Đối với bất kỳ cơ sở dữ liệu mới nào được tạo trong SQL Server, giá trị mặc định cho tùy chọn Thống kê Tự động Cập nhật được bật . Tôi nghi ngờ rằng hầu hết các DBA đều để tùy chọn được bật vì nó cho phép trình tối ưu hóa tự động cập nhật thống kê khi chúng bị vô hiệu và thông thường bạn nên để tùy chọn này được bật. Thống kê cũng được cập nhật khi các chỉ mục được xây dựng lại và mặc dù không có gì lạ khi các thống kê được quản lý tốt thông qua tùy chọn thống kê cập nhật tự động và thông qua việc xây dựng lại chỉ mục, đôi khi DBA có thể thấy cần thiết lập một công việc thường xuyên để cập nhật thống kê hoặc tập hợp các thống kê.
Quản lý tùy chỉnh số liệu thống kê thường liên quan đến lệnh UPDATE STATISTICS, có vẻ khá lành tính. Nó có thể được chạy cho tất cả các thống kê cho một bảng hoặc chế độ xem được lập chỉ mục, hoặc cho một thống kê cụ thể. Có thể sử dụng mẫu mặc định, có thể chỉ định tỷ lệ mẫu cụ thể hoặc số hàng để lấy mẫu hoặc bạn có thể sử dụng cùng một giá trị mẫu đã được sử dụng trước đó. Nếu thống kê được cập nhật cho một bảng hoặc chế độ xem được lập chỉ mục, bạn có thể chọn cập nhật tất cả thống kê, chỉ thống kê chỉ mục hoặc chỉ thống kê cột. Và cuối cùng, bạn có thể tắt tùy chọn thống kê cập nhật tự động cho một thống kê.
Đối với hầu hết các DBA, cân nhắc lớn nhất có thể là khi nào để chạy câu lệnh UPDATE STATISTICS. Nhưng các DBA cũng quyết định, có ý thức hay không, kích thước mẫu cho bản cập nhật. Kích thước mẫu được chọn có thể ảnh hưởng đến hiệu suất của bản cập nhật thực tế, cũng như hiệu suất của các truy vấn.
Hiểu ảnh hưởng của kích thước mẫu
Kích thước mẫu mặc định cho THỐNG KÊ CẬP NHẬT đến từ một thuật toán phi tuyến tính và kích thước mẫu giảm khi kích thước bảng lớn hơn, như Joe Sack đã trình bày trong bài đăng của mình, Kiểm tra lấy mẫu mặc định số liệu thống kê tự động cập nhật. Trong một số trường hợp, kích thước mẫu có thể không đủ lớn để thu thập đủ thông tin thú vị hoặc đúng thông tin, cho biểu đồ thống kê, như Conor Cunningham đã lưu ý trong bài đăng Tỷ lệ mẫu thống kê của mình. Nếu mẫu mặc định không tạo biểu đồ tốt, các DBA có thể chọn cập nhật thống kê với tỷ lệ lấy mẫu cao hơn, lên đến FULLSCAN (quét tất cả các hàng trong bảng hoặc chế độ xem được lập chỉ mục). Nhưng như Conor đã đề cập trong bài đăng của mình, việc quét nhiều hàng hơn sẽ phải trả giá và DBA gặp thách thức trong việc quyết định có chạy FULLSCAN để thử và tạo biểu đồ "tốt nhất" có thể hay lấy mẫu một tỷ lệ phần trăm nhỏ hơn để giảm thiểu tác động hiệu suất của bản cập nhật.
Để thử và hiểu tại điểm nào một mẫu mất nhiều thời gian hơn FULLSCAN, tôi đã chạy các câu lệnh sau đối với các bản sao của bảng SalesOrderDetail đã được phóng to bằng cách sử dụng tập lệnh của Jonathan Kehayias:
| ID câu lệnh | CẬP NHẬT Tuyên bố THỐNG KÊ |
|---|---|
| 1 | CẬP NHẬT THỐNG KÊ [Doanh số]. [SalesOrderDetailEnlarged] VỚI FULLSCAN; |
| 2 | CẬP NHẬT THỐNG KÊ [Bán hàng]. [SalesOrderDetailEnlarged]; |
| 3 | CẬP NHẬT THỐNG KÊ [Doanh số]. [SalesOrderDetailEnlarged] VỚI MẪU 10 PERCENT; |
| 4 | CẬP NHẬT THỐNG KÊ [Doanh số]. [SalesOrderDetailEnlarged] VỚI MẪU 25 PERCENT; |
| 5 | CẬP NHẬT THỐNG KÊ [Doanh số]. [SalesOrderDetailEnlarged] VỚI MẪU 50 PERCENT; |
| 6 | CẬP NHẬT THỐNG KÊ [Doanh số]. [SalesOrderDetailEnlarged] VỚI MẪU 75 PERCENT; |
Tôi đã có ba bản sao của bảng SalesOrderDetailEnlarged, với các đặc điểm sau *:
| Số hàng | Số trang | MAXDOP | Bộ nhớ tối đa | Dung lượng | Máy |
|---|---|---|---|---|---|
| 23.899.449 | 363,284 | 4 | 8GB | SSD_1 | Máy tính xách tay |
| 607.312.902 | 7.757.200 | 16 | 54 GB | SSD_2 | Máy chủ Thử nghiệm |
| 607.312.902 | 7.757.200 | 16 | 54 GB | 15 nghìn | Máy chủ Thử nghiệm |
* Chi tiết bổ sung về phần cứng có ở cuối bài đăng này.
Tất cả các bản sao của bảng đều có thống kê sau và không có thống kê chỉ mục nào trong số ba thống kê chỉ mục bao gồm các cột:
| Thống kê | Loại | Các cột trong Khóa |
|---|---|---|
| PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID | Chỉ mục | SalesOrderID, SalesOrderDetailID |
| AK_SalesOrderDetailEnlarged_rowguid | Chỉ mục | rowguid |
| IX_SalesOrderDetailEnlarged_ProductID | Chỉ mục | ProductId |
| user_CarrierTrackingNumber | Cột | CarrierTrackingNumber |
Tôi đã chạy các câu lệnh UPDATE STATISTICS ở trên bốn lần, mỗi câu đối với bảng SalesOrderDetailEnlarged trên máy tính xách tay của mình và hai lần mỗi lần với bảng SalesOrderDetailEnlarged trên TestServer. Các câu lệnh được chạy theo thứ tự ngẫu nhiên mỗi lần và bộ đệm thủ tục và bộ đệm đệm được xóa trước mỗi câu lệnh cập nhật. Thời lượng và việc sử dụng tempdb cho mỗi nhóm câu lệnh (tính trung bình) được thể hiện trong biểu đồ bên dưới:
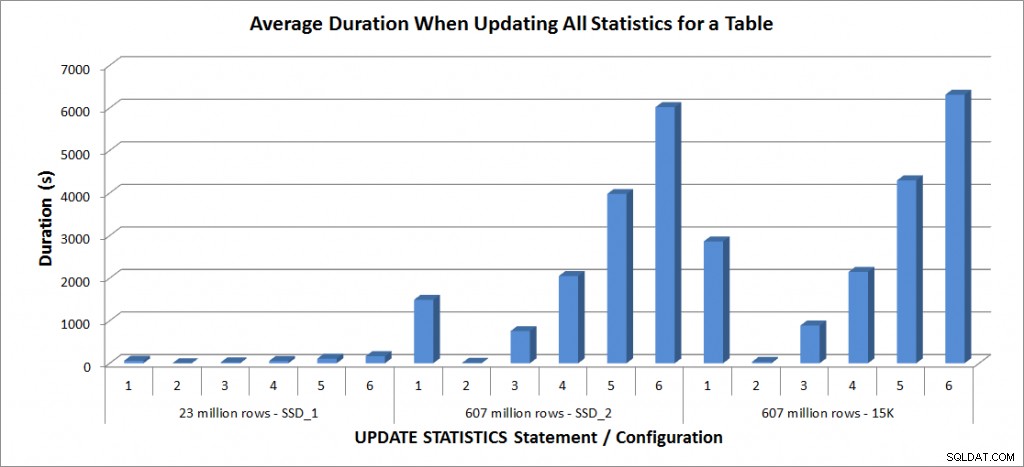
Thời lượng trung bình - Cập nhật tất cả thống kê cho SalesOrderDetailEnlarged
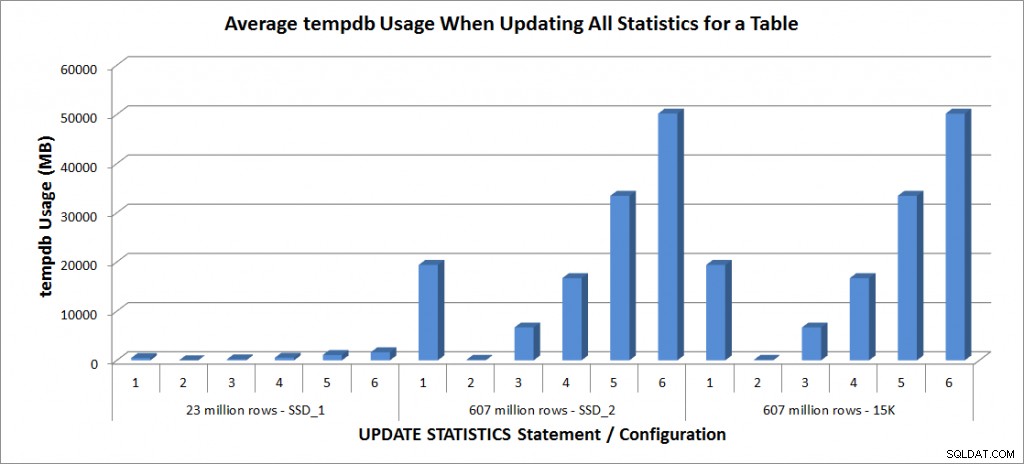
tempdb Usage - Cập nhật tất cả thống kê cho SalesOrderDetailEnlarged
Thời lượng cho bảng 23 triệu hàng đều dưới ba phút và được mô tả chi tiết hơn trong phần tiếp theo. Đối với bảng trên đĩa SSD_2, câu lệnh FULLSCAN mất 1492 giây (gần 25 phút) và bản cập nhật với mẫu 25% mất 2051 giây (hơn 34 phút). Ngược lại, trên đĩa 15K, câu lệnh FULLSCAN mất 2864 giây (hơn 47 phút) và bản cập nhật với mẫu 25% mất 2147 giây (gần 36 phút) - ít hơn thời gian của FULLSCAN. Tuy nhiên, quá trình cập nhật với mẫu 50% mất 4296 giây (hơn 71 phút).
Việc sử dụng Tempdb nhất quán hơn nhiều, cho thấy sự gia tăng ổn định khi kích thước mẫu tăng lên và sử dụng nhiều không gian tempdb hơn FULLSCAN ở khoảng từ 25% đến 50%. Điều đáng chú ý ở đây là THỐNG KÊ CẬP NHẬT không sử dụng tempdb, điều quan trọng cần nhớ khi bạn định kích thước tempdb cho môi trường SQL Server. Việc sử dụng Tempdb được đề cập trong mục CẬP NHẬT THỐNG KÊ BOL:
CẬP NHẬT THỐNG KÊ có thể sử dụng tempdb để sắp xếp mẫu các hàng để xây dựng thống kê. ”
Và hiệu ứng được ghi lại trong bài đăng của Linchi Shea, Tác động đến hiệu suất:thống kê tạm thời và cập nhật. Tuy nhiên, nó không phải là thứ luôn được đề cập trong các cuộc thảo luận về định cỡ tempdb. Nếu bạn có các bảng lớn và thực hiện cập nhật với FULLSCAN hoặc các giá trị mẫu cao, hãy lưu ý việc sử dụng tempdb.
Hiệu suất của các bản cập nhật có chọn lọc
Tiếp theo, tôi quyết định kiểm tra các câu lệnh CẬP NHẬT THỐNG KÊ cho các thống kê khác trên bảng, nhưng giới hạn các thử nghiệm của tôi ở bản sao của bảng có 23 triệu hàng. Sáu biến thể ở trên của câu lệnh CẬP NHẬT THỐNG KÊ đã được lặp lại bốn lần mỗi lần cho các thống kê riêng lẻ sau đây và sau đó được so sánh với bản cập nhật cho toàn bộ bảng:
- PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID
- IX_SalesOrderDetailEnlarged_ProductID
- user_CarrierTrackingNumber
Tất cả các bài kiểm tra đều được chạy với cấu hình nói trên trên máy tính xách tay của tôi và kết quả có trong biểu đồ bên dưới:
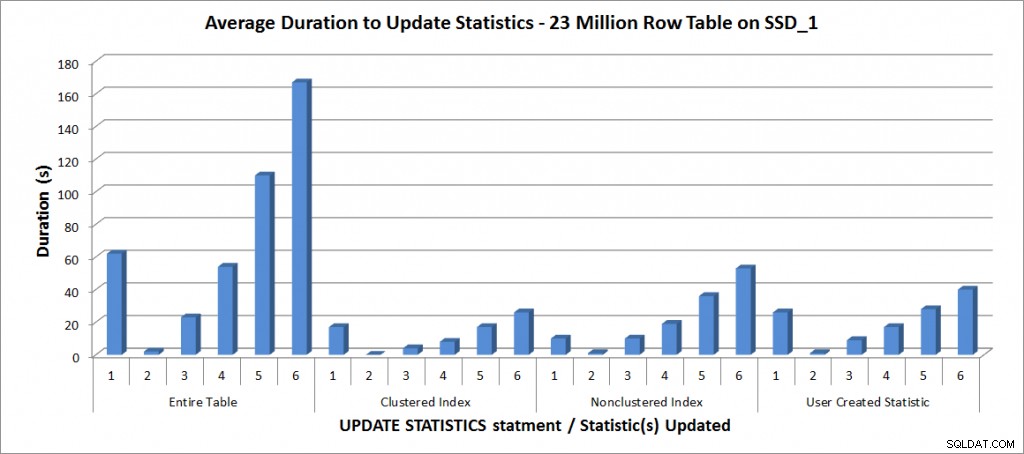
Thời lượng trung bình để CẬP NHẬT THỐNG KÊ - Tất cả thống kê so với Đã chọn
Như mong đợi, việc cập nhật một thống kê riêng lẻ mất ít thời gian hơn so với khi cập nhật tất cả thống kê cho bảng. Giá trị mà tại đó mẫu được cập nhật mất nhiều thời gian hơn FULLSCAN thay đổi:
| câu lệnh CẬP NHẬT | Thời lượng FULLSCAN | CẬP NHẬT đầu tiên mất nhiều thời gian hơn |
|---|---|---|
| Toàn bộ Bảng | 62 | 50% - 110 giây |
| Chỉ mục theo cụm | 17 | 75% - 26 giây |
| Chỉ mục không phân biệt | 10 | 25% - 19 giây |
| Thống kê do người dùng tạo | 26 | 50% - 28 giây |
Kết luận
Dựa trên dữ liệu này và dữ liệu FULLSCAN từ 607 triệu bảng hàng, không có cụ thể điểm giới hạn trong đó bản cập nhật được lấy mẫu mất nhiều thời gian hơn FULLSCAN; điểm đó phụ thuộc vào kích thước bảng và các tài nguyên có sẵn. Nhưng dữ liệu vẫn đáng giá vì nó chứng minh rằng có có một điểm mà giá trị được lấy mẫu có thể mất nhiều thời gian hơn để thu thập so với FULLSCAN. Nó một lần nữa đi đến việc biết dữ liệu của bạn. Điều này rất quan trọng để không chỉ hiểu liệu một bảng có cần quản lý thống kê tùy chỉnh hay không mà còn hiểu được kích thước mẫu lý tưởng để tạo biểu đồ hữu ích và cũng như tối ưu hóa việc sử dụng tài nguyên.
Thông số kỹ thuật
Thông số kỹ thuật máy tính xách tay:Dell M6500, 1 Intel i7 (4 lõi 2,13GHz và HT được kích hoạt để 8 lõi logic), bộ nhớ 32 GB, Windows 7, SQL Server 2012 SP1 (11.0.3128.0 x64), tệp cơ sở dữ liệu được lưu trữ trên SSD Samsung 265 GB PM810Thông số kỹ thuật của Máy chủ kiểm tra:Dell R720, 2 Intel E5-2670 (8 lõi 2,6 GHz và HT được kích hoạt để 16 lõi lôgic trên mỗi ổ cắm), bộ nhớ 64 GB, Windows 2012, SQL Server 2012 SP1 (11.0.3339.0 x64), tệp cơ sở dữ liệu cho một bảng nằm trên hai thẻ Fusion-io Duo MLC 640GB, các tệp cơ sở dữ liệu cho bảng còn lại nằm trên chín đĩa 15K RPM trong một mảng RAID5