SQL Server đã giới thiệu các đối tượng OLTP trong bộ nhớ trong SQL Server 2014. Có nhiều hạn chế trong bản phát hành đầu tiên; một số vấn đề đã được giải quyết trong SQL Server 2016 và dự kiến rằng nhiều vấn đề khác sẽ được giải quyết trong bản phát hành tiếp theo khi tính năng này tiếp tục phát triển. Cho đến nay, việc áp dụng In-Memory OLTP dường như không phổ biến lắm, nhưng khi tính năng này trưởng thành, tôi hy vọng sẽ có nhiều khách hàng bắt đầu hỏi về việc triển khai. Như với bất kỳ thay đổi lược đồ hoặc mã lớn nào, tôi khuyên bạn nên kiểm tra kỹ lưỡng để xác định xem OLTP trong bộ nhớ có mang lại những lợi ích như mong đợi hay không. Với ý nghĩ đó, tôi muốn xem hiệu suất thay đổi như thế nào đối với các câu lệnh INSERT, UPDATE và DELETE rất đơn giản với In-Memory OLTP. Tôi hy vọng rằng nếu tôi có thể chứng minh việc chốt hoặc khóa là một vấn đề với các bảng dựa trên đĩa, thì các bảng trong bộ nhớ sẽ cung cấp giải pháp, vì chúng không có khóa và không có chốt.
Tôi đã phát triển thử nghiệm sau trường hợp:
- Một bảng dựa trên đĩa với các thủ tục được lưu trữ truyền thống cho DML.
- Bảng Trong Bộ nhớ với các thủ tục được lưu trữ truyền thống cho DML.
- Một bảng trong bộ nhớ với các thủ tục được biên dịch nguyên bản cho DML.
Tôi quan tâm đến việc so sánh hiệu suất của các thủ tục được lưu trữ truyền thống và các thủ tục được biên dịch tự nhiên, bởi vì một hạn chế của thủ tục được biên dịch tự nhiên là bất kỳ bảng nào được tham chiếu phải là Trong Bộ nhớ. Mặc dù các sửa đổi đơn hàng, đơn lẻ có thể phổ biến trong một số hệ thống, tôi thường thấy các sửa đổi xảy ra trong một thủ tục được lưu trữ lớn hơn với nhiều câu lệnh (SELECT và DML) truy cập một hoặc nhiều bảng. Tài liệu OLTP trong bộ nhớ thực sự khuyên bạn nên sử dụng các thủ tục được biên dịch nguyên bản để có được lợi ích cao nhất về mặt hiệu suất. Tôi muốn hiểu nó đã cải thiện hiệu suất đến mức nào.
Thiết lập
Tôi đã tạo cơ sở dữ liệu với nhóm tệp được tối ưu hóa bộ nhớ và sau đó tạo ba bảng khác nhau trong cơ sở dữ liệu (một bảng dựa trên đĩa, hai trong bộ nhớ):
- DiskTable
- InMemory_Temp1
- InMemory_Temp2
DDL gần như giống nhau đối với tất cả các đối tượng, tính trên đĩa so với trong bộ nhớ khi thích hợp. DiskTable DDL so với DDL trong bộ nhớ:
CREATE TABLE [dbo].[DiskTable] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED, [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) ON [DiskTables]; GO CREATE TABLE [dbo].[InMemTable_Temp1] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000), [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) WITH (MEMORY_OPTIMIZED=ON, DURABILITY = SCHEMA_AND_DATA); GO
Tôi cũng đã tạo chín thủ tục được lưu trữ - một thủ tục cho mỗi kết hợp bảng / sửa đổi.
- DiskTable_Insert
- DiskTable_Update
- DiskTable_Delete
- InMemRegularSP_Insert
- InMemRegularSP _Update
- InMemRegularSP _Delete
- InMemCompiledSP_Insert
- InMemCompiledSP_Update
- InMemCompiledSP_Delete
Mỗi thủ tục được lưu trữ chấp nhận một đầu vào số nguyên để lặp lại cho số lượng sửa đổi đó. Các thủ tục được lưu trữ tuân theo cùng một định dạng, các biến thể chỉ là bảng được truy cập và liệu đối tượng có được biên dịch nguyên bản hay không. Bạn có thể tìm thấy mã hoàn chỉnh để tạo cơ sở dữ liệu và các đối tượng tại đây, với ví dụ câu lệnh INSERT và UPDATE bên dưới:
CREATE PROCEDURE dbo.[DiskTable_Inserts] @NumRows INT AS BEGIN SET NOCOUNT ON; DECLARE @Name INT; DECLARE @Type INT; DECLARE @ColInt INT; DECLARE @ColVarchar VARCHAR(255) DECLARE @RowLoop INT = 1; WHILE (@RowLoop <= @NumRows) BEGIN SET @Name = CONVERT (INT, RAND () * 1000) + 1; SET @Type = CONVERT (INT, RAND () * 100) + 1; SET @ColInt = CONVERT (INT, RAND () * 850) + 1 SET @ColVarchar = CONVERT (INT, RAND () * 1300) + 1 INSERT INTO [dbo].[DiskTable] ( [Name], [Type], [c4], [c5], [c6], [c7], [c8], [c9], [c10], [c11] ) VALUES (@Name, @Type, @ColInt, @ColInt + (CONVERT (INT, RAND () * 20) + 1), @ColInt + (CONVERT (INT, RAND () * 30) + 1), @ColInt + (CONVERT (INT, RAND () * 40) + 1), @ColVarchar, @ColVarchar + (CONVERT (INT, RAND () * 20) + 1), @ColVarchar + (CONVERT (INT, RAND () * 30) + 1), @ColVarchar + (CONVERT (INT, RAND () * 40) + 1)) SELECT @RowLoop = @RowLoop + 1 END END GO CREATE PROCEDURE [InMemUpdates_CompiledSP] @NumRows INT WITH NATIVE_COMPILATION, SCHEMABINDING AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english') DECLARE @RowLoop INT = 1; DECLARE @ID INT DECLARE @RowNum INT = @@SPID * (CONVERT (INT, RAND () * 1000) + 1) WHILE (@RowLoop <= @NumRows) BEGIN SELECT @ID = ID FROM [dbo].[IDs_InMemTable2] WHERE RowNum = @RowNum UPDATE [dbo].[InMemTable_Temp2] SET [c4] = [c5] * 2 WHERE [ID] = @ID SET @RowLoop = @RowLoop + 1 SET @RowNum = @RowNum + (CONVERT (INT, RAND () * 10) + 1) END END GO
Lưu ý:Các bảng IDs_ * đã được tạo lại sau khi mỗi bộ INSERT hoàn thành và dành riêng cho ba trường hợp khác nhau.
Phương pháp thử nghiệm
Thử nghiệm được thực hiện bằng cách sử dụng các tập lệnh .cmd sử dụng sqlcmd để gọi một tập lệnh thực thi quy trình được lưu trữ, ví dụ:
sqlcmd -S CAP \ ROGERS -i "C:\ Temp \ SentryOne \ InMemTable_RegularDeleteSP_100.sql"thoát
Tôi đã sử dụng cách tiếp cận này để tạo một hoặc nhiều kết nối đến cơ sở dữ liệu sẽ chạy đồng thời. Ngoài việc hiểu những thay đổi cơ bản đối với hiệu suất, tôi cũng muốn kiểm tra ảnh hưởng của các khối lượng công việc khác nhau. Các tập lệnh này được khởi tạo từ một máy riêng biệt để loại bỏ chi phí của các kết nối khởi tạo. Mỗi thủ tục được lưu trữ được thực thi 1000 lần bởi một kết nối và tôi đã thử nghiệm 1 kết nối, 10 kết nối và 100 kết nối (lần lượt các sửa đổi 1000, 10000 và 100000). Tôi đã nắm bắt các số liệu hiệu suất bằng cách sử dụng Cửa hàng truy vấn và cũng đã ghi lại Thống kê chờ. Với Query Store, tôi có thể nắm bắt thời lượng và CPU trung bình cho mỗi quy trình được lưu trữ. Dữ liệu thống kê chờ được thu thập cho từng kết nối bằng cách sử dụng dm_exec_session_wait_stats, sau đó được tổng hợp cho toàn bộ quá trình kiểm tra.
Tôi đã chạy mỗi bài kiểm tra bốn lần và sau đó tính toán mức trung bình tổng thể cho dữ liệu được sử dụng trong bài đăng này. Các tập lệnh được sử dụng để kiểm tra khối lượng công việc có thể được tải xuống từ đây.
Kết quả
Như người ta dự đoán, hiệu suất với các đối tượng Trong bộ nhớ tốt hơn so với các đối tượng dựa trên đĩa. Tuy nhiên, bảng Trong Bộ nhớ với quy trình được lưu trữ thông thường đôi khi có hiệu suất tương đương hoặc chỉ tốt hơn một chút so với bảng dựa trên đĩa với quy trình được lưu trữ thông thường. Hãy nhớ rằng:Tôi quan tâm đến việc tìm hiểu xem liệu tôi có thực sự cần một thủ tục được lưu trữ đã biên dịch để có được lợi ích lớn với bảng trong bộ nhớ hay không. Đối với kịch bản này, tôi đã làm. Trong mọi trường hợp, bảng trong bộ nhớ với thủ tục được biên dịch nguyên bản có hiệu suất tốt hơn đáng kể. Hai biểu đồ bên dưới hiển thị cùng một dữ liệu, nhưng với các tỷ lệ khác nhau cho trục x, để chứng minh hiệu suất đó cho các thủ tục được lưu trữ thông thường sửa đổi dữ liệu bị giảm chất lượng với nhiều kết nối đồng thời hơn.
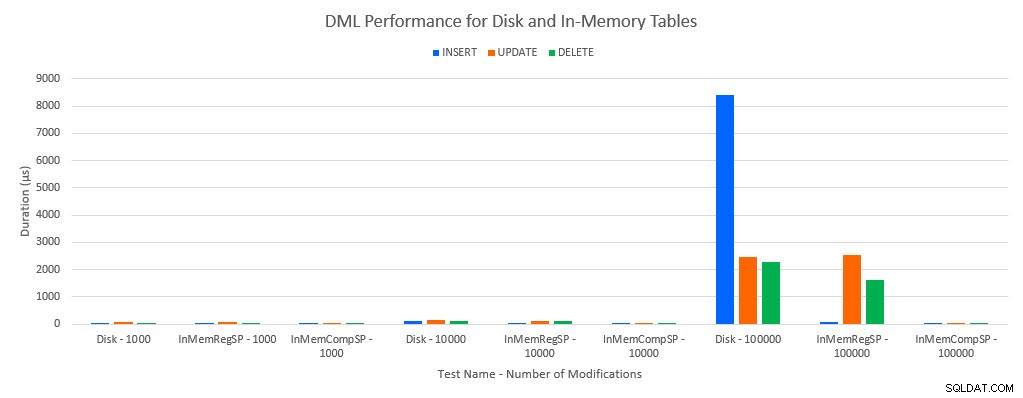
Hiệu suất DML theo Kiểm tra và Khối lượng công việc
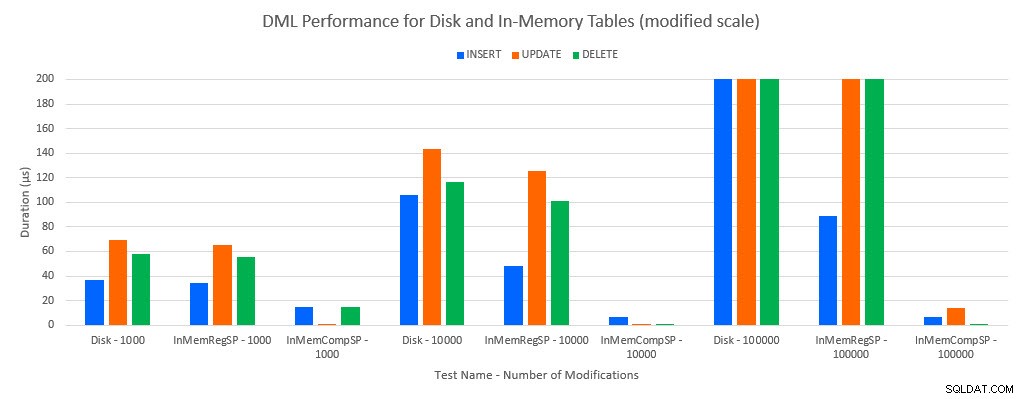
Hiệu suất DML theo Kiểm tra và Khối lượng công việc [Quy mô đã sửa đổi]
Ngoại lệ là CHÈN vào bảng Trong Bộ nhớ với thủ tục được lưu trữ thông thường. Với 100 kết nối, thời lượng trung bình là hơn 8ms đối với bảng dựa trên đĩa, nhưng dưới 100 micro giây đối với bảng Trong bộ nhớ. Lý do có thể là do không có khóa và chốt với bảng Trong bộ nhớ và điều này được hỗ trợ với dữ liệu thống kê chờ:
| Kiểm tra | CHÈN | CẬP NHẬT | XÓA |
|---|---|---|---|
| Bảng đĩa - 1000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_RegularSP - 1000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP - 1000 | WRITELOG | MEMORY_ALLOCATION_EXT | MEMORY_ALLOCATION_EXT |
| Bảng đĩa - 10.000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_RegularSP - 10.000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP - 10.000 | WRITELOG | WRITELOG | MEMORY_ALLOCATION_EXT |
| Bảng đĩa - 100.000 | PAGELATCH_EX | WRITELOG | WRITELOG |
| InMemTable_RegularSP - 100.000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP - 100.000 | WRITELOG | WRITELOG | WRITELOG |
Chờ số liệu thống kê bằng cách kiểm tra
Dữ liệu thống kê chờ được liệt kê ở đây dựa trên Tổng thời gian chờ của tài nguyên (thường cũng được dịch thành thời gian tài nguyên trung bình cao nhất, nhưng vẫn có ngoại lệ). Kiểu chờ WRITELOG là yếu tố hạn chế trong phần lớn thời gian của hệ thống này. Tuy nhiên, PAGELATCH_EX đợi 100 kết nối đồng thời chạy câu lệnh INSERT gợi ý rằng với tải bổ sung, hành vi khóa và chốt tồn tại với các bảng dựa trên đĩa có thể là yếu tố hạn chế. Trong kịch bản CẬP NHẬT và XÓA với 10 và 100 kết nối cho các bài kiểm tra bảng dựa trên đĩa, Thời gian chờ tài nguyên trung bình là cao nhất cho các khóa (LCK_M_X).
Kết luận
OLTP trong bộ nhớ hoàn toàn có thể tăng hiệu suất cho khối lượng công việc phù hợp. Tuy nhiên, các ví dụ được thử nghiệm ở đây cực kỳ đơn giản và không nên được coi là lý do đơn thuần để chuyển sang giải pháp Trong bộ nhớ. Có nhiều hạn chế vẫn tồn tại cần được xem xét và phải kiểm tra kỹ lưỡng trước khi quá trình di chuyển xảy ra (đặc biệt vì di chuyển sang bảng Trong bộ nhớ là một quá trình ngoại tuyến). Nhưng đối với trường hợp phù hợp, tính năng mới này có thể cung cấp một sự thúc đẩy hiệu suất. Miễn là bạn hiểu rằng một số hạn chế cơ bản vẫn sẽ tồn tại, chẳng hạn như tốc độ nhật ký giao dịch cho các bảng bền, mặc dù rất có thể theo cách giảm - bất kể bảng tồn tại trên đĩa hay trong bộ nhớ.



