Trong Phần 1 của loạt bài này, bạn đã sử dụng Flask và Connexion để tạo API REST cung cấp các hoạt động CRUD cho một cấu trúc trong bộ nhớ đơn giản được gọi là PEOPLE . Điều đó hoạt động để chứng minh cách mô-đun Connexion giúp bạn xây dựng một API REST đẹp cùng với tài liệu tương tác.
Như một số lưu ý trong phần nhận xét cho Phần 1, PEOPLE cấu trúc được khởi tạo lại mỗi khi ứng dụng được khởi động lại. Trong bài viết này, bạn sẽ tìm hiểu cách lưu trữ PEOPLE cấu trúc và các hành động mà API cung cấp cho cơ sở dữ liệu sử dụng SQLAlchemy và Marshmallow.
SQLAlchemy cung cấp Mô hình quan hệ đối tượng (ORM), mô hình này lưu trữ các đối tượng Python vào cơ sở dữ liệu biểu diễn dữ liệu của đối tượng. Điều đó có thể giúp bạn tiếp tục suy nghĩ theo cách Pythonic và không quan tâm đến cách dữ liệu đối tượng sẽ được biểu diễn trong cơ sở dữ liệu.
Marshmallow cung cấp chức năng tuần tự hóa và giải mã hóa các đối tượng Python khi chúng chảy ra và vào API REST dựa trên JSON của chúng tôi. Marshmallow chuyển đổi các phiên bản lớp Python thành các đối tượng có thể được chuyển đổi sang JSON.
Bạn có thể tìm thấy mã Python cho bài viết này tại đây.
Tiền thưởng miễn phí: Nhấp vào đây để tải xuống bản sao của Hướng dẫn "Ví dụ về API REST" và nhận phần giới thiệu thực hành về các nguyên tắc của Python + REST API với các ví dụ có thể hành động.
Bài viết này dành cho ai
Nếu bạn thích Phần 1 của loạt bài này, thì bài viết này sẽ mở rộng thêm dây đai dụng cụ của bạn. Bạn sẽ sử dụng SQLAlchemy để truy cập cơ sở dữ liệu theo cách Pythonic hơn là SQL thông thường. Bạn cũng sẽ sử dụng Marshmallow để tuần tự hóa và giải mã hóa dữ liệu do REST API quản lý. Để làm được điều này, bạn sẽ sử dụng các tính năng Lập trình hướng đối tượng cơ bản có sẵn trong Python.
Bạn cũng sẽ sử dụng SQLAlchemy để tạo cơ sở dữ liệu cũng như tương tác với nó. Điều này là cần thiết để thiết lập và chạy API REST với PEOPLE dữ liệu được sử dụng trong Phần 1.
Ứng dụng web được trình bày trong Phần 1 sẽ có các tệp HTML và JavaScript được sửa đổi theo những cách nhỏ để hỗ trợ các thay đổi. Bạn có thể xem lại phiên bản cuối cùng của mã từ Phần 1 tại đây.
Phụ thuộc bổ sung
Trước khi bắt đầu xây dựng chức năng mới này, bạn cần cập nhật virtualenv bạn đã tạo để chạy mã Phần 1 hoặc tạo một mã mới cho dự án này. Cách dễ nhất để làm điều đó sau khi bạn đã kích hoạt virtualenv của mình là chạy lệnh sau:
$ pip install Flask-SQLAlchemy flask-marshmallow marshmallow-sqlalchemy marshmallow
Điều này bổ sung nhiều chức năng hơn cho virtualenv của bạn:
-
Flask-SQLAlchemythêm SQLAlchemy, cùng với một số liên kết với Flask, cho phép các chương trình truy cập cơ sở dữ liệu. -
flask-marshmallowthêm các phần Flask của Marshmallow, cho phép các chương trình chuyển đổi các đối tượng Python sang và từ các cấu trúc có thể tuần tự hóa. -
marshmallow-sqlalchemythêm một số móc Marshmallow vào SQLAlchemy để cho phép các chương trình tuần tự hóa và giải mã hóa các đối tượng Python do SQLAlchemy tạo ra. -
marshmallowthêm phần lớn chức năng Marshmallow.
Dữ liệu về con người
Như đã đề cập ở trên, PEOPLE cấu trúc dữ liệu trong bài viết trước là một từ điển Python trong bộ nhớ. Trong từ điển đó, bạn đã sử dụng họ của người đó làm khóa tra cứu. Cấu trúc dữ liệu trông giống như thế này trong mã:
# Data to serve with our API
PEOPLE = {
"Farrell": {
"fname": "Doug",
"lname": "Farrell",
"timestamp": get_timestamp()
},
"Brockman": {
"fname": "Kent",
"lname": "Brockman",
"timestamp": get_timestamp()
},
"Easter": {
"fname": "Bunny",
"lname": "Easter",
"timestamp": get_timestamp()
}
}
Các sửa đổi bạn sẽ thực hiện đối với chương trình sẽ chuyển tất cả dữ liệu vào bảng cơ sở dữ liệu. Điều này có nghĩa là dữ liệu sẽ được lưu vào đĩa của bạn và sẽ tồn tại giữa các lần chạy server.py chương trình.
Vì họ là khóa từ điển nên mã hạn chế việc thay đổi họ của một người:chỉ có thể thay đổi tên. Ngoài ra, việc chuyển sang cơ sở dữ liệu sẽ cho phép bạn thay đổi họ vì họ sẽ không còn được sử dụng làm khóa tra cứu cho một người nữa.
Về mặt khái niệm, một bảng cơ sở dữ liệu có thể được coi như một mảng hai chiều, trong đó các hàng là các bản ghi và các cột là các trường trong các bản ghi đó.
Các bảng cơ sở dữ liệu thường có giá trị số nguyên tự động tăng dần làm khóa tra cứu cho các hàng. Đây được gọi là khóa chính. Mỗi bản ghi trong bảng sẽ có một khóa chính có giá trị là duy nhất trên toàn bộ bảng. Việc có khóa chính độc lập với dữ liệu được lưu trữ trong bảng giúp bạn có thể sửa đổi bất kỳ trường nào khác trong hàng.
Lưu ý:
Khóa chính tự động tăng dần có nghĩa là cơ sở dữ liệu sẽ đảm nhận:
- Tăng trường khóa chính lớn nhất hiện có mỗi khi một bản ghi mới được chèn vào bảng
- Sử dụng giá trị đó làm khóa chính cho dữ liệu mới được chèn vào
Điều này đảm bảo một khóa chính duy nhất khi bảng phát triển.
Bạn sẽ tuân theo quy ước cơ sở dữ liệu đặt tên bảng là số ít, vì vậy bảng sẽ được gọi là person . Dịch PEOPLE của chúng tôi cấu trúc ở trên thành một bảng cơ sở dữ liệu có tên person cung cấp cho bạn cái này:
| person_id | lname | fname | dấu thời gian |
|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01.888444 |
| 2 | Brockman | Kent | 2018-08-08 21:16:01.889060 |
| 3 | Lễ Phục sinh | Chú thỏ | 2018-08-08 21:16:01.886834 |
Mỗi cột trong bảng có một tên trường như sau:
-
person_id: trường khóa chính cho mỗi người -
lname: họ của người đó -
fname: tên của người đó -
timestamp: dấu thời gian được liên kết với các hành động chèn / cập nhật
Tương tác cơ sở dữ liệu
Bạn sẽ sử dụng SQLite làm công cụ cơ sở dữ liệu để lưu trữ PEOPLE dữ liệu. SQLite là cơ sở dữ liệu được phân phối rộng rãi nhất trên thế giới và nó đi kèm với Python miễn phí. Nó nhanh chóng, thực hiện tất cả công việc bằng cách sử dụng tệp và phù hợp với nhiều dự án lớn. Đó là một RDBMS (Hệ thống quản lý cơ sở dữ liệu quan hệ) hoàn chỉnh bao gồm SQL, ngôn ngữ của nhiều hệ thống cơ sở dữ liệu.
Hiện tại, hãy tưởng tượng về person bảng đã tồn tại trong cơ sở dữ liệu SQLite. Nếu bạn đã có bất kỳ kinh nghiệm nào với RDBMS, bạn có thể biết về SQL, Ngôn ngữ truy vấn có cấu trúc mà hầu hết các RDBMS sử dụng để tương tác với cơ sở dữ liệu.
Không giống như các ngôn ngữ lập trình như Python, SQL không xác định cách thức để lấy dữ liệu:nó mô tả cái gì dữ liệu được mong muốn, để lại cách thức lên đến công cụ cơ sở dữ liệu.
Truy vấn SQL lấy tất cả dữ liệu trong person của chúng tôi bảng, được sắp xếp theo họ, sẽ trông như sau:
SELECT * FROM person ORDER BY 'lname';
Truy vấn này yêu cầu công cụ cơ sở dữ liệu lấy tất cả các trường từ bảng người và sắp xếp chúng theo thứ tự tăng dần, mặc định bằng cách sử dụng lname đồng ruộng.
Nếu bạn chạy truy vấn này với cơ sở dữ liệu SQLite có chứa person bảng, kết quả sẽ là một tập hợp các bản ghi chứa tất cả các hàng trong bảng, với mỗi hàng chứa dữ liệu từ tất cả các trường tạo thành một hàng. Dưới đây là một ví dụ sử dụng công cụ dòng lệnh SQLite chạy truy vấn trên với person bảng cơ sở dữ liệu:
sqlite> SELECT * FROM person ORDER BY lname;
2|Brockman|Kent|2018-08-08 21:16:01.888444
3|Easter|Bunny|2018-08-08 21:16:01.889060
1|Farrell|Doug|2018-08-08 21:16:01.886834
Kết quả đầu ra ở trên là danh sách tất cả các hàng trong person bảng cơ sở dữ liệu với các ký tự ống dẫn (‘|’) phân tách các trường trong hàng, được thực hiện cho mục đích hiển thị bởi SQLite.
Python hoàn toàn có khả năng giao tiếp với nhiều công cụ cơ sở dữ liệu và thực hiện truy vấn SQL ở trên. Các kết quả rất có thể sẽ là một danh sách các bộ giá trị. Danh sách bên ngoài chứa tất cả các bản ghi trong person bàn. Mỗi bộ dữ liệu bên trong riêng lẻ sẽ chứa tất cả dữ liệu đại diện cho mỗi trường được xác định cho một hàng trong bảng.
Lấy dữ liệu theo cách này không phải là Pythonic cho lắm. Danh sách các bản ghi thì không sao, nhưng mỗi bản ghi riêng lẻ chỉ là một bộ dữ liệu. Chương trình phải biết chỉ mục của từng trường để truy xuất một trường cụ thể. Đoạn mã Python sau sử dụng SQLite để trình bày cách chạy truy vấn trên và hiển thị dữ liệu:
1import sqlite3
2
3conn = sqlite3.connect('people.db')
4cur = conn.cursor()
5cur.execute('SELECT * FROM person ORDER BY lname')
6people = cur.fetchall()
7for person in people:
8 print(f'{person[2]} {person[1]}')
Chương trình trên thực hiện những việc sau:
-
Dòng 1 nhập
sqlite3mô-đun. -
Dòng 3 tạo kết nối với tệp cơ sở dữ liệu.
-
Dòng 4 tạo con trỏ từ kết nối.
-
Dòng 5 sử dụng con trỏ để thực thi một
SQLtruy vấn được biểu thị dưới dạng một chuỗi. -
Dòng 6 nhận tất cả các bản ghi được trả về bởi
SQLtruy vấn và gán chúng chopersonbiến. -
Dòng 7 &8 lặp qua
personbiến danh sách và in ra họ và tên của từng người.
people biến từ Dòng 6 ở trên sẽ giống như thế này bằng Python:
people = [
(2, 'Brockman', 'Kent', '2018-08-08 21:16:01.888444'),
(3, 'Easter', 'Bunny', '2018-08-08 21:16:01.889060'),
(1, 'Farrell', 'Doug', '2018-08-08 21:16:01.886834')
]
Đầu ra của chương trình ở trên trông giống như sau:
Kent Brockman
Bunny Easter
Doug Farrell
Trong chương trình trên, bạn phải biết rằng tên của một người ở chỉ mục 2 và họ của một người ở chỉ mục 1 . Tệ hơn nữa, cấu trúc bên trong của person cũng phải được biết bất cứ khi nào bạn chuyển biến lặp lại person dưới dạng một tham số cho một hàm hoặc một phương thức.
Sẽ tốt hơn nhiều nếu những gì bạn nhận lại cho person là một đối tượng Python, trong đó mỗi trường là một thuộc tính của đối tượng. Đây là một trong những điều SQLAlchemy làm.
Bàn Bobby Nhỏ
Trong chương trình trên, câu lệnh SQL là một chuỗi đơn giản được truyền trực tiếp đến cơ sở dữ liệu để thực thi. Trong trường hợp này, đó không phải là vấn đề vì SQL là một chuỗi theo nghĩa đen hoàn toàn nằm dưới sự kiểm soát của chương trình. Tuy nhiên, trường hợp sử dụng cho API REST của bạn sẽ lấy đầu vào của người dùng từ ứng dụng web và sử dụng nó để tạo truy vấn SQL. Điều này có thể mở ứng dụng của bạn để tấn công.
Bạn sẽ nhớ lại từ Phần 1 rằng REST API để có được một person duy nhất từ PEOPLE dữ liệu trông như thế này:
GET /api/people/{lname}
Điều này có nghĩa là API của bạn đang mong đợi một biến, lname , trong đường dẫn điểm cuối URL mà nó sử dụng để tìm một person . Sửa đổi mã Python SQLite từ bên trên để thực hiện việc này sẽ trông giống như sau:
1lname = 'Farrell'
2cur.execute('SELECT * FROM person WHERE lname = \'{}\''.format(lname))
Đoạn mã trên thực hiện những việc sau:
-
Dòng 1 đặt
lnamebiến thành'Farrell'. Điều này sẽ đến từ đường dẫn điểm cuối URL REST API. -
Dòng 2 sử dụng định dạng chuỗi Python để tạo chuỗi SQL và thực thi nó.
Để đơn giản hóa mọi thứ, đoạn mã trên đặt lname biến thành một hằng số, nhưng thực sự nó sẽ đến từ đường dẫn điểm cuối URL API và có thể là bất kỳ thứ gì do người dùng cung cấp. SQL được tạo bởi định dạng chuỗi trông giống như sau:
SELECT * FROM person WHERE lname = 'Farrell'
Khi cơ sở dữ liệu SQL này thực thi, nó sẽ tìm kiếm person bảng cho một bản ghi có họ bằng 'Farrell' . Đây là những gì dự định, nhưng bất kỳ chương trình nào chấp nhận thông tin nhập của người dùng cũng sẽ mở cho những người dùng độc hại. Trong chương trình trên, nơi lname biến được đặt bởi đầu vào do người dùng cung cấp, điều này sẽ mở chương trình của bạn tới cái được gọi là tấn công chèn SQL. Đây là cái được gọi trìu mến là Bàn Little Bobby:
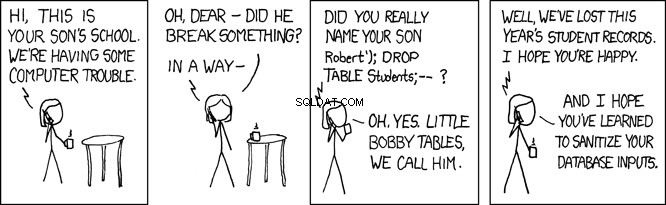
Ví dụ:hãy tưởng tượng một người dùng độc hại gọi là API REST của bạn theo cách này:
GET /api/people/Farrell');DROP TABLE person;
Yêu cầu API REST ở trên đặt lname biến thành 'Farrell');DROP TABLE person;' , trong đoạn mã trên sẽ tạo ra câu lệnh SQL này:
SELECT * FROM person WHERE lname = 'Farrell');DROP TABLE person;
Câu lệnh SQL ở trên là hợp lệ và khi được thực thi bởi cơ sở dữ liệu, nó sẽ tìm thấy một bản ghi trong đó lname khớp với 'Farrell' . Sau đó, nó sẽ tìm ký tự phân cách câu lệnh SQL ; và sẽ tiếp tục ngay trước và bỏ toàn bộ bảng. Điều này về cơ bản sẽ phá hủy ứng dụng của bạn.
Bạn có thể bảo vệ chương trình của mình bằng cách khử trùng tất cả dữ liệu bạn nhận được từ người dùng ứng dụng của bạn. Dọn dẹp dữ liệu trong ngữ cảnh này có nghĩa là chương trình của bạn phải kiểm tra dữ liệu do người dùng cung cấp và đảm bảo dữ liệu đó không chứa bất kỳ thứ gì nguy hiểm cho chương trình. Điều này có thể khó thực hiện đúng và sẽ phải được thực hiện ở mọi nơi dữ liệu người dùng tương tác với cơ sở dữ liệu.
Có một cách khác dễ dàng hơn nhiều:sử dụng SQLAlchemy. Nó sẽ làm sạch dữ liệu người dùng cho bạn trước khi tạo các câu lệnh SQL. Đó là một lợi thế và lý do lớn khác để sử dụng SQLAlchemy khi làm việc với cơ sở dữ liệu.
Lập mô hình dữ liệu với SQLAlchemy
SQLAlchemy là một dự án lớn và cung cấp rất nhiều chức năng để làm việc với cơ sở dữ liệu bằng Python. Một trong những thứ mà nó cung cấp là ORM hoặc Object Relational Mapper và đây là thứ bạn sẽ sử dụng để tạo và làm việc với person bảng cơ sở dữ liệu. Điều này cho phép bạn ánh xạ một hàng trường từ bảng cơ sở dữ liệu sang một đối tượng Python.
Lập trình hướng đối tượng cho phép bạn kết nối dữ liệu cùng với hành vi, chức năng hoạt động trên dữ liệu đó. Bằng cách tạo các lớp SQLAlchemy, bạn có thể kết nối các trường từ các hàng trong bảng cơ sở dữ liệu với hành vi, cho phép bạn tương tác với dữ liệu. Đây là định nghĩa lớp SQLAlchemy cho dữ liệu trong person bảng cơ sở dữ liệu:
class Person(db.Model):
__tablename__ = 'person'
person_id = db.Column(db.Integer,
primary_key=True)
lname = db.Column(db.String)
fname = db.Column(db.String)
timestamp = db.Column(db.DateTime,
default=datetime.utcnow,
onupdate=datetime.utcnow)
Lớp Person kế thừa từ db.Model , mà bạn sẽ nhận được khi bắt đầu xây dựng mã chương trình. Hiện tại, điều đó có nghĩa là bạn đang kế thừa từ một lớp cơ sở có tên là Model , cung cấp các thuộc tính và chức năng chung cho tất cả các lớp có nguồn gốc từ nó.
Phần còn lại của các định nghĩa là các thuộc tính cấp độ lớp được định nghĩa như sau:
-
__tablename__ = 'person'kết nối định nghĩa lớp vớipersonbảng cơ sở dữ liệu. -
person_id = db.Column(db.Integer, primary_key=True)tạo một cột cơ sở dữ liệu chứa một số nguyên đóng vai trò là khóa chính cho bảng. Điều này cũng cho cơ sở dữ liệu biết rằngperson_idsẽ là một giá trị Số nguyên tự động tăng thêm. -
lname = db.Column(db.String)tạo trường họ, một cột cơ sở dữ liệu có chứa giá trị chuỗi. -
fname = db.Column(db.String)tạo trường tên, một cột cơ sở dữ liệu có chứa giá trị chuỗi. -
timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)tạo trường dấu thời gian, cột cơ sở dữ liệu chứa giá trị ngày / giờ.default=datetime.utcnowtham số mặc định giá trị dấu thời gian thànhutcnowhiện tại giá trị khi một bản ghi được tạo.onupdate=datetime.utcnowtham số cập nhật dấu thời gian vớiutcnowhiện tại giá trị khi bản ghi được cập nhật.
Lưu ý:Dấu thời gian UTC
Bạn có thể thắc mắc tại sao dấu thời gian trong lớp trên được mặc định thành và được cập nhật bởi datetime.utcnow() , trả về UTC hoặc Giờ Phối hợp Quốc tế. Đây là một cách chuẩn hóa nguồn dấu thời gian của bạn.
Nguồn, hay thời gian không, là một đường chạy theo hướng bắc và nam từ cực bắc đến nam của Trái đất qua Vương quốc Anh. Đây là múi giờ 0 mà từ đó tất cả các múi giờ khác được bù đắp. Bằng cách sử dụng nguồn này làm nguồn thời gian 0, dấu thời gian của bạn chênh lệch với điểm tham chiếu tiêu chuẩn này.
Nếu ứng dụng của bạn được truy cập từ các múi giờ khác nhau, bạn có cách để thực hiện tính toán ngày / giờ. Tất cả những gì bạn cần là dấu thời gian UTC và múi giờ đích.
Nếu bạn đã sử dụng múi giờ địa phương làm nguồn dấu thời gian của mình, thì bạn không thể thực hiện tính toán ngày / giờ mà không có thông tin về múi giờ địa phương được bù đắp từ 0 giờ. Nếu không có thông tin nguồn dấu thời gian, bạn hoàn toàn không thể thực hiện bất kỳ phép toán so sánh ngày / giờ nào.
Làm việc với dấu thời gian dựa trên UTC là một tiêu chuẩn tốt để tuân theo. Đây là trang web bộ công cụ để làm việc và hiểu rõ hơn về chúng.
Bạn đang đi đâu với Person này định nghĩa giai cấp? Mục tiêu cuối cùng là có thể chạy truy vấn bằng SQLAlchemy và lấy lại danh sách các bản sao của Person lớp. Để làm ví dụ, hãy xem câu lệnh SQL trước:
SELECT * FROM people ORDER BY lname;
Hiển thị cùng một chương trình ví dụ nhỏ ở trên, nhưng hiện đang sử dụng SQLAlchemy:
1from models import Person
2
3people = Person.query.order_by(Person.lname).all()
4for person in people:
5 print(f'{person.fname} {person.lname}')
Bỏ qua dòng 1 lúc này, những gì bạn muốn là tất cả person các bản ghi được sắp xếp theo thứ tự tăng dần theo lname đồng ruộng. Những gì bạn nhận lại được từ các câu lệnh SQLAlchemy Person.query.order_by(Person.lname).all() là danh sách của Person các đối tượng cho tất cả các bản ghi trong person bảng cơ sở dữ liệu theo thứ tự đó. Trong chương trình trên, people biến chứa danh sách Person đối tượng.
Chương trình lặp lại trên person biến, lấy từng person lần lượt và in ra họ và tên của người đó từ cơ sở dữ liệu. Lưu ý rằng chương trình không phải sử dụng các chỉ mục để lấy fname hoặc lname giá trị:nó sử dụng các thuộc tính được xác định trên Person đối tượng.
Sử dụng SQLAlchemy cho phép bạn suy nghĩ về các đối tượng có hành vi hơn là SQL thô . Điều này thậm chí còn trở nên có lợi hơn khi các bảng cơ sở dữ liệu của bạn trở nên lớn hơn và các tương tác phức tạp hơn.
Serializing / Deserializing Dataed Modeled Data
Làm việc với dữ liệu được mô hình hóa SQLAlchemy bên trong các chương trình của bạn rất thuận tiện. Nó đặc biệt thuận tiện trong các chương trình thao tác dữ liệu, có thể là tính toán hoặc sử dụng nó để tạo các bản trình bày trên màn hình. Ứng dụng của bạn về cơ bản là một API REST cung cấp các hoạt động CRUD trên dữ liệu và do đó nó không thực hiện nhiều thao tác dữ liệu.
API REST hoạt động với dữ liệu JSON và ở đây bạn có thể gặp sự cố với mô hình SQLAlchemy. Vì dữ liệu do SQLAlchemy trả về là các bản sao của lớp Python nên Connexion không thể tuần tự hóa các bản sao lớp này thành dữ liệu có định dạng JSON. Hãy nhớ từ Phần 1 rằng Connexion là công cụ bạn đã sử dụng để thiết kế và định cấu hình API REST bằng cách sử dụng tệp YAML và kết nối các phương thức Python với nó.
Trong ngữ cảnh này, tuần tự hóa có nghĩa là chuyển đổi các đối tượng Python, có thể chứa các đối tượng Python khác và các kiểu dữ liệu phức tạp, thành các cấu trúc dữ liệu đơn giản hơn có thể được phân tích cú pháp thành các kiểu dữ liệu JSON, được liệt kê ở đây:
-
string: một loại chuỗi -
number: các số được Python hỗ trợ (số nguyên, số float, longs) -
object: một đối tượng JSON, gần tương đương với một từ điển Python -
array: gần tương đương với một Danh sách Python -
boolean: được biểu diễn trong JSON dưới dạngtruehoặcfalse, nhưng trong Python làTruehoặcFalse -
null: về cơ bản là mộtNonebằng Python
Ví dụ:Person của bạn lớp chứa một dấu thời gian, là một DateTime trong Python . Không có định nghĩa ngày / giờ trong JSON, vì vậy dấu thời gian phải được chuyển đổi thành chuỗi để tồn tại trong cấu trúc JSON.
Person của bạn lớp đủ đơn giản nên việc lấy các thuộc tính dữ liệu từ nó và tạo từ điển theo cách thủ công để trả về từ các điểm cuối REST URL của chúng tôi sẽ không khó lắm. Trong một ứng dụng phức tạp hơn với nhiều mô hình SQLAlchemy lớn hơn, điều này sẽ không xảy ra. Giải pháp tốt hơn là sử dụng mô-đun có tên Marshmallow để thực hiện công việc cho bạn.
Marshmallow giúp bạn tạo PersonSchema lớp, giống như SQLAlchemy Person lớp chúng tôi đã tạo. Tuy nhiên, ở đây, thay vì ánh xạ các bảng cơ sở dữ liệu và tên trường với lớp và các thuộc tính của nó, PersonSchema lớp xác định cách các thuộc tính của một lớp sẽ được chuyển đổi thành các định dạng thân thiện với JSON. Đây là định nghĩa lớp Marshmallow cho dữ liệu trong person của chúng tôi bảng:
class PersonSchema(ma.ModelSchema):
class Meta:
model = Person
sqla_session = db.session
Lớp PersonSchema kế thừa từ ma.ModelSchema , mà bạn sẽ nhận được khi bắt đầu xây dựng mã chương trình. Hiện tại, điều này có nghĩa là PersonSchema đang kế thừa từ một lớp cơ sở Marshmallow được gọi là ModelSchema , cung cấp các thuộc tính và chức năng chung cho tất cả các lớp có nguồn gốc từ nó.
Phần còn lại của định nghĩa như sau:
-
class Metađịnh nghĩa một lớp có tênMetatrong lớp học của bạn.ModelSchemalớp màPersonSchemalớp kế thừa từ ngoại hình choMetanội bộ này và sử dụng nó để tìm mô hình SQLAlchemyPersonvàdb.session. Đây là cách Marshmallow tìm thấy các thuộc tính trongPersonlớp và kiểu của những thuộc tính đó để nó biết cách tuần tự hóa / giải mã hóa chúng. -
modelcho lớp biết mô hình SQLAlchemy nào sẽ sử dụng để tuần tự hóa / giải mã hóa dữ liệu đến và đi. -
db.sessioncho lớp biết phiên cơ sở dữ liệu nào sẽ sử dụng để xem xét bên trong và xác định các kiểu dữ liệu thuộc tính.
Bạn đang hướng đến đâu với định nghĩa lớp này? Bạn muốn có thể tuần tự hóa một phiên bản của Person phân loại thành dữ liệu JSON và để giải mã hóa dữ liệu JSON và tạo một Person các cá thể lớp từ nó.
Tạo cơ sở dữ liệu được khởi tạo
SQLAlchemy xử lý nhiều tương tác cụ thể đối với cơ sở dữ liệu cụ thể và cho phép bạn tập trung vào các mô hình dữ liệu cũng như cách sử dụng chúng.
Bây giờ bạn thực sự sẽ tạo một cơ sở dữ liệu, như đã đề cập trước đây, bạn sẽ sử dụng SQLite. Bạn đang làm điều này vì một số lý do. Nó đi kèm với Python và không cần phải cài đặt như một mô-đun riêng biệt. Nó lưu tất cả thông tin cơ sở dữ liệu trong một tệp duy nhất và do đó dễ thiết lập và sử dụng.
Cài đặt một máy chủ cơ sở dữ liệu riêng biệt như MySQL hoặc PostgreSQL sẽ hoạt động tốt nhưng sẽ yêu cầu cài đặt các hệ thống đó và khởi động chúng và chạy, điều này nằm ngoài phạm vi của bài viết này.
Bởi vì SQLAlchemy xử lý cơ sở dữ liệu, theo nhiều cách, nó thực sự không quan trọng cơ sở dữ liệu bên dưới là gì.
Bạn sẽ tạo một chương trình tiện ích mới có tên là build_database.py để tạo và khởi tạo SQLite people.db tệp cơ sở dữ liệu chứa person của bạn bảng cơ sở dữ liệu. Trong quá trình này, bạn sẽ tạo hai mô-đun Python, config.py và models.py , sẽ được sử dụng bởi build_database.py và server.py đã sửa đổi từ Phần 1.
Đây là nơi bạn có thể tìm thấy mã nguồn cho các mô-đun bạn sắp tạo, được giới thiệu tại đây:
-
config.pyđược nhập các mô-đun cần thiết vào chương trình và được cấu hình. Điều này bao gồm Flask, Connexion, SQLAlchemy và Marshmallow. Vì nó sẽ được sử dụng bởi cảbuild_database.pyvàserver.py, một số phần của cấu hình sẽ chỉ áp dụng choserver.pyứng dụng. -
models.pylà mô-đun nơi bạn sẽ tạoPersonSQLAlchemy vàPersonSchemaĐịnh nghĩa lớp Marshmallow được mô tả ở trên. Mô-đun này phụ thuộc vàoconfig.pycho một số đối tượng được tạo và định cấu hình ở đó.
Mô-đun cấu hình
config.py mô-đun, như tên của nó, là nơi tất cả thông tin cấu hình được tạo và khởi tạo. Chúng tôi sẽ sử dụng mô-đun này cho cả build_database.py của chúng tôi tệp chương trình và sắp được cập nhật server.py tập tin từ bài báo Phần 1. Điều này có nghĩa là chúng ta sẽ định cấu hình Flask, Connexion, SQLAlchemy và Marshmallow tại đây.
Mặc dù build_database.py chương trình không sử dụng Flask, Connexion hoặc Marshmallow, nó sử dụng SQLAlchemy để tạo kết nối của chúng tôi với cơ sở dữ liệu SQLite. Đây là mã cho config.py mô-đun:
1import os
2import connexion
3from flask_sqlalchemy import SQLAlchemy
4from flask_marshmallow import Marshmallow
5
6basedir = os.path.abspath(os.path.dirname(__file__))
7
8# Create the Connexion application instance
9connex_app = connexion.App(__name__, specification_dir=basedir)
10
11# Get the underlying Flask app instance
12app = connex_app.app
13
14# Configure the SQLAlchemy part of the app instance
15app.config['SQLALCHEMY_ECHO'] = True
16app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:////' + os.path.join(basedir, 'people.db')
17app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
18
19# Create the SQLAlchemy db instance
20db = SQLAlchemy(app)
21
22# Initialize Marshmallow
23ma = Marshmallow(app)
Đây là những gì đoạn mã trên đang thực hiện:
-
Dòng 2 - 4 nhập Connexion như bạn đã làm trong
server.pychương trình từ Phần 1. Nó cũng nhậpSQLAlchemytừflask_sqlalchemymô-đun. Điều này cho phép bạn truy cập cơ sở dữ liệu chương trình. Cuối cùng, nó nhậpMarshmallowtừflask_marshamllowmô-đun. -
Dòng 6 tạo biến
basedirtrỏ đến thư mục mà chương trình đang chạy. -
Dòng 9 sử dụng
basedirbiến để tạo phiên bản ứng dụng Connexion và cung cấp cho nó đường dẫn đếnswagger.ymltệp. -
Dòng 12 tạo một
appbiến , là phiên bản Flask được khởi tạo bởi Connexion. -
Dòng 15 sử dụng ứng dụng
appbiến để cấu hình các giá trị được SQLAlchemy sử dụng. Đầu tiên nó đặtSQLALCHEMY_ECHOthànhTrue. Điều này khiến SQLAlchemy lặp lại các câu lệnh SQL mà nó thực thi tới bảng điều khiển. Điều này rất hữu ích để gỡ lỗi các vấn đề khi xây dựng các chương trình cơ sở dữ liệu. Đặt giá trị này thànhFalsecho môi trường sản xuất. -
Dòng 16 bộ
SQLALCHEMY_DATABASE_URItớisqlite:////' + os.path.join(basedir, 'people.db'). Điều này yêu cầu SQLAlchemy sử dụng SQLite làm cơ sở dữ liệu và một tệp có tênpeople.dbtrong thư mục hiện tại dưới dạng tệp cơ sở dữ liệu. Các công cụ cơ sở dữ liệu khác nhau, như MySQL và PostgreSQL, sẽ cóSQLALCHEMY_DATABASE_URIkhác nhau các chuỗi để định cấu hình chúng. -
Dòng 17 bộ
SQLALCHEMY_TRACK_MODIFICATIONSthànhFalse, tắt hệ thống sự kiện SQLAlchemy được bật theo mặc định. Hệ thống sự kiện tạo ra các sự kiện hữu ích trong các chương trình hướng sự kiện nhưng bổ sung thêm chi phí đáng kể. Vì bạn không tạo chương trình hướng sự kiện, hãy tắt tính năng này. -
Dòng 19 tạo
dbbiến bằng cách gọiSQLAlchemy(app). Thao tác này khởi tạo SQLAlchemy bằng cách chuyển ứng dụngappthông tin cấu hình vừa thiết lập.dbbiến là những gì được nhập vàobuild_database.pychương trình để cấp cho nó quyền truy cập vào SQLAlchemy và cơ sở dữ liệu. Nó sẽ phục vụ cùng một mục đích trongserver.pychương trình vàpeople.pymô-đun. -
Dòng 23 tạo
mabiến bằng cách gọiMarshmallow(app). Điều này khởi tạo Marshmallow và cho phép nó xem xét các thành phần SQLAlchemy được đính kèm với ứng dụng. Đây là lý do tại sao Marshmallow được khởi tạo sau SQLAlchemy.
Mô-đun Mô hình
models.py mô-đun được tạo để cung cấp cho Person và PersonSchema các lớp chính xác như được mô tả trong các phần trên về mô hình hóa và tuần tự hóa dữ liệu. Đây là mã cho mô-đun đó:
1from datetime import datetime
2from config import db, ma
3
4class Person(db.Model):
5 __tablename__ = 'person'
6 person_id = db.Column(db.Integer, primary_key=True)
7 lname = db.Column(db.String(32), index=True)
8 fname = db.Column(db.String(32))
9 timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
10
11class PersonSchema(ma.ModelSchema):
12 class Meta:
13 model = Person
14 sqla_session = db.session
Đây là những gì đoạn mã trên đang thực hiện:
-
Dòng 1 nhập
datetimeđối tượng từdatetimemô-đun đi kèm với Python. Điều này cung cấp cho bạn một cách để tạo dấu thời gian trongPersonlớp học. -
Dòng 2 nhập
dbvàmacác biến phiên bản được xác định trongconfig.pymô-đun. Điều này cung cấp cho mô-đun quyền truy cập vào các thuộc tính và phương thức SQLAlchemy được đính kèm vớidbbiến và các thuộc tính và phương thức Marshmallow được đính kèm vớimabiến. -
Dòng 4 - 9 xác định
Personnhư đã thảo luận trong phần mô hình dữ liệu ở trên, nhưng bây giờ bạn biếtdb.Modelở đâu mà lớp kế thừa từ ban đầu. Điều này mang lại choPersoncác tính năng của lớp SQLAlchemy, như kết nối với cơ sở dữ liệu và truy cập vào các bảng của nó. -
Dòng 11 - 14 xác định
PersonSchemanhư đã được thảo luận trong phần tuần tự hóa dữ liệu ở trên. Lớp này kế thừa từma.ModelSchemaand gives thePersonSchemaclass Marshmallow features, like introspecting thePersonclass to help serialize/deserialize instances of that class.
Creating the Database
You’ve seen how database tables can be mapped to SQLAlchemy classes. Now use what you’ve learned to create the database and populate it with data. You’re going to build a small utility program to create and build the database with the People data. Here’s the build_database.py program:
1import os
2from config import db
3from models import Person
4
5# Data to initialize database with
6PEOPLE = [
7 {'fname': 'Doug', 'lname': 'Farrell'},
8 {'fname': 'Kent', 'lname': 'Brockman'},
9 {'fname': 'Bunny','lname': 'Easter'}
10]
11
12# Delete database file if it exists currently
13if os.path.exists('people.db'):
14 os.remove('people.db')
15
16# Create the database
17db.create_all()
18
19# Iterate over the PEOPLE structure and populate the database
20for person in PEOPLE:
21 p = Person(lname=person['lname'], fname=person['fname'])
22 db.session.add(p)
23
24db.session.commit()
Here’s what the above code is doing:
-
Line 2 imports the
dbinstance from theconfig.pymodule. -
Line 3 imports the
Personclass definition from themodels.pymodule. -
Lines 6 – 10 create the
PEOPLEdata structure, which is a list of dictionaries containing your data. The structure has been condensed to save presentation space. -
Lines 13 &14 perform some simple housekeeping to delete the
people.dbfile, if it exists. This file is where the SQLite database is maintained. If you ever have to re-initialize the database to get a clean start, this makes sure you’re starting from scratch when you build the database. -
Line 17 creates the database with the
db.create_all()call. This creates the database by using thedbinstance imported from theconfigmodule. Thedbinstance is our connection to the database. -
Lines 20 – 22 iterate over the
PEOPLElist and use the dictionaries within to instantiate aPersonlớp. After it is instantiated, you call thedb.session.add(p)function. This uses the database connection instancedbto access thesessionvật. The session is what manages the database actions, which are recorded in the session. In this case, you are executing theadd(p)method to add the newPersoninstance to thesessionobject. -
Line 24 calls
db.session.commit()to actually save all the person objects created to the database.
Lưu ý: At Line 22, no data has been added to the database. Everything is being saved within the session vật. Only when you execute the db.session.commit() call at Line 24 does the session interact with the database and commit the actions to it.
In SQLAlchemy, the session is an important object. It acts as the conduit between the database and the SQLAlchemy Python objects created in a program. The session helps maintain the consistency between data in the program and the same data as it exists in the database. It saves all database actions and will update the underlying database accordingly by both explicit and implicit actions taken by the program.
Now you’re ready to run the build_database.py program to create and initialize the new database. You do so with the following command, with your Python virtual environment active:
python build_database.py
When the program runs, it will print SQLAlchemy log messages to the console. These are the result of setting SQLALCHEMY_ECHO to True in the config.py tập tin. Much of what’s being logged by SQLAlchemy is the SQL commands it’s generating to create and build the people.db SQLite database file. Here’s an example of what’s printed out when the program is run:
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine SELECT CAST('test plain returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine SELECT CAST('test unicode returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine PRAGMA table_info("person")
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine
CREATE TABLE person (
person_id INTEGER NOT NULL,
lname VARCHAR,
fname VARCHAR,
timestamp DATETIME,
PRIMARY KEY (person_id)
)
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,975 INFO sqlalchemy.engine.base.Engine COMMIT
2018-09-11 22:20:29,980 INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine ('Farrell', 'Doug', '2018-09-12 02:20:29.983143')
2018-09-11 22:20:29,984 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Brockman', 'Kent', '2018-09-12 02:20:29.984821')
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Easter', 'Bunny', '2018-09-12 02:20:29.985462')
2018-09-11 22:20:29,986 INFO sqlalchemy.engine.base.Engine COMMIT
Using the Database
Once the database has been created, you can modify the existing code from Part 1 to make use of it. All of the modifications necessary are due to creating the person_id primary key value in our database as the unique identifier rather than the lname value.
Update the REST API
None of the changes are very dramatic, and you’ll start by re-defining the REST API. The list below shows the API definition from Part 1 but is updated to use the person_id variable in the URL path:
| Action | HTTP Verb | URL Path | Mô tả |
|---|---|---|---|
| Create | POST | /api/people | Defines a unique URL to create a new person |
| Read | GET | /api/people | Defines a unique URL to read a collection of people |
| Read | GET | /api/people/{person_id} | Defines a unique URL to read a particular person by person_id |
| Update | PUT | /api/people/{person_id} | Defines a unique URL to update an existing person by person_id |
| Delete | DELETE | /api/orders/{person_id} | Defines a unique URL to delete an existing person by person_id |
Where the URL definitions required an lname value, they now require the person_id (primary key) for the person record in the people bàn. This allows you to remove the code in the previous app that artificially restricted users from editing a person’s last name.
In order for you to implement these changes, the swagger.yml file from Part 1 will have to be edited. For the most part, any lname parameter value will be changed to person_id , and person_id will be added to the POST and PUT responses. You can check out the updated swagger.yml file.
Update the REST API Handlers
With the swagger.yml file updated to support the use of the person_id identifier, you’ll also need to update the handlers in the people.py file to support these changes. In the same way that the swagger.yml file was updated, you need to change the people.py file to use the person_id value rather than lname .
Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people :
1from flask import (
2 make_response,
3 abort,
4)
5from config import db
6from models import (
7 Person,
8 PersonSchema,
9)
10
11def read_all():
12 """
13 This function responds to a request for /api/people
14 with the complete lists of people
15
16 :return: json string of list of people
17 """
18 # Create the list of people from our data
19 people = Person.query \
20 .order_by(Person.lname) \
21 .all()
22
23 # Serialize the data for the response
24 person_schema = PersonSchema(many=True)
25 return person_schema.dump(people).data
Here’s what the above code is doing:
-
Lines 1 – 9 import some Flask modules to create the REST API responses, as well as importing the
dbinstance from theconfig.pymodule. In addition, it imports the SQLAlchemyPersonand MarshmallowPersonSchemaclasses to access thepersondatabase table and serialize the results. -
Line 11 starts the definition of
read_all()that responds to the REST API URL endpointGET /api/peopleand returns all the records in thepersondatabase table sorted in ascending order by last name. -
Lines 19 – 22 tell SQLAlchemy to query the
persondatabase table for all the records, sort them in ascending order (the default sorting order), and return a list ofPersonPython objects as the variablepeople. -
Line 24 is where the Marshmallow
PersonSchemaclass definition becomes valuable. You create an instance of thePersonSchema, passing it the parametermany=True. This tellsPersonSchemato expect an interable to serialize, which is what thepeoplevariable is. -
Line 25 uses the
PersonSchemainstance variable (person_schema), calling itsdump()method with thepeoplelist. The result is an object having adataattribute, an object containing apeoplelist that can be converted to JSON. This is returned and converted by Connexion to JSON as the response to the REST API call.
Lưu ý: The people list variable created on Line 24 above can’t be returned directly because Connexion won’t know how to convert the timestamp field into JSON. Returning the list of people without processing it with Marshmallow results in a long error traceback and finally this Exception:
TypeError: Object of type Person is not JSON serializable
Here’s another part of the person.py module that makes a request for a single person from the person database. Here, read_one(person_id) function receives a person_id from the REST URL path, indicating the user is looking for a specific person. Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people/{person_id} :
1def read_one(person_id):
2 """
3 This function responds to a request for /api/people/{person_id}
4 with one matching person from people
5
6 :param person_id: ID of person to find
7 :return: person matching ID
8 """
9 # Get the person requested
10 person = Person.query \
11 .filter(Person.person_id == person_id) \
12 .one_or_none()
13
14 # Did we find a person?
15 if person is not None:
16
17 # Serialize the data for the response
18 person_schema = PersonSchema()
19 return person_schema.dump(person).data
20
21 # Otherwise, nope, didn't find that person
22 else:
23 abort(404, 'Person not found for Id: {person_id}'.format(person_id=person_id))
Here’s what the above code is doing:
-
Lines 10 – 12 use the
person_idparameter in a SQLAlchemy query using thefiltermethod of the query object to search for a person with aperson_idattribute matching the passed-inperson_id. Rather than using theall()query method, use theone_or_none()method to get one person, or returnNoneif no match is found. -
Line 15 determines whether a
personwas found or not. -
Line 17 shows that, if
personwas notNone(a matchingpersonwas found), then serializing the data is a little different. You don’t pass themany=Trueparameter to the creation of thePersonSchema()ví dụ. Instead, you passmany=Falsebecause only a single object is passed in to serialize. -
Line 18 is where the
dumpmethod ofperson_schemais called, and thedataattribute of the resulting object is returned. -
Line 23 shows that, if
personwasNone(a matching person wasn’t found), then the Flaskabort()method is called to return an error.
Another modification to person.py is creating a new person in the database. This gives you an opportunity to use the Marshmallow PersonSchema to deserialize a JSON structure sent with the HTTP request to create a SQLAlchemy Person vật. Here’s part of the updated person.py module showing the handler for the REST URL endpoint POST /api/people :
1def create(person):
2 """
3 This function creates a new person in the people structure
4 based on the passed-in person data
5
6 :param person: person to create in people structure
7 :return: 201 on success, 406 on person exists
8 """
9 fname = person.get('fname')
10 lname = person.get('lname')
11
12 existing_person = Person.query \
13 .filter(Person.fname == fname) \
14 .filter(Person.lname == lname) \
15 .one_or_none()
16
17 # Can we insert this person?
18 if existing_person is None:
19
20 # Create a person instance using the schema and the passed-in person
21 schema = PersonSchema()
22 new_person = schema.load(person, session=db.session).data
23
24 # Add the person to the database
25 db.session.add(new_person)
26 db.session.commit()
27
28 # Serialize and return the newly created person in the response
29 return schema.dump(new_person).data, 201
30
31 # Otherwise, nope, person exists already
32 else:
33 abort(409, f'Person {fname} {lname} exists already')
Here’s what the above code is doing:
-
Line 9 &10 set the
fnameandlnamevariables based on thePersondata structure sent as thePOSTbody of the HTTP request. -
Lines 12 – 15 use the SQLAlchemy
Personclass to query the database for the existence of a person with the samefnameandlnameas the passed-inperson. -
Line 18 addresses whether
existing_personlàNone. (existing_personwas not found.) -
Line 21 creates a
PersonSchema()instance calledschema. -
Line 22 uses the
schemavariable to load the data contained in thepersonparameter variable and create a new SQLAlchemyPersoninstance variable callednew_person. -
Line 25 adds the
new_personinstance to thedb.session. -
Line 26 commits the
new_personinstance to the database, which also assigns it a new primary key value (based on the auto-incrementing integer) and a UTC-based timestamp. -
Line 33 shows that, if
existing_personis notNone(a matching person was found), then the Flaskabort()method is called to return an error.
Update the Swagger UI
With the above changes in place, your REST API is now functional. The changes you’ve made are also reflected in an updated swagger UI interface and can be interacted with in the same manner. Below is a screenshot of the updated swagger UI opened to the GET /people/{person_id} section. This section of the UI gets a single person from the database and looks like this:
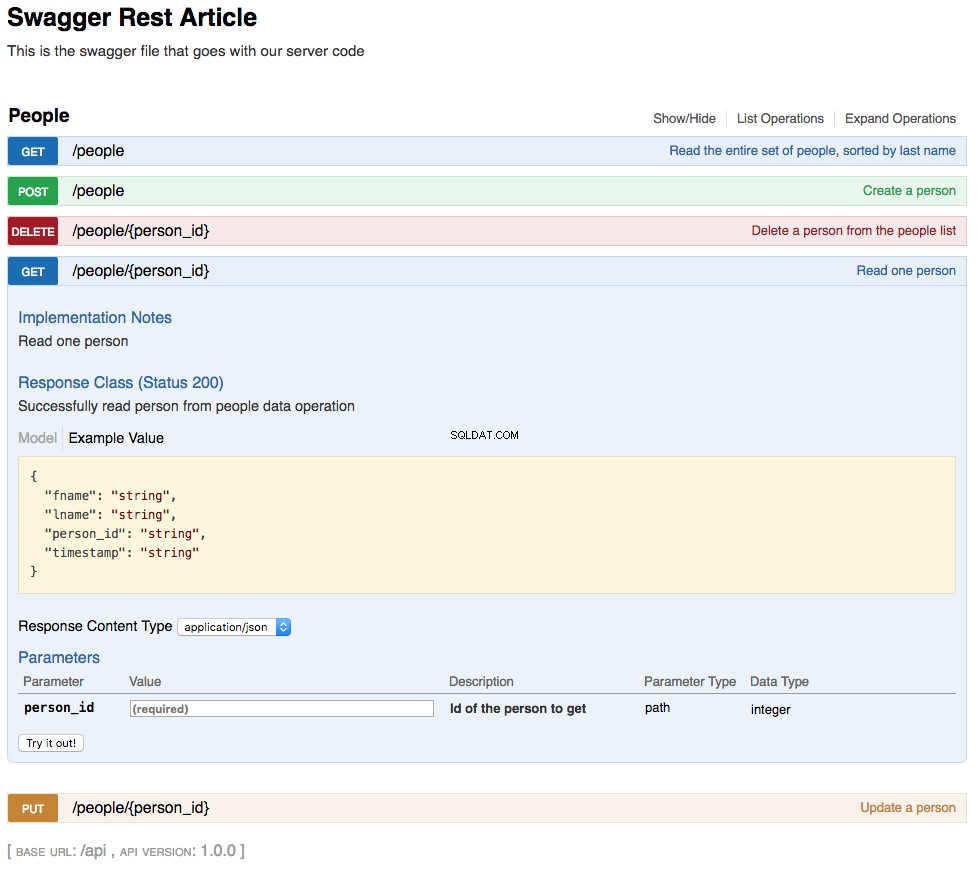
As shown in the above screenshot, the path parameter lname has been replaced by person_id , which is the primary key for a person in the REST API. The changes to the UI are a combined result of changing the swagger.yml file and the code changes made to support that.
Update the Web Application
The REST API is running, and CRUD operations are being persisted to the database. So that it is possible to view the demonstration web application, the JavaScript code has to be updated.
The updates are again related to using person_id instead of lname as the primary key for person data. In addition, the person_id is attached to the rows of the display table as HTML data attributes named data-person-id , so the value can be retrieved and used by the JavaScript code.
This article focused on the database and making your REST API use it, which is why there’s just a link to the updated JavaScript source and not much discussion of what it does.
Example Code
All of the example code for this article is available here. There’s one version of the code containing all the files, including the build_database.py utility program and the server.py modified example program from Part 1.
Kết luận
Congratulations, you’ve covered a lot of new material in this article and added useful tools to your arsenal!
You’ve learned how to save Python objects to a database using SQLAlchemy. You’ve also learned how to use Marshmallow to serialize and deserialize SQLAlchemy objects and use them with a JSON REST API. The things you’ve learned have certainly been a step up in complexity from the simple REST API of Part 1, but that step has given you two very powerful tools to use when creating more complex applications.
SQLAlchemy and Marshmallow are amazing tools in their own right. Using them together gives you a great leg up to create your own web applications backed by a database.
In Part 3 of this series, you’ll focus on the R part of RDBMS :relationships, which provide even more power when you are using a database.