Trong bài đăng cuối cùng của tôi, tôi đã chỉ ra một số cách tiếp cận hiệu quả để nối theo nhóm. Lần này, tôi muốn nói về một số khía cạnh bổ sung của vấn đề này mà chúng ta có thể thực hiện dễ dàng với FOR XML PATH cách tiếp cận:sắp xếp danh sách và xóa các bản sao.
Có một số cách mà tôi đã thấy mọi người muốn danh sách được phân tách bằng dấu phẩy được sắp xếp theo thứ tự. Đôi khi họ muốn mục trong danh sách được sắp xếp theo thứ tự bảng chữ cái; Tôi đã cho thấy điều đó trong bài viết trước của tôi. Nhưng đôi khi họ muốn nó được sắp xếp theo một số thuộc tính khác mà thực sự không được giới thiệu trong đầu ra; ví dụ, có thể tôi muốn sắp xếp danh sách theo mục gần đây nhất trước. Hãy lấy một ví dụ đơn giản, trong đó chúng ta có bảng Nhân viên và bàn CoffeeOrders. Hãy chỉ điền đơn đặt hàng của một người trong vài ngày:
CREATE TABLE dbo.Employees
(
EmployeeID INT PRIMARY KEY,
Name NVARCHAR(128)
);
INSERT dbo.Employees(EmployeeID, Name) VALUES(1, N'Jack');
CREATE TABLE dbo.CoffeeOrders
(
EmployeeID INT NOT NULL REFERENCES dbo.Employees(EmployeeID),
OrderDate DATE NOT NULL,
OrderDetails NVARCHAR(64)
);
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
VALUES(1,'20140801',N'Large double double'),
(1,'20140802',N'Medium double double'),
(1,'20140803',N'Large Vanilla Latte'),
(1,'20140804',N'Medium double double');
Nếu chúng tôi sử dụng phương pháp hiện có mà không chỉ định ORDER BY , chúng tôi nhận được một thứ tự tùy ý (trong trường hợp này, rất có thể là trường hợp bạn sẽ thấy các hàng theo thứ tự mà chúng đã được chèn vào, nhưng đừng phụ thuộc vào điều đó với các tập dữ liệu lớn hơn, nhiều chỉ mục hơn, v.v.):
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Kết quả (hãy nhớ rằng bạn có thể nhận được các kết quả * khác * trừ khi bạn chỉ định ORDER BY ):
Jack | Đôi lớn, đôi vừa, đôi vừa, Vanilla Latte lớn, Đôi vừa
Nếu chúng ta muốn sắp xếp danh sách theo thứ tự bảng chữ cái, rất đơn giản; chúng tôi chỉ thêm ORDER BY c.OrderDetails :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDetails -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Kết quả:
Tên | Đơn đặt hàngJack | Đôi lớn, Đôi lớn Vanilla Latte, Đôi vừa đôi, Đôi vừa
Chúng ta cũng có thể sắp xếp theo một cột không xuất hiện trong tập kết quả; ví dụ:chúng tôi có thể đặt hàng theo đơn hàng cà phê gần đây nhất trước:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDate DESC -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Kết quả:
Tên | Đơn đặt hàngJack | Đôi vừa, Đôi lớn Vanilla Latte, Đôi vừa đôi, Đôi lớn
Một điều khác mà chúng tôi thường muốn làm là loại bỏ các bản sao; sau khi tất cả, có rất ít lý do để xem "Đôi đôi trung bình" hai lần. Chúng tôi có thể loại bỏ điều đó bằng cách sử dụng GROUP BY :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails -- removed ORDER BY and added GROUP BY here FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Bây giờ, điều này * xảy ra * để sắp xếp đầu ra theo thứ tự bảng chữ cái, nhưng một lần nữa bạn không thể dựa vào điều này:
Tên | Đơn đặt hàngJack | Đôi lớn, Đôi lớn Vanilla Latte, Đôi vừa
Nếu bạn muốn đảm bảo rằng đặt hàng theo cách này, bạn chỉ cần thêm lại ĐƠN ĐẶT HÀNG BẰNG CÁCH:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDetails -- added ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Kết quả giống nhau (nhưng tôi sẽ nhắc lại, đây chỉ là sự trùng hợp trong trường hợp này; nếu bạn muốn thứ tự này, hãy luôn nói như vậy):
Tên | Đơn đặt hàngJack | Đôi lớn, Đôi lớn Vanilla Latte, Đôi vừa
Nhưng điều gì sẽ xảy ra nếu chúng ta muốn loại bỏ các bản sao * và * sắp xếp danh sách theo thứ tự cà phê gần đây nhất trước tiên? Xu hướng đầu tiên của bạn có thể là giữ GROUP BY và chỉ cần thay đổi ORDER BY , như thế này:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDate DESC -- changed ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Điều đó sẽ không hoạt động, vì OrderDate không được nhóm hoặc tổng hợp như một phần của truy vấn:
Cột "dbo.CoffeeOrders.OrderDate" không hợp lệ trong mệnh đề ORDER BY vì nó không có trong hàm tổng hợp hoặc mệnh đề GROUP BY.
Một cách giải quyết, được thừa nhận là làm cho truy vấn xấu hơn một chút, là trước tiên hãy nhóm các đơn đặt hàng riêng rẽ, sau đó chỉ lấy các hàng có ngày tối đa cho đơn đặt hàng cà phê đó cho mỗi nhân viên:
;WITH grouped AS ( SELECT EmployeeID, OrderDetails, OrderDate = MAX(OrderDate) FROM dbo.CoffeeOrders GROUP BY EmployeeID, OrderDetails ) SELECT e.Name, Orders = STUFF((SELECT N', ' + g.OrderDetails FROM grouped AS g WHERE g.EmployeeID = e.EmployeeID ORDER BY g.OrderDate DESC FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Kết quả:
Tên | Đơn đặt hàngJack | Đôi vừa đôi, Vanilla Latte lớn, Đôi lớn
Điều này hoàn thành cả hai mục tiêu của chúng tôi:chúng tôi đã loại bỏ các bản sao và chúng tôi sắp xếp danh sách theo thứ gì đó thực sự không có trong danh sách.
Hiệu suất
Bạn có thể tự hỏi rằng các phương pháp này hoạt động tồi tệ như thế nào đối với một tập dữ liệu mạnh mẽ hơn. Tôi sẽ điền vào bảng của chúng tôi 100.000 hàng, xem chúng hoạt động như thế nào mà không có bất kỳ chỉ mục bổ sung nào và sau đó chạy lại các truy vấn tương tự với một chút điều chỉnh chỉ mục để hỗ trợ các truy vấn của chúng tôi. Vì vậy, trước tiên, có được 100.000 hàng trải dài trên 1.000 nhân viên:
-- clear out our tiny sample data
DELETE dbo.CoffeeOrders;
DELETE dbo.Employees;
-- create 1000 fake employees
INSERT dbo.Employees(EmployeeID, Name)
SELECT TOP (1000)
EmployeeID = ROW_NUMBER() OVER (ORDER BY t.[object_id]),
Name = LEFT(t.name + c.name, 128)
FROM sys.all_objects AS t
INNER JOIN sys.all_columns AS c
ON t.[object_id] = c.[object_id];
-- create 100 fake coffee orders for each employee
-- we may get duplicates in here for name
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
SELECT e.EmployeeID,
OrderDate = DATEADD(DAY, ROW_NUMBER() OVER
(PARTITION BY e.EmployeeID ORDER BY c.[guid]), '20140630'),
LEFT(c.name, 64)
FROM dbo.Employees AS e
CROSS APPLY
(
SELECT TOP (100) name, [guid] = NEWID()
FROM sys.all_columns
WHERE [object_id] < e.EmployeeID
ORDER BY NEWID()
) AS c; Bây giờ chúng ta chỉ cần chạy mỗi truy vấn của chúng ta hai lần và xem thời gian như thế nào trong lần thử thứ hai (chúng ta sẽ có một bước nhảy vọt về niềm tin ở đây và giả sử rằng - trong một thế giới lý tưởng - chúng ta sẽ làm việc với một bộ nhớ cache được mồi ). Tôi đã chạy những điều này trong SQL Sentry Plan Explorer, vì đó là cách dễ nhất mà tôi biết về thời gian và so sánh một loạt các truy vấn riêng lẻ:
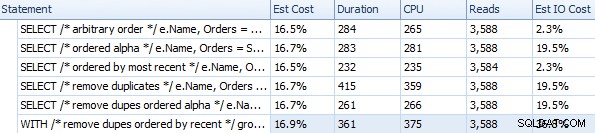 Thời lượng và các chỉ số thời gian chạy khác cho các phương pháp tiếp cận FOR XML PATH khác nhau
Thời lượng và các chỉ số thời gian chạy khác cho các phương pháp tiếp cận FOR XML PATH khác nhau
Những thời gian này (thời lượng tính bằng mili giây) thực sự không tệ chút nào IMHO, khi bạn nghĩ về những gì thực sự đang được thực hiện ở đây. Kế hoạch phức tạp nhất, ít nhất là về mặt trực quan, dường như là kế hoạch mà chúng tôi đã loại bỏ các bản sao và sắp xếp theo thứ tự gần đây nhất:
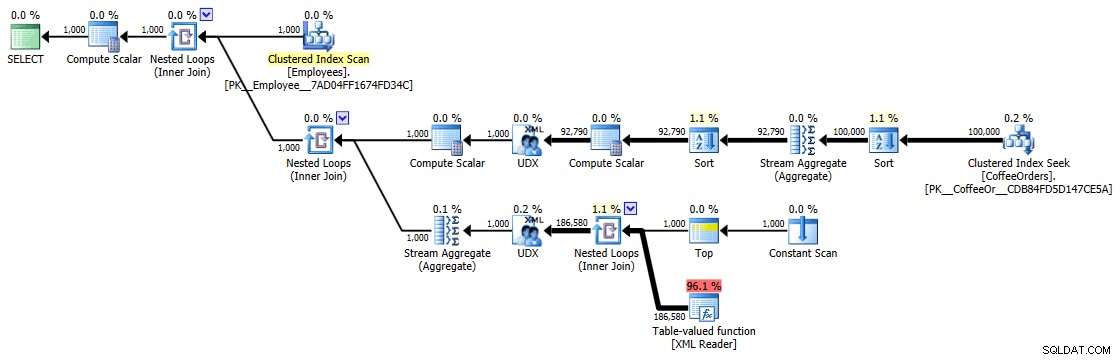 Kế hoạch thực thi cho truy vấn được nhóm và sắp xếp
Kế hoạch thực thi cho truy vấn được nhóm và sắp xếp
Nhưng ngay cả toán tử đắt nhất ở đây - hàm giá trị bảng XML - dường như là tất cả CPU (mặc dù tôi tự do thừa nhận rằng tôi không chắc có bao nhiêu công việc thực tế được hiển thị trong chi tiết kế hoạch truy vấn):
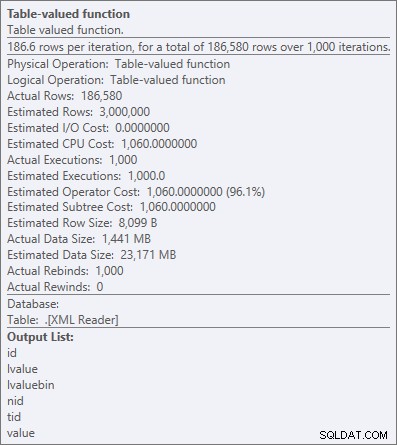 Thuộc tính toán tử cho hàm giá trị bảng XML
Thuộc tính toán tử cho hàm giá trị bảng XML
"Tất cả CPU" thường không sao, vì hầu hết các hệ thống đều bị ràng buộc I / O và / hoặc giới hạn bộ nhớ, không ràng buộc CPU. Như tôi đã nói khá thường xuyên, trong hầu hết các hệ thống, tôi sẽ đánh đổi một số khoảng trống CPU của mình để lấy bộ nhớ hoặc đĩa bất kỳ ngày nào trong tuần (một trong những lý do tôi thích OPTION (RECOMPILE) như một giải pháp cho các vấn đề đánh hơi thông số phổ biến).
Điều đó nói rằng, tôi thực sự khuyến khích bạn thử nghiệm các phương pháp này so với các kết quả tương tự mà bạn có thể nhận được từ phương pháp GROUP_CONCAT CLR trên CodePlex, cũng như thực hiện tổng hợp và sắp xếp ở cấp trình bày (đặc biệt nếu bạn đang giữ dữ liệu chuẩn hóa ở một số loại của lớp bộ nhớ đệm).