Khi người dùng yêu cầu dữ liệu từ một hệ thống, họ thường muốn xem dữ liệu đó theo một thứ tự cụ thể… ngay cả khi họ trả về hàng nghìn hàng. Như nhiều DBA và nhà phát triển đã biết, ORDER BY có thể đưa sự tàn phá vào một kế hoạch truy vấn, vì nó yêu cầu dữ liệu phải được sắp xếp. Điều này đôi khi có thể yêu cầu toán tử SORT như một phần của quá trình thực thi truy vấn, đây có thể là một hoạt động tốn kém, đặc biệt nếu ước tính bị tắt và nó tràn ra đĩa. Trong một thế giới lý tưởng, dữ liệu đã được sắp xếp nhờ một chỉ mục (các chỉ mục và cách sắp xếp rất bổ sung cho nhau). Chúng ta thường nói về việc tạo một chỉ mục bao trùm để đáp ứng một truy vấn - để trình tối ưu hóa không phải quay lại bảng cơ sở hoặc chỉ mục nhóm để lấy thêm các cột. Và bạn có thể đã nghe mọi người nói rằng thứ tự của các cột trong chỉ mục rất quan trọng. Bạn đã bao giờ xem nó ảnh hưởng như thế nào đến hoạt động SORT của bạn chưa?
Kiểm tra ĐẶT HÀNG THEO VÀ Sắp xếp
Chúng ta sẽ bắt đầu với một bản sao mới của cơ sở dữ liệu AdventureWorks2014 trên phiên bản SQL Server 2014 (phiên bản 12.0.2000). Nếu chúng tôi chạy một truy vấn SELECT đơn giản đối với Sales.SalesOrderHeader mà không có ORDER BY, chúng tôi sẽ thấy một bản quét chỉ mục cụm cũ đơn giản (sử dụng SQL Sentry Plan Explorer):
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader];
 Truy vấn không có ORDER BY, quét chỉ mục theo nhóm
Truy vấn không có ORDER BY, quét chỉ mục theo nhóm
Bây giờ, hãy thêm một ĐƠN ĐẶT HÀNG BẰNG CÁCH để xem kế hoạch thay đổi như thế nào:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID];
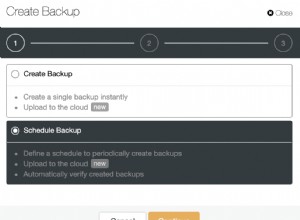
 Truy vấn với ORDER BY, quét chỉ mục theo cụm và sắp xếp
Truy vấn với ORDER BY, quét chỉ mục theo cụm và sắp xếp
Ngoài Quét chỉ mục theo cụm, giờ đây chúng tôi có một Sắp xếp được trình tối ưu hóa giới thiệu và chi phí ước tính của nó cao hơn đáng kể so với quá trình quét. Bây giờ, chi phí ước tính chỉ là ước tính và chúng tôi không thể nói một cách hoàn toàn chắc chắn ở đây rằng Sắp xếp chiếm 79,6% chi phí của truy vấn. Để thực sự hiểu Sort đắt như thế nào, chúng ta cũng cần xem xét THỐNG KÊ IO, điều này nằm ngoài mục tiêu của ngày hôm nay.
Bây giờ nếu đây là một truy vấn được thực thi thường xuyên trong môi trường của bạn, bạn có thể sẽ cân nhắc thêm một chỉ mục để hỗ trợ nó. Trong trường hợp này, không có mệnh đề WHERE, chúng tôi chỉ lấy bốn cột và sắp xếp theo một trong số chúng. Một nỗ lực hợp lý đầu tiên đối với một chỉ mục sẽ là:
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_CustomerID_OrderDate_SubTotal] ON [Sales].[SalesOrderHeader]( [CustomerID] ASC) INCLUDE ( [OrderDate], [SubTotal]);
Chúng tôi sẽ chạy lại truy vấn của mình sau khi thêm chỉ mục có tất cả các cột mà chúng tôi muốn và hãy nhớ rằng chỉ mục đã thực hiện công việc sắp xếp dữ liệu. Giờ đây, chúng tôi thấy một bản Quét chỉ mục dựa trên chỉ mục không hợp nhất mới của chúng tôi:
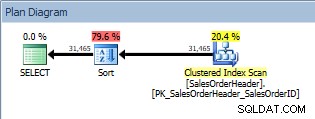
 Truy vấn bằng ORDER BY, chỉ mục mới, không phân tán được quét
Truy vấn bằng ORDER BY, chỉ mục mới, không phân tán được quét
Đây là một tin tốt. Nhưng điều gì sẽ xảy ra nếu ai đó thay đổi truy vấn đó - vì người dùng có thể chỉ định những cột nào họ muốn sắp xếp theo thứ tự hoặc vì một nhà phát triển đã yêu cầu một thay đổi? Ví dụ:có thể người dùng muốn xem các CustomerID và SalesOrderID theo thứ tự giảm dần:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] DESC;
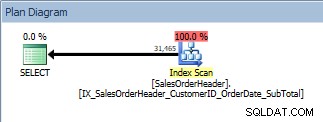
 Truy vấn có hai cột trong ORDER BY, chỉ mục mới, không phân tán được quét
Truy vấn có hai cột trong ORDER BY, chỉ mục mới, không phân tán được quét
Chúng tôi có cùng một kế hoạch; không có toán tử Sắp xếp nào được thêm vào. Nếu chúng ta xem chỉ mục bằng cách sử dụng sp_helpindex của Kimberly Tripp (một số cột được thu gọn để tiết kiệm dung lượng), chúng ta có thể thấy lý do tại sao kế hoạch không thay đổi:
 Đầu ra của sp_helpindex
Đầu ra của sp_helpindex
Cột chính cho chỉ mục là CustomerID, nhưng vì SalesOrderID là cột chính cho chỉ mục nhóm, nên nó cũng là một phần của khóa chỉ mục, do đó dữ liệu được sắp xếp theo CustomerID, sau đó là SalesOrderID. Truy vấn yêu cầu dữ liệu được sắp xếp theo hai cột đó, theo thứ tự giảm dần. Chỉ mục được tạo với cả hai cột tăng dần, nhưng vì nó là một danh sách được liên kết kép nên chỉ mục có thể được đọc ngược lại. Bạn có thể thấy điều này trong ngăn Thuộc tính trong Management Studio cho toán tử quét chỉ mục không phân biệt:
 Ngăn thuộc tính của quá trình quét chỉ mục không phân biệt, cho thấy nó đã bị ngược
Ngăn thuộc tính của quá trình quét chỉ mục không phân biệt, cho thấy nó đã bị ngược
Tuyệt vời, không có vấn đề gì với truy vấn đó… nhưng còn câu hỏi này thì sao:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] ASC;
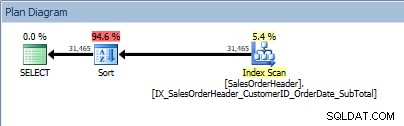 Truy vấn có hai cột trong ORDER BY và sắp xếp được thêm
Truy vấn có hai cột trong ORDER BY và sắp xếp được thêm
Toán tử SORT của chúng tôi xuất hiện lại, vì dữ liệu đến từ chỉ mục không được sắp xếp theo thứ tự được yêu cầu. Chúng ta sẽ thấy hành vi tương tự nếu chúng ta sắp xếp trên một trong các cột được bao gồm:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] ASC, [OrderDate] ASC;
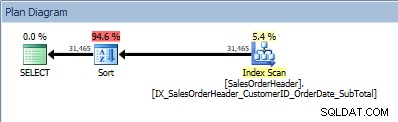 Truy vấn có hai cột trong ORDER BY và sắp xếp được thêm
Truy vấn có hai cột trong ORDER BY và sắp xếp được thêm
Điều gì xảy ra nếu chúng ta (cuối cùng) thêm một vị từ và thay đổi một chút ĐẶT HÀNG BẰNG CÁCH?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] = 13464 ORDER BY [SalesOrderID];
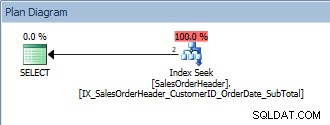 Truy vấn với một vị từ duy nhất và một LỆNH THEO
Truy vấn với một vị từ duy nhất và một LỆNH THEO
Truy vấn này là ok vì một lần nữa, SalesOrderID là một phần của khóa chỉ mục. Đối với một CustomerID này, dữ liệu đã được đặt hàng bởi SalesOrderID. Điều gì sẽ xảy ra nếu chúng tôi truy vấn một loạt các CustomerID, được sắp xếp theo SalesOrderIDs?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 13464 AND 13466 ORDER BY [SalesOrderID];
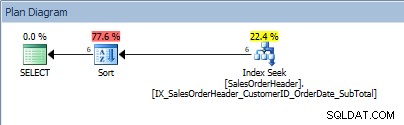 Truy vấn với một phạm vi giá trị trong vị từ và một LỆNH BẰNG
Truy vấn với một phạm vi giá trị trong vị từ và một LỆNH BẰNG
Chuột, SORT của chúng tôi đã trở lại. Thực tế là dữ liệu được đặt hàng bởi CustomerID chỉ giúp tìm kiếm chỉ mục để tìm ra phạm vi giá trị đó; đối với ORDER BY SalesOrderID, trình tối ưu hóa phải can thiệp vào Sắp xếp để đưa dữ liệu vào thứ tự được yêu cầu.
Tại thời điểm này, bạn có thể tự hỏi tại sao tôi lại cố định toán tử Sắp xếp xuất hiện trong các kế hoạch truy vấn. Đó là bởi vì nó đắt tiền. Nó có thể tốn kém về tài nguyên (bộ nhớ, IO) và / hoặc thời lượng.
Thời lượng truy vấn có thể bị ảnh hưởng bởi Sắp xếp vì nó là hoạt động dừng và chạy. Toàn bộ tập dữ liệu phải được sắp xếp trước khi hoạt động tiếp theo trong kế hoạch có thể xảy ra. Nếu chỉ có một vài hàng dữ liệu phải được sắp xếp, đó không phải là một vấn đề lớn. Nếu đó là hàng nghìn hoặc hàng triệu hàng? Bây giờ chúng tôi đang đợi.
Ngoài thời lượng truy vấn tổng thể, chúng ta cũng phải nghĩ đến việc sử dụng tài nguyên. Hãy lấy 31.465 hàng mà chúng tôi đã làm việc và đẩy chúng vào một biến bảng, sau đó chạy truy vấn ban đầu đó với ORDER BY trên CustomerID:
DECLARE @t TABLE (CustomerID INT, SalesOrderID INT, OrderDate DATETIME, SubTotal MONEY); INSERT @t SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader]; SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM @t ORDER BY [CustomerID];
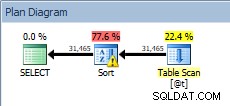 Truy vấn đối với biến bảng, có sắp xếp
Truy vấn đối với biến bảng, có sắp xếp
SORT của chúng tôi đã trở lại và lần này nó có cảnh báo (lưu ý hình tam giác màu vàng với dấu chấm than). Cảnh báo là không tốt. Nếu chúng ta nhìn vào Thuộc tính của loại, chúng ta có thể thấy cảnh báo, "Nhà điều hành đã sử dụng tempdb để làm tràn dữ liệu trong quá trình thực thi với mức tràn 1":
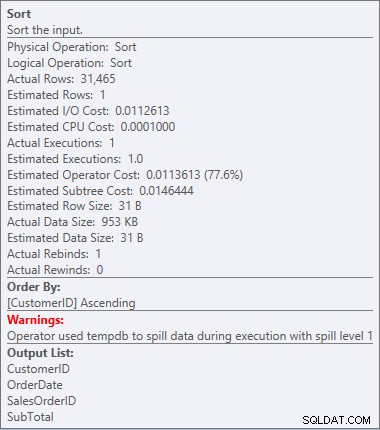 Cảnh báo sắp xếp
Cảnh báo sắp xếp
Đây không phải là điều tôi muốn thấy trong một kế hoạch. Trình tối ưu hóa đã ước tính lượng dung lượng nó cần trong bộ nhớ để sắp xếp dữ liệu và nó yêu cầu bộ nhớ đó. Nhưng khi nó thực sự có tất cả dữ liệu và tiến hành sắp xếp nó, động cơ nhận ra không có đủ bộ nhớ (trình tối ưu hóa yêu cầu quá ít!), Vì vậy hoạt động Sắp xếp đã bị lỗi. Trong một số trường hợp, điều này có thể tràn ra đĩa, có nghĩa là đọc và ghi - vốn rất chậm. Chúng tôi không chỉ chờ đợi để có được dữ liệu theo thứ tự, nó thậm chí còn chậm hơn vì chúng tôi không thể thực hiện tất cả trong bộ nhớ. Tại sao trình tối ưu hóa không yêu cầu đủ bộ nhớ? Nó có một ước tính sai về dữ liệu nó cần để sắp xếp:
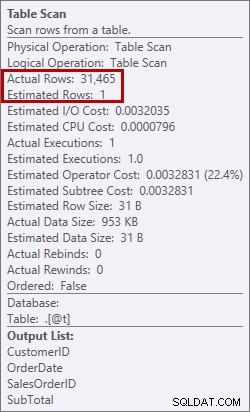 Ước tính 1 hàng so với thực tế là 31.465 hàng
Ước tính 1 hàng so với thực tế là 31.465 hàng
Trong trường hợp này, tôi đã buộc một ước tính sai bằng cách sử dụng một biến bảng. Có một số vấn đề đã biết với ước tính thống kê và biến bảng (Aaron Bertrand có một bài đăng tuyệt vời về các tùy chọn để cố gắng giải quyết vấn đề này) và ở đây, trình tối ưu hóa tin rằng chỉ có 1 hàng sẽ được trả về từ quá trình quét bảng, không phải 31.465.
Tùy chọn
Vì vậy, bạn, với tư cách là một DBA hoặc nhà phát triển, có thể làm gì để tránh SORTs trong kế hoạch truy vấn của bạn? Câu trả lời nhanh là, "Đừng sắp xếp dữ liệu của bạn." Nhưng điều đó không phải lúc nào cũng thực tế. Trong một số trường hợp, bạn có thể giảm tải việc sắp xếp đó cho máy khách hoặc cho một lớp ứng dụng - nhưng người dùng vẫn phải đợi để sắp xếp dữ liệu tại that lớp. Trong các tình huống mà bạn không thể thay đổi cách ứng dụng hoạt động, bạn có thể bắt đầu bằng cách xem các chỉ mục của mình.
Nếu bạn hỗ trợ một ứng dụng cho phép người dùng chạy các truy vấn đặc biệt hoặc thay đổi thứ tự sắp xếp để họ có thể xem dữ liệu được sắp xếp theo cách họ muốn… thì bạn sẽ gặp khó khăn nhất (nhưng đó không phải là nguyên nhân mất tích đừng ngừng đọc!). Bạn không thể lập chỉ mục cho mọi tùy chọn. Nó không hiệu quả và bạn sẽ tạo ra nhiều vấn đề hơn là bạn giải quyết. Đặt cược tốt nhất của bạn ở đây là nói chuyện với người dùng (tôi biết, đôi khi thật đáng sợ khi rời khỏi góc rừng của bạn, nhưng hãy thử xem). Đối với các truy vấn mà người dùng chạy thường xuyên nhất, hãy tìm hiểu cách họ thường muốn xem dữ liệu. Có, bạn cũng có thể lấy điều này từ bộ nhớ cache của kế hoạch - bạn có thể truy xuất các truy vấn và kế hoạch cho đến khi bạn nằm lòng để xem chúng đang làm gì. Nhưng sẽ nhanh hơn để nói chuyện với người dùng. Lợi ích bổ sung là bạn có thể giải thích lý do tại sao bạn đang yêu cầu và tại sao ý tưởng "sắp xếp trên tất cả các cột vì tôi có thể" không phải là một ý tưởng tốt. Biết là một nửa trận chiến. Nếu bạn có thể dành một chút thời gian để giáo dục những người dùng thành thạo của mình và những người dùng đào tạo những người mới, bạn có thể làm được một số điều tốt.
Nếu bạn hỗ trợ một ứng dụng có các tùy chọn ORDER BY giới hạn, thì bạn có thể thực hiện một số phân tích thực tế. Xem lại các biến thể ORDER BY tồn tại, xác định các kết hợp nào được thực thi thường xuyên nhất và lập chỉ mục để hỗ trợ các truy vấn đó. Bạn có thể sẽ không đánh trúng tất cả, nhưng bạn vẫn có thể tạo ra tác động. Bạn có thể tiến thêm một bước nữa bằng cách nói chuyện với các nhà phát triển của mình và hướng dẫn họ về vấn đề cũng như cách giải quyết.
Cuối cùng, khi bạn đang xem xét các kế hoạch truy vấn với các hoạt động SORT, đừng chỉ tập trung vào việc loại bỏ Sắp xếp. Nhìn vào nơi sắp xếp xảy ra trong kế hoạch. Nếu nó xảy ra ở bên trái kế hoạch và thường là một vài hàng, có thể có các khu vực khác có yếu tố cải thiện lớn hơn cần tập trung vào. Sắp xếp ở bên trái là mẫu mà chúng tôi tập trung vào ngày hôm nay, nhưng Sắp xếp không phải lúc nào cũng xảy ra do LỆNH THEO. Nếu bạn thấy Sắp xếp ở ngoài cùng bên phải của kế hoạch và có nhiều hàng di chuyển qua phần đó của kế hoạch, bạn biết rằng bạn đã tìm thấy một nơi tốt để bắt đầu điều chỉnh.