Phân trang là một trường hợp sử dụng phổ biến trong các ứng dụng khách và ứng dụng web ở mọi nơi. Google hiển thị cho bạn 10 kết quả cùng một lúc, ngân hàng trực tuyến của bạn có thể hiển thị 20 hóa đơn trên mỗi trang và phần mềm theo dõi lỗi và kiểm soát nguồn có thể hiển thị 50 mặt hàng trên màn hình.
Tôi muốn xem xét cách tiếp cận phân trang phổ biến trên SQL Server 2012 - OFFSET / FETCH (một tiêu chuẩn tương đương với mệnh đề LIMIT cơ bản của MySQL) - và đề xuất một biến thể sẽ dẫn đến hiệu suất phân trang tuyến tính hơn trên toàn bộ tập hợp, thay vì chỉ tối ưu lúc bắt đầu. Điều đáng buồn là rất nhiều cửa hàng sẽ thử nghiệm.
Phân trang trong SQL Server là gì?
Dựa trên việc lập chỉ mục của bảng, các cột cần thiết và phương pháp sắp xếp đã chọn, việc phân trang có thể tương đối dễ dàng. Nếu bạn đang tìm kiếm 20 khách hàng "đầu tiên" và chỉ mục được phân nhóm hỗ trợ việc sắp xếp đó (giả sử, chỉ mục được phân nhóm trên cột IDENTITY hoặc cột Được tạo theo ngày tháng), thì truy vấn sẽ tương đối hiệu quả. Nếu bạn cần hỗ trợ sắp xếp yêu cầu các chỉ mục không phân cụm và đặc biệt nếu bạn có các cột cần thiết cho đầu ra không được chỉ mục bao phủ (đừng bận tâm nếu không có chỉ mục hỗ trợ), các truy vấn có thể đắt hơn. Và ngay cả cùng một truy vấn (với một tham số @PageNumber khác) có thể đắt hơn nhiều khi @PageNumber cao hơn - vì có thể cần nhiều lần đọc hơn để đến được "phần" dữ liệu đó.
Một số người sẽ nói rằng tiến triển về cuối tập hợp là điều mà bạn có thể giải quyết bằng cách tăng thêm bộ nhớ cho vấn đề (vì vậy bạn loại bỏ mọi I / O vật lý) và / hoặc sử dụng bộ nhớ đệm cấp ứng dụng (vì vậy bạn sẽ không cơ sở dữ liệu). Hãy giả sử cho mục đích của bài đăng này rằng không phải lúc nào cũng có thể có thêm bộ nhớ, vì không phải khách hàng nào cũng có thể thêm RAM vào máy chủ ngoài khe cắm bộ nhớ hoặc không nằm trong tầm kiểm soát của họ, hoặc chỉ cần búng tay là đã có sẵn các máy chủ mới hơn, lớn hơn đi. Đặc biệt là vì một số khách hàng đang sử dụng Phiên bản Tiêu chuẩn, do đó, bị giới hạn ở 64GB (SQL Server 2012) hoặc 128GB (SQL Server 2014) hoặc đang sử dụng các phiên bản thậm chí còn hạn chế hơn như Express (1GB) hoặc một trong nhiều dịch vụ đám mây.
Vì vậy, tôi muốn xem xét cách tiếp cận phân trang phổ biến trên SQL Server 2012 - OFFSET / FETCH - và đề xuất một biến thể sẽ dẫn đến hiệu suất phân trang tuyến tính hơn trên toàn bộ tập hợp, thay vì chỉ tối ưu ở phần đầu. Điều đáng buồn là rất nhiều cửa hàng sẽ thử nghiệm.
Thiết lập dữ liệu phân trang / Ví dụ
Tôi sẽ mượn từ một bài đăng khác, Thói quen xấu:Chỉ tập trung vào dung lượng ổ đĩa khi chọn khóa, trong đó tôi điền vào bảng sau với 1.000.000 hàng dữ liệu khách hàng ngẫu nhiên (nhưng không hoàn toàn thực tế):
CREATE TABLE [dbo].[Customers_I] ( [CustomerID] [int] IDENTITY(1,1) NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT ((1)), [Created] [datetime] NOT NULL DEFAULT (sysdatetime()), [Updated] [datetime] NULL, CONSTRAINT [C_PK_Customers_I] PRIMARY KEY CLUSTERED ([CustomerID] ASC) ); GO CREATE NONCLUSTERED INDEX [C_Active_Customers_I] ON [dbo].[Customers_I] ([FirstName] ASC, [LastName] ASC, [EMail] ASC) WHERE ([Active] = 1); GO CREATE UNIQUE NONCLUSTERED INDEX [C_Email_Customers_I] ON [dbo].[Customers_I] ([EMail] ASC); GO CREATE NONCLUSTERED INDEX [C_Name_Customers_I] ON [dbo].[Customers_I] ([LastName] ASC, [FirstName] ASC) INCLUDE ([EMail]); GO
Vì tôi biết mình sẽ kiểm tra I / O ở đây và sẽ kiểm tra từ cả bộ đệm nóng và lạnh, tôi đã thực hiện bài kiểm tra ít nhất một chút công bằng hơn bằng cách xây dựng lại tất cả các chỉ mục để giảm thiểu sự phân mảnh (như sẽ được thực hiện ít hơn một cách gián đoạn, nhưng thường xuyên, trên hầu hết các hệ thống bận rộn đang thực hiện bất kỳ loại bảo trì chỉ mục nào):
ALTER INDEX ALL ON dbo.Customers_I REBUILD WITH (ONLINE = ON);
Sau khi xây dựng lại, phân mảnh hiện ở mức 0,05% - 0,17% cho tất cả các chỉ mục (cấp chỉ mục =0), các trang được lấp đầy hơn 99% và số hàng / số trang cho các chỉ mục như sau:
| Chỉ mục | Số lượng trang | Số lượng hàng |
|---|---|---|
| C_PK_Customers_I (chỉ mục theo nhóm) | 19.210 | 1.000.000 |
| C_Email_Customers_I | 7.344 | 1.000.000 |
| C_Active_Customers_I (chỉ mục được lọc) | 13.648 | 815.235 |
| C_Name_Customers_I | 16.824 | 1.000.000 |
Chỉ mục, số trang, số hàng
Đây rõ ràng không phải là một bảng siêu rộng và lần này tôi đã để nén ra khỏi bức tranh. Có lẽ tôi sẽ khám phá nhiều cấu hình hơn trong một thử nghiệm trong tương lai.
Cách phân trang hiệu quả một truy vấn SQL
Khái niệm phân trang - chỉ hiển thị cho người dùng các hàng tại một thời điểm - dễ hình dung hơn là giải thích. Hãy nghĩ đến mục lục của một cuốn sách vật lý, có thể có nhiều trang tham chiếu đến các điểm trong cuốn sách, nhưng được sắp xếp theo thứ tự bảng chữ cái. Để đơn giản, giả sử rằng mười mục phù hợp trên mỗi trang của chỉ mục. Điều này có thể trông giống như sau:
Bây giờ, nếu tôi đã đọc trang 1 và 2 của mục lục, tôi biết rằng để đến trang 3, tôi cần phải bỏ qua 2 trang. Nhưng vì tôi biết rằng có 10 mục trên mỗi trang, tôi cũng có thể coi đây là việc bỏ qua 2 x 10 mục và bắt đầu từ mục thứ 21. Hay nói cách khác, tôi cần bỏ qua (10 * (3-1)) mục đầu tiên. Để làm cho điều này chung chung hơn, tôi có thể nói rằng để bắt đầu từ trang n, tôi cần bỏ qua (10 * (n-1)) mục đầu tiên. Để đến trang đầu tiên, tôi bỏ qua 10 * (1-1) mục, để kết thúc ở mục 1. Để đến trang thứ hai, tôi bỏ qua 10 * (2-1) mục, để kết thúc ở mục 11. Và như vậy trên.
Với thông tin đó, người dùng sẽ hình thành một truy vấn phân trang như thế này, vì các mệnh đề OFFSET / FETCH được thêm vào SQL Server 2012 được thiết kế đặc biệt để bỏ qua nhiều hàng đó:
SELECT [a_bunch_of_columns] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY;
Như tôi đã đề cập ở trên, điều này hoạt động tốt nếu có một chỉ mục hỗ trợ ORDER BY và bao gồm tất cả các cột trong mệnh đề SELECT (và đối với các truy vấn phức tạp hơn, mệnh đề WHERE và JOIN). Tuy nhiên, chi phí sắp xếp có thể cao ngất ngưởng khi không có chỉ mục hỗ trợ và nếu các cột đầu ra không được bao phủ, bạn sẽ kết thúc với toàn bộ các tra cứu chính hoặc thậm chí bạn có thể nhận được bảng quét trong một số trường hợp.
Sắp xếp các phương pháp hay nhất về phân trang SQL
Với bảng và các chỉ mục ở trên, tôi muốn kiểm tra các tình huống này, trong đó chúng tôi muốn hiển thị 100 hàng trên mỗi trang và xuất tất cả các cột trong bảng:
- Mặc định -
ORDER BY CustomerID(chỉ mục theo cụm). Đây là cách sắp xếp thuận tiện nhất cho những người làm trong cơ sở dữ liệu, vì nó không yêu cầu sắp xếp bổ sung và tất cả dữ liệu từ bảng này có thể cần thiết để hiển thị đều được đưa vào. Mặt khác, đây có thể không phải là chỉ mục hiệu quả nhất để sử dụng nếu bạn đang hiển thị một tập hợp con của bảng. Lệnh này cũng có thể không có ý nghĩa đối với người dùng cuối, đặc biệt nếu CustomerID là mã định danh thay thế không có ý nghĩa bên ngoài. - Danh bạ -
ORDER BY LastName, FirstName(hỗ trợ chỉ mục không phân cụm). Đây là thứ tự trực quan nhất cho người dùng, nhưng sẽ yêu cầu một chỉ mục không phân cụm để hỗ trợ cả phân loại và phạm vi. Nếu không có chỉ mục hỗ trợ, toàn bộ bảng sẽ phải được quét. - Do người dùng xác định -
ORDER BY FirstName DESC, EMail(không có chỉ số hỗ trợ). Điều này thể hiện khả năng người dùng chọn bất kỳ thứ tự sắp xếp nào mà họ muốn, một mẫu mà Michael J. Swart cảnh báo trong "Các mẫu thiết kế giao diện người dùng không theo quy mô".
Tôi muốn thử nghiệm các phương pháp này và so sánh các kế hoạch và số liệu khi - trong cả tình huống bộ đệm nóng và bộ đệm lạnh - xem trang 1, trang 500, trang 5.000 và trang 9.999. Tôi đã tạo các thủ tục này (chỉ khác điều khoản ORDER BY):
CREATE PROCEDURE dbo.Pagination_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Pagination_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Pagination_Test_3 -- ORDER BY FirstName DESC, EMail Trong thực tế, bạn có thể sẽ chỉ có một thủ tục sử dụng SQL động (như trong ví dụ về "bồn rửa nhà bếp" của tôi) hoặc biểu thức CASE để ra lệnh.
Trong cả hai trường hợp, bạn có thể thấy kết quả tốt nhất bằng cách sử dụng TÙY CHỌN (RECOMPILE) trên truy vấn để tránh sử dụng lại các kế hoạch tối ưu cho một tùy chọn sắp xếp nhưng không phải tất cả. Tôi đã tạo các thủ tục riêng biệt ở đây để loại bỏ các biến đó; Tôi đã thêm TÙY CHỌN (RECOMPILE) cho các thử nghiệm này để tránh xa tính năng dò tìm tham số và các vấn đề tối ưu hóa khác mà không xóa liên tục toàn bộ bộ nhớ cache của kế hoạch.
Một cách tiếp cận thay thế để phân trang SQL Server để có hiệu suất tốt hơn
Một cách tiếp cận hơi khác, mà tôi không thấy được triển khai thường xuyên, là xác định vị trí "trang" mà chúng tôi đang truy cập chỉ bằng cách sử dụng khóa phân cụm và sau đó kết hợp với trang đó:
;WITH pg AS ( SELECT [key_column] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY ) SELECT t.[bunch_of_columns] FROM dbo.[some_table] AS t INNER JOIN pg ON t.[key_column] = pg.[key_column] -- or EXISTS ORDER BY [some_column_or_columns];
Tất nhiên, đó là mã dài dòng hơn, nhưng hy vọng rằng nó rõ ràng SQL Server có thể bị ép buộc làm gì:tránh quét hoặc ít nhất là trì hoãn tra cứu cho đến khi tập hợp kết quả nhỏ hơn nhiều. Paul White (@SQL_Kiwi) đã điều tra một cách tiếp cận tương tự vào năm 2010, trước khi OFFSET / FETCH được giới thiệu trong phiên bản SQL Server 2012 đầu tiên (lần đầu tiên tôi viết blog về nó vào cuối năm đó).
Với các tình huống ở trên, tôi đã tạo thêm ba thủ tục, với sự khác biệt duy nhất giữa (các) cột được chỉ định trong mệnh đề ORDER BY (bây giờ chúng ta cần hai, một cho chính trang và một để sắp xếp kết quả):
CREATE PROCEDURE dbo.Alternate_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
;WITH pg AS
(
SELECT CustomerID
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.Customers_I AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY c.CustomerID OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Alternate_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Alternate_Test_3 -- ORDER BY FirstName DESC, EMail Lưu ý:Điều này có thể không hoạt động tốt nếu khóa chính của bạn không được nhóm lại - một phần của thủ thuật giúp điều này hoạt động tốt hơn, khi một chỉ mục hỗ trợ có thể được sử dụng, là khóa phân cụm đã có trong chỉ mục, vì vậy thường tránh tra cứu.
Kiểm tra loại khóa phân cụm
Đầu tiên, tôi đã thử nghiệm trường hợp mà tôi không mong đợi nhiều sự khác biệt giữa hai phương pháp - sắp xếp theo khóa phân cụm. Tôi đã chạy các câu lệnh này trong một loạt trong SQL Sentry Plan Explorer và quan sát thời lượng, lần đọc và các kế hoạch đồ họa, đảm bảo rằng mỗi truy vấn đều bắt đầu từ một bộ nhớ cache hoàn toàn nguội:
SET NOCOUNT ON; -- default method DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 9999; -- alternate method DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 9999;
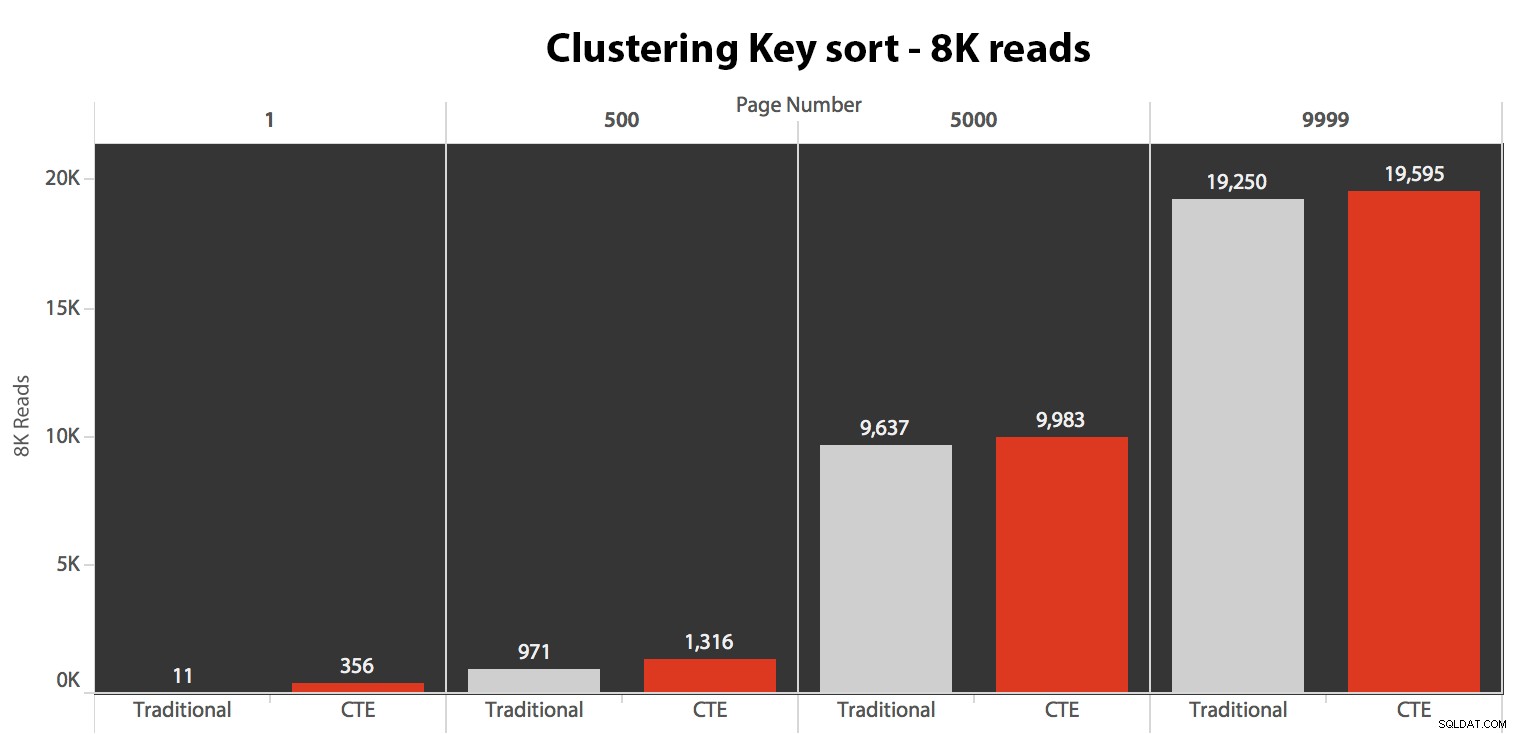
Kết quả ở đây không đáng kinh ngạc. Trên 5 lần thực thi, số lần đọc trung bình được hiển thị ở đây, cho thấy sự khác biệt không đáng kể giữa hai truy vấn, trên tất cả các số trang, khi sắp xếp theo khóa phân cụm:
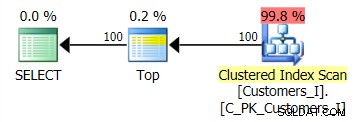
Kế hoạch cho phương pháp mặc định (như được hiển thị trong Plan Explorer) trong mọi trường hợp như sau:
Mặc dù kế hoạch cho phương pháp dựa trên CTE trông như thế này:
Bây giờ, trong khi I / O giống nhau bất kể bộ nhớ đệm (chỉ đọc thêm nhiều lần đọc trước trong kịch bản bộ đệm lạnh), tôi đã đo thời lượng bằng bộ đệm lạnh và cũng bằng bộ đệm ấm (nơi tôi nhận xét về các lệnh DROPCLEANBUFFERS và chạy các truy vấn nhiều lần trước khi đo). Các khoảng thời gian này trông như thế này:
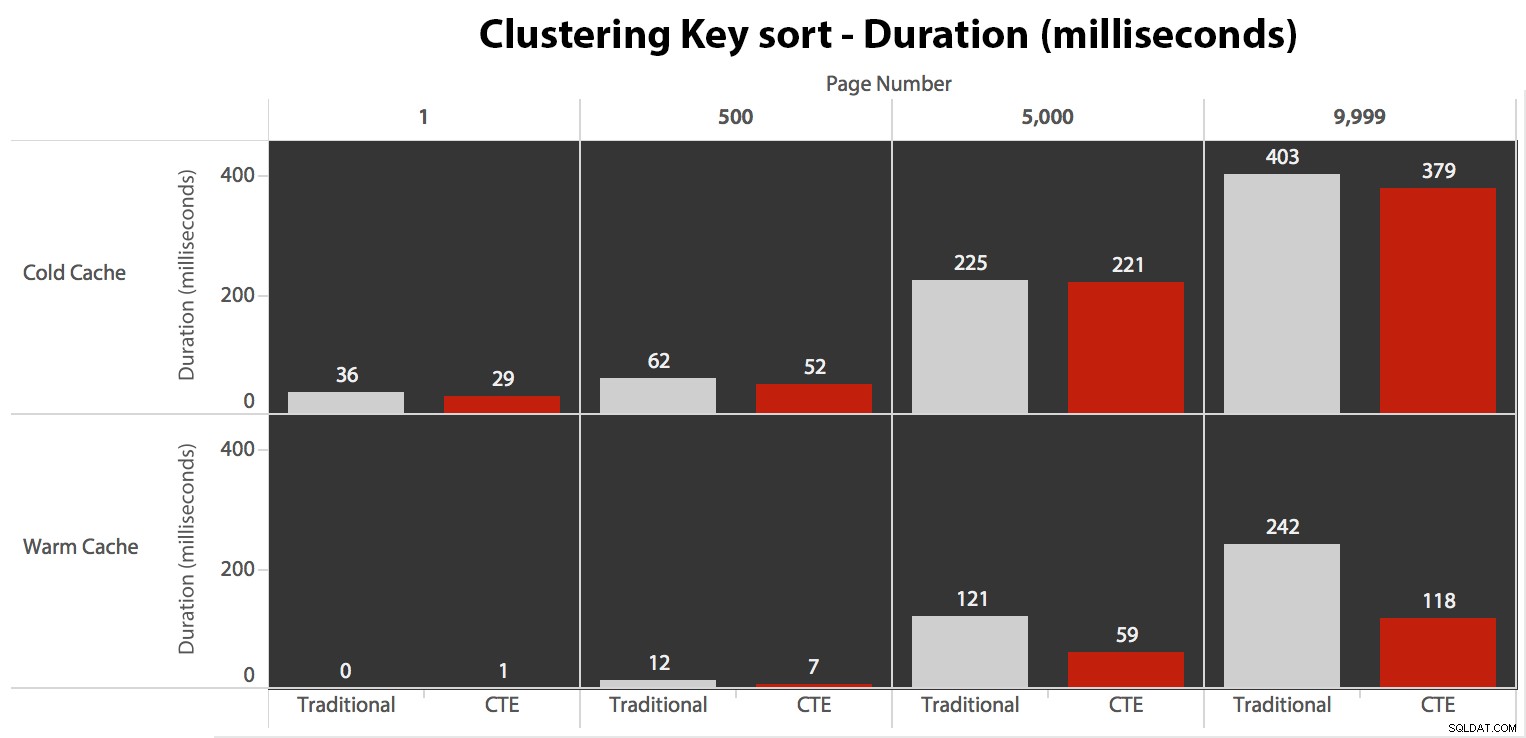
Mặc dù bạn có thể thấy một mẫu hiển thị thời lượng tăng lên khi số trang cao hơn, nhưng hãy lưu ý tỷ lệ:để đạt đến hàng 999,801 -> 999,900, chúng ta đang nói nửa giây trong trường hợp xấu nhất và 118 mili giây trong trường hợp tốt nhất. Phương pháp tiếp cận CTE thắng, nhưng không thắng lợi nhiều.
Kiểm tra cách sắp xếp danh bạ
Tiếp theo, tôi đã thử nghiệm trường hợp thứ hai, trong đó việc sắp xếp được hỗ trợ bởi một chỉ mục không bao trùm trên LastName, FirstName. Truy vấn ở trên vừa thay đổi tất cả các bản sao của Test_1 đến Test_2 . Đây là những lần đọc sử dụng bộ đệm lạnh:
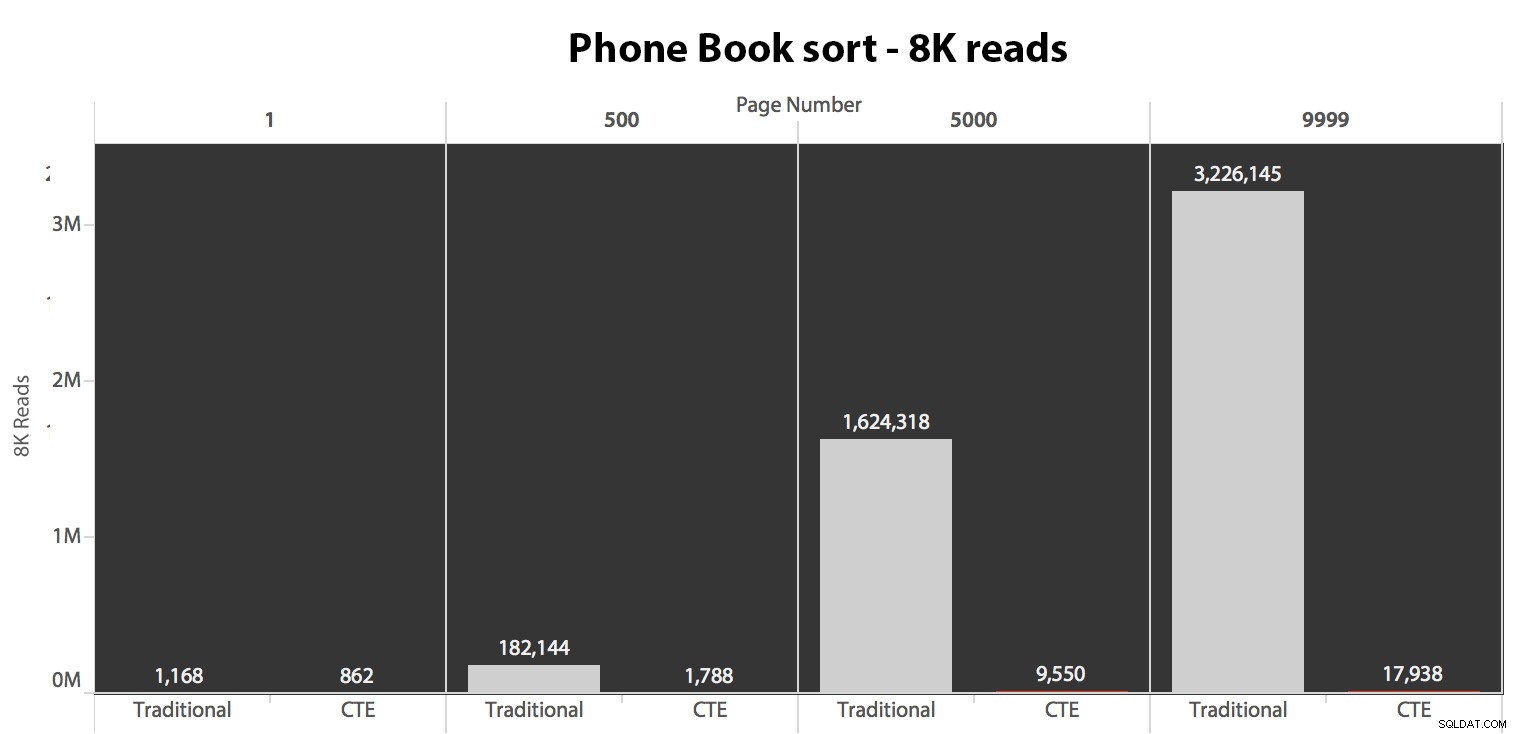
(Các lần đọc trong bộ nhớ đệm ấm áp theo cùng một mô hình - các con số thực tế khác nhau một chút, nhưng không đủ để điều chỉnh một biểu đồ riêng biệt.)
Khi chúng tôi không sử dụng chỉ mục được phân cụm để sắp xếp, rõ ràng là chi phí I / O liên quan đến phương pháp truyền thống của OFFSET / FETCH kém hơn nhiều so với khi xác định các khóa đầu tiên trong CTE và kéo phần còn lại của các cột chỉ cho tập hợp con đó.
Đây là kế hoạch cho phương pháp truy vấn truyền thống:
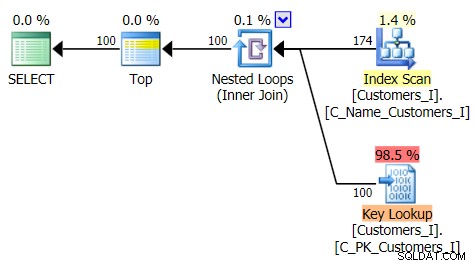
Và kế hoạch cho phương pháp tiếp cận CTE thay thế của tôi:
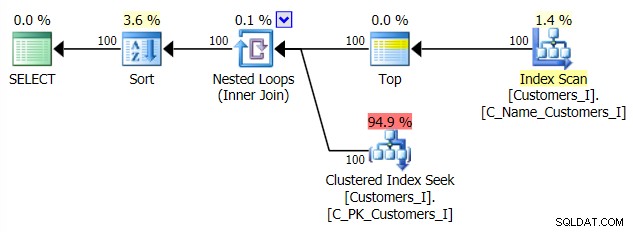
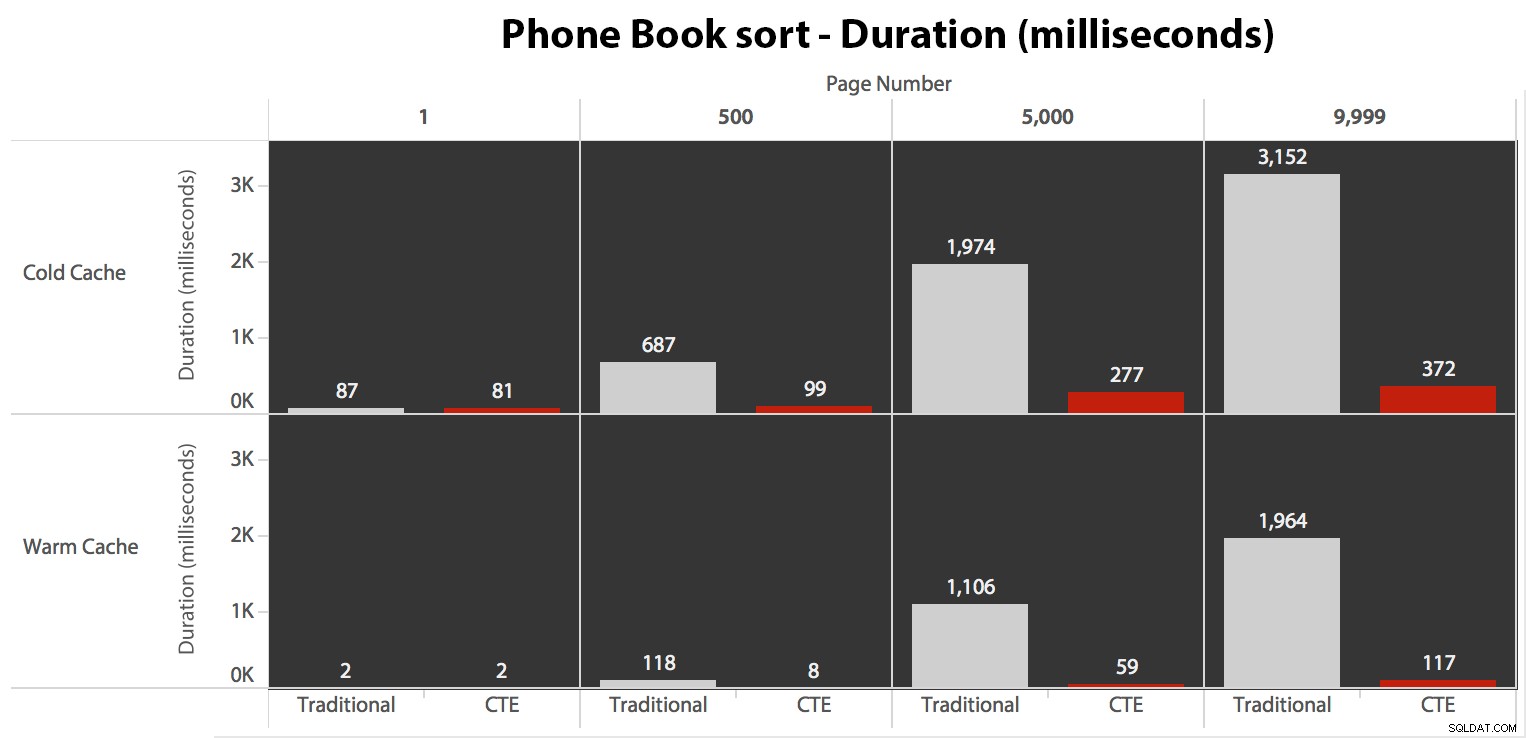
Cuối cùng, thời lượng:
Cách tiếp cận truyền thống cho thấy thời lượng tăng lên rất rõ ràng khi bạn tiến về cuối phân trang. Cách tiếp cận CTE cũng cho thấy một mô hình phi tuyến tính, nhưng nó ít rõ rệt hơn và mang lại thời gian tốt hơn ở mọi số trang. Chúng tôi thấy 117 mili giây cho trang từ thứ hai đến trang cuối cùng, so với cách tiếp cận truyền thống là gần hai giây.
Kiểm tra sắp xếp do người dùng xác định
Cuối cùng, tôi đã thay đổi truy vấn để sử dụng Test_3 các thủ tục được lưu trữ, kiểm tra trường hợp sắp xếp được xác định bởi người dùng và không có chỉ mục hỗ trợ. I / O nhất quán qua từng bộ thử nghiệm; biểu đồ quá không thú vị, tôi chỉ liên kết với nó. Truyện ngắn:có hơn 19.000 lượt đọc trong tất cả các bài kiểm tra. Lý do là vì mọi biến thể đơn lẻ phải thực hiện quét toàn bộ do thiếu chỉ mục để hỗ trợ thứ tự. Đây là kế hoạch cho cách tiếp cận truyền thống:
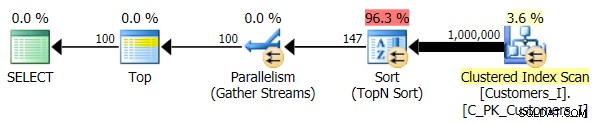
Và trong khi kế hoạch cho phiên bản CTE của truy vấn trông phức tạp hơn một cách đáng báo động…
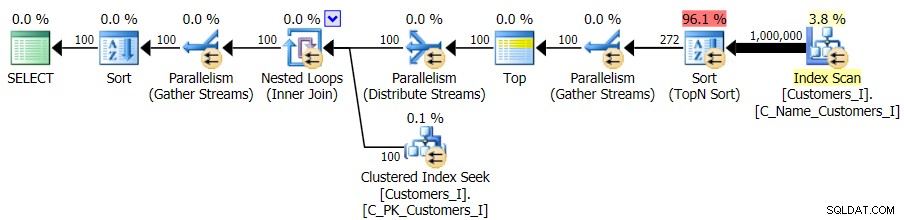
… Nó dẫn đến thời lượng thấp hơn trong tất cả trừ một trường hợp. Đây là thời lượng:
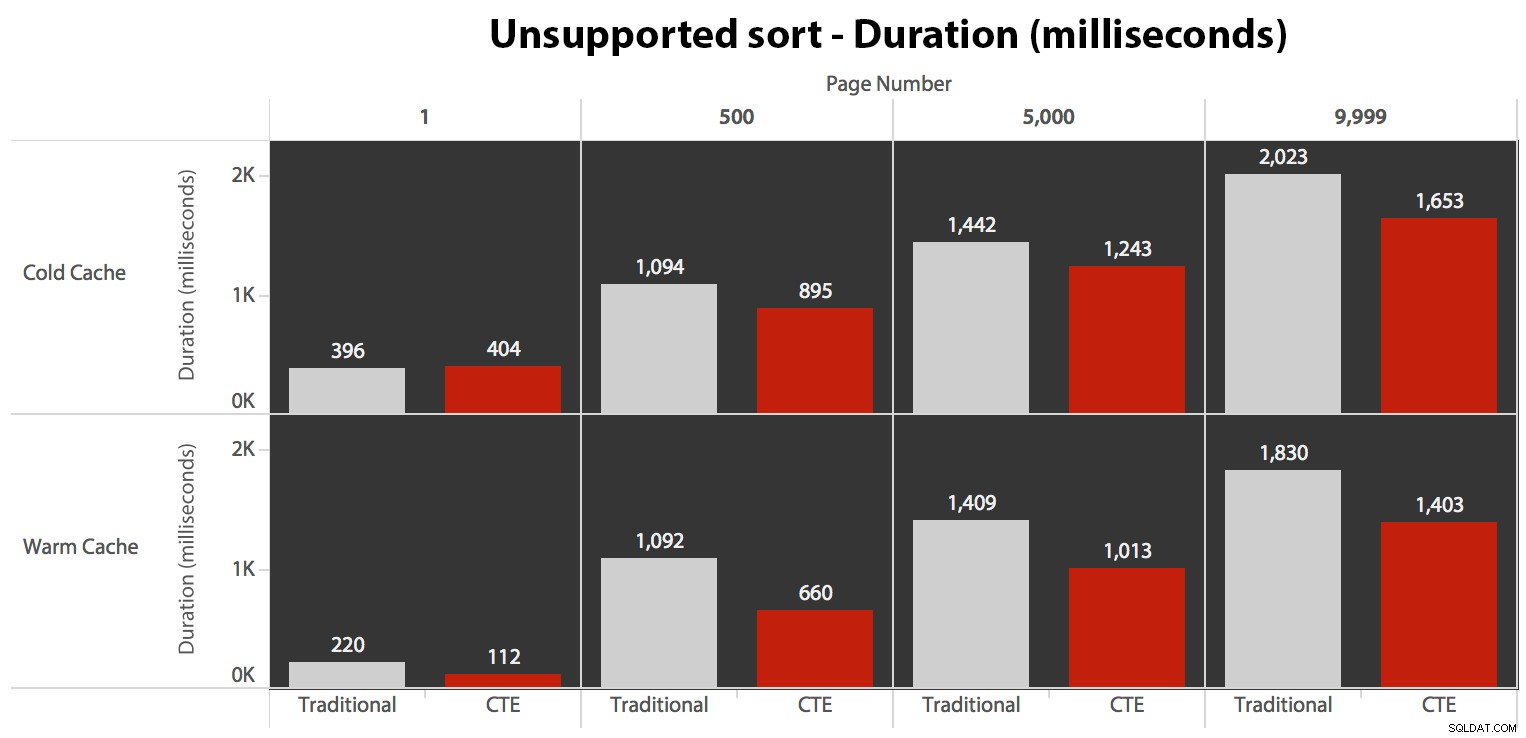
Bạn có thể thấy rằng chúng tôi không thể có được hiệu suất tuyến tính ở đây bằng cách sử dụng cả hai phương pháp, nhưng CTE thực sự xuất hiện trên đầu với một mức lợi nhuận tốt (bất kỳ nơi nào tốt hơn từ 16% đến 65%) trong mọi trường hợp ngoại trừ truy vấn bộ đệm lạnh so với đầu tiên trang (trong đó nó bị mất một con số khổng lồ 8 mili giây). Cũng rất thú vị khi lưu ý rằng phương pháp truyền thống không giúp được gì nhiều bởi một bộ đệm ấm ở "giữa" (trang 500 và 5000); chỉ về cuối bộ thì hiệu quả mới đáng được nhắc đến.
Âm lượng cao hơn
Sau khi thử nghiệm riêng lẻ một vài lần thực thi và lấy giá trị trung bình, tôi nghĩ rằng việc kiểm tra khối lượng giao dịch lớn sẽ phần nào mô phỏng lưu lượng truy cập thực trên một hệ thống bận rộn cũng rất hợp lý. Vì vậy, tôi đã tạo một công việc với 6 bước, một bước cho mỗi sự kết hợp của phương pháp truy vấn (phân trang truyền thống so với CTE) và loại sắp xếp (khóa phân cụm, danh bạ điện thoại và không được hỗ trợ), với trình tự 100 bước đánh vào bốn số trang ở trên , 10 lần mỗi trang và 60 số trang khác được chọn ngẫu nhiên (nhưng giống nhau cho mỗi bước). Đây là cách tôi tạo tập lệnh tạo công việc:
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX), @job SYSNAME = N'Paging Test', @step SYSNAME, @command NVARCHAR(MAX);
;WITH t10 AS (SELECT TOP (10) number FROM master.dbo.spt_values),
f AS (SELECT f FROM (VALUES(1),(500),(5000),(9999)) AS f(f))
SELECT @sql = STUFF((SELECT CHAR(13) + CHAR(10)
+ N'EXEC dbo.$p$_Test_$v$ @PageNumber = ' + RTRIM(f) + ';'
FROM
(
SELECT f FROM
(
SELECT f.f FROM t10 CROSS JOIN f
UNION ALL
SELECT TOP (60) f = ABS(CHECKSUM(NEWID())) % 10000
FROM sys.all_objects
) AS x
) AS y ORDER BY NEWID()
FOR XML PATH(''),TYPE).value(N'.[1]','nvarchar(max)'),1,0,'');
IF EXISTS (SELECT 1 FROM msdb.dbo.sysjobs WHERE name = @job)
BEGIN
EXEC msdb.dbo.sp_delete_job @job_name = @job;
END
EXEC msdb.dbo.sp_add_job
@job_name = @job,
@enabled = 0,
@notify_level_eventlog = 0,
@category_id = 0,
@owner_login_name = N'sa';
EXEC msdb.dbo.sp_add_jobserver
@job_name = @job,
@server_name = N'(local)';
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT step = p.p + '_' + v.v,
command = REPLACE(REPLACE(@sql, N'$p$', p.p), N'$v$', v.v)
FROM
(SELECT v FROM (VALUES('1'),('2'),('3')) AS v(v)) AS v
CROSS JOIN
(SELECT p FROM (VALUES('Alternate'),('Pagination')) AS p(p)) AS p
ORDER BY p.p, v.v;
OPEN c; FETCH c INTO @step, @command;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC msdb.dbo.sp_add_jobstep
@job_name = @job,
@step_name = @step,
@command = @command,
@database_name = N'IDs',
@on_success_action = 3;
FETCH c INTO @step, @command;
END
EXEC msdb.dbo.sp_update_jobstep
@job_name = @job,
@step_id = 6,
@on_success_action = 1; -- quit with success
PRINT N'EXEC msdb.dbo.sp_start_job @job_name = ''' + @job + ''';'; Đây là danh sách bước công việc kết quả và một trong các thuộc tính của bước:
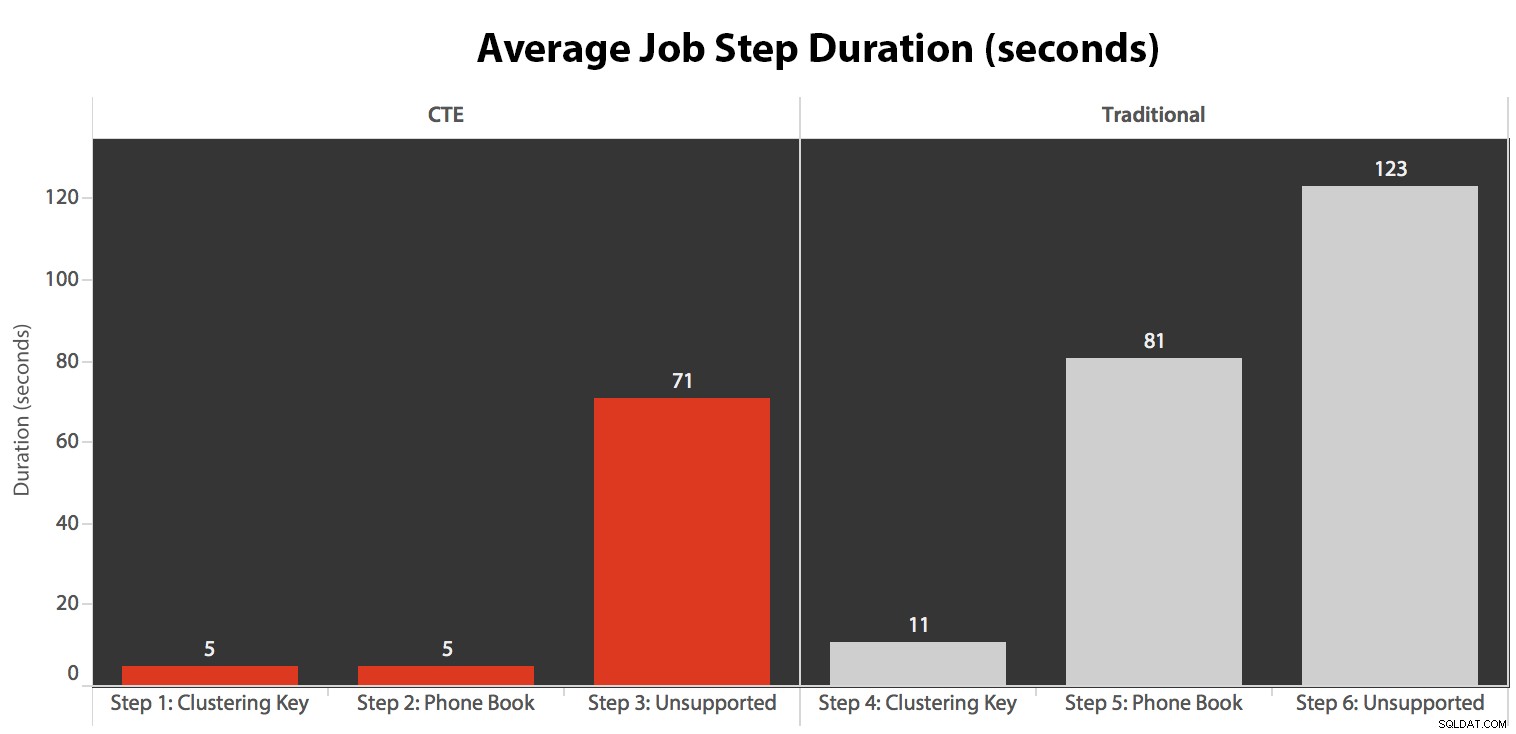
Tôi đã chạy công việc năm lần, sau đó xem lại lịch sử công việc và đây là thời gian chạy trung bình của mỗi bước:
Tôi cũng liên quan đến một trong những lần thực thi trên lịch SQL Sentry Event Manager…
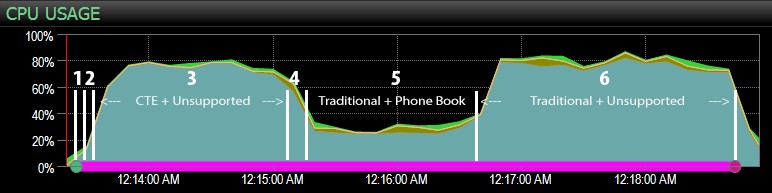
… Với bảng điều khiển SQL Sentry, và được đánh dấu theo cách thủ công gần đúng vị trí từng bước trong sáu bước chạy. Đây là biểu đồ sử dụng CPU từ phía Windows của bảng điều khiển:
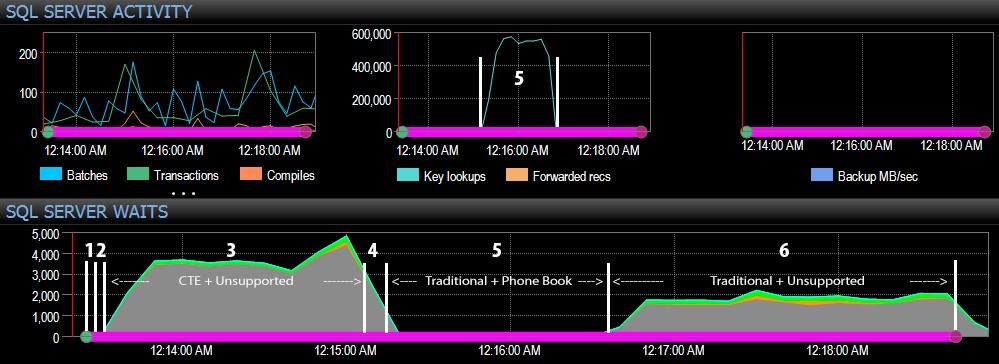
Và từ phía SQL Server của bảng điều khiển, các số liệu thú vị nằm trong đồ thị Key Lookups và Waits:
Những quan sát thú vị nhất chỉ từ góc độ trực quan thuần túy:
- CPU khá nóng, khoảng 80%, trong bước 3 (CTE + không có chỉ mục hỗ trợ) và bước 6 (truyền thống + không có chỉ mục hỗ trợ);
- Thời gian chờ của CXPACKET tương đối cao trong bước 3 và ở mức độ thấp hơn trong bước 6;
- bạn có thể thấy lượng tìm kiếm quan trọng tăng vọt, lên gần 600.000, trong khoảng một phút (tương ứng với bước 5 - cách tiếp cận truyền thống với chỉ mục kiểu danh bạ điện thoại).
Trong một thử nghiệm trong tương lai - như với bài viết trước của tôi về GUID - tôi muốn thử nghiệm điều này trên một hệ thống mà dữ liệu không vừa với bộ nhớ (dễ mô phỏng) và nơi đĩa chạy chậm (không dễ mô phỏng) , vì một số kết quả này có thể được hưởng lợi từ những thứ không phải hệ thống sản xuất nào cũng có - đĩa nhanh và đủ RAM. Tôi cũng nên mở rộng các thử nghiệm để bao gồm nhiều biến thể hơn (sử dụng cột mỏng và rộng, chỉ mục gầy và rộng, chỉ mục danh bạ điện thoại thực sự bao gồm tất cả các cột đầu ra và sắp xếp theo cả hai hướng). Phạm vi creep chắc chắn hạn chế phạm vi thử nghiệm của tôi cho tập hợp các thử nghiệm đầu tiên này.
Cách cải thiện phân trang SQL Server
Việc phân trang không phải lúc nào cũng đau đớn; SQL Server 2012 chắc chắn làm cho cú pháp dễ dàng hơn, nhưng nếu bạn chỉ cắm cú pháp gốc vào, không phải lúc nào bạn cũng có thể thấy được lợi ích lớn. Ở đây tôi đã chỉ ra rằng cú pháp dài dòng hơn một chút bằng cách sử dụng CTE có thể dẫn đến hiệu suất tốt hơn nhiều trong trường hợp tốt nhất và sự khác biệt về hiệu suất được cho là không đáng kể trong trường hợp xấu nhất. Bằng cách tách vị trí dữ liệu khỏi truy xuất dữ liệu thành hai bước khác nhau, chúng ta có thể thấy lợi ích to lớn trong một số trường hợp, bên ngoài số lần đợi CXPACKET cao hơn trong một trường hợp (và thậm chí sau đó, các truy vấn song song hoàn thành nhanh hơn các truy vấn khác hiển thị ít hoặc không chờ đợi, vì vậy chúng khó có thể là CXPACKET "xấu" mà mọi người đã cảnh báo cho bạn).
Tuy nhiên, ngay cả phương pháp nhanh hơn cũng chậm khi không có chỉ mục hỗ trợ. Mặc dù bạn có thể bị cám dỗ để triển khai chỉ mục cho mọi thuật toán sắp xếp có thể mà người dùng có thể chọn, nhưng bạn có thể muốn xem xét cung cấp ít tùy chọn hơn (vì tất cả chúng ta đều biết rằng chỉ mục không miễn phí). Ví dụ:ứng dụng của bạn có nhất thiết phải hỗ trợ sắp xếp theo LastName tăng dần * và * LastName giảm dần không? Nếu họ muốn tiếp cận trực tiếp những khách hàng có họ bắt đầu bằng Z, họ không thể chuyển đến trang * cuối cùng * và làm việc ngược lại? Đó là một quyết định kinh doanh và khả năng sử dụng nhiều hơn là một quyết định kỹ thuật, chỉ cần giữ nó như một tùy chọn trước khi bổ sung các chỉ mục trên mọi cột sắp xếp, theo cả hai hướng, để có được hiệu suất tốt nhất cho ngay cả những tùy chọn sắp xếp khó hiểu nhất.