Một nhà phát triển Oracle thường sử dụng các cụm từ thông dụng trong mã sớm hay muộn có thể phải đối mặt với một hiện tượng thực sự thần bí. Tìm kiếm lâu dài để tìm ra gốc rễ của vấn đề có thể dẫn đến giảm cân, thèm ăn và gây ra nhiều loại rối loạn tâm thần - tất cả điều này có thể được ngăn chặn với sự trợ giúp của chức năng regexp_replace. Nó có thể có tối đa 6 đối số:
REGEXP_REPLACE (
- source_string,
- mẫu,
- substituting_string,
- vị trí bắt đầu của tìm kiếm đối sánh với một mẫu (mặc định 1),
- vị trí xuất hiện của mẫu trong chuỗi nguồn (theo mặc định 0 bằng tất cả các lần xuất hiện),
- bổ ngữ (cho đến nay nó là một con ngựa đen)
)
Trả về chuỗi source_string đã sửa đổi, trong đó tất cả các lần xuất hiện của mẫu được thay thế bằng giá trị được truyền trong tham số substituting_string. Thường thì một phiên bản ngắn của hàm được sử dụng, trong đó 3 đối số đầu tiên được chỉ định, đủ để giải quyết nhiều vấn đề. Tôi sẽ làm giống. Giả sử chúng ta cần che tất cả các ký tự chuỗi bằng dấu hoa thị trong chuỗi ‘MASK:chữ thường’. Để chỉ định phạm vi ký tự viết thường, mẫu ‘[a-z]‘ phải phù hợp.
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual Kỳ vọng
+------------------+ | RESULT | +------------------+ | MASK: ***** **** | +------------------+
Thực tế
+------------------+ | RESULT | +------------------+ | *A**: ***** **** | +------------------+
Nếu sự kiện này chưa được tái tạo trong cơ sở dữ liệu của bạn, thì bạn là người may mắn cho đến nay. Nhưng thường xuyên hơn, bạn bắt đầu đào mã, chuyển đổi các chuỗi từ một bộ ký tự này sang một bộ ký tự khác và cuối cùng, sự tuyệt vọng ập đến.
Xác định vấn đề
Câu hỏi đặt ra - điều gì đặc biệt ở chữ ‘A’ mà nó vẫn chưa được thay thế vì phần còn lại của các ký tự viết hoa cũng không được thay thế. Có thể có những chữ cái chính xác khác ngoại trừ cái này. Cần phải xem toàn bộ bảng chữ cái gồm các ký tự viết hoa.
select regexp_replace('ABCDEFJHIGKLMNOPQRSTUVWXYZ', '[a-z]', '*') as alphabet from dual
+----------------------------+
| ALPHABET |
+----------------------------+
| A************************* |
+----------------------------+ Tuy nhiên
Nếu đối số thứ 6 của hàm không được chỉ định rõ ràng, ví dụ:'i' là phân biệt chữ hoa chữ thường hoặc 'c' là phân biệt chữ hoa chữ thường khi so sánh một chuỗi nguồn với một mẫu, thì biểu thức chính quy sử dụng tham số NLS_SORT của phiên / cơ sở dữ liệu theo mặc định. Ví dụ:
select value from sys.nls_session_parameters where parameter = 'NLS_SORT' +---------+ | VALUE | +---------+ | ENGLISH | +---------+
Tham số này chỉ định phương pháp sắp xếp trong ORDER BY. Nếu chúng ta nói về việc sắp xếp các ký tự riêng lẻ đơn giản, thì một số nhị phân nhất định (mã NLSSORT) tương ứng với từng ký tự đó và việc sắp xếp thực sự diễn ra theo giá trị của các số này.
Để minh họa điều này, hãy lấy một vài ký tự đầu tiên và cuối cùng của bảng chữ cái, cả chữ thường và chữ hoa, đặt chúng vào một nhóm bảng không có thứ tự có điều kiện và gọi nó là ABC. Sau đó, hãy sắp xếp tập hợp này theo trường SYMBOL và hiển thị mã NLSSORT của nó ở định dạng HEX bên cạnh mỗi ký hiệu.
with ABC as (
select column_value as symbol
from table(sys.odcivarchar2list('A','B','C','X','Y','Z','a','b','c','x','y','z'))
)
select symbol,
nlssort(symbol) nls_code_hex
from ABC
order by symbol
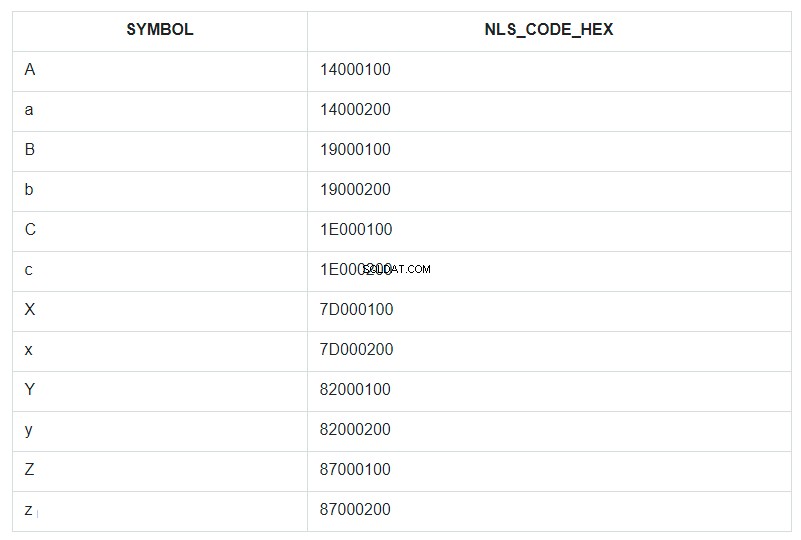
Trong truy vấn, ORDER BY được chỉ định cho trường SYMBOL, nhưng trên thực tế, trong cơ sở dữ liệu, việc sắp xếp theo các giá trị từ trường NLS_CODE_HEX.
Bây giờ, quay trở lại phạm vi từ mẫu và xem bảng - chiều dọc giữa ký hiệu ‘a’ (mã 14000200) và ‘z’ (mã 87000200) là gì? Tất cả mọi thứ ngoại trừ chữ cái viết hoa ‘A’. Đó là tất cả những gì đã được thay thế bằng dấu hoa thị. Và mã 14000100 của chữ ‘A’ không được bao gồm trong phạm vi thay thế từ 14000200 đến 87000200.
Chữa bệnh
Chỉ định rõ ràng công cụ sửa đổi phân biệt chữ hoa chữ thường
select regexp_replace('MASK: lower case', '[a-z]', '*', 1, 0, 'c') from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+
Một số nguồn nói rằng bổ ngữ ‘c’ được đặt theo mặc định, nhưng chúng tôi vừa thấy rằng điều này không hoàn toàn đúng. Và nếu ai đó không nhìn thấy nó, thì tham số NLS_SORT của phiên / cơ sở dữ liệu của nó rất có thể được đặt thành BINARY và việc sắp xếp được thực hiện tương ứng với mã ký tự thực. Thật vậy, nếu bạn thay đổi tham số phiên, vấn đề sẽ được giải quyết.
ALTER SESSION SET NLS_SORT=BINARY;
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+ Các thử nghiệm đã được thực hiện trong Oracle 12c.
Hãy để lại bình luận của bạn và quan tâm.