Đây là một vấn đề khá phổ biến.
Đồng bằng B-Tree các chỉ mục không tốt cho các truy vấn như thế này:
SELECT measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
Chỉ mục rất tốt cho việc tìm kiếm các giá trị trong các giới hạn đã cho, như sau:
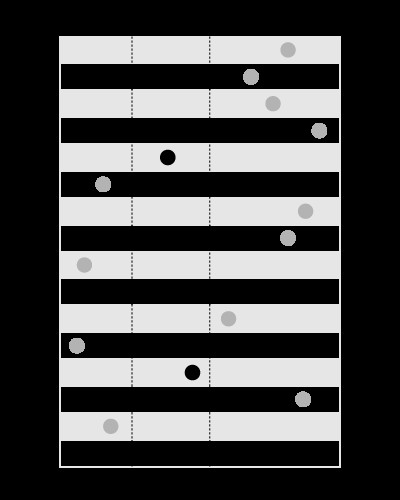
, nhưng không phải để tìm kiếm các giới hạn chứa giá trị đã cho, như thế này:
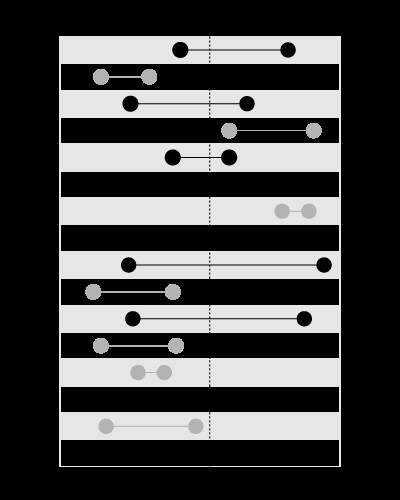
Bài viết này trong blog của tôi giải thích vấn đề chi tiết hơn:
(mô hình tập hợp lồng nhau xử lý loại vị từ tương tự).
Bạn có thể lập chỉ mục vào time , theo cách này, các intervals sẽ dẫn đầu trong phép nối, khoảng thời gian sẽ được sử dụng bên trong các vòng lặp lồng nhau. Điều này sẽ yêu cầu sắp xếp theo time .
Bạn có thể tạo chỉ mục không gian trên các khoảng thời gian intervals (có sẵn trong MySQL sử dụng MyISAM lưu trữ) sẽ bao gồm start và end trong một cột hình học. Bằng cách này, measures có thể dẫn đầu tham gia và không cần sắp xếp.
Tuy nhiên, chỉ mục không gian chậm hơn, vì vậy điều này sẽ chỉ hiệu quả nếu bạn có ít thước đo nhưng có nhiều khoảng thời gian.
Vì bạn có ít khoảng thời gian nhưng có nhiều số đo, chỉ cần đảm bảo rằng bạn có chỉ mục trên measures.time :
CREATE INDEX ix_measures_time ON measures (time)
Cập nhật:
Đây là một tập lệnh mẫu để kiểm tra:
BEGIN
DBMS_RANDOM.seed(20091223);
END;
/
CREATE TABLE intervals (
entry_time NOT NULL,
exit_time NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level,
TO_DATE('23.12.2009', 'dd.mm.yyyy') - level + DBMS_RANDOM.value
FROM dual
CONNECT BY
level <= 1500
/
CREATE UNIQUE INDEX ux_intervals_entry ON intervals (entry_time)
/
CREATE TABLE measures (
time NOT NULL,
measure NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level / 720,
CAST(DBMS_RANDOM.value * 10000 AS NUMBER(18, 2))
FROM dual
CONNECT BY
level <= 1080000
/
ALTER TABLE measures ADD CONSTRAINT pk_measures_time PRIMARY KEY (time)
/
CREATE INDEX ix_measures_time_measure ON measures (time, measure)
/
Truy vấn này:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_NL(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
sử dụng NESTED LOOPS và trả về trong 1.7 giây.
Truy vấn này:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_MERGE(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
sử dụng MERGE JOIN và tôi phải dừng nó sau 5 phút.
Cập nhật 2:
Có thể bạn sẽ cần buộc engine sử dụng đúng thứ tự bảng trong phép nối bằng cách sử dụng gợi ý như sau:
SELECT /*+ LEADING (intervals) USE_NL(intervals, measures) */
measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
Oracle Trình tối ưu hóa của không đủ thông minh để thấy rằng các khoảng thời gian không giao nhau. Đó là lý do tại sao nó có thể sẽ sử dụng measures như một bảng dẫn đầu (sẽ là một quyết định khôn ngoan nếu các khoảng cắt nhau).
Cập nhật 3:
WITH splits AS
(
SELECT /*+ MATERIALIZE */
entry_range, exit_range,
exit_range - entry_range + 1 AS range_span,
entry_time, exit_time
FROM (
SELECT TRUNC((entry_time - TO_DATE(1, 'J')) * 2) AS entry_range,
TRUNC((exit_time - TO_DATE(1, 'J')) * 2) AS exit_range,
entry_time,
exit_time
FROM intervals
)
),
upper AS
(
SELECT /*+ MATERIALIZE */
MAX(range_span) AS max_range
FROM splits
),
ranges AS
(
SELECT /*+ MATERIALIZE */
level AS chunk
FROM upper
CONNECT BY
level <= max_range
),
tiles AS
(
SELECT /*+ MATERIALIZE USE_MERGE (r s) */
entry_range + chunk - 1 AS tile,
entry_time,
exit_time
FROM ranges r
JOIN splits s
ON chunk <= range_span
)
SELECT /*+ LEADING(t) USE_HASH(m t) */
SUM(LENGTH(stuffing))
FROM tiles t
JOIN measures m
ON TRUNC((m.time - TO_DATE(1, 'J')) * 2) = tile
AND m.time BETWEEN t.entry_time AND t.exit_time
Truy vấn này chia trục thời gian thành các phạm vi và sử dụng HASH JOIN để kết hợp các thước đo và dấu thời gian trên các giá trị phạm vi, với tính năng lọc tốt sau này.
Xem bài viết này trong blog của tôi để biết giải thích chi tiết hơn về cách nó hoạt động: