Bài viết này cung cấp hướng dẫn từng bước để sử dụng khả năng Học máy với 2UDA. Trong bài viết, chúng tôi sẽ sử dụng một ví dụ về Động vật để dự đoán chúng là động vật có vú, Chim, Cá hay Côn trùng.
Phiên bản phần mềm
Chúng tôi sẽ sử dụng 2UDA phiên bản 11.6-1 để triển khai mô hình Học máy. Phiên bản 2UDA 11.6-1 kết hợp:
- PostgreSQL 11.6
- Màu cam 3.23.0
Bạn có thể tìm thấy phiên bản mới nhất của 2UDA tại đây.
Bước 1:Tải tập dữ liệu đào tạo vào PostgreSQL
Tập dữ liệu mẫu được sử dụng để đào tạo mô hình của chúng tôi hiện có tại kho lưu trữ GitHub chính thức của Orange tại đây.
Làm theo các bước sau để tải dữ liệu đào tạo vào các bảng PostgreSQL:
- Kết nối với PostgreSQL qua psql, OmniDB hoặc bất kỳ công cụ nào khác mà bạn quen thuộc.
- Tạo bảng để lưu trữ dữ liệu đào tạo của chúng tôi . Ở đây, nó được đặt tên là training_data.
CREATE TABLE training_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- Chèn dữ liệu đào tạo vào bảng thông qua truy vấn COPY. Trước khi thực hiện truy vấn COPY, hãy đảm bảo rằng PostgreSQL đã yêu cầu quyền đọc trên tệp dữ liệu, nếu không hoạt động COPY sẽ không thành công.
LƯU Ý: Vui lòng đảm bảo bạn nhập tab khoảng trắng ở giữa các dấu ngoặc kép sau dấu phân cách từ khóa.
COPY training_data FROM 'Path_to_training_data_file’ with delimiter ' ' csv header;
Vui lòng tìm ảnh chụp màn hình của tập dữ liệu đào tạo dưới đây
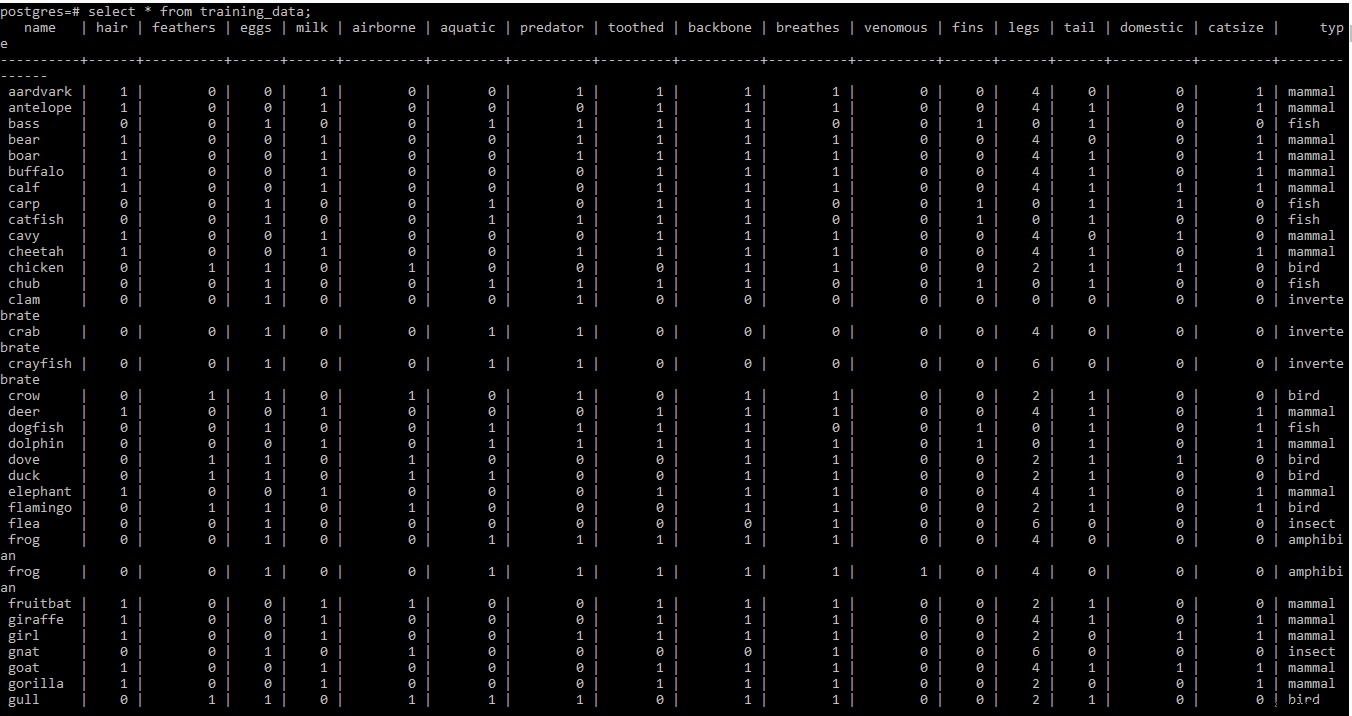
LƯU Ý: Hàng hai và hàng ba của tập dữ liệu đào tạo trong .tab tệp chứa một số thông tin meta. Vì nó không cần thiết tại thời điểm này, nó đã bị xóa khỏi tệp.
Bước 2:Tạo quy trình làm việc với Orange
- Chuyển đến màn hình và nhấp đúp vào biểu tượng Màu cam.
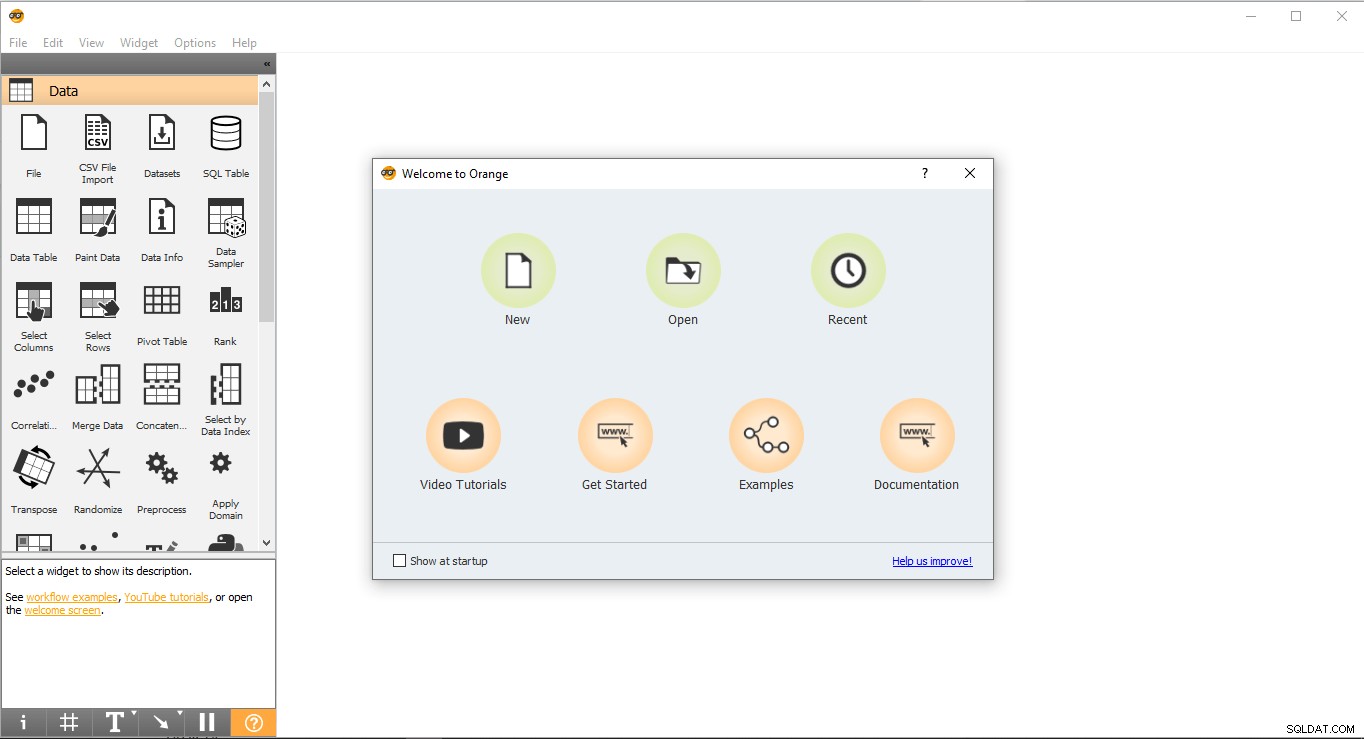
- Đây là giao diện của trang khởi động. Chọn Mới và nó sẽ tạo ra một dự án trống.

Bây giờ bạn đã sẵn sàng áp dụng mô hình Học máy trên tập dữ liệu.
Bước 3:Chọn mô hình Học máy để đào tạo dữ liệu
Đối với bài viết này, k-gần nhất hàng xóm (KNN) Mô hình Học máy được sử dụng để đào tạo dữ liệu. Sau khi quá trình đào tạo dữ liệu hoàn tất, dữ liệu kiểm tra ở bước tiếp theo được chuyển đến Dự đoán tiện ích con để kiểm tra độ chính xác của các dự đoán.
Bước 4:Nhập dữ liệu đào tạo từ PostgreSQL vào Orange
Tập dữ liệu đào tạo này sẽ được sử dụng để đào tạo mô hình Học máy.
- Kéo và Thả Bảng SQL tiện ích con từ Dữ liệu thực đơn.
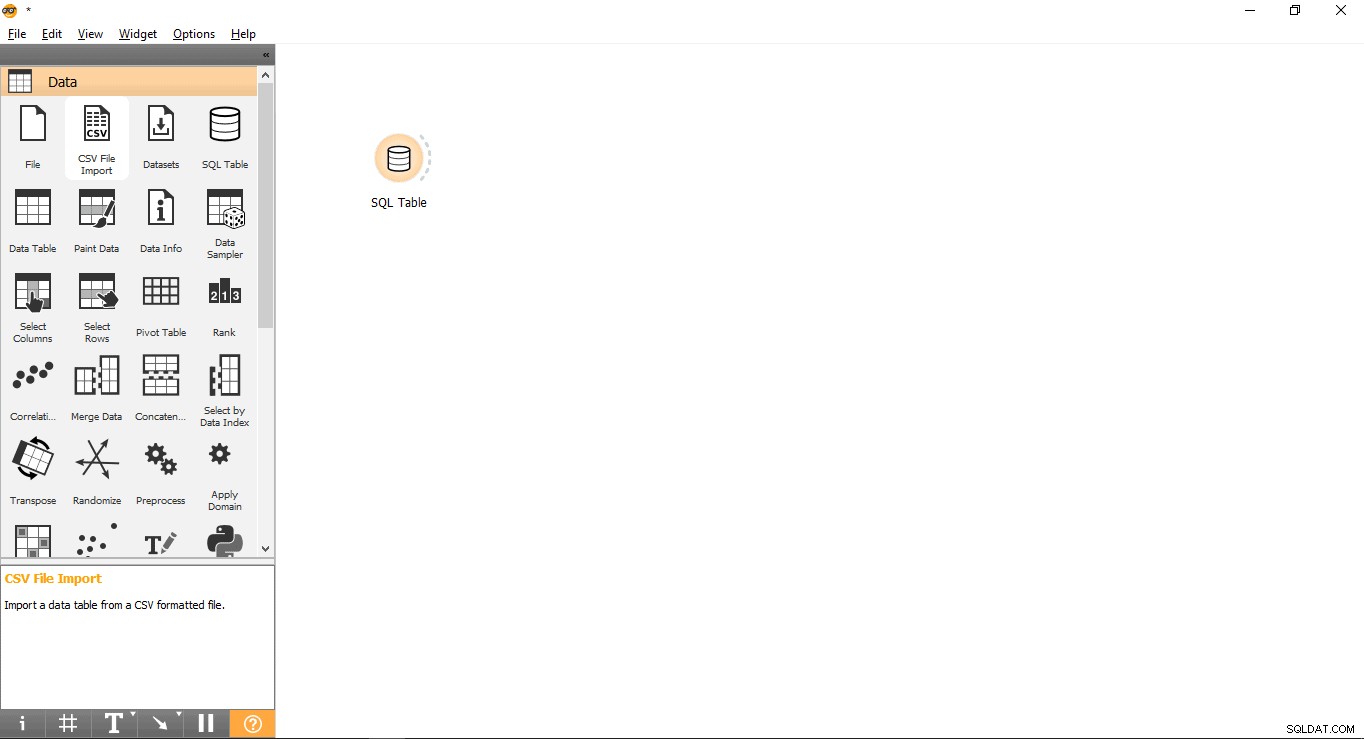
- Đổi tên tiện ích con (tùy chọn)
- Nhấp chuột phải vào Bảng SQL tiện ích con.
- Chọn Đổi tên .
- Kết nối với PostgreSQL để tải tập dữ liệu đào tạo:
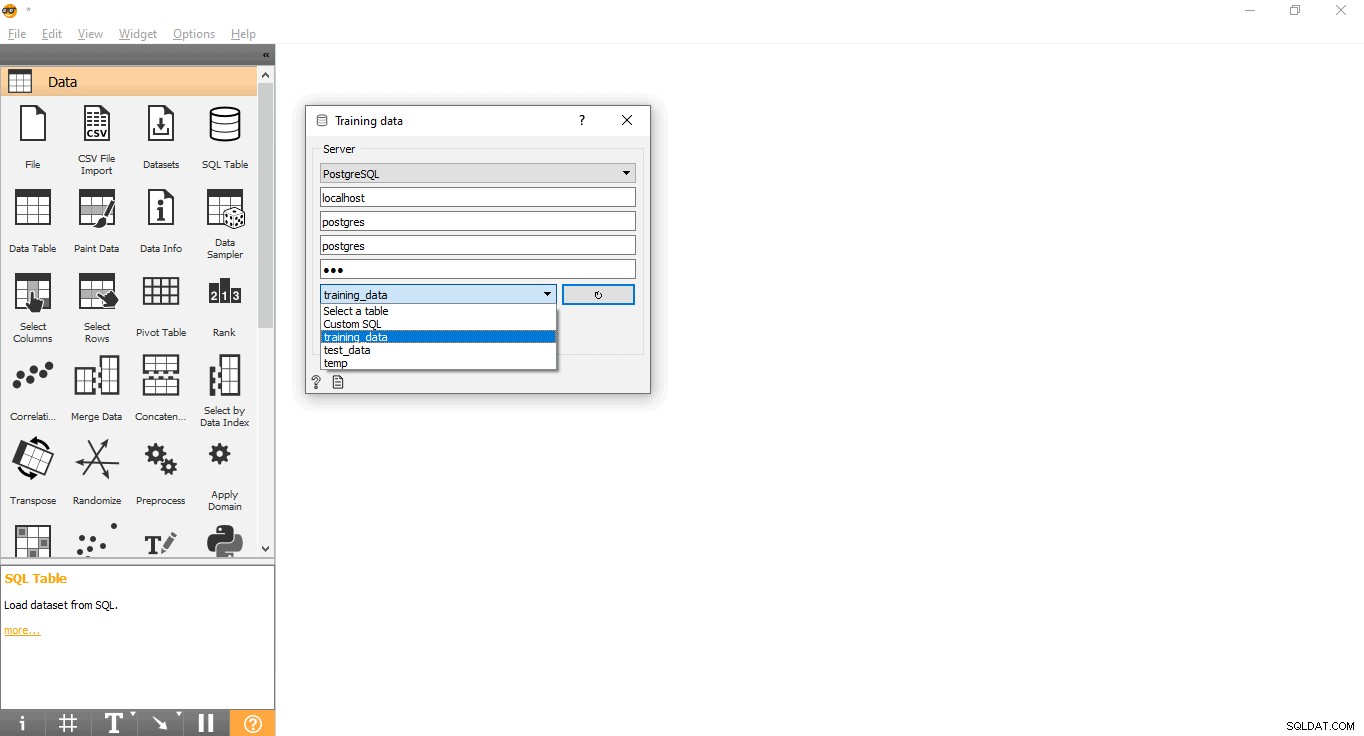
- Nhấp đúp vào Dữ liệu đào tạo tiện ích con.
- Nhập thông tin đăng nhập để kết nối với cơ sở dữ liệu PostgreSQL.
- Nhấn nút tải lại để tải tất cả các bảng có sẵn từ cơ sở dữ liệu đã cho.
- Chọn bảng training_data từ menu thả xuống và đóng cửa sổ bật lên.
Bước 5:Thêm cột Mục tiêu
Bước này quan trọng vì mô hình Học máy sẽ cố gắng dự đoán dữ liệu cho biến / cột mục tiêu này:
- Kéo và thả Chọn cột tiện ích con từ dữ liệu menu.
- Nhấp đúp vào Chọn cột tiện ích con.
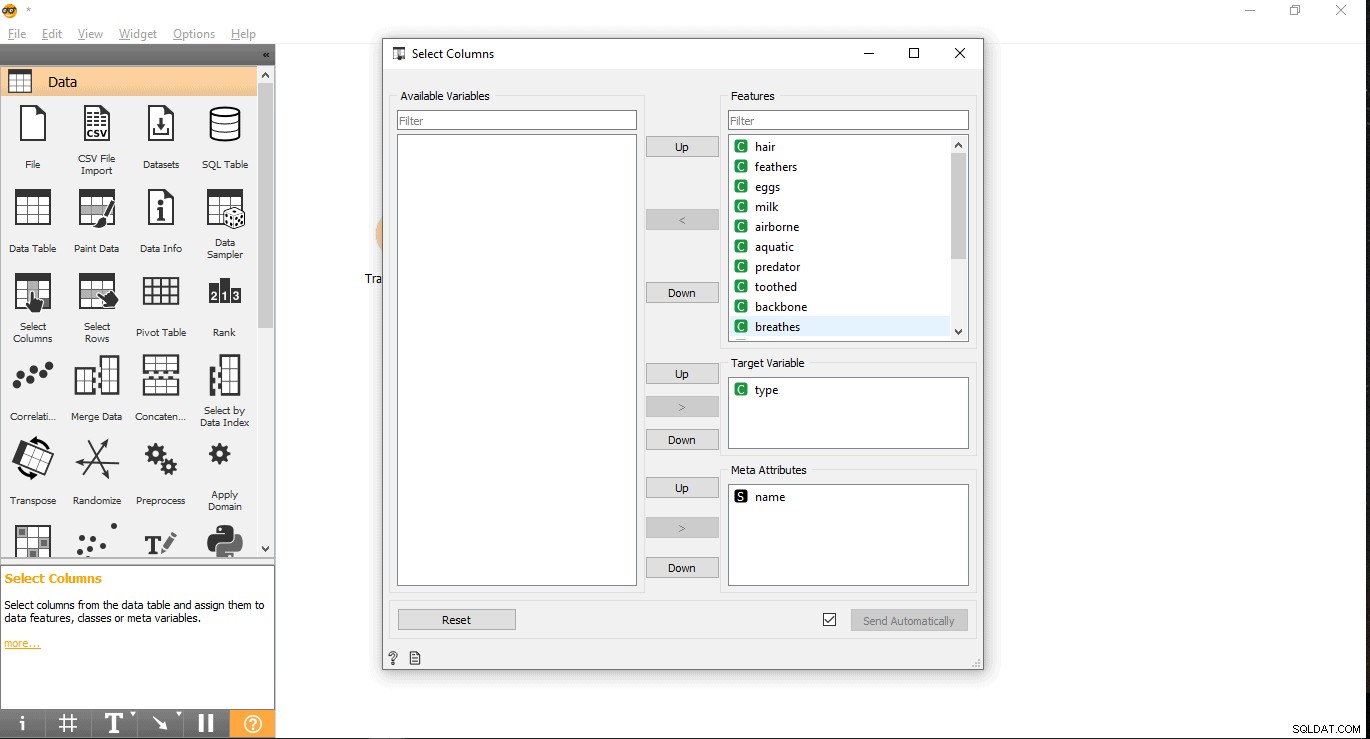
- Tìm kiếm cột mục tiêu của bạn trong nhãn Tính năng. Ở đây, loại được sử dụng dưới dạng biến mục tiêu vì chúng ta cần xem loại động vật nhất định là gì.
- Kéo và thả nó trong Biến mục tiêu và đóng cửa sổ bật lên.
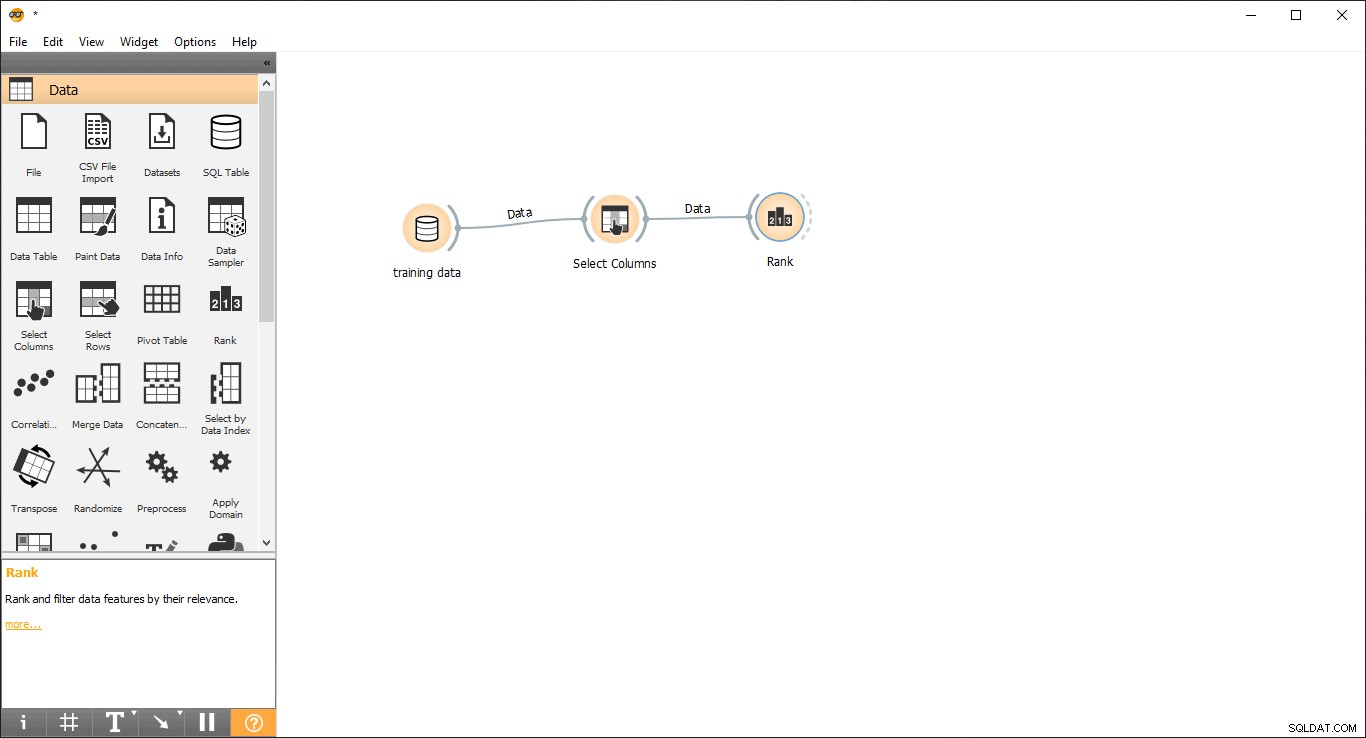
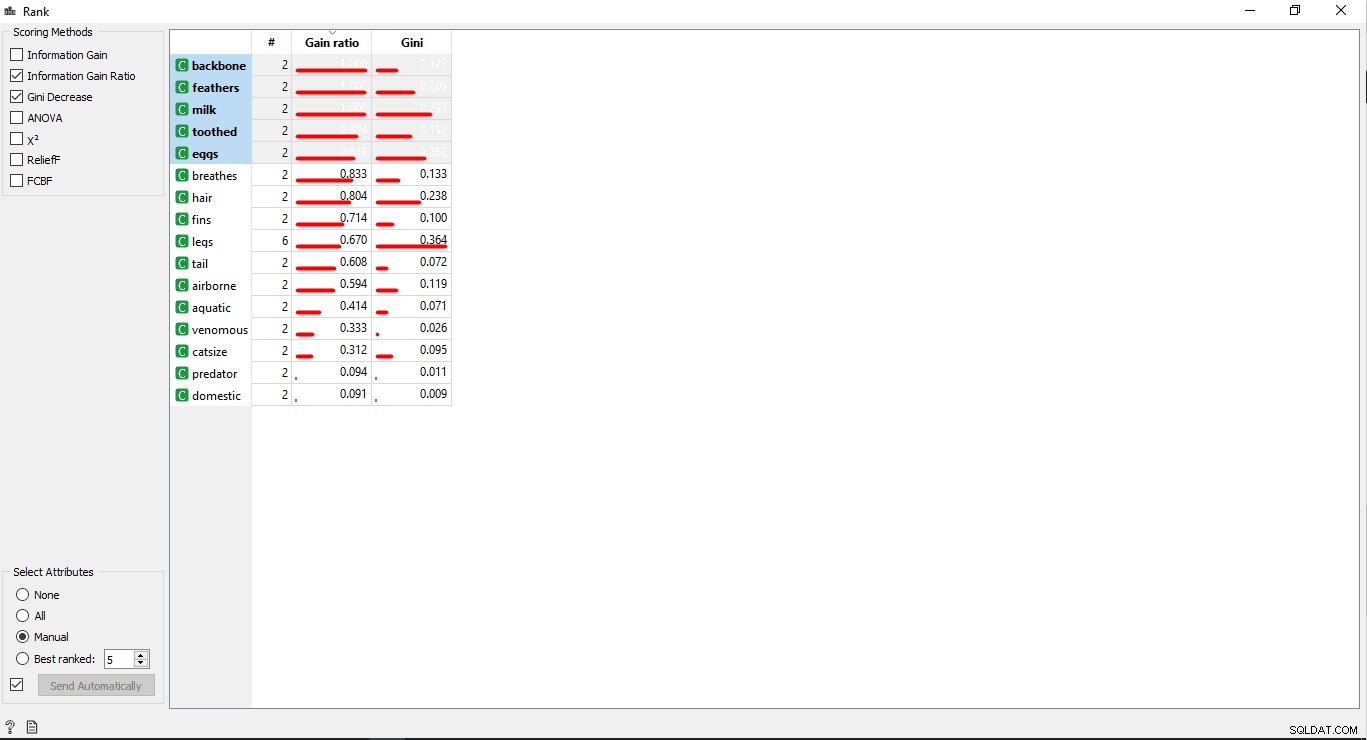
Bước 6:Xếp hạng các cột
Bạn có thể Xếp hạng hoặc Cho điểm biến / cột đào tạo theo mối tương quan của chúng với cột mục tiêu.
- Kéo và thả Xếp hạng tiện ích con từ dữ liệu menu.
- Vẽ đường liên kết từ Chọn cột tiện ích con để Xếp hạng tiện ích con.
- Nhấp đúp vào Xếp hạng tiện ích con để xem các cột liên quan nhất trong bảng dữ liệu đào tạo. Theo mặc định, nó sẽ chọn 5 cột hàng đầu.
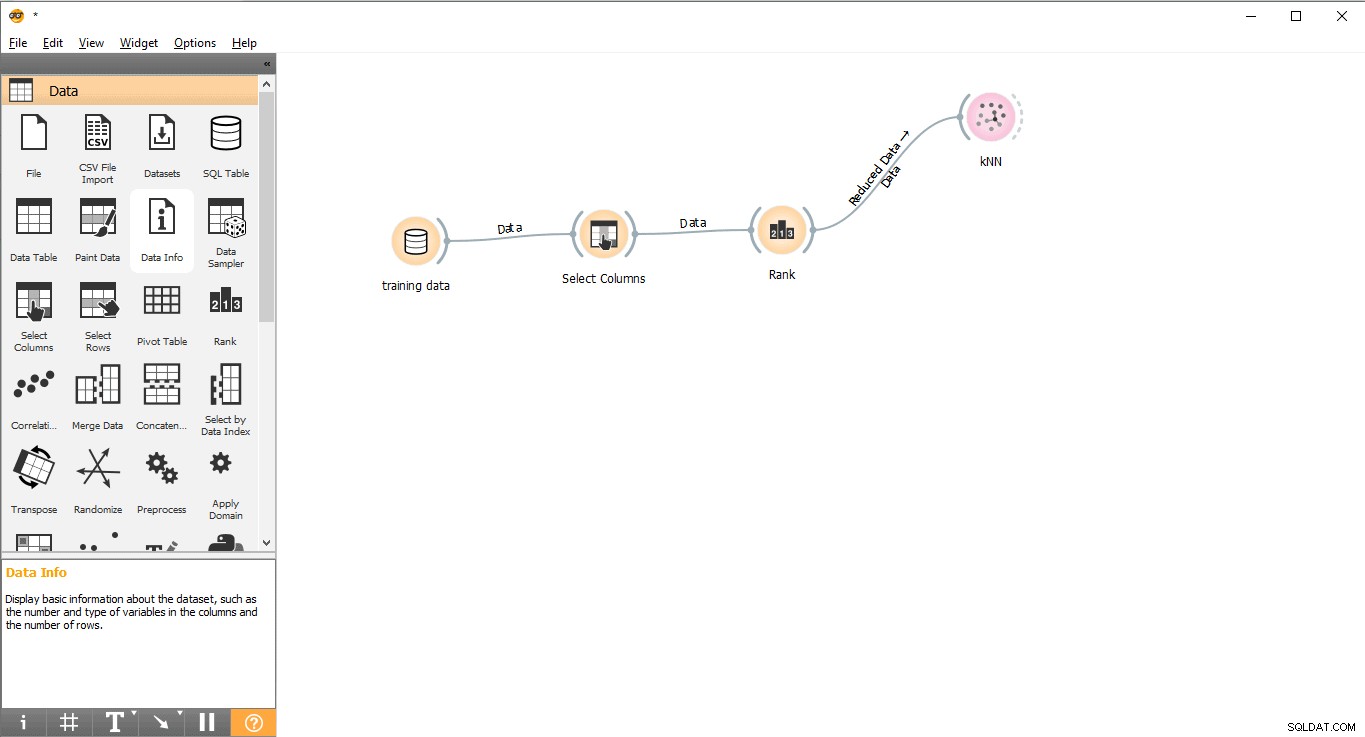
Bước 7:Đào tạo dữ liệu
Trong bước này, Mô hình học máy (KNN) sẽ được đào tạo cùng với tập dữ liệu đào tạo. Vui lòng làm theo các bước sau:
- Kéo và thả KNN tiện ích con từ Mô hình menu.
- Vẽ đường liên kết từ Xếp hạng tiện ích con cho KNN tiện ích con.
Bước 8:Tải tập dữ liệu thử nghiệm vào PostgreSQL
Một tập dữ liệu thử nghiệm riêng biệt được tạo để thực hiện các dự đoán. Vui lòng làm theo các bước để tải tập dữ liệu thử nghiệm vào bảng PostgreSQL.
- Tạo bảng để lưu trữ dữ liệu thử nghiệm của chúng tôi . Ở đây, nó được đặt tên là test_data.
CREATE TABLE test_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- Chèn dữ liệu kiểm tra vào bảng kiểm tra qua COPY truy vấn. Trước khi thực thi COPY truy vấn, vui lòng đảm bảo rằng PostgreSQL đã yêu cầu quyền đọc đối với tệp dữ liệu, nếu không hoạt động COPY sẽ không thành công.
LƯU Ý: Vui lòng đảm bảo bạn nhập tab khoảng cách giữa các dấu ngoặc kép sau dấu phân cách từ khóa. Dấu chấm hỏi được cố ý đặt trong loại cột của tập dữ liệu thử nghiệm vì chúng tôi cần tìm ra loại động vật nhất định bằng mô hình Học máy của chúng tôi.
COPY test_data FROM 'Path_to_test_data_file’ with delimiter ' ' csv header;
Vui lòng tìm ảnh chụp màn hình của tập dữ liệu thử nghiệm dưới đây

Bước 9:Nhập dữ liệu thử nghiệm từ PostgreSQL vào Orange
Vui lòng làm theo các bước sau để áp dụng các dự đoán.
- Kéo và thả Bảng SQL tiện ích con từ dữ liệu thực đơn.
- Đổi tên tiện ích con (Tùy chọn)
- Nhấp chuột phải vào Bảng SQL tiện ích con.
- Chọn Đổi tên .
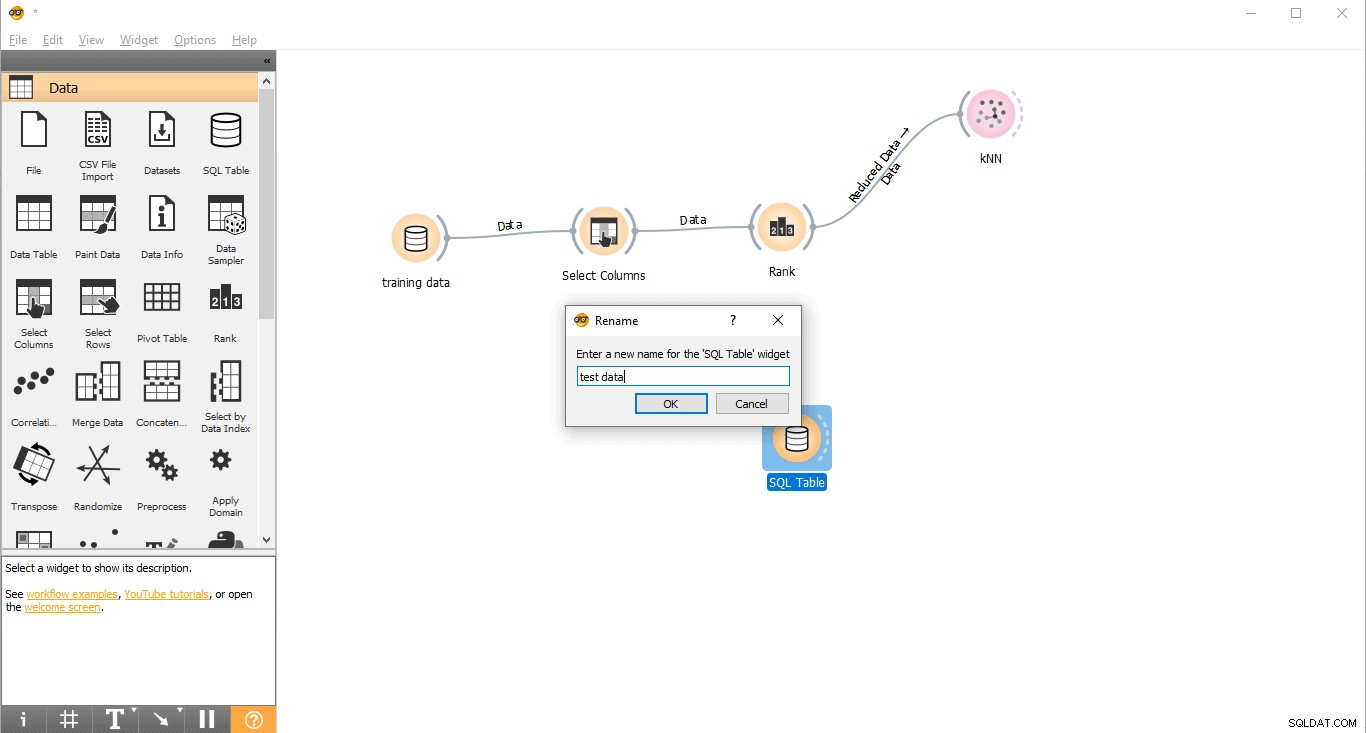
- Kết nối với PostgreSQL để tải dữ liệu thử nghiệm.
- Nhấp đúp vào Dữ liệu thử nghiệm tiện ích con.
- Kết nối nó với Dữ liệu thử nghiệm bảng từ PostgreSQL.
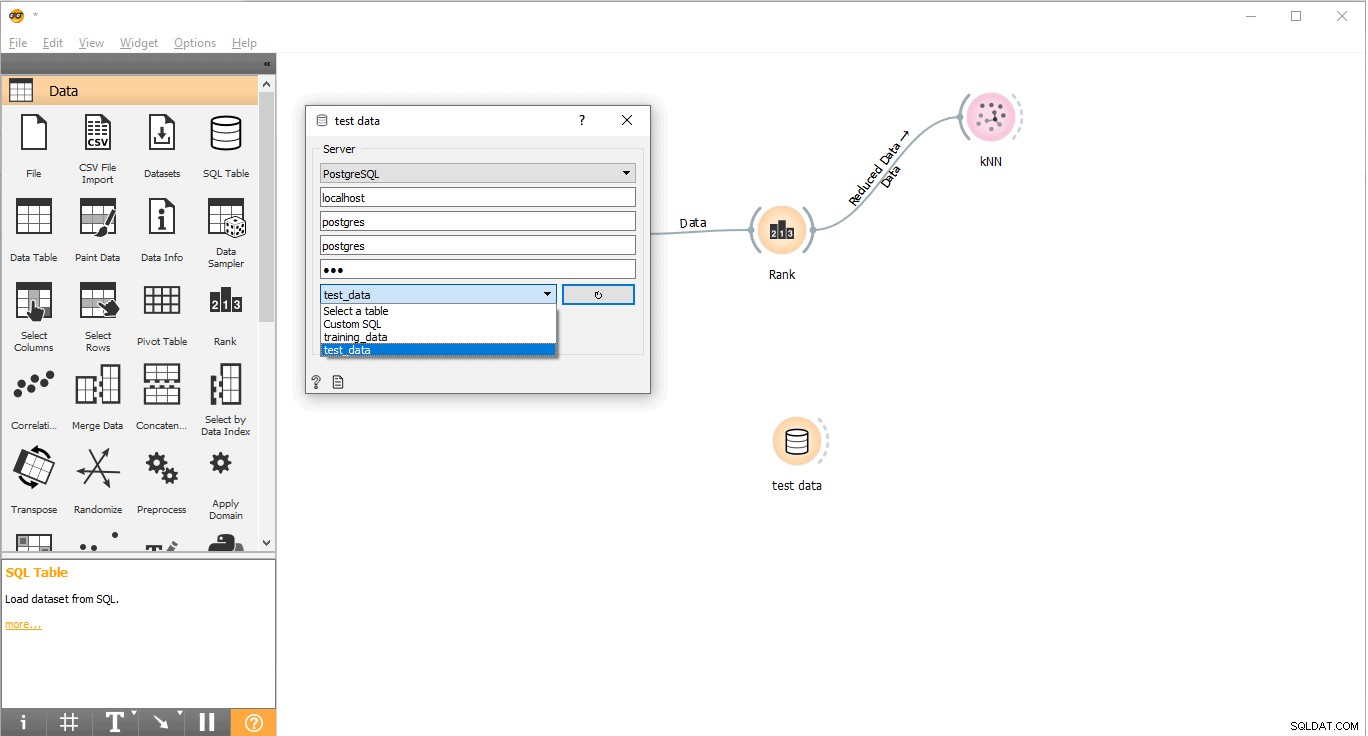
Bây giờ chúng tôi đã sẵn sàng thực hiện các dự đoán.
Bước 10:Dự đoán
Dự đoán tiện ích con sẽ cố gắng dự đoán dữ liệu kiểm tra dựa trên dữ liệu đào tạo từ KNN .
- Kéo và thả Dự đoán tiện ích con từ Đánh giá menu.
- Vẽ biểu mẫu đường liên kết Dữ liệu thử nghiệm tiện ích con cho Dự đoán tiện ích con.
- Vẽ đường liên kết từ KNN tiện ích con cho Dự đoán tiện ích con.
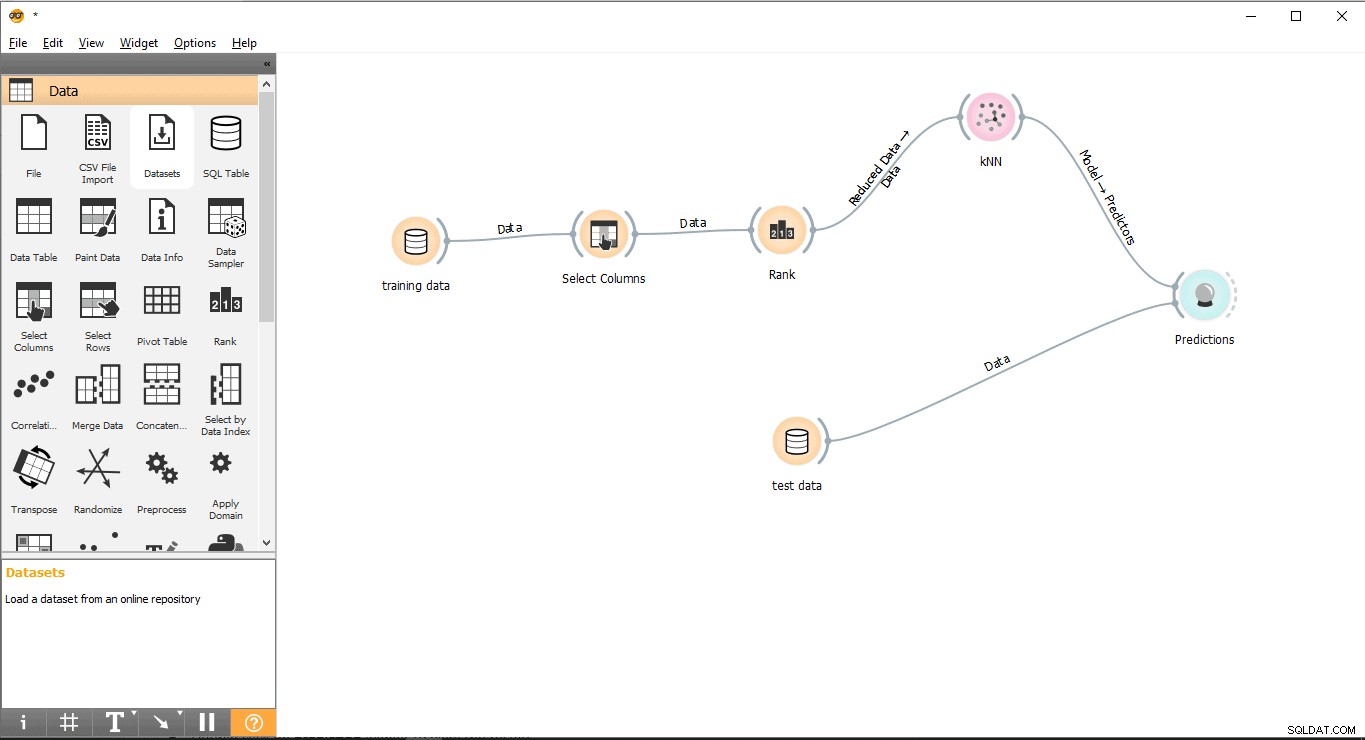
Bước 11:Kết quả
Nhấp đúp vào Dự đoán tiện ích con để xem kết quả.
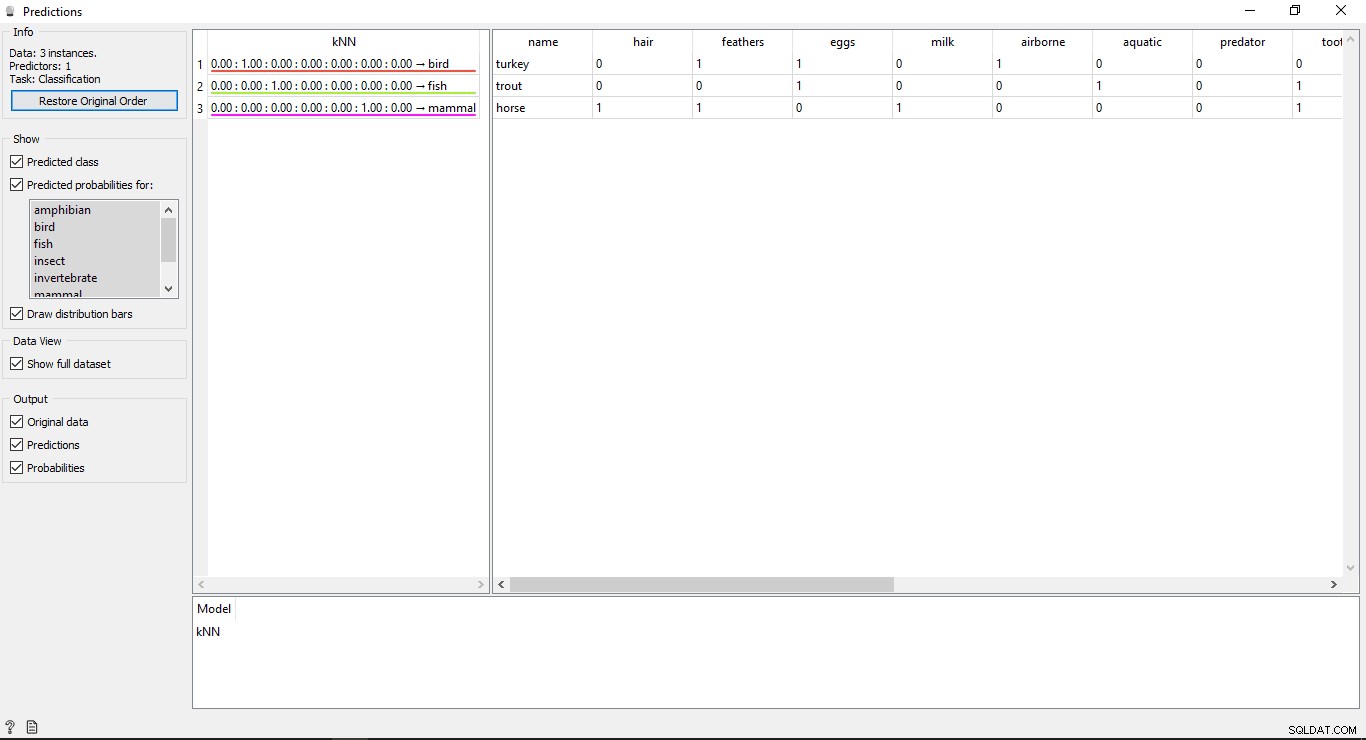
Hiểu kết quả
Bạn sẽ thấy 2 bảng chính trong cửa sổ dự đoán. Bảng bên trái hiển thị kết quả dự đoán, trong khi bảng bên phải hiển thị dữ liệu thử nghiệm ban đầu, được cung cấp cho các dự đoán.
Kể từ KNN mô hình được sử dụng để đào tạo dữ liệu, vì vậy bạn sẽ thấy một cột có tên KNN liệt kê các kết quả.
Như chúng ta biết:
- Ngựa là Động vật có vú
- Cá hồi là một Cá
- Thổ Nhĩ Kỳ là một Con chim
Vì vậy KNN có thể xác định tất cả các loại một cách chính xác.
Độ chính xác của các dự đoán
Nếu bạn nhìn thấy bảng ở phía bên trái trong đầu ra của tiện ích dự đoán, thì bảng này có một số con số trước loại dự đoán, tức là 1,00. 0,00 Những con số này cho thấy độ chính xác của loại dự đoán.
Chúng tôi đã sử dụng 7 loại động vật trong tập dữ liệu huấn luyện, vì vậy nó hiển thị tổng số 7 cột với giá trị độ chính xác, mỗi cột sẽ đại diện cho 1 loại động vật. Bạn có thể kiểm tra cột nào đại diện cho loại động vật nào bằng cách xem danh sách có sẵn ở bên trái màn hình của bạn trong Xác suất dự đoán cho nhãn. Nếu bạn nhìn vào hàng đầu tiên có nội dung Thổ Nhĩ Kỳ là một Con chim . Chúng ta có thể thấy độ chính xác của nó là 1,00 (100% từ cột thứ 2). Tương tự với các ví dụ khác Trout là một Cá và độ chính xác của nó là 1,00 (100% từ cột thứ 3).
Trong bài viết này, chúng tôi đã sử dụng thuật toán k-hàng xóm gần nhất (KNN) để triển khai mô hình Học máy. Trong blog tiếp theo, chúng tôi sẽ sử dụng Máy hỗ trợ vectơ (SVM).
Đối với bất kỳ câu hỏi hoặc nhận xét nào, vui lòng liên hệ bằng cách sử dụng biểu mẫu liên hệ tại đây.