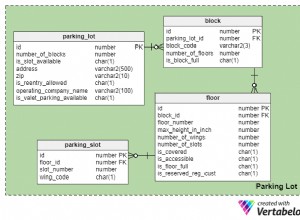
Có, nếu cơ sở dữ liệu Oracle của bạn được tạo bằng bộ ký tự Unicode, NVARCHAR trong SQL Server nên được chuyển sang VARCHAR2 trong Oracle. Trong Oracle, NVARCHAR tồn tại kiểu dữ liệu để cho phép các ứng dụng lưu trữ dữ liệu bằng cách sử dụng bộ ký tự Unicode khi bộ ký tự cơ sở dữ liệu không hỗ trợ Unicode.
Tuy nhiên, một điều cần lưu ý khi di chuyển là ngữ nghĩa độ dài ký tự. Trong SQL Server, NVARCHAR(20) phân bổ không gian cho 20 ký tự yêu cầu tối đa 40 byte trong UCS-2. Trong Oracle, theo mặc định, VARCHAR2(20) phân bổ 20 byte dung lượng lưu trữ. Trong AL32UTF8 bộ ký tự, có khả năng chỉ đủ chỗ cho 6 ký tự mặc dù rất có thể nó sẽ xử lý nhiều hơn (một ký tự trong AL32UTF8 yêu cầu từ 1 đến 3 byte. Bạn có thể muốn khai báo các loại Oracle của mình là VARCHAR2(20 CHAR) cho biết rằng bạn muốn phân bổ không gian cho 20 ký tự bất kể yêu cầu bao nhiêu byte. Điều đó có xu hướng dễ giao tiếp hơn nhiều so với việc cố gắng giải thích tại sao một số chuỗi 20 ký tự được cho phép trong khi 10 chuỗi ký tự khác bị từ chối.
Bạn có thể thay đổi ngữ nghĩa độ dài mặc định ở cấp phiên để bất kỳ bảng nào bạn tạo mà không chỉ định bất kỳ ngữ nghĩa độ dài nào sẽ sử dụng ký tự thay vì ngữ nghĩa byte
ALTER SESSION SET nls_length_semantics=CHAR;
Điều đó cho phép bạn tránh nhập CHAR mỗi khi bạn xác định một cột mới. Cũng có thể đặt điều đó ở cấp hệ thống nhưng nhóm NLS không khuyến khích làm như vậy - rõ ràng là không phải tất cả các tập lệnh mà Oracle cung cấp đều đã được kiểm tra kỹ lưỡng dựa trên cơ sở dữ liệu có NLS_LENGTH_SEMANTICS đã thay đổi. Và có lẽ rất ít tập lệnh của bên thứ ba.