Khách Tác giả:Michael J Swart (@MJSwart)
Tôi dành nhiều thời gian để dịch các yêu cầu phần mềm thành lược đồ và truy vấn. Những yêu cầu này đôi khi dễ thực hiện nhưng thường rất khó. Tôi muốn nói về các lựa chọn thiết kế giao diện người dùng dẫn đến các mẫu truy cập dữ liệu khó triển khai bằng SQL Server.
Sắp xếp theo cột
Sắp xếp theo cột là một mô hình quen thuộc đến mức chúng ta có thể coi đó là điều hiển nhiên. Mỗi khi chúng ta tương tác với phần mềm hiển thị bảng, chúng ta có thể mong đợi các cột có thể sắp xếp được như thế này:
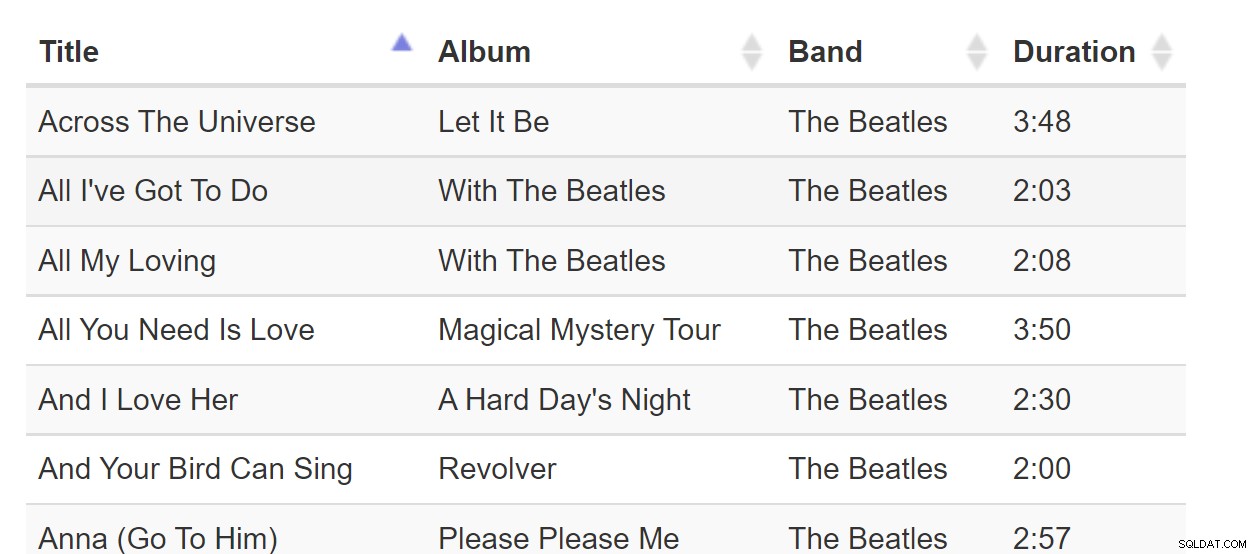
Sắp xếp theo Colunn là một mô hình tuyệt vời khi tất cả dữ liệu có thể nằm gọn trong trình duyệt. Nhưng nếu tập dữ liệu lớn hàng tỷ hàng, điều này có thể trở nên khó xử ngay cả khi trang web chỉ yêu cầu một trang dữ liệu. Hãy xem xét bảng các bài hát này:
CREATE TABLE Songs
(
Title NVARCHAR(300) NOT NULL,
Album NVARCHAR(300) NOT NULL,
Band NVARCHAR(300) NOT NULL,
DurationInSeconds INT NOT NULL,
CONSTRAINT PK_Songs PRIMARY KEY CLUSTERED (Title),
);
CREATE NONCLUSTERED INDEX IX_Songs_Album
ON dbo.Songs(Album)
INCLUDE (Band, DurationInSeconds);
CREATE NONCLUSTERED INDEX IX_Songs_Band
ON dbo.Songs(Band); Và hãy xem xét bốn truy vấn này được sắp xếp theo từng cột:
SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Title; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Album; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Band; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY DurationInSeconds;
Ngay cả đối với một truy vấn đơn giản này, vẫn có các kế hoạch truy vấn khác nhau. Hai truy vấn đầu tiên sử dụng các chỉ mục bao gồm:
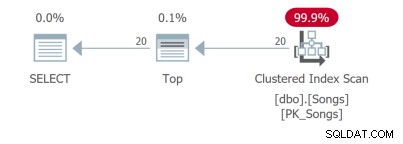
Truy vấn thứ ba cần thực hiện tra cứu khóa không phải là lý tưởng:
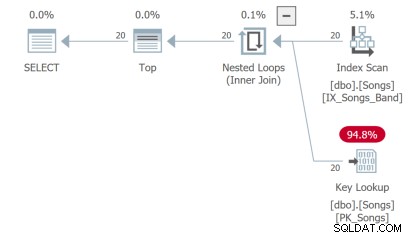
Nhưng điều tồi tệ nhất là truy vấn thứ tư cần phải quét toàn bộ bảng và thực hiện sắp xếp để trả về 20 hàng đầu tiên:
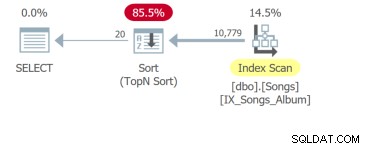
Vấn đề là mặc dù sự khác biệt duy nhất là mệnh đề ORDER BY, những truy vấn đó phải được phân tích riêng biệt. Đơn vị cơ bản của điều chỉnh SQL là truy vấn. Vì vậy, nếu bạn cho tôi xem các yêu cầu về giao diện người dùng với mười cột có thể sắp xếp, tôi sẽ hiển thị cho bạn mười truy vấn để phân tích.
Khi nào thì điều này trở nên khó xử?
Tính năng Sắp xếp theo Cột là một mẫu giao diện người dùng tuyệt vời, nhưng nó có thể trở nên khó xử nếu dữ liệu đến từ một bảng đang phát triển khổng lồ với rất nhiều cột. Có thể hấp dẫn để tạo các chỉ mục bao trùm trên mọi cột, nhưng điều đó có những sự cân bằng khác. Chỉ mục Columnstore có thể hữu ích trong một số trường hợp, nhưng điều đó lại dẫn đến một mức độ khó xử khác. Không phải lúc nào cũng có một giải pháp thay thế dễ dàng.
Kết quả theo trang
Sử dụng kết quả phân trang là một cách tốt để không làm người dùng choáng ngợp với quá nhiều thông tin cùng một lúc. Đó cũng là một cách tốt để không làm tràn ngập các máy chủ cơ sở dữ liệu… thông thường.
Hãy xem xét thiết kế này:

Dữ liệu đằng sau ví dụ này yêu cầu đếm và xử lý toàn bộ tập dữ liệu để báo cáo số lượng kết quả. Truy vấn cho ví dụ này có thể sử dụng cú pháp như sau:
... ORDER BY LastModifiedTime OFFSET @N ROWS FETCH NEXT 25 ROWS ONLY;
Đó là cú pháp thuận tiện và truy vấn chỉ tạo ra 25 hàng. Nhưng chỉ vì tập hợp kết quả nhỏ, điều đó không nhất thiết có nghĩa là nó rẻ. Giống như chúng ta đã thấy với mẫu Sắp xếp theo cột, toán tử TOP chỉ rẻ nếu trước tiên nó không cần phải sắp xếp nhiều dữ liệu.
Yêu cầu trang không đồng bộ
Khi người dùng điều hướng từ trang kết quả này sang trang kết quả tiếp theo, các yêu cầu web liên quan có thể được phân tách bằng giây hoặc phút. Điều này dẫn đến các vấn đề trông giống như những cạm bẫy gặp phải khi sử dụng NOLOCK. Ví dụ:
SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY; -- wait a little bit SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 25 ROWS FETCH NEXT 25 ROWS ONLY;
Khi một hàng được thêm vào giữa hai yêu cầu, người dùng có thể thấy cùng một hàng hai lần. Và nếu một hàng bị xóa, người dùng có thể bỏ lỡ một hàng khi họ điều hướng các trang. Mẫu Kết quả theo trang này tương đương với "Cho tôi hàng 26-50". Khi câu hỏi thực sự nên là "Cho tôi 25 hàng tiếp theo". Sự khác biệt là rất nhỏ.
Mẫu đẹp hơn
Với Kết quả theo trang, “OFFSET @N ROWS” đó có thể mất nhiều thời gian hơn khi @N phát triển. Thay vào đó, hãy xem xét các nút Load-More hoặc Infinite-Scrolling. Với phân trang Tải nhiều hơn, ít nhất có cơ hội sử dụng hiệu quả một chỉ mục. Truy vấn sẽ giống như sau:
SELECT [Some Columns] FROM [Some Table] WHERE [Sort Value] > @Bookmark ORDER BY [Sort Value] FETCH NEXT 25 ROWS ONLY;
Nó vẫn gặp phải một số cạm bẫy của các yêu cầu trang không đồng bộ, nhưng do có dấu trang, người dùng sẽ tiếp tục tại nơi họ đã dừng lại.
Tìm kiếm văn bản cho chuỗi con
Tìm kiếm ở khắp mọi nơi trên internet. Nhưng giải pháp nào nên được sử dụng ở back end? Tôi muốn cảnh báo không nên tìm kiếm chuỗi con bằng bộ lọc LIKE của SQL Server với các ký tự đại diện như sau:
SELECT Title, Category FROM MyContent WHERE Title LIKE '%' + @SearchTerm + '%';
Nó có thể dẫn đến những kết quả khó xử như thế này:
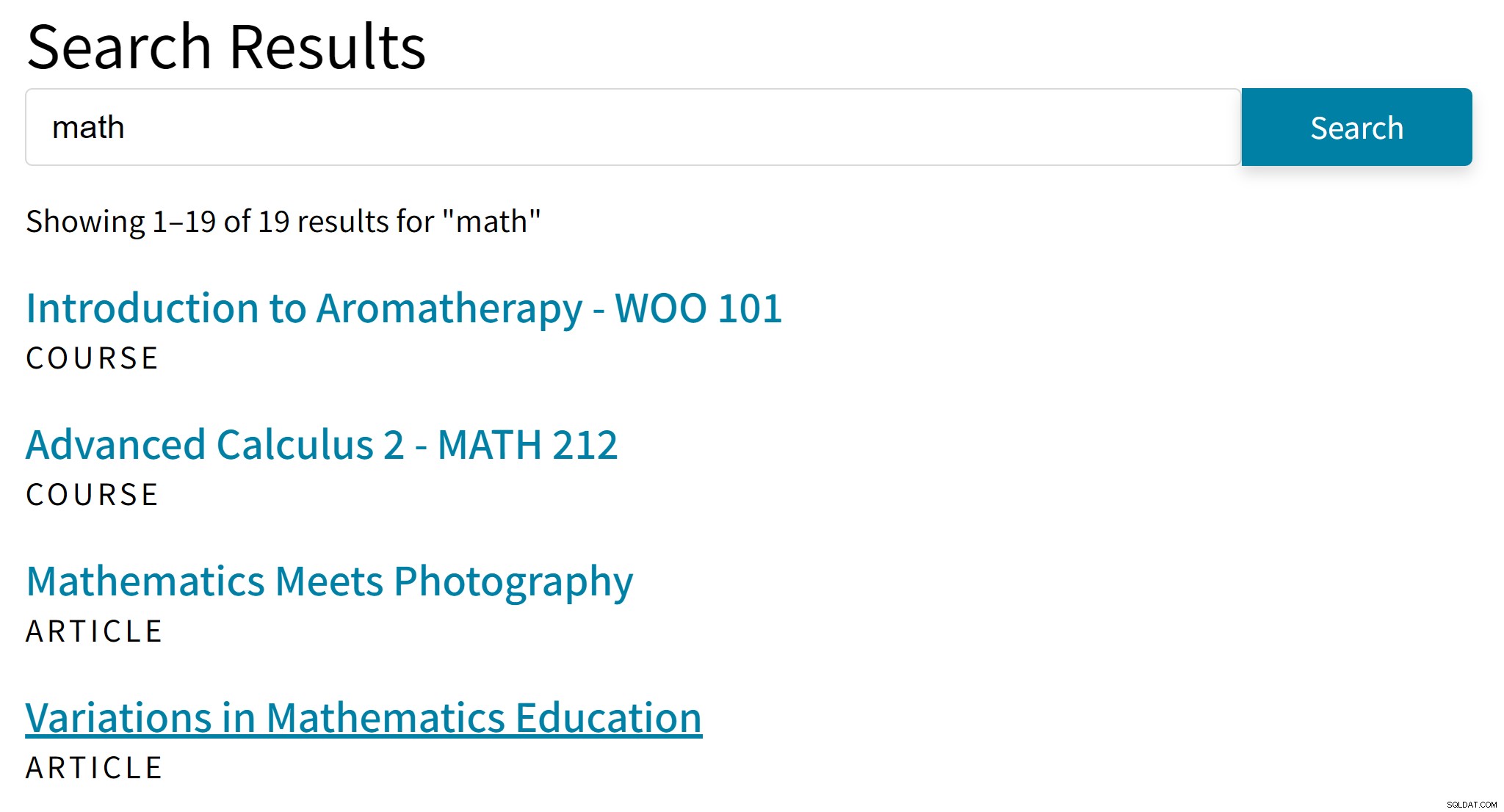
“Liệu pháp hương thơm” có lẽ không phải là một thành công tốt cho cụm từ tìm kiếm “toán học”. Trong khi đó, kết quả tìm kiếm thiếu các bài báo chỉ đề cập đến Đại số hoặc Lượng giác.
Cũng có thể rất khó để thực hiện một cách hiệu quả bằng cách sử dụng SQL Server. Không có chỉ mục đơn giản nào hỗ trợ loại tìm kiếm này. Paul White đã đưa ra một giải pháp phức tạp với Tìm kiếm chuỗi ký tự đại diện Trigram trong SQL Server. Cũng có những khó khăn có thể xảy ra với đối chiếu và Unicode. Nó có thể trở thành một giải pháp đắt tiền cho trải nghiệm người dùng không quá tốt.
Sử dụng gì để thay thế
Tìm kiếm toàn văn bản của SQL Server có vẻ như nó có thể hữu ích, nhưng cá nhân tôi chưa bao giờ sử dụng nó. Trong thực tế, tôi chỉ thấy thành công trong các giải pháp bên ngoài SQL Server (ví dụ:Elasticsearch).
Kết luận
Theo kinh nghiệm của mình, tôi nhận thấy rằng các nhà thiết kế phần mềm thường rất dễ tiếp thu phản hồi rằng các thiết kế của họ đôi khi khó thực hiện. Khi không, tôi thấy hữu ích khi làm nổi bật những cạm bẫy, chi phí và thời gian giao hàng. Loại phản hồi đó là cần thiết để giúp xây dựng các giải pháp có thể bảo trì, có thể mở rộng.
Giới thiệu về tác giả
 Michael J Swart là một blogger chuyên nghiệp và đam mê cơ sở dữ liệu, người tập trung vào phát triển cơ sở dữ liệu và kiến trúc phần mềm. Anh ấy thích nói về bất cứ điều gì liên quan đến dữ liệu, đóng góp cho các dự án cộng đồng. Michael viết blog với tên "Người thì thầm cơ sở dữ liệu" tại michaeljswart.com.
Michael J Swart là một blogger chuyên nghiệp và đam mê cơ sở dữ liệu, người tập trung vào phát triển cơ sở dữ liệu và kiến trúc phần mềm. Anh ấy thích nói về bất cứ điều gì liên quan đến dữ liệu, đóng góp cho các dự án cộng đồng. Michael viết blog với tên "Người thì thầm cơ sở dữ liệu" tại michaeljswart.com.