Bố cục bảng
Thiết kế lại bảng để lưu trữ giờ mở cửa (giờ hoạt động) dưới dạng tập hợp tsrange (phạm vi timestamp without time zone ) các giá trị. Yêu cầu Postgres 9.2 trở lên .
Chọn một tuần ngẫu nhiên để phân chia giờ mở cửa của bạn. Tôi thích tuần:
1996-01-01 (Thứ Hai) đến 1996-01-07 (Chủ nhật)
Đó là năm nhuận gần đây nhất mà ngày 1 tháng 1 thuận tiện trở thành ngày thứ Hai. Nhưng nó có thể là bất kỳ tuần ngẫu nhiên nào đối với trường hợp này. Chỉ cần nhất quán.
Cài đặt mô-đun bổ sung btree_gist đầu tiên:
CREATE EXTENSION btree_gist;
Xem:
- Tương đương với ràng buộc loại trừ bao gồm số nguyên và dải ô
Sau đó, tạo bảng như sau:
CREATE TABLE hoo (
hoo_id serial PRIMARY KEY
, shop_id int NOT NULL -- REFERENCES shop(shop_id) -- reference to shop
, hours tsrange NOT NULL
, CONSTRAINT hoo_no_overlap EXCLUDE USING gist (shop_id with =, hours WITH &&)
, CONSTRAINT hoo_bounds_inclusive CHECK (lower_inc(hours) AND upper_inc(hours))
, CONSTRAINT hoo_standard_week CHECK (hours <@ tsrange '[1996-01-01 0:0, 1996-01-08 0:0]')
);
Cái một cột hours thay thế tất cả các cột của bạn:
opens_on, closes_on, opens_at, closes_atVí dụ:giờ hoạt động từ Thứ Tư, 18:30 đến Thứ Năm, 05:00 UTC được nhập là:
'[1996-01-03 18:30, 1996-01-04 05:00]'
Ràng buộc loại trừ hoo_no_overlap ngăn chặn các mục nhập trùng lặp cho mỗi cửa hàng. Nó được triển khai với chỉ mục GiST , điều này cũng xảy ra để hỗ trợ các truy vấn của chúng tôi. Hãy xem xét chương "Chỉ mục và Hiệu suất" bên dưới thảo luận về các chiến lược lập chỉ mục.
Ràng buộc kiểm tra hoo_bounds_inclusive thực thi các ranh giới bao trùm cho các phạm vi của bạn, với hai hậu quả đáng chú ý:
- Luôn bao gồm một thời điểm rơi vào ranh giới phía dưới hoặc phía trên chính xác.
- Các mục nhập liền kề cho cùng một cửa hàng thực sự không được phép. Với các giới hạn bao gồm, những giới hạn đó sẽ "chồng chéo" và ràng buộc loại trừ sẽ tạo ra một ngoại lệ. Thay vào đó, các mục nhập liền kề phải được hợp nhất thành một hàng. Ngoại trừ khi họ quấn quanh nửa đêm Chủ nhật , trong trường hợp đó chúng phải được chia thành hai hàng. Hàm
f_hoo_hours()bên dưới giải quyết vấn đề này.
Ràng buộc kiểm tra hoo_standard_week thực thi các giới hạn bên ngoài của tuần dàn dựng bằng cách sử dụng toán tử "phạm vi được chứa bởi" <@ .
Với bao gồm giới hạn, bạn phải quan sát trường hợp góc thời gian kết thúc vào lúc nửa đêm Chủ Nhật:
'1996-01-01 00:00+0' = '1996-01-08 00:00+0'
Mon 00:00 = Sun 24:00 (= next Mon 00:00)
Bạn phải tìm kiếm cả hai dấu thời gian cùng một lúc. Đây là một trường hợp liên quan với độc quyền giới hạn trên sẽ không thể hiện thiếu sót này:
- Ngăn các mục nhập liền kề / chồng chéo với EXCLUDE trong PostgreSQL
Hàm f_hoo_time(timestamptz)
Để "chuẩn hóa" bất kỳ timestamp with time zone :
CREATE OR REPLACE FUNCTION f_hoo_time(timestamptz)
RETURNS timestamp
LANGUAGE sql IMMUTABLE PARALLEL SAFE AS
$func$
SELECT timestamp '1996-01-01' + ($1 AT TIME ZONE 'UTC' - date_trunc('week', $1 AT TIME ZONE 'UTC'))
$func$;
PARALLEL SAFE chỉ dành cho Postgres 9.6 trở lên.
Hàm lấy timestamptz và trả về timestamp . Nó thêm khoảng thời gian đã trôi qua của tuần tương ứng ($1 - date_trunc('week', $1) theo giờ UTC đến thời điểm bắt đầu trong tuần diễn ra của chúng tôi. (date + interval tạo ra timestamp .)
Hàm f_hoo_hours(timestamptz, timestamptz)
Để chuẩn hóa các phạm vi và tách các phạm vi đó qua Thứ Hai 00:00. Hàm này có khoảng thời gian bất kỳ (dưới dạng hai timestamptz ) và tạo ra một hoặc hai tsrange được chuẩn hóa các giá trị. Nó bao gồm bất kỳ đầu vào hợp pháp và không cho phép phần còn lại:
CREATE OR REPLACE FUNCTION f_hoo_hours(_from timestamptz, _to timestamptz)
RETURNS TABLE (hoo_hours tsrange)
LANGUAGE plpgsql IMMUTABLE PARALLEL SAFE COST 500 ROWS 1 AS
$func$
DECLARE
ts_from timestamp := f_hoo_time(_from);
ts_to timestamp := f_hoo_time(_to);
BEGIN
-- sanity checks (optional)
IF _to <= _from THEN
RAISE EXCEPTION '%', '_to must be later than _from!';
ELSIF _to > _from + interval '1 week' THEN
RAISE EXCEPTION '%', 'Interval cannot span more than a week!';
END IF;
IF ts_from > ts_to THEN -- split range at Mon 00:00
RETURN QUERY
VALUES (tsrange('1996-01-01', ts_to , '[]'))
, (tsrange(ts_from, '1996-01-08', '[]'));
ELSE -- simple case: range in standard week
hoo_hours := tsrange(ts_from, ts_to, '[]');
RETURN NEXT;
END IF;
RETURN;
END
$func$;
Tới INSERT một đơn hàng đầu vào:
INSERT INTO hoo(shop_id, hours)
SELECT 123, f_hoo_hours('2016-01-11 00:00+04', '2016-01-11 08:00+04');
Đối với bất kỳ số hàng đầu vào:
INSERT INTO hoo(shop_id, hours)
SELECT id, f_hoo_hours(f, t)
FROM (
VALUES (7, timestamptz '2016-01-11 00:00+0', timestamptz '2016-01-11 08:00+0')
, (8, '2016-01-11 00:00+1', '2016-01-11 08:00+1')
) t(id, f, t);
Mỗi hàng có thể chèn hai hàng nếu một dải ô cần tách vào Thứ Hai 00:00 UTC.
Truy vấn
Với thiết kế đã điều chỉnh, toàn bộ truy vấn lớn, phức tạp, đắt tiền của bạn có thể được thay thế bằng ... this:
SELECT *
FROM hoo
WHERE hours @> f_hoo_time(now());
Để có một chút hồi hộp, tôi đặt một tấm spoiler lên trên dung dịch. Di chuyển chuột qua nó.
Truy vấn được hỗ trợ bởi chỉ mục GiST đã nói và nhanh chóng, ngay cả đối với các bảng lớn.
db <> fiddle here (với nhiều ví dụ hơn)
Old sqlfiddle
Nếu bạn muốn tính tổng số giờ mở cửa (mỗi cửa hàng), đây là công thức:
- Tính giờ làm việc giữa 2 ngày trong PostgreSQL
Chỉ mục và Hiệu suất
Toán tử ngăn chặn cho các loại phạm vi có thể được hỗ trợ bằng GiST hoặc SP-GiST mục lục. Có thể sử dụng cả hai để triển khai ràng buộc loại trừ, nhưng chỉ GiST mới hỗ trợ các chỉ mục đa cột:
Hiện tại, chỉ các loại chỉ mục B-tree, GiST, GIN và BRIN hỗ trợ chỉ mục đa cột.
Và thứ tự của các cột chỉ mục quan trọng:
Chỉ mục GiST nhiều cột có thể được sử dụng với các điều kiện truy vấn để giải quyết bất kỳ tập con nào trong số các cột của chỉ mục. Điều kiện trên các cột bổ sung hạn chế các mục nhập được chỉ mục trả về, nhưng điều kiện cột đầu tiên là điều kiện quan trọng nhất để xác định cách mà chỉ mục cần được quét. Chỉ mục GiST sẽ tương đối hiệu quả nếu cột đầu tiên của nó chỉ có một vài giá trị riêng biệt, nếu có nhiều giá trị khác biệt trong các cột bổ sung.
Vì vậy, chúng tôi có lợi ích xung đột đây. Đối với các bảng lớn, sẽ có nhiều giá trị khác biệt hơn cho shop_id hơn trong hours .
- Chỉ mục GiST với
shop_idđứng đầu viết nhanh hơn và thực thi ràng buộc loại trừ. - Nhưng chúng tôi đang tìm kiếm
hourstrong truy vấn của chúng tôi. Có cột đó trước sẽ tốt hơn. - Nếu chúng tôi cần tra cứu
shop_idtrong các truy vấn khác, chỉ mục btree thuần túy sẽ nhanh hơn nhiều. - Đầu tiên, tôi đã tìm thấy SP-GiST lập chỉ mục chỉ trong
hourstrở nên nhanh nhất cho truy vấn.
Điểm chuẩn
Thử nghiệm mới với Postgres 12 trên một máy tính xách tay cũ. Tập lệnh của tôi để tạo dữ liệu giả:
INSERT INTO hoo(shop_id, hours)
SELECT id
, f_hoo_hours(((date '1996-01-01' + d) + interval '4h' + interval '15 min' * trunc(32 * random())) AT TIME ZONE 'UTC'
, ((date '1996-01-01' + d) + interval '12h' + interval '15 min' * trunc(64 * random() * random())) AT TIME ZONE 'UTC')
FROM generate_series(1, 30000) id
JOIN generate_series(0, 6) d ON random() > .33;
Kết quả trong ~ 141 nghìn hàng được tạo ngẫu nhiên, ~ 30 nghìn shop_id khác biệt , ~ 12k hours riêng biệt . Kích thước bảng 8 MB.
Tôi đã bỏ và tạo lại ràng buộc loại trừ:
ALTER TABLE hoo
DROP CONSTRAINT hoo_no_overlap
, ADD CONSTRAINT hoo_no_overlap EXCLUDE USING gist (shop_id WITH =, hours WITH &&); -- 3.5 sec; index 8 MB
ALTER TABLE hoo
DROP CONSTRAINT hoo_no_overlap
, ADD CONSTRAINT hoo_no_overlap EXCLUDE USING gist (hours WITH &&, shop_id WITH =); -- 13.6 sec; index 12 MB
shop_id đầu tiên là nhanh hơn ~ 4 lần cho bản phân phối này.
Ngoài ra, tôi đã thử nghiệm thêm hai lần nữa để kiểm tra hiệu suất đọc:
CREATE INDEX hoo_hours_gist_idx on hoo USING gist (hours);
CREATE INDEX hoo_hours_spgist_idx on hoo USING spgist (hours); -- !!
Sau khi VACUUM FULL ANALYZE hoo; , Tôi đã chạy hai truy vấn:
- Q1 :đêm muộn, chỉ tìm thấy 35 hàng
- Quý 2 :vào buổi chiều, tìm thấy 4547 hàng .
Kết quả
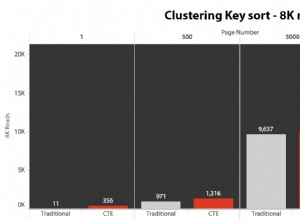
Có một bản quét chỉ lập chỉ mục cho mỗi (tất nhiên là ngoại trừ "không có chỉ mục"):
index idx size Q1 Q2
------------------------------------------------
no index 38.5 ms 38.5 ms
gist (shop_id, hours) 8MB 17.5 ms 18.4 ms
gist (hours, shop_id) 12MB 0.6 ms 3.4 ms
gist (hours) 11MB 0.3 ms 3.1 ms
spgist (hours) 9MB 0.7 ms 1.8 ms -- !
- SP-GiST và GiST ngang nhau đối với các truy vấn tìm kiếm ít kết quả (GiST thậm chí còn nhanh hơn đối với very ít).
- SP-GiST mở rộng quy mô tốt hơn với số lượng kết quả ngày càng tăng và quy mô cũng nhỏ hơn.
Nếu bạn đọc nhiều hơn những gì bạn viết (trường hợp sử dụng điển hình), hãy giữ giới hạn loại trừ như được đề xuất ngay từ đầu và tạo chỉ mục SP-GiST bổ sung để tối ưu hóa hiệu suất đọc.