Một trong những trường hợp sử dụng chỉ mục được lọc được đề cập trong Sách Trực tuyến liên quan đến cột chứa hầu hết NULL các giá trị. Ý tưởng là tạo chỉ mục được lọc loại trừ NULLs , dẫn đến một chỉ mục không được lọc nhỏ hơn và cần ít bảo trì hơn so với chỉ mục không được lọc tương đương. Một cách sử dụng phổ biến khác của các chỉ mục được lọc là lọc NULLs từ một UNIQUE lập chỉ mục, cung cấp cho người dùng hành vi của các công cụ cơ sở dữ liệu khác có thể mong đợi từ một UNIQUE mặc định chỉ mục hoặc ràng buộc:tính duy nhất chỉ được thực thi cho không phải NULL giá trị.
Thật không may, trình tối ưu hóa truy vấn có những hạn chế liên quan đến các chỉ mục được lọc. Bài đăng này xem xét một vài ví dụ ít được biết đến hơn.
Bảng mẫu
Chúng tôi sẽ sử dụng hai bảng (A &B) có cùng cấu trúc:một khóa chính thay thế theo cụm, một chủ yếu- NULL cột duy nhất (bỏ qua NULLs ) và cột đệm đại diện cho các cột khác có thể có trong bảng thực.
Cột được quan tâm chủ yếu là- NULL một, mà tôi đã khai báo là SPARSE . Tùy chọn thưa thớt là không bắt buộc, tôi chỉ đưa nó vào vì tôi không có nhiều cơ hội sử dụng nó. Trong mọi trường hợp, SPARSE có lẽ có ý nghĩa trong nhiều trường hợp mà dữ liệu cột được mong đợi chủ yếu là NULL . Vui lòng xóa thuộc tính thưa thớt khỏi các ví dụ nếu bạn muốn.
CREATE TABLE dbo.TableA (pk integer IDENTITY PRIMARY KEY, data bigint SPARSE NULL, padding binary (250) NOT NULL DEFAULT 0x); TẠO BẢNG dbo.TableB (pk integer IDENTITY PRIMARY KEY, data bigint SPARSE NULL, padding binary (250) NOT NULL DEFAULT 0x);
Mỗi bảng chứa các số từ 1 đến 2.000 trong cột dữ liệu với thêm 40.000 hàng trong đó cột dữ liệu là NULL :
- Các số 1 - 2.000INSERT dbo.TableA WITH (TABLOCKX) (dữ liệu) CHỌN ĐẦU (2000) ROW_NUMBER () OVER (ORDER BY (SELECT NULL)) TỪ sys.col cột AS cCROSS JOIN sys.columns AS c2ORDER BY ROW_NUMBER () HẾT (ORDER BY (SELECT NULL)); - NULLsINSERT TOP (40000) dbo.TableA VỚI (TABLOCKX) (dữ liệu) CHỌN CHUYỂN ĐỔI (bigint, NULL) TỪ sys.columns AS cCROSS JOIN sys.columns AS c2; - Sao chép vào TableBINSERT dbo.TableB WITH (TABLOCKX) (dữ liệu) CHỌN ta.dataFROM dbo.TableA AS ta;
Cả hai bảng đều nhận được UNIQUE chỉ mục được lọc cho 2.000 không phải NULL giá trị dữ liệu:
TẠO CHỈ SỐ KHÔNG ĐƯỢC ĐIỀU CHỈNH DUY NHẤT uqAON dbo.TableA (dữ liệu) TRONG ĐÓ dữ liệu KHÔNG ĐẦY ĐỦ; TẠO CHỈ SỐ KHÔNG ĐƯỢC ĐIỀU CHỈNH DUY NHẤT uqBON dbo.TableB (dữ liệu) TRONG ĐÓ dữ liệu KHÔNG ĐẦY ĐỦ;
Kết quả của DBCC SHOW_STATISTICS tóm tắt tình hình:
DBCC SHOW_STATISTICS (TableA, uqA) VỚI STAT_HEADER; DBCC SHOW_STATISTICS (TableB, uqB) VỚI STAT_HEADER;

Truy vấn mẫu
Truy vấn dưới đây thực hiện một phép nối đơn giản của hai bảng - hãy tưởng tượng các bảng có mối quan hệ cha-con nào đó và nhiều khóa ngoại là NULL. Dù sao thì cũng có gì đó dọc theo những dòng đó.
CHỌN ta.data, tb.dataFROM dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data;
Kế hoạch thực thi mặc định
Với SQL Server ở cấu hình mặc định, trình tối ưu hóa chọn một kế hoạch thực thi có tham gia các vòng lặp lồng nhau song song:
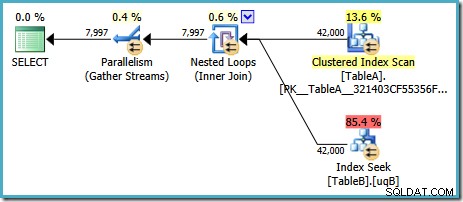
Kế hoạch này có chi phí ước tính là 7.7768 đơn vị tối ưu hóa ma thuật ™.
Tuy nhiên, Có một số điều kỳ lạ về kế hoạch này. Tìm kiếm chỉ mục sử dụng chỉ mục đã lọc của chúng tôi trên bảng B, nhưng truy vấn được điều khiển bởi Quét chỉ mục theo cụm của bảng A. Vị từ nối là một kiểm tra bình đẳng trên các cột dữ liệu, sẽ từ chối NULLs (bất kể ANSI_NULLS thiết lập). Chúng tôi có thể đã hy vọng trình tối ưu hóa sẽ thực hiện một số suy luận nâng cao dựa trên quan sát đó, nhưng không. Kế hoạch này đọc mọi hàng từ bảng A (bao gồm 40.000 NULL ), thực hiện tìm kiếm vào chỉ mục đã lọc trên bảng B cho từng chỉ mục, dựa trên thực tế là NULL sẽ không khớp với NULL trong tìm kiếm đó. Đây là một sự lãng phí công sức to lớn.
Điều kỳ lạ là trình tối ưu hóa phải nhận ra phép nối từ chối NULLs để chọn chỉ mục được lọc cho bảng B tìm kiếm, nhưng nó không nghĩ là lọc NULLs từ bảng A trước - hoặc vẫn tốt hơn, chỉ cần quét NULL -có chỉ số lọc miễn phí trên bảng A. Bạn có thể tự hỏi nếu đây là một quyết định dựa trên chi phí, có thể số liệu thống kê không tốt lắm? Có lẽ chúng ta nên buộc sử dụng chỉ mục đã lọc với một gợi ý? Gợi ý chỉ mục đã lọc trên bảng A chỉ dẫn đến cùng một kế hoạch với các vai trò được đảo ngược - quét bảng B và tìm kiếm trong bảng A. Việc buộc chỉ mục được lọc cho cả hai bảng sẽ tạo ra lỗi 8622 :bộ xử lý truy vấn không thể tạo ra một kế hoạch truy vấn.
Thêm vị từ NOT NULL
Nghi ngờ nguyên nhân có liên quan đến NULL ngụ ý - từ chối vị từ kết hợp, chúng tôi thêm một NOT NULL rõ ràng vị từ cho ON mệnh đề (hoặc WHERE nếu bạn thích, nó có cùng một điều ở đây):
CHỌN ta.data, tb.dataFROM dbo.TableA NHƯ taJOIN dbo.TableB NHƯ tb BẬT ta.data =tb.data VÀ ta.data KHÔNG ĐẦY ĐỦ;
Chúng tôi đã thêm NOT NULL kiểm tra cột của bảng A vì kế hoạch ban đầu đã quét chỉ mục nhóm của bảng đó thay vì sử dụng chỉ mục đã lọc của chúng tôi (tìm kiếm trong bảng B là tốt - nó đã sử dụng chỉ mục được lọc). Truy vấn mới hoàn toàn giống với truy vấn trước đó về mặt ngữ nghĩa, nhưng kế hoạch thực thi thì khác:
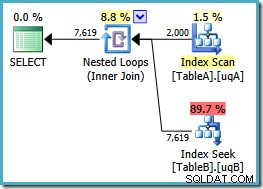
Bây giờ chúng ta đã quét chỉ mục được lọc hy vọng trên bảng A, tạo ra 2.000 không phải NULL các hàng để điều khiển vòng lặp lồng nhau tìm kiếm bảng B. Cả hai bảng đều đang sử dụng các chỉ mục đã lọc của chúng tôi rõ ràng là tối ưu ngay bây giờ:gói mới có giá chỉ 0,362835 đơn vị (giảm từ 7,7768). Tuy nhiên, chúng tôi có thể làm tốt hơn.
Thêm hai vị từ NOT NULL
NOT NULL thừa vị ngữ cho bảng A đã làm việc kỳ công; điều gì xảy ra nếu chúng ta cũng thêm một cái cho bảng B?
CHỌN ta.data, tb.dataFROM dbo.TableA NHƯ taJOIN dbo.TableB NHƯ tb ON ta.data =tb.data VÀ ta.data KHÔNG ĐẦY ĐỦ VÀ tb.data KHÔNG ĐỦ;
Truy vấn này về mặt logic vẫn giống như hai nỗ lực trước đó, nhưng kế hoạch thực hiện lại khác:
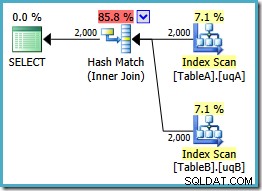
Kế hoạch này xây dựng một bảng băm cho 2.000 hàng từ bảng A, sau đó thăm dò các kết quả phù hợp bằng cách sử dụng 2.000 hàng từ bảng B. Số hàng ước tính được trả về nhiều hơn kế hoạch trước đó (bạn có nhận thấy ước tính 7.619 ở đó không?) và chi phí thực hiện ước tính lại giảm xuống, từ 0,362835 xuống 0,0772056 .
Bạn có thể thử buộc tham gia băm bằng cách sử dụng gợi ý trên bản gốc hoặc đơn- NOT NULL nhưng bạn sẽ không nhận được gói chi phí thấp được hiển thị ở trên. Trình tối ưu hóa không có khả năng giải thích đầy đủ về NULL - hành vi từ chối của phép nối vì nó áp dụng cho các chỉ mục đã lọc của chúng tôi mà không có cả hai vị từ thừa.
Bạn được phép ngạc nhiên vì điều này - ngay cả khi ý tưởng rằng một vị từ thừa là không đủ (chắc chắn nếu ta.data là NOT NULL và ta.data = tb.data , nó theo sau tb.data cũng là NOT NULL , phải không?)
Vẫn chưa hoàn hảo
Bạn hơi ngạc nhiên khi thấy một hàm băm tham gia ở đó. Nếu bạn đã quen với sự khác biệt chính giữa ba toán tử kết hợp vật lý, bạn có thể biết rằng tham gia băm là một ứng cử viên hàng đầu trong đó:
- Đầu vào được sắp xếp trước không khả dụng
- Đầu vào bản dựng băm nhỏ hơn đầu vào của đầu dò
- Đầu vào của đầu dò khá lớn
Không có điều nào trong số những điều này là đúng ở đây. Kỳ vọng của chúng tôi là kế hoạch tốt nhất cho truy vấn và tập dữ liệu này sẽ là phép kết hợp hợp nhất, khai thác đầu vào theo thứ tự có sẵn từ hai chỉ mục đã lọc của chúng tôi. Chúng tôi có thể thử gợi ý một phép nối hợp nhất, giữ lại hai phần ON bổ sung vị ngữ mệnh đề:
SELECT ta.data, tb.dataFROM dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data VÀ ta.data KHÔNG NULL VÀ tb.data KHÔNG NULLOPTION (MERGE JOIN);Hình dạng kế hoạch như chúng tôi hy vọng:
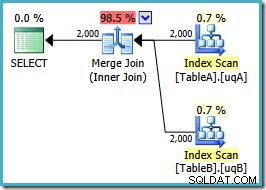
Một bản quét theo thứ tự của cả hai chỉ mục đã lọc, ước tính bản số tuyệt vời, thật tuyệt vời. Chỉ một vấn đề nhỏ:kế hoạch thực thi này tệ hơn nhiều ; chi phí ước tính đã tăng từ 0,0772056 lên 0,741527 . Lý do cho sự tăng vọt chi phí ước tính được tiết lộ bằng cách kiểm tra các thuộc tính của toán tử kết hợp hợp nhất:
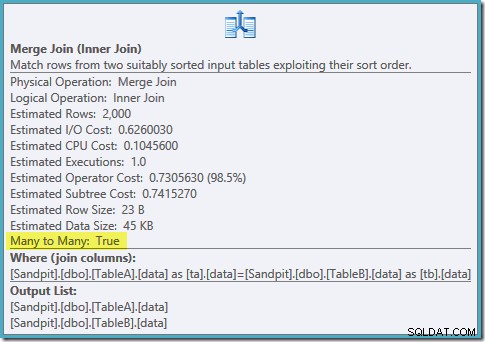
Đây là một phép nối nhiều-nhiều đắt tiền, trong đó công cụ thực thi phải theo dõi các bản sao từ đầu vào bên ngoài trong một bảng làm việc và tua lại khi cần thiết. Bản sao? Chúng tôi đang quét một chỉ mục duy nhất! Hóa ra trình tối ưu hóa không biết rằng chỉ mục duy nhất được lọc tạo ra các giá trị duy nhất (kết nối mục tại đây). Trên thực tế, đây là phép kết hợp một-một, nhưng trình tối ưu hóa chi phí nó như thể nhiều-nhiều, giải thích tại sao nó thích kế hoạch tham gia băm hơn.
Một chiến lược thay thế
Có vẻ như chúng tôi tiếp tục chống lại các giới hạn của trình tối ưu hóa khi sử dụng các chỉ mục được lọc ở đây (mặc dù đây là một trường hợp sử dụng được đánh dấu trong Sách Trực tuyến). Điều gì xảy ra nếu chúng tôi thử sử dụng chế độ xem thay thế?
Sử dụng Chế độ xem
Hai chế độ xem sau chỉ lọc các bảng cơ sở để hiển thị các hàng có cột dữ liệu
NOT NULL:TẠO CHẾ ĐỘ XEM dbo.VAWITH SCHEMABINDING ASSELECT pk, data, paddingFROM dbo.TableAWHERE data NOT NULL; GOCREATE VIEW dbo.VBWITH SCHEMABINDING ASSELECT pk, data, paddingFROM dbo.TableBWHERE data NOT NULL;Việc viết lại truy vấn ban đầu để sử dụng các chế độ xem là điều tầm thường:
CHỌN v.data, v2.dataFROM dbo.VA AS vJOIN dbo.VB AS v2 ON v.data =v2.data;Hãy nhớ truy vấn này ban đầu tạo ra một kế hoạch các vòng lặp lồng nhau song song có giá là 7,7768 các đơn vị. Với các tham chiếu chế độ xem, chúng tôi nhận được kế hoạch thực thi này:
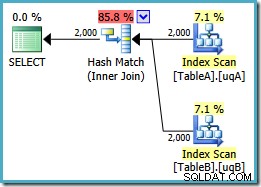
Đây chính xác là kế hoạch tham gia băm mà chúng tôi phải thêm
NOT NULLdư thừa các vị từ cần nhận với các chỉ mục đã lọc (chi phí là 0,0772056 đơn vị như trước đây). Điều này được mong đợi, bởi vì tất cả những gì chúng ta đã làm ở đây về cơ bản là đẩy thêmNOT NULLcác vị từ từ truy vấn đến một chế độ xem.Lập chỉ mục các chế độ xem
Chúng tôi cũng có thể thử cụ thể hóa các chế độ xem bằng cách tạo chỉ mục nhóm duy nhất trên cột pk:
TẠO cuq CHỈ SỐ ĐƯỢC ĐIỀU CHỈNH DUY NHẤT TRÊN dbo.VA (pk); TẠO CHỈ SỐ ĐƯỢC ĐIỀU CHỈNH DUY NHẤT TRÊN dbo.VB (pk);Giờ đây, chúng tôi có thể thêm các chỉ mục không phân biệt duy nhất trên cột dữ liệu đã lọc trong chế độ xem được lập chỉ mục:
TẠO CHỈ SỐ KHÔNG CHỈ ĐỊNH DUY NHẤT ix TRÊN dbo.VA (dữ liệu); TẠO CHỈ SỐ KHÔNG CHỈNH SỬA DUY NHẤT ix TRÊN dbo.VB (dữ liệu);Lưu ý rằng quá trình lọc được thực hiện trong chế độ xem, các chỉ mục không phân biệt này không tự được lọc.
Kế hoạch hoàn hảo
Giờ đây, chúng tôi đã sẵn sàng chạy truy vấn của mình đối với chế độ xem, sử dụng
NOEXPANDgợi ý bảng:CHỌN v.data, v2.dataFROM dbo.VA AS v VỚI (NOEXPAND) THAM GIA dbo.VB AS v2 VỚI (NOEXPAND) ON v.data =v2.data;Kế hoạch thực hiện là:
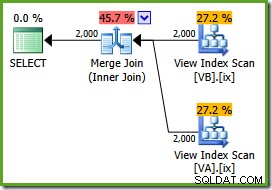
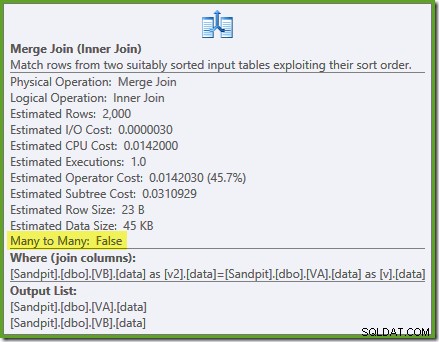
Trình tối ưu hóa có thể thấy phần chưa được lọc chỉ mục chế độ xem không phân tán là duy nhất, vì vậy không cần kết hợp nhiều thành nhiều. Kế hoạch thực hiện cuối cùng này có chi phí ước tính là 0,0310929 đơn vị - thậm chí còn thấp hơn kế hoạch tham gia băm (0,0772056 đơn vị). Điều này xác thực kỳ vọng của chúng tôi rằng liên kết hợp nhất phải có chi phí ước tính thấp nhất cho truy vấn này và tập dữ liệu mẫu.
NOEXPANDgợi ý là cần thiết ngay cả trong Phiên bản Doanh nghiệp để đảm bảo tính duy nhất được cung cấp bởi các chỉ mục chế độ xem được sử dụng bởi trình tối ưu hóa.Tóm tắt
Bài đăng này nêu bật hai hạn chế quan trọng của trình tối ưu hóa với các chỉ mục được lọc:
- Các vị từ kết hợp dự phòng có thể cần thiết để khớp với các chỉ mục đã lọc
- Các chỉ mục duy nhất được lọc không cung cấp thông tin về tính duy nhất cho trình tối ưu hóa
Trong một số trường hợp, có thể thực tế là chỉ cần thêm các vị từ thừa vào mọi truy vấn. Giải pháp thay thế là đóng gói các vị từ ngụ ý mong muốn trong một chế độ xem không lập chỉ mục. Kế hoạch đối sánh băm trong bài đăng này tốt hơn nhiều so với kế hoạch mặc định, mặc dù trình tối ưu hóa phải có thể tìm ra kế hoạch liên kết hợp nhất tốt hơn một chút. Đôi khi, bạn có thể cần lập chỉ mục chế độ xem và sử dụng NOEXPAND gợi ý (vẫn bắt buộc đối với các phiên bản Standard Edition). Trong các trường hợp khác, không có phương pháp nào trong số này sẽ phù hợp. Xin lỗi về điều đó :)