Trong Phần 1 và Phần 2 của loạt bài này, tôi đã trình bày các khía cạnh logic hoặc khái niệm của các biểu thức bảng được đặt tên nói chung và các bảng dẫn xuất cụ thể. Tháng này và tháng tới, tôi sẽ đề cập đến các khía cạnh xử lý vật lý của các bảng dẫn xuất. Nhớ lại từ Phần 1 về độc lập dữ liệu vật lý nguyên lý của lý thuyết quan hệ. Mô hình quan hệ và ngôn ngữ truy vấn chuẩn dựa trên nó được cho là chỉ xử lý các khía cạnh khái niệm của dữ liệu và để lại các chi tiết thực hiện vật lý như lưu trữ, tối ưu hóa, truy cập và xử lý dữ liệu cho nền tảng cơ sở dữ liệu ( triển khai ). Không giống như việc xử lý khái niệm dữ liệu dựa trên mô hình toán học và ngôn ngữ chuẩn, và do đó rất giống trong các hệ thống quản lý cơ sở dữ liệu quan hệ khác nhau ngoài đó, việc xử lý dữ liệu vật lý không dựa trên bất kỳ tiêu chuẩn nào và do đó có xu hướng rất cụ thể cho nền tảng. Trong phần trình bày của tôi về cách xử lý vật lý đối với các biểu thức bảng được đặt tên trong loạt bài này, tôi tập trung vào cách xử lý trong Microsoft SQL Server và Azure SQL Database. Việc xử lý vật lý trong các nền tảng cơ sở dữ liệu khác có thể hoàn toàn khác.
Hãy nhớ lại rằng điều gây ra loạt bài này là một số nhầm lẫn tồn tại trong cộng đồng SQL Server xung quanh các biểu thức bảng được đặt tên. Cả về thuật ngữ và về tối ưu hóa. Tôi đã giải quyết một số cân nhắc về thuật ngữ trong hai phần đầu tiên của loạt bài này và sẽ đề cập nhiều hơn trong các bài viết trong tương lai khi thảo luận về CTE, quan điểm và TVF nội tuyến. Đối với việc tối ưu hóa các biểu thức bảng đã đặt tên, có sự nhầm lẫn xung quanh các mục sau (tôi đề cập đến các bảng dẫn xuất ở đây vì đó là trọng tâm của bài viết này):
- Tính ổn định: Một bảng dẫn xuất vẫn tồn tại ở bất kỳ đâu? Nó có tiếp tục tồn tại trên đĩa không và SQL Server xử lý bộ nhớ cho nó như thế nào?
- Phép chiếu cột: Đối sánh chỉ mục hoạt động như thế nào với các bảng dẫn xuất? Ví dụ:nếu một bảng dẫn xuất chiếu một tập hợp con nhất định của các cột từ một số bảng bên dưới và truy vấn ngoài cùng chiếu một tập con các cột từ bảng dẫn xuất, thì SQL Server có đủ thông minh để tìm ra cách lập chỉ mục tối ưu dựa trên tập hợp con cuối cùng của các cột không điều đó thực sự cần thiết? Và những gì về quyền; người dùng cần quyền đối với tất cả các cột được tham chiếu trong các truy vấn bên trong hay chỉ những cột cuối cùng thực sự cần thiết?
- Nhiều tham chiếu đến bí danh cột: Nếu bảng dẫn xuất có cột kết quả dựa trên tính toán không xác định, ví dụ:lệnh gọi hàm SYSDATETIME và truy vấn bên ngoài có nhiều tham chiếu đến cột đó, thì việc tính toán sẽ chỉ được thực hiện một lần hay riêng biệt cho từng tham chiếu bên ngoài ?
- Bỏ ghi chú / thay thế / nội dòng: SQL Server có bỏ sót, hoặc nội dòng, truy vấn bảng dẫn xuất không? Tức là, SQL Server có thực hiện quá trình thay thế theo đó nó chuyển đổi mã lồng nhau ban đầu thành một truy vấn trực tiếp chống lại các bảng cơ sở không? Và nếu vậy, có cách nào để hướng dẫn SQL Server tránh quá trình không cần thiết này không?
Đây là tất cả các câu hỏi quan trọng và câu trả lời cho những câu hỏi này có ý nghĩa đáng kể về hiệu suất, vì vậy bạn nên hiểu rõ về cách các mục này được xử lý trong SQL Server. Tháng này, tôi sẽ giải quyết ba mục đầu tiên. Có khá nhiều điều để nói về mục thứ tư nên tôi sẽ dành một bài viết riêng cho nó vào tháng tới (Phần 4).
Trong các ví dụ của mình, tôi sẽ sử dụng cơ sở dữ liệu mẫu có tên là TSQLV5. Bạn có thể tìm thấy tập lệnh tạo và điền TSQLV5 tại đây và sơ đồ ER của nó tại đây.
Tính bền bỉ
Một số người trực quan cho rằng SQL Server duy trì kết quả của phần biểu thức bảng của bảng dẫn xuất (kết quả của truy vấn bên trong) trong một bảng làm việc. Vào ngày viết bài này, đó không phải là trường hợp; tuy nhiên, vì cân nhắc về độ bền là lựa chọn của nhà cung cấp, Microsoft có thể quyết định thay đổi điều này trong tương lai. Thật vậy, SQL Server có thể duy trì kết quả truy vấn trung gian trong bảng làm việc (thường là trong tempdb) như một phần của quá trình xử lý truy vấn. Nếu nó chọn làm như vậy, bạn sẽ thấy một số dạng toán tử cuộn trong kế hoạch (Spool, Eager Spool, Lazy Spool, Table Spool, Index Spool, Window Spool, Row Count Spool). Tuy nhiên, lựa chọn của SQL Server về việc có đưa thứ gì đó vào bảng làm việc hay không hiện không liên quan gì đến việc bạn sử dụng các biểu thức bảng được đặt tên trong truy vấn. SQL Server đôi khi làm hỏng kết quả trung gian vì lý do hiệu suất, chẳng hạn như tránh làm việc lặp lại (mặc dù hiện tại không liên quan đến việc sử dụng các biểu thức bảng đã đặt tên) và đôi khi vì các lý do khác, chẳng hạn như bảo vệ Halloween.
Như đã đề cập, vào tháng tới, tôi sẽ đi đến chi tiết về việc hủy ghi chú các bảng dẫn xuất. Hiện tại, đủ để nói rằng SQL Server thường áp dụng một quy trình bỏ ghi chú / nội dòng cho các bảng dẫn xuất, nơi nó thay thế các truy vấn lồng nhau bằng một truy vấn chống lại các bảng cơ sở bên dưới. Chà, tôi đang đơn giản hóa một chút. Nó không giống như SQL Server theo nghĩa đen chuyển đổi chuỗi truy vấn T-SQL ban đầu với các bảng dẫn xuất thành một chuỗi truy vấn mới mà không có các bảng đó; thay vào đó, SQL Server áp dụng các phép biến đổi cho một cây lôgic nội bộ của các toán tử và kết quả là các bảng dẫn xuất thường không được yêu cầu một cách hiệu quả. Khi bạn xem xét kế hoạch thực thi cho một truy vấn liên quan đến các bảng dẫn xuất, bạn sẽ không thấy bất kỳ đề cập nào về các bảng đó vì đối với hầu hết các mục đích tối ưu hóa, chúng không tồn tại. Bạn thấy quyền truy cập vào các cấu trúc vật lý giữ dữ liệu cho các bảng cơ sở bên dưới (heap, B-tree rowstore index và columnstore index cho các bảng dựa trên đĩa và chỉ mục cây và băm cho các bảng được tối ưu hóa bộ nhớ).
Có những trường hợp ngăn không cho SQL Server bỏ ghi chú một bảng dẫn xuất, nhưng ngay cả trong những trường hợp đó, SQL Server không duy trì kết quả của biểu thức bảng trong một bảng làm việc. Tôi sẽ cung cấp các chi tiết cùng với các ví dụ vào tháng tới.
Vì SQL Server không duy trì các bảng dẫn xuất, thay vì tương tác trực tiếp với các cấu trúc vật lý giữ dữ liệu cho các bảng cơ sở bên dưới, câu hỏi liên quan đến cách xử lý bộ nhớ cho các bảng dẫn xuất là rất nhiều. Nếu các bảng cơ sở bên dưới là các bảng dựa trên đĩa, các trang liên quan của chúng cần được xử lý trong vùng đệm. Nếu các bảng bên dưới là các bảng được tối ưu hóa bộ nhớ, thì các hàng trong bộ nhớ có liên quan của chúng cần được xử lý. Nhưng điều đó không khác gì khi bạn tự mình truy vấn trực tiếp các bảng bên dưới mà không sử dụng các bảng dẫn xuất. Vì vậy, không có gì đặc biệt ở đây. Khi bạn sử dụng các bảng dẫn xuất, SQL Server không cần áp dụng bất kỳ cân nhắc bộ nhớ đặc biệt nào cho các bảng đó. Đối với hầu hết các mục đích tối ưu hóa truy vấn, chúng không tồn tại.
Nếu bạn gặp trường hợp cần duy trì kết quả của bước trung gian nào đó trong bảng làm việc, bạn cần sử dụng bảng tạm thời hoặc biến bảng — không phải biểu thức bảng được đặt tên.
Phép chiếu cột và một từ trên SELECT *
Phép chiếu là một trong những toán tử ban đầu của đại số quan hệ. Giả sử bạn có một quan hệ R1 với các thuộc tính x, y và z. Phép chiếu của R1 trên một số tập con các thuộc tính của nó, ví dụ:x và z, là một quan hệ mới R2, có tiêu đề là tập con của các thuộc tính được chiếu từ R1 (x và z trong trường hợp của chúng tôi) và có phần thân là tập các bộ giá trị được hình thành từ sự kết hợp ban đầu của các giá trị thuộc tính dự kiến từ các bộ giá trị của R1.
Nhớ lại rằng phần thân của một mối quan hệ — là một tập hợp các bộ giá trị — theo định nghĩa không có bản sao. Vì vậy, không cần phải nói rằng bộ giá trị của quan hệ kết quả là sự kết hợp riêng biệt của các giá trị thuộc tính được chiếu từ quan hệ ban đầu. Tuy nhiên, hãy nhớ rằng phần thân của bảng trong SQL là một tập hợp nhiều hàng chứ không phải một tập hợp, và thông thường, SQL sẽ không loại bỏ các hàng trùng lặp trừ khi bạn hướng dẫn nó. Cho một bảng R1 với các cột x, y và z, truy vấn sau có khả năng trả về các hàng trùng lặp và do đó không tuân theo ngữ nghĩa của toán tử chiếu của đại số quan hệ khi trả về một tập hợp:
SELECT x, z FROM R1;
Bằng cách thêm mệnh đề DISTINCT, bạn loại bỏ các hàng trùng lặp và tuân thủ chặt chẽ hơn ngữ nghĩa của phép chiếu quan hệ:
SELECT DISTINCT x, z FROM R1;
Tất nhiên, có một số trường hợp bạn biết rằng kết quả truy vấn của bạn có các hàng riêng biệt mà không cần mệnh đề DISTINCT, ví dụ:khi một tập hợp con của các cột mà bạn đang trả về bao gồm một khóa từ bảng đã truy vấn. Ví dụ:nếu x là một khóa trong R1, thì hai truy vấn trên là tương đương về mặt logic.
Dù sao đi nữa, hãy nhớ lại những câu hỏi tôi đã đề cập trước đó xung quanh việc tối ưu hóa các truy vấn liên quan đến các bảng dẫn xuất và phép chiếu cột. Đối sánh chỉ mục hoạt động như thế nào? Nếu một bảng dẫn xuất chiếu một tập hợp con nhất định của các cột từ một số bảng bên dưới và truy vấn ngoài cùng chiếu tập hợp con các cột từ bảng dẫn xuất, thì SQL Server có đủ thông minh để tìm ra cách lập chỉ mục tối ưu dựa trên tập hợp con cuối cùng của các cột thực sự không cần thiết? Và những gì về quyền; người dùng cần quyền đối với tất cả các cột được tham chiếu trong các truy vấn bên trong hay chỉ những cột cuối cùng thực sự cần thiết? Ngoài ra, giả sử rằng truy vấn biểu thức bảng xác định cột kết quả dựa trên tính toán, nhưng truy vấn bên ngoài không chiếu cột đó. Tính toán có được đánh giá không?
Bắt đầu với câu hỏi cuối cùng, hãy thử nó. Hãy xem xét truy vấn sau:
USE TSQLV5; GO SELECT custid, city, 1/0 AS div0error FROM Sales.Customers;
Như bạn mong đợi, truy vấn này không thành công với lỗi chia cho 0:
Msg 8134, Mức 16, Trạng thái 1Đã gặp lỗi chia cho 0.
Tiếp theo, xác định một bảng dẫn xuất được gọi là D dựa trên truy vấn trên và trong dự án truy vấn bên ngoài D chỉ trên custid và thành phố, như sau:
SELECT custid, city
FROM ( SELECT custid, city, 1/0 AS div0error
FROM Sales.Customers ) AS D; Như đã đề cập, SQL Server thường áp dụng tính năng hủy đăng ký / thay thế và vì không có gì trong truy vấn này ngăn chặn việc hủy đăng ký (thêm vào tháng sau), truy vấn trên tương đương với truy vấn sau:
SELECT custid, city FROM Sales.Customers;
Một lần nữa, tôi đang đơn giản hóa một chút ở đây. Thực tế phức tạp hơn một chút so với việc hai truy vấn được coi là thực sự giống hệt nhau này, nhưng tôi sẽ giải quyết những sự phức tạp đó vào tháng tới. Vấn đề là, biểu thức 1/0 thậm chí không hiển thị trong kế hoạch thực thi của truy vấn và hoàn toàn không được đánh giá, vì vậy truy vấn ở trên chạy thành công mà không có lỗi.
Tuy nhiên, biểu thức bảng cần phải hợp lệ. Ví dụ:hãy xem xét truy vấn sau:
SELECT country
FROM ( SELECT *
FROM Sales.Customers
GROUP BY country ) AS D; Mặc dù truy vấn bên ngoài chỉ chiếu một cột từ tập hợp nhóm của truy vấn bên trong, nhưng truy vấn bên trong không hợp lệ vì nó cố gắng trả về các cột không phải là một phần của tập hợp nhóm cũng như không chứa trong một hàm tổng hợp. Truy vấn này không thành công với lỗi sau:
Msg 8120, Cấp 16, Trạng thái 1Cột 'Sales.Customers.custid' không hợp lệ trong danh sách lựa chọn vì nó không có trong hàm tổng hợp hoặc mệnh đề GROUP BY.
Tiếp theo, hãy giải quyết câu hỏi đối sánh chỉ mục. Nếu truy vấn bên ngoài chỉ chiếu một tập hợp con của các cột từ bảng dẫn xuất, thì SQL Server có đủ thông minh để thực hiện đối sánh chỉ mục chỉ dựa trên các cột được trả về không (và tất nhiên là bất kỳ cột nào khác đóng vai trò có ý nghĩa khác, chẳng hạn như lọc, nhóm và như vậy)? Nhưng trước khi chúng tôi giải quyết câu hỏi này, bạn có thể tự hỏi tại sao chúng tôi thậm chí còn bận tâm đến nó. Tại sao bạn lại có các cột trả về truy vấn bên trong mà truy vấn bên ngoài không cần?
Câu trả lời rất đơn giản, để rút ngắn mã bằng cách yêu cầu truy vấn bên trong sử dụng SELECT * nổi tiếng. Tất cả chúng ta đều biết rằng sử dụng SELECT * là một phương pháp không tốt, nhưng đó là trường hợp chủ yếu khi nó được sử dụng trong truy vấn ngoài cùng. Điều gì sẽ xảy ra nếu bạn truy vấn một bảng với một tiêu đề nhất định và sau đó tiêu đề đó bị thay đổi? Ứng dụng có thể có lỗi. Ngay cả khi bạn không gặp lỗi, bạn vẫn có thể tạo ra lưu lượng mạng không cần thiết bằng cách trả về các cột mà ứng dụng không thực sự cần. Ngoài ra, bạn sử dụng lập chỉ mục kém tối ưu hơn trong trường hợp như vậy vì bạn giảm cơ hội khớp các chỉ mục bao gồm dựa trên các cột thực sự cần thiết.
Điều đó nói rằng, tôi thực sự cảm thấy khá thoải mái khi sử dụng SELECT * trong biểu thức bảng, biết rằng dù sao thì tôi cũng sẽ chỉ chiếu những cột thực sự cần thiết trong truy vấn ngoài cùng. Từ quan điểm logic, điều đó khá an toàn với một số cảnh báo nhỏ mà tôi sẽ trình bày ngay sau đây. Điều đó miễn là đối sánh chỉ mục được thực hiện một cách tối ưu trong trường hợp như vậy và tin tốt là vậy.
Để chứng minh điều này, giả sử rằng bạn cần truy vấn bảng Sales.Orders, trả về ba đơn đặt hàng gần đây nhất cho mỗi khách hàng. Bạn đang định xác định một bảng dẫn xuất có tên D dựa trên một truy vấn tính toán các số hàng (rownum cột kết quả) được phân vùng theo custid và sắp xếp theo orderdate DESC, orderid DESC. Truy vấn bên ngoài sẽ lọc khỏi D ( hạn chế quan hệ ) chỉ những hàng mà rownum nhỏ hơn hoặc bằng 3 và chiếu D lên custid, orderdate, orderid và rownum. Bây giờ, Sales.Orders có nhiều cột hơn những cột mà bạn cần chiếu, nhưng để ngắn gọn, bạn muốn truy vấn bên trong sử dụng SELECT *, cộng với tính toán số hàng. Điều đó an toàn và sẽ được xử lý tối ưu về mặt đối sánh chỉ mục.
Sử dụng mã sau để tạo chỉ mục bao trùm tối ưu để hỗ trợ truy vấn của bạn:
CREATE INDEX idx_custid_odD_oidD ON Sales.Orders(custid, orderdate DESC, orderid DESC);
Đây là truy vấn lưu trữ nhiệm vụ hiện có (chúng tôi sẽ gọi nó là Truy vấn 1):
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Lưu ý đến SELECT * của truy vấn bên trong và danh sách cột rõ ràng của truy vấn bên ngoài.
Kế hoạch cho truy vấn này, như được kết xuất bởi SentryOne Plan Explorer, được hiển thị trong Hình 1.
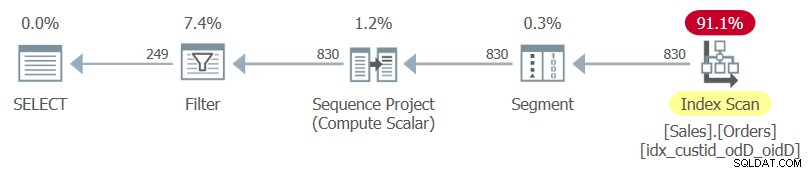 Hình 1:Kế hoạch cho Truy vấn 1
Hình 1:Kế hoạch cho Truy vấn 1
Quan sát rằng chỉ mục duy nhất được sử dụng trong kế hoạch này là chỉ mục bao quát tối ưu mà bạn vừa tạo.
Nếu bạn chỉ đánh dấu truy vấn bên trong và kiểm tra kế hoạch thực thi của nó, bạn sẽ thấy chỉ mục nhóm của bảng được sử dụng theo sau bởi một thao tác sắp xếp.
Vì vậy, đó là một tin tốt.
Đối với quyền, đó là một câu chuyện khác. Không giống như đối sánh chỉ mục, trong đó bạn không cần chỉ mục bao gồm các cột được tham chiếu bởi các truy vấn bên trong miễn là cuối cùng chúng không cần thiết, bạn bắt buộc phải có quyền đối với tất cả các cột được tham chiếu.
Để chứng minh điều này, hãy sử dụng mã sau để tạo người dùng có tên là user1 và chỉ định một số quyền (quyền CHỌN trên tất cả các cột từ Sales.Customers và chỉ trên ba cột từ Sales. Đơn hàng cuối cùng có liên quan trong truy vấn trên):
CREATE USER user1 WITHOUT LOGIN; GRANT SHOWPLAN TO user1; GRANT SELECT ON Sales.Customers TO user1; GRANT SELECT ON Sales.Orders(custid, orderdate, orderid) TO user1;
Chạy mã sau để mạo danh user1:
EXECUTE AS USER = 'user1';
Cố gắng chọn tất cả các cột từ Bán hàng. Đơn đặt hàng:
SELECT * FROM Sales.Orders;
Như mong đợi, bạn nhận được các lỗi sau do thiếu quyền trên một số cột:
Msg 230, Cấp 14, Trạng thái 1Quyền SELECT bị từ chối trên cột 'trống' của đối tượng 'Đơn hàng', cơ sở dữ liệu 'TSQLV5', giản đồ 'Bán hàng'.
Bản tin 230 , Cấp 14, Trạng thái 1
Quyền SELECT bị từ chối trên cột 'ngày yêu cầu' của đối tượng 'Đơn hàng', cơ sở dữ liệu 'TSQLV5', lược đồ 'Bán hàng'.
Bản tin thứ 230, Cấp độ 14, Trạng thái 1
Quyền SELECT bị từ chối trên cột 'ngày vận chuyển' của đối tượng 'Đơn hàng', cơ sở dữ liệu 'TSQLV5', lược đồ 'Bán hàng'.
Bản tin thứ 230, Mức 14, Trạng thái 1
Quyền SELECT bị từ chối trên cột 'shipperid' của đối tượng 'Đơn hàng', cơ sở dữ liệu 'TSQLV5', lược đồ 'Bán hàng'.
Bản tin thứ 230, Mức 14, Trạng thái 1
Quyền SELECT bị từ chối trên cột 'cước phí' của đối tượng 'Đơn đặt hàng', cơ sở dữ liệu 'TSQLV5', lược đồ 'Bán hàng'.
Msg 230, Level 14, State 1
Quyền SELECT đã bị từ chối trên cột 'tên tàu' của đối tượng 'Đơn đặt hàng', cơ sở dữ liệu 'TSQLV5', lược đồ 'Bán hàng'.
Msg 230, Cấp 14, Trạng thái 1
Quyền SELECT đã bị từ chối trên cột 'địa chỉ giao hàng' của đối tượng 'Đơn đặt hàng', cơ sở dữ liệu 'TSQLV5', lược đồ 'Bán hàng'.
Msg 230, Cấp 14, Trạng thái 1
Quyền SELECT đã bị từ chối trên cột 'shipcity' của đối tượng 'Order', cơ sở dữ liệu 'TSQLV5', giản đồ 'Sales'.
Msg 230, Level 14, State 1
The SELECT quyền đã bị từ chối trên cột 'khu vực vận chuyển' của đối tượng 'Đơn hàng', cơ sở dữ liệu 'TSQLV5', lược đồ 'Bán hàng'.
Msg 230, Mức 14, Trạng thái 1
Quyền SELECT là bị từ chối trên cột 'shippostalcode' của đối tượng 'Đơn đặt hàng', cơ sở dữ liệu 'TSQLV5', lược đồ 'Bán hàng'.
Msg 230, Cấp 14, Trạng thái 1
Quyền SELECT bị từ chối trên cột 'quốc gia vận chuyển' của đối tượng 'Đơn hàng', cơ sở dữ liệu 'TSQLV5', giản đồ 'Bán hàng'.
Hãy thử truy vấn sau, chỉ chiếu và tương tác với các cột mà user1 có quyền:
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Tuy nhiên, bạn vẫn gặp lỗi quyền đối với cột do thiếu quyền đối với một số cột được tham chiếu bởi truy vấn bên trong thông qua SELECT *:
của nó Msg 230, Cấp 14, Trạng thái 1Quyền SELECT bị từ chối trên cột 'trống' của đối tượng 'Đơn hàng', cơ sở dữ liệu 'TSQLV5', giản đồ 'Bán hàng'.
Bản tin 230 , Cấp 14, Trạng thái 1
Quyền SELECT bị từ chối trên cột 'ngày yêu cầu' của đối tượng 'Đơn hàng', cơ sở dữ liệu 'TSQLV5', lược đồ 'Bán hàng'.
Bản tin thứ 230, Cấp độ 14, Trạng thái 1
Quyền SELECT bị từ chối trên cột 'ngày vận chuyển' của đối tượng 'Đơn hàng', cơ sở dữ liệu 'TSQLV5', lược đồ 'Bán hàng'.
Bản tin thứ 230, Mức 14, Trạng thái 1
Quyền SELECT bị từ chối trên cột 'shipperid' của đối tượng 'Đơn hàng', cơ sở dữ liệu 'TSQLV5', lược đồ 'Bán hàng'.
Bản tin thứ 230, Mức 14, Trạng thái 1
Quyền SELECT bị từ chối trên cột 'cước phí' của đối tượng 'Đơn đặt hàng', cơ sở dữ liệu 'TSQLV5', lược đồ 'Bán hàng'.
Msg 230, Level 14, State 1
Quyền SELECT đã bị từ chối trên cột 'tên tàu' của đối tượng 'Đơn đặt hàng', cơ sở dữ liệu 'TSQLV5', lược đồ 'Bán hàng'.
Msg 230, Cấp 14, Trạng thái 1
Quyền SELECT đã bị từ chối trên cột 'địa chỉ giao hàng' của đối tượng 'Đơn đặt hàng', cơ sở dữ liệu 'TSQLV5', lược đồ 'Bán hàng'.
Msg 230, Cấp 14, Trạng thái 1
Quyền SELECT đã bị từ chối trên cột 'shipcity' của đối tượng 'Order', cơ sở dữ liệu 'TSQLV5', giản đồ 'Sales'.
Msg 230, Level 14, State 1
The SELECT quyền đã bị từ chối trên cột 'khu vực vận chuyển' của đối tượng 'Đơn hàng', cơ sở dữ liệu 'TSQLV5', lược đồ 'Bán hàng'.
Msg 230, Mức 14, Trạng thái 1
Quyền SELECT là bị từ chối trên cột 'shippostalcode' của đối tượng 'Đơn đặt hàng', cơ sở dữ liệu 'TSQLV5', lược đồ 'Bán hàng'.
Msg 230, Cấp 14, Trạng thái 1
Quyền SELECT bị từ chối trên cột 'quốc gia vận chuyển' của đối tượng 'Đơn hàng', cơ sở dữ liệu 'TSQLV5', giản đồ 'Bán hàng'.
Nếu thực sự trong công ty của bạn, việc chỉ định quyền cho người dùng trên các cột có liên quan mà họ cần tương tác, sẽ rất hợp lý, bạn nên sử dụng mã dài hơn một chút và trình bày rõ ràng về danh sách cột trong cả truy vấn bên trong và bên ngoài, như vậy:
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT custid, orderdate, orderid,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Lần này, truy vấn chạy mà không có lỗi.
Một biến thể khác yêu cầu người dùng chỉ có quyền đối với các cột có liên quan là phải rõ ràng về tên cột trong danh sách SELECT của truy vấn bên trong và sử dụng SELECT * trong truy vấn bên ngoài, như sau:
SELECT *
FROM ( SELECT custid, orderdate, orderid,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Truy vấn này cũng chạy mà không có lỗi. Tuy nhiên, tôi thấy phiên bản này dễ gặp lỗi trong trường hợp sau này, một số thay đổi được thực hiện ở một số cấp độ lồng bên trong. Như đã đề cập trước đó, đối với tôi, phương pháp hay nhất là nói rõ ràng về danh sách cột trong truy vấn ngoài cùng. Vì vậy, miễn là bạn không có bất kỳ lo lắng nào về việc thiếu quyền đối với một số cột, tôi cảm thấy thoải mái với SELECT * trong các truy vấn bên trong, nhưng một danh sách cột rõ ràng trong truy vấn ngoài cùng. Nếu việc áp dụng các quyền đối với cột cụ thể là một thực tế phổ biến trong công ty, thì tốt nhất bạn nên trình bày rõ ràng về tên cột trong tất cả các cấp lồng ghép. Xin lưu ý bạn, việc trình bày rõ ràng về tên cột trong tất cả các cấp lồng ghép thực sự là bắt buộc nếu truy vấn của bạn được sử dụng trong đối tượng liên kết lược đồ, vì liên kết lược đồ không cho phép sử dụng SELECT * ở bất kỳ đâu trong truy vấn.
Tại thời điểm này, hãy chạy mã sau để xóa chỉ mục bạn đã tạo trước đó trên Bán hàng. Đơn đặt hàng:
DROP INDEX IF EXISTS idx_custid_odD_oidD ON Sales.Orders;
Có một trường hợp khác có tình huống khó xử tương tự liên quan đến tính hợp pháp của việc sử dụng SELECT *; trong truy vấn bên trong của vị từ EXISTS.
Hãy xem xét truy vấn sau (chúng tôi sẽ gọi nó là Truy vấn 2):
SELECT custid
FROM Sales.Customers AS C
WHERE EXISTS (SELECT * FROM Sales.Orders AS O
WHERE O.custid = C.custid); Kế hoạch cho truy vấn này được thể hiện trong Hình 2.
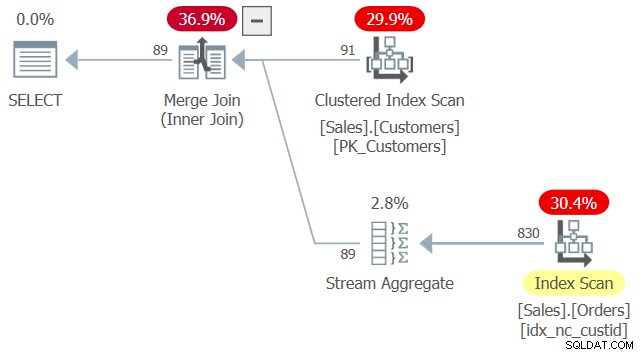 Hình 2:Kế hoạch cho Truy vấn 2
Hình 2:Kế hoạch cho Truy vấn 2
Khi áp dụng đối sánh chỉ mục, trình tối ưu hóa đã tìm ra rằng chỉ mục idx_nc_custid là chỉ mục bao trùm trên Sales.Orders vì nó chứa cột custid — cột duy nhất có liên quan trong truy vấn này. Đó là mặc dù thực tế là chỉ mục này không chứa bất kỳ cột nào khác ngoài custid và truy vấn bên trong trong vị từ EXISTS cho biết SELECT *. Cho đến nay, hành vi dường như tương tự như việc sử dụng SELECT * trong các bảng dẫn xuất.
Điều khác biệt với truy vấn này là nó chạy mà không có lỗi, mặc dù thực tế là user1 không có quyền đối với một số cột từ Sales.Orders. Có một lập luận để biện minh cho việc không yêu cầu quyền trên tất cả các cột ở đây. Rốt cuộc, vị từ EXISTS chỉ cần kiểm tra sự tồn tại của các hàng phù hợp, vì vậy danh sách SELECT của truy vấn bên trong thực sự vô nghĩa. Có lẽ sẽ là tốt nhất nếu SQL không yêu cầu danh sách CHỌN trong trường hợp như vậy, nhưng con tàu đó đã ra khơi. Tin tốt là danh sách CHỌN bị bỏ qua một cách hiệu quả — cả về đối sánh chỉ mục và về quyền bắt buộc.
Có vẻ như có một sự khác biệt khác giữa các bảng dẫn xuất và các bảng TỒN TẠI khi sử dụng SELECT * trong truy vấn bên trong. Hãy nhớ truy vấn này từ trước đó trong bài viết:
SELECT country
FROM ( SELECT *
FROM Sales.Customers
GROUP BY country ) AS D; Nếu bạn nhớ lại, mã này đã tạo ra lỗi vì truy vấn bên trong không hợp lệ.
Hãy thử cùng một truy vấn bên trong, chỉ lần này trong vị từ EXISTS (chúng tôi sẽ gọi đây là Câu lệnh 3):
IF EXISTS ( SELECT *
FROM Sales.Customers
GROUP BY country )
PRINT 'This works! Thanks Dmitri Korotkevitch for the tip!'; Thật kỳ lạ, SQL Server coi mã này là hợp lệ và nó chạy thành công. Kế hoạch cho mã này được thể hiện trong Hình 3.
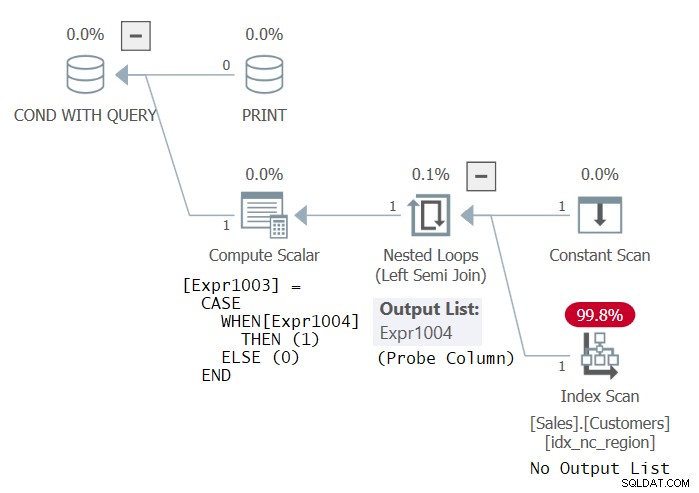 Hình 3:Kế hoạch cho Tuyên bố 3
Hình 3:Kế hoạch cho Tuyên bố 3
Kế hoạch này giống với kế hoạch bạn sẽ nhận được nếu truy vấn bên trong chỉ là CHỌN * TỪ Sales.Customers (không có GROUP BY). Sau cùng, bạn đang kiểm tra sự tồn tại của các nhóm và nếu có hàng, thì đương nhiên là có các nhóm. Dù sao, tôi nghĩ rằng việc SQL Server coi truy vấn này là hợp lệ là một lỗi. Chắc chắn, mã SQL phải hợp lệ! Nhưng tôi có thể hiểu tại sao một số người có thể tranh luận rằng danh sách SELECT trong truy vấn EXISTS được cho là bị bỏ qua. Ở bất kỳ mức độ nào, kế hoạch sử dụng phép nối bán bên trái đã được thăm dò, không cần trả về bất kỳ cột nào, thay vào đó chỉ cần thăm dò một bảng để kiểm tra sự tồn tại của bất kỳ hàng nào. Chỉ số về Khách hàng có thể là bất kỳ chỉ mục nào.
Tại thời điểm này, bạn có thể chạy mã sau để ngừng mạo danh user1 và loại bỏ nó:
REVERT; DROP USER IF EXISTS user1;
Quay trở lại thực tế là tôi thấy việc sử dụng SELECT * trong các cấp độ lồng bên trong là một phương pháp tiện lợi, bạn càng có nhiều cấp độ thì phương pháp này càng rút ngắn và đơn giản hóa mã của bạn. Dưới đây là một ví dụ với hai cấp độ lồng nhau:
SELECT orderid, orderyear, custid, empid, shipperid
FROM ( SELECT *, DATEFROMPARTS(orderyear, 12, 31) AS endofyear
FROM ( SELECT *, YEAR(orderdate) AS orderyear
FROM Sales.Orders ) AS D1 ) AS D2
WHERE orderdate = endofyear; Có những trường hợp không thể sử dụng cách làm này. Ví dụ:khi truy vấn bên trong kết hợp các bảng có tên cột chung, như trong ví dụ sau:
SELECT custid, companyname, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3; Cả Sales.Customers và Sales.Orders đều có một cột được gọi là custid. Bạn đang sử dụng biểu thức bảng dựa trên phép nối giữa hai bảng để xác định bảng dẫn xuất D. Hãy nhớ rằng tiêu đề của bảng là một tập hợp các cột và là một tập hợp, bạn không thể có các tên cột trùng lặp. Do đó, truy vấn này không thành công với lỗi sau:
Msg 8156, Mức 16, Trạng thái 1Cột 'custid' được chỉ định nhiều lần cho 'D'.
Ở đây, bạn cần phải rõ ràng về tên cột trong truy vấn bên trong và đảm bảo rằng bạn trả về custid chỉ từ một trong các bảng hoặc gán tên cột duy nhất cho các cột kết quả trong trường hợp bạn muốn trả về cả hai. Bạn sẽ thường xuyên sử dụng cách tiếp cận trước đây hơn, như sau:
SELECT custid, companyname, orderdate, orderid, rownum
FROM ( SELECT C.custid, C.companyname, O.orderdate, O.orderid,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3; Một lần nữa, bạn có thể rõ ràng với các tên cột trong truy vấn bên trong và sử dụng SELECT * trong truy vấn bên ngoài, như vậy:
SELECT *
FROM ( SELECT C.custid, C.companyname, O.orderdate, O.orderid,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3; Nhưng như tôi đã đề cập trước đó, tôi coi việc không trình bày rõ ràng về tên cột trong truy vấn ngoài cùng là một việc làm không tốt.
Nhiều tham chiếu đến bí danh cột
Hãy tiếp tục với mục tiếp theo — nhiều tham chiếu đến các cột trong bảng dẫn xuất. Nếu bảng dẫn xuất có cột kết quả dựa trên phép tính không xác định và truy vấn bên ngoài có nhiều tham chiếu đến cột đó, thì phép tính chỉ được đánh giá một lần hay riêng biệt cho mỗi tham chiếu?
Hãy bắt đầu với thực tế là nhiều tham chiếu đến cùng một hàm không xác định trong một truy vấn được cho là được đánh giá độc lập. Hãy xem xét truy vấn sau đây làm ví dụ:
SELECT NEWID() AS mynewid1, NEWID() AS mynewid2;
Mã này tạo ra kết quả sau hiển thị hai GUID khác nhau:
mynewid1 mynewid2 ------------------------------------ ------------------------------------ 7BF389EC-082F-44DA-B98A-DB85CD095506 EA1EFF65-B2E4-4060-9592-7116F674D406
Ngược lại, nếu bạn có một bảng dẫn xuất với một cột dựa trên phép tính không xác định và truy vấn bên ngoài có nhiều tham chiếu đến cột đó, thì phép tính chỉ được đánh giá một lần. Hãy xem xét truy vấn sau (chúng tôi sẽ gọi đây là Truy vấn 4):
SELECT mynewid AS mynewid1, mynewid AS mynewid2 FROM ( SELECT NEWID() AS mynewid ) AS D;
Kế hoạch cho truy vấn này được thể hiện trong Hình 4.
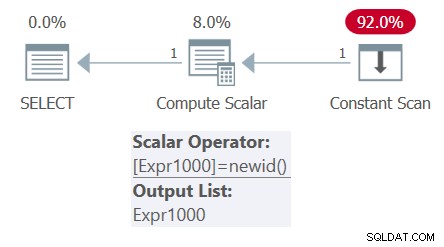 Hình 4:Kế hoạch cho Truy vấn 4
Hình 4:Kế hoạch cho Truy vấn 4
Quan sát rằng chỉ có một lệnh gọi hàm NEWID trong kế hoạch. Theo đó, kết quả hiển thị cùng một GUID hai lần:
mynewid1 mynewid2 ------------------------------------ ------------------------------------ 296A80C9-260A-47F9-9EB1-C2D0C401E74A 296A80C9-260A-47F9-9EB1-C2D0C401E74A
Vì vậy, hai truy vấn trên không tương đương về mặt logic và có những trường hợp nội tuyến / thay thế không diễn ra.
Với một số hàm không xác định, sẽ phức tạp hơn một chút khi chứng minh rằng nhiều lệnh gọi trong một truy vấn được xử lý riêng biệt. Lấy chức năng SYSDATETIME làm ví dụ. Nó có độ chính xác 100 nano giây. Cơ hội mà một truy vấn như sau sẽ thực sự hiển thị hai giá trị khác nhau là gì?
SELECT SYSDATETIME() AS mydt1, SYSDATETIME() AS mydt2;
Nếu cảm thấy buồn chán, bạn có thể nhấn F5 liên tục cho đến khi nó xảy ra. Nếu bạn có nhiều việc quan trọng hơn phải làm với thời gian của mình, bạn có thể thích chạy một vòng lặp, như vậy:
DECLARE @i AS INT = 1;
WHILE EXISTS( SELECT *
FROM ( SELECT SYSDATETIME() AS mydt1, SYSDATETIME() AS mydt2 ) AS D
WHERE mydt1 = mydt2 )
SET @i += 1;
PRINT @i; Ví dụ:khi tôi chạy mã này, tôi nhận được 1971.
Nếu bạn muốn đảm bảo rằng hàm không xác định chỉ được gọi một lần và dựa trên cùng một giá trị trong nhiều tham chiếu truy vấn, hãy đảm bảo rằng bạn xác định biểu thức bảng với một cột dựa trên lệnh gọi hàm và có nhiều tham chiếu đến cột đó từ truy vấn bên ngoài, giống như vậy (chúng tôi sẽ gọi đây là Truy vấn 5):
SELECT mydt AS mydt1, mydt AS mydt1 FROM ( SELECT SYSDATETIME() AS mydt ) AS D;
The plan for this query is shown in Figure 5.
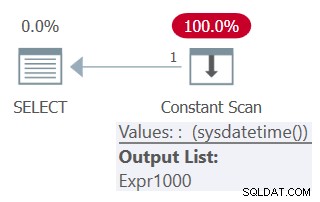 Figure 5:Plan for Query 5
Figure 5:Plan for Query 5
Notice in the plan that the function is invoked only once.
Now this could be a really interesting exercise in patients to hit F5 repeatedly until you get two different values. The good news is that a vaccine for COVID-19 will be found sooner.
You could of course try running a test with a loop:
DECLARE @i AS INT = 1;
WHILE EXISTS ( SELECT *
FROM (SELECT mydt AS mydt1, mydt AS mydt2
FROM ( SELECT SYSDATETIME() AS mydt ) AS D1) AS D2
WHERE mydt1 = mydt2 )
SET @i += 1;
PRINT @i; You can let it run as long as you feel that it’s reasonable to wait, but of course it won’t stop on its own.
Understanding this, you will know to avoid writing code such as the following:
SELECT
CASE
WHEN RAND() < 0.5
THEN STR(RAND(), 5, 3) + ' is less than half.'
ELSE STR(RAND(), 5, 3) + ' is at least half.'
END; Because occasionally, the output will not seem to make sense, e.g.,
0.550 is less than half.For more on evaluation within a CASE expression, see the section "Expressions can be evaluated more than once" in Aaron Bertrand's post, "Dirty Secrets of the CASE Expression."
Instead, you should either store the function’s result in a variable and then work with the variable or, if it needs to be part of a query, you can always work with a derived table, like so:
SELECT
CASE
WHEN rnd < 0.5
THEN STR(rnd, 5, 3) + ' is less than half.'
ELSE STR(rnd, 5, 3) + ' is at least half.'
END
FROM ( SELECT RAND() AS rnd ) AS D; Tóm tắt
In this article I covered some aspects of the physical processing of derived tables.
When the outer query projects only a subset of the columns of a derived table, SQL Server is able to apply efficient index matching based on the columns in the outermost SELECT list, or that play some other meaningful role in the query, such as filtering, grouping, ordering, and so on. From this perspective, if for brevity you prefer to use SELECT * in inner levels of nesting, this will not negatively affect index matching. However, the executing user (or the user whose effective permissions are evaluated), needs permissions to all columns that are referenced in inner levels of nesting, even those that eventually are not really relevant. An exception to this rule is the SELECT list of the inner query in an EXISTS predicate, which is effectively ignored.
When you have multiple references to a nondeterministic function in a query, the different references are evaluated independently. Conversely, if you encapsulate a nondeterministic function call in a result column of a derived table, and refer to that column multiple times from the outer query, all references will rely on the same function invocation and get the same values.