Đây là phần thứ hai của loạt bài gồm hai phần trên 2ndQuadrant’s repmgr, một công cụ mã nguồn mở có tính khả dụng cao dành cho PostgreSQL.
Trong phần đầu tiên, chúng tôi thiết lập một cụm PostgreSQL 12 ba nút cùng với một nút “nhân chứng”. Cụm bao gồm một nút chính và hai nút dự phòng. Cụm và nút nhân chứng được lưu trữ trong Amazon Web Service Virtual Private Cloud (VPC). Các máy chủ EC2 lưu trữ các phiên bản Postgres được đặt trong các mạng con ở các vùng khả dụng khác nhau (AZ), như được hiển thị bên dưới:
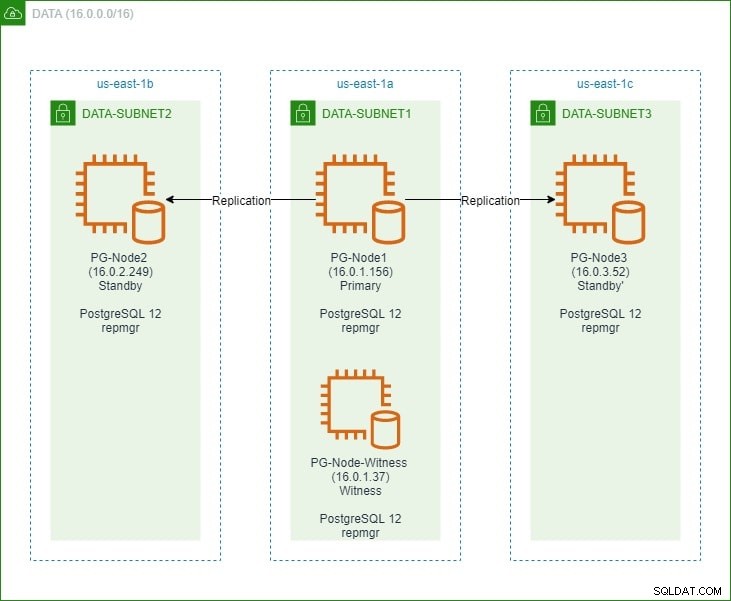
Chúng tôi sẽ tham khảo rộng rãi đến tên nút và địa chỉ IP của chúng, vì vậy đây là bảng một lần nữa với chi tiết của các nút:
| Tên nút | Địa chỉ IP | Vai trò | Ứng dụng đang chạy |
| PG-Node1 | 16.0.1.156 | Chính | PostgreSQL 12 và repmgr |
| PG-Node2 | 16.0.2.249 | Chế độ chờ 1 | PostgreSQL 12 và repmgr |
| PG-Node3 | 16.0.3.52 | Chế độ chờ 2 | PostgreSQL 12 và repmgr |
| PG-Node-Witness | 16.0.1.37 | Nhân chứng | PostgreSQL 12 và repmgr |
Chúng tôi đã cài đặt repmgr trong các nút chính và nút chờ, sau đó đăng ký nút chính bằng repmgr. Sau đó, chúng tôi nhân bản cả hai nút chờ từ nút chính và khởi động chúng. Cả hai nút chờ cũng đã được đăng ký với repmgr. Lệnh "repmgr cluster show" cho chúng ta thấy mọi thứ đang chạy như mong đợi:

Vấn đề hiện tại
Thiết lập sao chép luồng với repmgr rất đơn giản. Những gì chúng ta cần làm tiếp theo là đảm bảo cụm sẽ hoạt động ngay cả khi cụm chính không khả dụng. Đây là những gì chúng tôi sẽ đề cập trong bài viết này.
Trong bản sao PostgreSQL, một bản chính có thể không khả dụng vì một vài lý do. Ví dụ:
- Hệ điều hành của nút chính có thể gặp sự cố hoặc không phản hồi
- Nút chính có thể mất kết nối mạng
- Dịch vụ PostgreSQL trong nút chính có thể gặp sự cố, dừng hoặc không khả dụng đột ngột
- Dịch vụ PostgreSQL trong nút chính có thể bị dừng cố ý hoặc vô tình
Bất cứ khi nào thiết bị chính không khả dụng, chế độ chờ sẽ không tự động thăng cấp lên vai trò chính. Chế độ chờ vẫn tiếp tục phục vụ các truy vấn chỉ đọc - mặc dù dữ liệu sẽ cập nhật đến LSN cuối cùng nhận được từ dữ liệu chính. Mọi nỗ lực thực hiện thao tác ghi sẽ không thành công.
Có hai cách để giảm thiểu điều này:
- Chế độ chờ thủ công được nâng cấp lên vai trò chính. Điều này thường xảy ra đối với chuyển đổi dự phòng theo kế hoạch hoặc "chuyển đổi"
- Chế độ chờ tự động được thăng chức lên vai trò chính. Đây là trường hợp xảy ra với các công cụ không có nguồn gốc liên tục theo dõi quá trình sao chép và thực hiện hành động khôi phục khi công cụ chính không khả dụng. repmgr là một trong những công cụ như vậy.
Chúng tôi sẽ xem xét kịch bản thứ hai ở đây. Tuy nhiên, tình huống này có một số thách thức bổ sung:
- Nếu có nhiều hơn một mã dự phòng, làm cách nào để công cụ (hoặc các mã độc lập) quyết định cái nào sẽ được thăng hạng là chính? Nhóm túc số và quy trình thăng tiến hoạt động như thế nào?
- Đối với nhiều nút dự phòng, nếu một nút được đặt là nút chính, làm cách nào để các nút khác bắt đầu “theo sau nó” làm nút chính mới?
- Điều gì sẽ xảy ra nếu thiết bị chính đang hoạt động nhưng vì lý do nào đó tạm thời bị tách ra khỏi mạng? Nếu một trong các điểm chờ được thăng cấp lên hàng chính và sau đó điểm chính ban đầu hoạt động trở lại trực tuyến, thì làm cách nào để tránh được tình huống “chia rẽ đôi bên”?
remgr’s Answer:Witness Node and the repmgr Daemon
Để trả lời những câu hỏi này, repmgr sử dụng một thứ gọi là nút nhân chứng . Khi nhóm chính không khả dụng - công việc của nút nhân chứng là giúp các nhóm độc lập đạt đến số đại biểu nếu một trong số họ nên được thăng cấp lên vai trò chính. Các dự phòng đạt đến số đại biểu này bằng cách xác định xem nút chính thực sự ngoại tuyến hay chỉ tạm thời không khả dụng. Nút nhân chứng phải được đặt trong cùng trung tâm dữ liệu / phân đoạn mạng / mạng con với nút chính, nhưng KHÔNG BAO GIỜ phải chạy trên cùng một máy chủ vật lý như nút chính.
Hãy nhớ rằng trong phần đầu tiên của loạt bài này, chúng tôi đã triển khai một nút nhân chứng trong cùng một vùng khả dụng và mạng con như nút chính. Chúng tôi đặt tên nó là PG-Node-Witness và cài đặt một phiên bản PostgreSQL 12 ở đó. Trong bài đăng này, chúng tôi cũng sẽ cài đặt repmgr ở đó, nhưng sẽ cài đặt thêm ở đó sau.
Thành phần thứ hai của giải pháp là daemon repmgr (repmgrd) chạy trong tất cả các nút của cụm và nút nhân chứng. Một lần nữa, chúng tôi đã không khởi động daemon này trong phần đầu tiên của loạt bài này, nhưng chúng tôi sẽ làm như vậy ở đây. Daemon là một phần của gói repmgr - khi được kích hoạt, nó sẽ chạy như một dịch vụ thông thường và liên tục theo dõi tình trạng của cụm. Nó bắt đầu chuyển đổi dự phòng khi đạt đến số đại biểu về trạng thái chính đang ngoại tuyến. Nó không chỉ có thể tự động thúc đẩy chế độ chờ mà còn có thể khởi động lại các chế độ chờ khác trong một cụm nhiều nút để tuân theo chế độ chính mới .
Quy trình túc số
Khi một chế độ chờ nhận ra nó không thể nhìn thấy chế độ chính, nó sẽ tham khảo ý kiến của các chế độ chờ khác. Tất cả các dự phòng đang chạy trong cụm đều đạt đến số đại biểu để chọn một dự phòng chính mới bằng cách sử dụng một loạt các kiểm tra:
- Mỗi chế độ chờ sẽ thẩm vấn các thiết bị chờ khác về thời gian cuối cùng nó “nhìn thấy” thiết bị chính. Nếu LSN được sao chép gần đây nhất của nút dự phòng hoặc thời gian giao tiếp cuối cùng với nút chính gần đây hơn LSN được sao chép gần đây nhất của nút hiện tại hoặc thời điểm giao tiếp cuối cùng, thì nút đó sẽ không làm gì cả và đợi giao tiếp với nút chính được khôi phục
- Nếu không có phím dự phòng nào có thể nhìn thấy nút chính, họ sẽ kiểm tra xem nút nhân chứng có khả dụng hay không. Nếu không thể tiếp cận được nút nhân chứng, thì các dự phòng cho rằng có sự cố mạng ở phía chính và không tiếp tục chọn nút chính mới
- Nếu có thể liên hệ được với nhân chứng, những người lập công cho rằng thiết bị chính bị hỏng và tiến hành chọn nhân chứng chính
- Nút được định cấu hình làm nút chính “ưu tiên” sau đó sẽ được thăng cấp. Mỗi chế độ chờ sẽ được khởi động lại bản sao của nó để tuân theo chế độ chính mới.
Định cấu hình Cụm để Chuyển đổi Dự phòng Tự động
Bây giờ chúng ta sẽ định cấu hình cụm và nút nhân chứng để tự động chuyển đổi dự phòng.
Bước 1:Cài đặt và định cấu hình repmgr trong Witness
Chúng ta đã biết cách cài đặt gói repmgr trong bài viết trước. Chúng tôi cũng làm điều này trong nút nhân chứng:
# wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
Và sau đó:
# yum install repmgr12 -y
Tiếp theo, chúng tôi thêm các dòng sau vào tệp postgresql.conf của nút nhân chứng:
listen_addresses = '*' shared_preload_libraries = 'repmgr'
Chúng tôi cũng thêm các dòng sau vào tệp pg_hba.conf trong nút nhân chứng. Lưu ý cách chúng tôi đang sử dụng phạm vi CIDR của cụm thay vì chỉ định các địa chỉ IP riêng lẻ.
local replication repmgr trust host replication repmgr 127.0.0.1/32 trust host replication repmgr 16.0.0.0/16 trust local repmgr repmgr trust host repmgr repmgr 127.0.0.1/32 trust host repmgr repmgr 16.0.0.0/16 trust
Lưu ý
[Các bước được mô tả ở đây chỉ dành cho mục đích trình diễn. Ví dụ của chúng tôi ở đây là sử dụng các IP có thể truy cập bên ngoài cho các nút. Do đó, việc sử dụng listening_address =‘*’ cùng với cơ chế bảo mật “tin cậy” của pg_hba gây ra rủi ro bảo mật và KHÔNG được sử dụng trong các kịch bản sản xuất. Trong hệ thống sản xuất, tất cả các nút sẽ nằm bên trong một hoặc nhiều mạng con riêng tư, có thể truy cập thông qua IP riêng từ các jumphost.]
Với các thay đổi postgresql.conf và pg_hba.conf được thực hiện, chúng tôi tạo người dùng repmgr và cơ sở dữ liệu repmgr trong nhân chứng và thay đổi đường dẫn tìm kiếm mặc định của người dùng repmgr:
[example@sqldat.comitness ~]$ createuser --superuser repmgr [example@sqldat.com ~]$ createdb --owner=repmgr repmgr [example@sqldat.com ~]$ psql -c "ALTER USER repmgr SET search_path TO repmgr, public;"
Cuối cùng, chúng tôi thêm các dòng sau vào tệp repmgr.conf, nằm dưới / etc / repmgr / 12 /
node_id=4 node_name='PG-Node-Witness' conninfo='host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2' data_directory='/var/lib/pgsql/12/data'
Sau khi các tham số cấu hình được đặt, chúng tôi khởi động lại dịch vụ PostgreSQL trong nút nhân chứng:
# systemctl restart postgresql-12.service
Để kiểm tra kết nối với nút chứng kiến repmgr, chúng ta có thể chạy lệnh này từ nút chính:
[example@sqldat.com ~]$ psql 'host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2'
Tiếp theo, chúng tôi đăng ký nút nhân chứng với repmgr bằng cách chạy lệnh “đăng ký nhân chứng repmgr” với tư cách là người dùng postgres. Lưu ý cách chúng tôi đang sử dụng địa chỉ của chính và KHÔNG phải là nút nhân chứng trong lệnh bên dưới:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf witness register -h 16.0.1.156
Điều này là do lệnh “đăng ký nhân chứng repmgr” thêm siêu dữ liệu của nút nhân chứng vào cơ sở dữ liệu repmgr của nút chính và nếu cần, hãy khởi tạo nút nhân chứng bằng cách cài đặt tiện ích mở rộng repmgr và sao chép siêu dữ liệu repmgr vào nút nhân chứng.
Đầu ra sẽ như thế này:
INFO: connecting to witness node "PG-Node-Witness" (ID: 4) INFO: connecting to primary node NOTICE: attempting to install extension "repmgr" NOTICE: "repmgr" extension successfully installed INFO: witness registration complete NOTICE: witness node "PG-Node-Witness" (ID: 4) successfully registered
Cuối cùng, chúng tôi kiểm tra trạng thái của thiết lập tổng thể từ bất kỳ nút nào:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
Đầu ra giống như sau:

Bước 2:Sửa đổi tệp sudoers
Với cụm và nhân chứng đang chạy, chúng tôi thêm các dòng sau vào tệp sudoers Trong mỗi nút của cụm và nút nhân chứng:
Defaults:postgres !requiretty postgres ALL = NOPASSWD: /usr/bin/systemctl stop postgresql-12.service, /usr/bin/systemctl start postgresql-12.service, /usr/bin/systemctl restart postgresql-12.service, /usr/bin/systemctl reload postgresql-12.service, /usr/bin/systemctl start repmgr12.service, /usr/bin/systemctl stop repmgr12.service
Bước 3:Định cấu hình tham số repmgrd
Chúng tôi đã thêm bốn tham số trong tệp repmgr.conf trong mỗi nút. Các tham số được thêm vào là những tham số cơ bản cần thiết cho hoạt động của repmgr. Để kích hoạt daemon repmgr và chuyển đổi dự phòng tự động, một số tham số khác cần được bật / thêm. Trong các phần phụ sau, chúng tôi sẽ mô tả từng tham số và giá trị mà chúng sẽ được đặt trong mỗi nút.
chuyển đổi dự phòng
Tham số chuyển đổi dự phòng là một trong những tham số bắt buộc đối với daemon repmgr. Tham số này cho daemon biết liệu nó có nên bắt đầu chuyển đổi dự phòng tự động khi phát hiện tình huống chuyển đổi dự phòng hay không. Nó có thể có một trong hai giá trị:“thủ công” hoặc “tự động”. Chúng tôi sẽ đặt điều này thành tự động trong mỗi nút:
failover='automatic'
promotion_command
Đây là một tham số bắt buộc khác cho daemon repmgr. Tham số này cho daemon repmgr biết lệnh nào nó sẽ chạy để thúc đẩy chế độ chờ. Giá trị của tham số này thường sẽ là lệnh “repmgr standby Promotion” hoặc đường dẫn đến một tập lệnh shell gọi lệnh. Đối với trường hợp sử dụng của chúng tôi, chúng tôi đặt điều này thành như sau trong mỗi nút:
promote_command='/usr/pgsql-12/bin/repmgr standby promote -f /etc/repmgr/12/repmgr.conf --log-to-file'
follow_command
Đây là tham số bắt buộc thứ ba cho daemon repmgr. Tham số này yêu cầu một nút dự phòng theo dõi nút chính mới. Daemon repmgr thay thế trình giữ chỗ% n bằng ID nút của tệp chính mới tại thời điểm chạy:
follow_command='/usr/pgsql-12/bin/repmgr standby follow -f /etc/repmgr/12/repmgr.conf --log-to-file --upstream-node-id=%n'
ưu tiên
Thông số ưu tiên bổ sung thêm sức mạnh cho tính đủ điều kiện của một nút để trở thành nút chính. Việc đặt tham số này thành giá trị cao hơn sẽ cho phép một nút đủ điều kiện trở thành nút chính hơn. Ngoài ra, việc đặt giá trị này thành 0 cho một nút sẽ đảm bảo nút không bao giờ được thăng cấp là chính.
Trong trường hợp sử dụng của chúng tôi, chúng tôi có hai dự phòng:PG-Node2 và PG-Node3. Chúng tôi muốn quảng bá PG-Node2 làm phiên bản chính mới khi PG-Node1 chuyển sang chế độ ngoại tuyến và PG-Node3 tiếp nối PG-Node2 làm phiên bản chính mới. Chúng tôi đặt thông số thành các giá trị sau trong hai nút chờ:
| Tên nút | Cài đặt Tham số |
| PG-Node2 | ưu tiên =60 |
| PG-Node3 | ưu tiên =40 |
monitor_interval_secs
Tham số này cho repmgr daemon biết tần suất (tính bằng số giây) nó sẽ kiểm tra tính khả dụng của nút ngược dòng. Trong trường hợp của chúng ta, chỉ có một nút ngược dòng:nút chính. Giá trị mặc định là 2 giây, nhưng chúng tôi sẽ đặt điều này một cách rõ ràng trong mỗi nút:
monitor_interval_secs=2
connection_check_type
Tham số connection_check_type chỉ định giao thức daemon repmgr sẽ sử dụng để tiếp cận với nút ngược dòng. Tham số này có thể nhận ba giá trị:
- ping :repmgr sử dụng phương thức PQPing ()
- kết nối :repmgr cố gắng tạo một kết nối mới tới nút ngược dòng
- truy vấn :repmgr cố gắng chạy một truy vấn SQL trên nút ngược dòng bằng cách sử dụng kết nối hiện có
Một lần nữa, chúng tôi sẽ đặt tham số này thành giá trị mặc định của ping trong mỗi nút:
connection_check_type='ping'
renect_attempts và renect_interval
Khi nút chính không khả dụng, daemon repmgr trong các nút dự phòng sẽ cố gắng kết nối lại với nút chính cho lần kết nối lại. Giá trị mặc định cho tham số này là 6. Giữa mỗi lần thử kết nối lại, nó sẽ đợi giây kết nối lại, có giá trị mặc định là 10. Đối với mục đích trình diễn, chúng tôi sẽ sử dụng một khoảng thời gian ngắn và ít lần thử kết nối lại hơn. Chúng tôi đặt tham số này trong mọi nút:
reconnect_attempts=4 reconnect_interval=8
primary_visibility_consensus
Khi nút chính không khả dụng trong một cụm nhiều nút, các nút dự phòng có thể tham khảo ý kiến lẫn nhau để xây dựng nhóm túc số về chuyển đổi dự phòng. Điều này được thực hiện bằng cách hỏi từng chế độ chờ về thời gian lần cuối nó nhìn thấy thiết bị chính. Nếu giao tiếp cuối cùng của một nút rất gần đây và muộn hơn thời điểm nút cục bộ nhìn thấy nút chính, thì nút cục bộ sẽ giả định rằng nút chính vẫn khả dụng và không tiếp tục với quyết định chuyển đổi dự phòng.
Để kích hoạt mô hình đồng thuận này, thông số primary_visibility_consensus cần được đặt thành "true" trong mỗi nút - bao gồm cả nhân chứng:
primary_visibility_consensus=true
standby_disconnect_on_failover
Khi tham số standby_disconnect_on_failover được đặt thành “true” trong một nút dự phòng, trình nền repmgr sẽ đảm bảo bộ thu WAL của nó bị ngắt kết nối khỏi bộ thu chính và không nhận bất kỳ phân đoạn WAL nào. Nó cũng sẽ đợi các bộ thu WAL của các nút dự phòng khác dừng lại trước khi đưa ra quyết định chuyển đổi dự phòng. Tham số này phải được đặt thành cùng một giá trị trong mỗi nút. Chúng tôi đang đặt điều này thành “true”.
standby_disconnect_on_failover=true
Đặt tham số này thành true có nghĩa là mọi nút dự phòng đã ngừng nhận dữ liệu từ nút chính khi quá trình chuyển đổi dự phòng xảy ra. Quá trình sẽ có độ trễ là 5 giây cộng với thời gian bộ thu WAL dừng lại trước khi đưa ra quyết định chuyển đổi dự phòng. Theo mặc định, daemon repmgr sẽ đợi 30 giây để xác nhận tất cả các nút anh em đã ngừng nhận các phân đoạn WAL trước khi chuyển đổi dự phòng xảy ra.
repmgrd_service_start_command và repmgrd_service_stop_command
Hai tham số này chỉ định cách khởi động và dừng daemon repmgr bằng cách sử dụng lệnh “repmgr daemon start” và “repmgr daemon stop”.
Về cơ bản, hai lệnh này là các trình bao bọc xung quanh các lệnh của hệ điều hành để bắt đầu / dừng dịch vụ. Hai giá trị tham số ánh xạ các lệnh này tới các phiên bản dành riêng cho hệ điều hành của chúng. Chúng tôi đặt các tham số này thành các giá trị sau trong mỗi nút:
repmgrd_service_start_command='sudo /usr/bin/systemctl start repmgr12.service' repmgrd_service_stop_command='sudo /usr/bin/systemctl stop repmgr12.service'
Lệnh khởi động / dừng / khởi động lại dịch vụ PostgreSQL
Là một phần hoạt động của nó, daemon repmgr thường sẽ cần phải dừng, khởi động hoặc khởi động lại dịch vụ PostgreSQL. Để đảm bảo điều này diễn ra suôn sẻ, cách tốt nhất là chỉ định các lệnh hệ điều hành tương ứng làm giá trị tham số trong tệp repmgr.conf. Chúng tôi sẽ đặt bốn tham số trong mỗi nút cho mục đích này:
service_start_command='sudo /usr/bin/systemctl start postgresql-12.service' service_stop_command='sudo /usr/bin/systemctl stop postgresql-12.service' service_restart_command='sudo /usr/bin/systemctl restart postgresql-12.service' service_reload_command='sudo /usr/bin/systemctl reload postgresql-12.service'
monitor_history
Đặt tham số monitor_history thành “yes” sẽ đảm bảo repmgr đang lưu dữ liệu giám sát cụm của nó. Chúng tôi đặt điều này thành "có" trong mỗi nút:
monitoring_history=yes
log_status_interval
Chúng tôi đặt tham số trong mỗi nút để chỉ định tần suất trình nền repmgr sẽ ghi lại một thông báo trạng thái. Trong trường hợp này, chúng tôi đang đặt điều này thành 60 giây một lần:
log_status_interval=60
Bước 4:Khởi động repmgr Daemon
Với các tham số hiện đã được thiết lập trong cụm và nút nhân chứng, chúng tôi thực hiện chạy lệnh ngắn để khởi động daemon repmgr. Trước tiên, chúng tôi kiểm tra điều này trong nút chính, sau đó là hai nút chờ, tiếp theo là nút nhân chứng. Lệnh phải được thực thi với tư cách là người dùng postgres:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start --dry-run
Đầu ra sẽ giống như sau:
INFO: prerequisites for starting repmgrd met DETAIL: following command would be executed: sudo /usr/bin/systemctl start repmgr12.service
Tiếp theo, chúng tôi khởi động daemon trong tất cả bốn nút:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start
Đầu ra trong mỗi nút sẽ hiển thị daemon đã bắt đầu:
NOTICE: executing: "sudo /usr/bin/systemctl start repmgr12.service" NOTICE: repmgrd was successfully started
Chúng tôi cũng có thể kiểm tra sự kiện khởi động dịch vụ từ các nút chính hoặc nút dự phòng:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event --event=repmgrd_start
Đầu ra sẽ hiển thị daemon đang giám sát các kết nối:
Node ID | Name | Event | OK | Timestamp | Details --------+-----------------+---------------+----+---------------------+------------------------------------------------------------------ 4 | PG-Node-Witness | repmgrd_start | t | 2020-02-05 11:37:31 | witness monitoring connection to primary node "PG-Node1" (ID: 1) 3 | PG-Node3 | repmgrd_start | t | 2020-02-05 11:37:24 | monitoring connection to upstream node "PG-Node1" (ID: 1) 2 | PG-Node2 | repmgrd_start | t | 2020-02-05 11:37:19 | monitoring connection to upstream node "PG-Node1" (ID: 1) 1 | PG-Node1 | repmgrd_start | t | 2020-02-05 11:37:14 | monitoring cluster primary "PG-Node1" (ID: 1)
Cuối cùng, chúng ta có thể kiểm tra đầu ra daemon từ nhật ký hệ thống trong bất kỳ lỗi nào:
# cat /var/log/messages | grep repmgr | less
Đây là kết quả từ PG-Node3:
Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] using provided configuration file "/etc/repmgr/12/repmgr.conf" Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] repmgrd (repmgrd 5.0.0) starting up Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] connecting to database "host=16.0.3.52 user=repmgr dbname=repmgr connect_timeout=2" Feb 5 11:37:24 PG-Node3 systemd[1]: repmgr12.service: Can't open PID file /run/repmgr/repmgrd-12.pid (yet?) after start: No such file or directory Feb 5 11:37:24 PG-Node3 repmgrd[2014]: INFO: set_repmgrd_pid(): provided pidfile is /run/repmgr/repmgrd-12.pid Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] starting monitoring of node "PG-Node3" (ID: 3) Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] "connection_check_type" set to "ping" Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] monitoring connection to upstream node "PG-Node1" (ID: 1) Feb 5 11:38:25 PG-Node3 repmgrd[2014]: [2020-02-05 11:38:25] [INFO] node "PG-Node3" (ID: 3) monitoring upstream node "PG-Node1" (ID: 1) in normal state Feb 5 11:38:25 PG-Node3 repmgrd[2014]: [2020-02-05 11:38:25] [DETAIL] last monitoring statistics update was 2 seconds ago Feb 5 11:39:26 PG-Node3 repmgrd[2014]: [2020-02-05 11:39:26] [INFO] node "PG-Node3" (ID: 3) monitoring upstream node "PG-Node1" (ID: 1) in normal state … …
Kiểm tra nhật ký hệ thống trong nút chính cho thấy một loại đầu ra khác:
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] using provided configuration file "/etc/repmgr/12/repmgr.conf" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] repmgrd (repmgrd 5.0.0) starting up Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] connecting to database "host=16.0.1.156 user=repmgr dbname=repmgr connect_timeout=2" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] starting monitoring of node "PG-Node1" (ID: 1) Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] "connection_check_type" set to "ping" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] monitoring cluster primary "PG-Node1" (ID: 1) Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node-Witness" (ID: 4) is not yet attached Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node3" (ID: 3) is attached Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node2" (ID: 2) is attached Feb 5 11:37:32 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:32] [NOTICE] new witness "PG-Node-Witness" (ID: 4) has connected Feb 5 11:38:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:38:14] [INFO] monitoring primary node "PG-Node1" (ID: 1) in normal state Feb 5 11:39:15 PG-Node1 repmgrd[2017]: [2020-02-05 11:39:15] [INFO] monitoring primary node "PG-Node1" (ID: 1) in normal state … …
Bước 5:Mô phỏng Chính không thành công
Bây giờ chúng ta sẽ mô phỏng một sơ cấp bị lỗi bằng cách dừng nút chính (PG-Node1). Từ dấu nhắc trình bao của nút, chúng tôi chạy lệnh sau:
# systemctl stop postgresql-12.service
Quá trình chuyển đổi dự phòng
Khi quá trình dừng lại, chúng tôi đợi khoảng một hoặc hai phút, sau đó kiểm tra tệp nhật ký hệ thống của PG-Node2. Các thông báo sau được hiển thị. Để rõ ràng và đơn giản, chúng tôi có các nhóm thư được mã hóa màu và thêm khoảng trắng giữa các dòng:
… Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [INFO] checking state of node 1, 2 of 4 attempts Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [INFO] checking state of node 1, 3 of 4 attempts Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of node 1, 4 of 4 attempts Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] unable to reconnect to node 1 after 4 attempts Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] setting "wal_retrieve_retry_interval" to 86405000 milliseconds Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] wal receiver not running Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] WAL receiver disconnected on all sibling nodes Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] WAL receiver disconnected on all 2 sibling nodes Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] local node's last receive lsn: 0/2214A000 Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of sibling node "PG-Node3" (ID: 3) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) reports its upstream is node 1, last seen 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node 3 last saw primary node 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] last receive LSN for sibling node "PG-Node3" (ID: 3) is: 0/2214A000 Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) has same LSN as current candidate "PG-Node2" (ID: 2) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) has lower priority (40) than current candidate "PG-Node2" (ID: 2) (60) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of sibling node "PG-Node-Witness" (ID: 4) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node-Witness" (ID: 4) reports its upstream is node 1, last seen 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node 4 last saw primary node 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] visible nodes: 3; total nodes: 3; no nodes have seen the primary within the last 4 seconds … … Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] promotion candidate is "PG-Node2" (ID: 2) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] setting "wal_retrieve_retry_interval" to 5000 ms Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] this node is the winner, will now promote itself and inform other nodes … … Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] promoting standby to primary Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [DETAIL] promoting server "PG-Node2" (ID: 2) using pg_promote() Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] waiting up to 60 seconds (parameter "promote_check_timeout") for promotion to complete Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] STANDBY PROMOTE successful Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [DETAIL] server "PG-Node2" (ID: 2) was successfully promoted to primary Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [INFO] 2 followers to notify Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] notifying node "PG-Node3" (ID: 3) to follow node 2 Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] notifying node "PG-Node-Witness" (ID: 4) to follow node 2 Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [INFO] switching to primary monitoring mode Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] monitoring cluster primary "PG-Node2" (ID: 2) Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new witness "PG-Node-Witness" (ID: 4) has connected Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new standby "PG-Node3" (ID: 3) has connected Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new standby "PG-Node3" (ID: 3) has connected Feb 5 11:55:02 PG-Node2 repmgrd[2165]: [2020-02-05 11:55:02] [INFO] monitoring primary node "PG-Node2" (ID: 2) in normal state Feb 5 11:56:02 PG-Node2 repmgrd[2165]: [2020-02-05 11:56:02] [INFO] monitoring primary node "PG-Node2" (ID: 2) in normal state … …
Có rất nhiều thông tin ở đây, nhưng hãy phân tích cách các sự kiện diễn ra. For simplicity, we have grouped messages and placed whitespaces between the groups.
The first set of messages shows the repmgr daemon is trying to connect to the primary node (node ID 1) four times using PQPing(). This is because we specified the connection_check_type parameter to “ping” in the repmgr.conf file. After 4 attempts, the daemon reports it cannot connect to the primary node.
The next set of messages tells us the standbys have disconnected their WAL receivers. This is because we had set the parameter standby_disconnect_on_failover to “true” in the repmgr.conf file.
In the next set of messages, the standby nodes and the witness inquire about the last received LSN from the primary and the last time each saw the primary. The last received LSNs match for both the standby nodes. The nodes agree they cannot see the primary within the last 4 seconds. Note how repmgr daemon also finds PG-Node3 has a lower priority for promotion. As none of the nodes have seen the primary recently, they can reach a quorum that the primary is down.
After this, we have messages that show repmgr is choosing PG-Node2 as the promotion candidate. It declares the node winner and says the node will promote itself and inform other nodes.
The group of messages after this shows PG-Node2 successfully promoting to the primary role. Once that’s done, the nodes PG-Node3 (node ID 3) and PG-Node-Witness (node ID 4) are signaled to follow the newly promoted primary.
The final set of messages shows the two nodes have connected to the new primary and the repmgr daemon has started monitoring the local node.
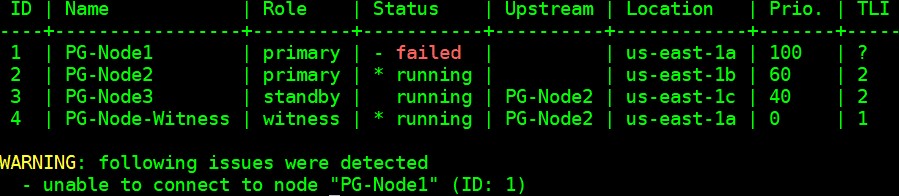
Our cluster is now back in action. We can confirm this by running the “repmgr cluster show” command:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
The output shown in the image below is self-explanatory:
We can also look for the events by running the “repmgr cluster event” command:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event
The output displays how it happened:
Node ID | Name | Event | OK | Timestamp | Details --------+-----------------+----------------------------+----+---------------------+------------------------------------------------------------------------------------ 3 | PG-Node3 | repmgrd_failover_follow | t | 2020-02-05 11:54:08 | node 3 now following new upstream node 2 3 | PG-Node3 | standby_follow | t | 2020-02-05 11:54:08 | standby attached to upstream node "PG-Node2" (ID: 2) 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new standby "PG-Node3" (ID: 3) has connected 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new witness "PG-Node-Witness" (ID: 4) has connected 4 | PG-Node-Witness | repmgrd_upstream_reconnect | t | 2020-02-05 11:54:02 | witness monitoring connection to primary node "PG-Node2" (ID: 2) 4 | PG-Node-Witness | repmgrd_failover_follow | t | 2020-02-05 11:54:02 | witness node 4 now following new primary node 2 2 | PG-Node2 | repmgrd_reload | t | 2020-02-05 11:54:01 | monitoring cluster primary "PG-Node2" (ID: 2) 2 | PG-Node2 | repmgrd_failover_promote | t | 2020-02-05 11:54:01 | node 2 promoted to primary; old primary 1 marked as failed 2 | PG-Node2 | standby_promote | t | 2020-02-05 11:54:01 | server "PG-Node2" (ID: 2) was successfully promoted to primary 1 | PG-Node1 | child_node_new_connect | t | 2020-02-05 11:37:32 | new witness "PG-Node-Witness" (ID: 4) has connected
Kết luận
This completes our two-part series on repmgr and its daemon repmgrd. As we saw in the first part, setting up a multi-node PostgreSQL replication is very simple with repmgr. The daemon makes it even easier to automate a failover. It also automatically redirects existing standbys to follow the new primary. In native PostgreSQL replication, all existing standbys have to be manually configured to replicate from the new primary – automating this process saves valuable time and effort for the DBA.
One thing we have not covered here is “fencing off” the failed primary. In a failover situation, a failed primary needs to be removed from the cluster, and remain inaccessible to client connections. This is to prevent any split-brain situation in the event the old primary accidentally comes back online. The repmgr daemon can work with a connection-pooling tool like pgbouncer to implement the fence-off process. For more information, you can refer to this 2ndQuadrant Github documentation.
Also, after a failover, applications connecting to the cluster need to have their connection strings changed to repoint to the new master. This is a big topic in itself and we will not go into the details here, but one of the methods to address this can be the use of a virtual IP address (and associated DNS resolution) to hide the underlying master node of the cluster.
How to Automate PostgreSQL 12 Replication and Failover with repmgr – Part 1