách tổ chức các thử thách mã Python. Kiểm tra bộ sưu tập đang phát triển của chúng tôi, phân nhánh repo và nhận mã!
Hãy cho chúng tôi biết nếu bạn xây dựng một thứ gì đó thú vị bằng cách đưa ra Yêu cầu kéo cho tác phẩm của bạn. Chúng tôi đã thấy mọi người thực sự vươn mình vượt qua những thử thách này và chúng tôi cũng vậy.
Chúc bạn viết mã vui vẻ!