Lựa chọn của bạn về kiểu dữ liệu máy chủ SQL và kích thước của chúng có quan trọng không?
Câu trả lời nằm ở kết quả bạn nhận được. Cơ sở dữ liệu của bạn có bong bóng trong một thời gian ngắn không? Các truy vấn của bạn có chậm không? Bạn đã có kết quả sai? Làm thế nào về lỗi thời gian chạy trong quá trình chèn và cập nhật?
Đây không phải là một nhiệm vụ quá khó khăn nếu bạn biết mình đang làm gì. Hôm nay, bạn sẽ tìm hiểu 5 lựa chọn tồi tệ nhất mà người ta có thể thực hiện với những kiểu dữ liệu này. Nếu chúng đã trở thành thói quen của bạn, đây là điều chúng tôi nên sửa chữa vì lợi ích của bạn và người dùng của bạn.
Rất nhiều kiểu dữ liệu trong SQL, rất nhiều sự nhầm lẫn
Khi tôi lần đầu tiên học về kiểu dữ liệu SQL Server, rất nhiều lựa chọn. Tất cả các loại được trộn lẫn trong tâm trí tôi như đám mây từ này trong Hình 1:

Tuy nhiên, chúng tôi có thể sắp xếp nó thành các danh mục:
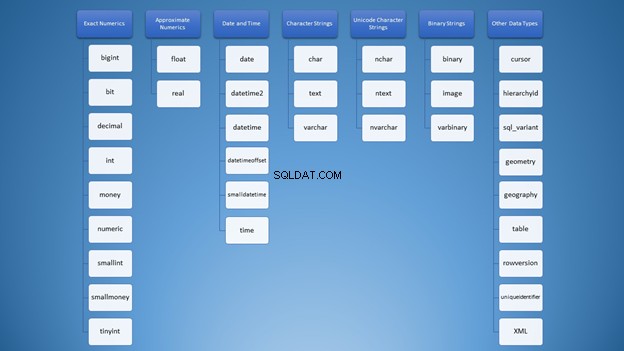
Tuy nhiên, để sử dụng chuỗi, bạn có rất nhiều tùy chọn có thể dẫn đến việc sử dụng sai. Lúc đầu, tôi nghĩ rằng varchar và nvarchar giống nhau. Bên cạnh đó, chúng đều là kiểu chuỗi ký tự. Sử dụng các con số cũng không khác gì. Là nhà phát triển, chúng tôi cần biết loại nào sẽ sử dụng trong các tình huống khác nhau.
Nhưng bạn có thể tự hỏi, điều tồi tệ nhất có thể xảy ra nếu tôi lựa chọn sai là gì? Để tôi kể cho bạn nghe!
1. Chọn kiểu dữ liệu SQL sai
Mục này sẽ sử dụng chuỗi và số nguyên để chứng minh quan điểm.
Sử dụng kiểu dữ liệu SQL chuỗi ký tự sai
Đầu tiên, hãy quay lại với chuỗi. Có một thứ được gọi là chuỗi Unicode và không phải Unicode. Cả hai đều có kích thước lưu trữ khác nhau. Bạn thường xác định điều này trên các cột và khai báo biến.
Cú pháp là varchar (n) / char (n) hoặc nvarchar (n) / nchar (n) ở đâu n là kích thước.
Lưu ý rằng n không phải là số ký tự mà là số byte. Đó là một quan niệm sai lầm phổ biến xảy ra bởi vì, trong varchar , số lượng ký tự giống với kích thước tính bằng byte. Nhưng không phải trong nvarchar .
Để chứng minh sự thật này, hãy tạo 2 bảng và đưa một số dữ liệu vào chúng.
CREATE TABLE dbo.VarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString VARCHAR(4000)
)
GO
CREATE TABLE dbo.NVarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString NVARCHAR(4000)
)
GO
INSERT INTO VarcharTable (someString)
VALUES (REPLICATE('x',4000))
GO 1000
INSERT INTO NVarcharTable (someString)
VALUES (REPLICATE(N'y',4000))
GO 1000
Bây giờ, hãy kiểm tra kích thước hàng của chúng bằng DATALENGTH.
SET STATISTICS IO ON
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM VarcharTable
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM NVarcharTable
SET STATISTICS IO OFF
Hình 3 cho thấy sự khác biệt là hai lần. Kiểm tra nó bên dưới.
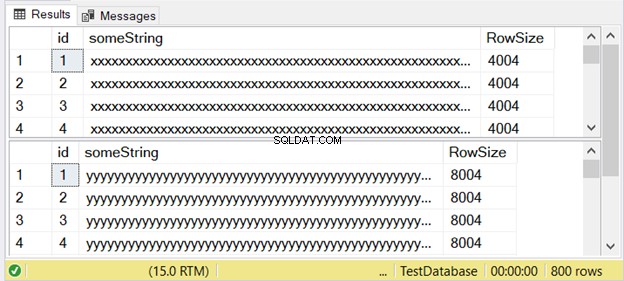
Lưu ý tập hợp kết quả thứ hai với kích thước hàng là 8004. Điều này sử dụng nvarchar loại dữ liệu. Nó cũng lớn hơn gần hai lần so với kích thước hàng của tập hợp kết quả đầu tiên. Và điều này sử dụng varchar kiểu dữ liệu.
Bạn thấy hàm ý về bộ nhớ và I / O. Hình 4 cho thấy các lần đọc logic của 2 truy vấn.
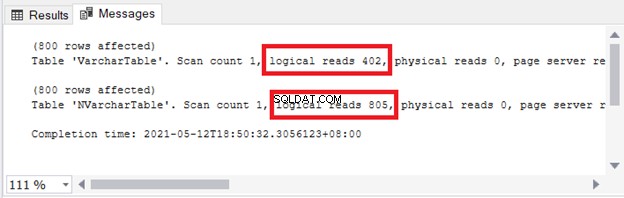
Xem? Số lần đọc logic cũng gấp hai lần khi sử dụng nvarchar so với varchar .
Vì vậy, bạn không thể chỉ sử dụng thay thế cho nhau. Nếu bạn cần lưu trữ đa ngôn ngữ ký tự, sử dụng nvarchar . Nếu không, hãy sử dụng varchar .
Điều này có nghĩa là nếu bạn sử dụng nvarchar chỉ dành cho các ký tự một byte (như tiếng Anh), kích thước bộ nhớ cao hơn . Hiệu suất truy vấn cũng chậm hơn với số lần đọc logic cao hơn.
Trong SQL Server 2019 (và cao hơn), bạn có thể lưu trữ toàn bộ dữ liệu ký tự Unicode bằng cách sử dụng varchar hoặc char với bất kỳ tùy chọn đối chiếu UTF-8 nào.
Sử dụng SQL kiểu dữ liệu số sai
Khái niệm tương tự cũng áp dụng với bigint so với int - kích thước của chúng có thể có nghĩa là đêm và ngày. Giống như nvarchar và varchar , bigint gấp đôi kích thước của int (8 byte cho bigint và 4 byte cho int ).
Tuy nhiên, một vấn đề khác vẫn có thể xảy ra. Nếu bạn không quan tâm đến kích thước của chúng, lỗi có thể xảy ra. Nếu bạn sử dụng một int và lưu trữ một số lớn hơn 2,147,483,647, tràn số học sẽ xảy ra:
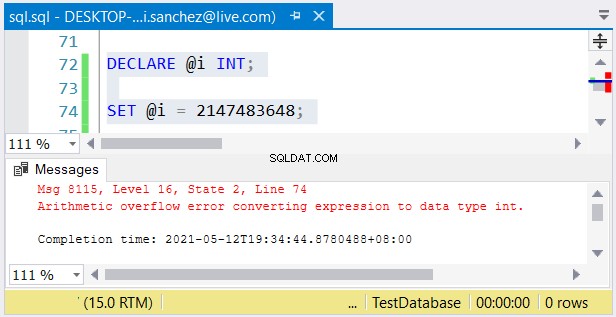
Khi chọn các loại số nguyên, hãy đảm bảo dữ liệu có giá trị lớn nhất sẽ phù hợp . Ví dụ:bạn có thể đang thiết kế một bảng với dữ liệu lịch sử. Bạn định sử dụng số nguyên làm giá trị khóa chính. Bạn có nghĩ rằng nó sẽ không đạt đến 2.147.483.647 hàng? Sau đó, sử dụng int thay vì bigint làm loại cột khóa chính.
Điều tồi tệ nhất có thể xảy ra
Việc chọn sai kiểu dữ liệu có thể ảnh hưởng đến hiệu suất truy vấn hoặc gây ra lỗi thời gian chạy. Do đó, hãy chọn kiểu dữ liệu phù hợp với dữ liệu.
2. Tạo hàng bảng lớn bằng cách sử dụng kiểu dữ liệu lớn cho SQL
Mục tiếp theo của chúng tôi có liên quan đến mục đầu tiên, nhưng nó sẽ mở rộng vấn đề hơn nữa với các ví dụ. Ngoài ra, nó có liên quan đến các trang và varchar có kích thước lớn hoặc nvarchar cột.
Điều gì xảy ra với Kích thước Trang và Hàng?
Khái niệm về các trang trong SQL Server có thể được so sánh với các trang của sổ ghi chép xoắn ốc. Mỗi trang trong sổ tay có cùng kích thước vật lý. Bạn viết từ và vẽ hình ảnh trên đó. Nếu một trang không đủ cho một tập hợp các đoạn văn và hình ảnh, bạn tiếp tục ở trang tiếp theo. Đôi khi, bạn cũng xé một trang và bắt đầu lại.
Tương tự như vậy, dữ liệu bảng, mục nhập chỉ mục và ảnh trong SQL Server được lưu trữ trong các trang.
Một trang có cùng kích thước 8 KB. Nếu một hàng dữ liệu rất lớn, nó sẽ không vừa với trang 8 KB. Một hoặc nhiều cột sẽ được viết trên một trang khác trong đơn vị phân bổ ROW_OVERFLOW_DATA. Nó chứa một con trỏ đến hàng gốc trên trang trong đơn vị phân bổ IN_ROW_DATA.
Dựa trên điều này, bạn không thể chỉ vừa nhiều cột trong một bảng trong quá trình thiết kế cơ sở dữ liệu. Sẽ có những hậu quả trên I / O. Ngoài ra, nếu bạn truy vấn nhiều về dữ liệu tràn hàng này, thời gian thực thi sẽ chậm hơn . Đây có thể là một cơn ác mộng.
Một vấn đề phát sinh khi bạn tăng tối đa tất cả các cột có kích thước khác nhau. Sau đó, dữ liệu sẽ tràn sang trang tiếp theo trong ROW_OVERFLOW_DATA. cập nhật các cột với dữ liệu có kích thước nhỏ hơn và nó cần được xóa trên trang đó. Hàng dữ liệu mới nhỏ hơn sẽ được viết trên trang dưới IN_ROW_DATA cùng với các cột khác. Hãy tưởng tượng I / O có liên quan ở đây.
Ví dụ về hàng lớn
Trước tiên, chúng ta hãy chuẩn bị dữ liệu của chúng tôi. Chúng tôi sẽ sử dụng kiểu dữ liệu chuỗi ký tự có kích thước lớn.
CREATE TABLE [dbo].[LargeTable](
[id] [int] IDENTITY(1,1) NOT NULL,
[SomeString] [varchar](15) NOT NULL,
[LargeString] [nvarchar](3980) NOT NULL,
[AnotherString] [varchar](8000) NULL,
CONSTRAINT [PK_LargeTable] PRIMARY KEY CLUSTERED
(
[id] ASC
))
GO
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',500),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',50))
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',8000))
GO 100
Lấy kích thước hàng
Từ dữ liệu đã tạo, hãy kiểm tra kích thước hàng của chúng dựa trên DATALENGTH.
SELECT *, DATALENGTH(id)
+ DATALENGTH(SomeString)
+ DATALENGTH(LargeString)
+ DATALENGTH(ISNULL(AnotherString,0)) AS RowSize
FROM LargeTable
300 bản ghi đầu tiên sẽ phù hợp với các trang IN_ROW_DATA vì mỗi hàng có ít hơn 8060 byte hoặc 8 KB. Nhưng 100 hàng cuối cùng quá lớn. Kiểm tra bộ kết quả trong Hình 6.
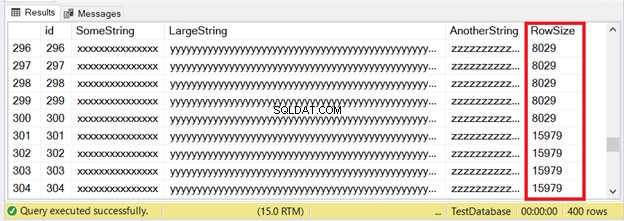
Bạn thấy một phần của 300 hàng đầu tiên. 100 tiếp theo vượt quá giới hạn kích thước trang. Làm cách nào để biết 100 hàng cuối cùng nằm trong đơn vị phân bổ ROW_OVERFLOW_DATA?
Kiểm tra ROW_OVERFLOW_DATA
Chúng tôi sẽ sử dụng sys.dm_db_index_physical_stats . Nó trả về thông tin trang về các mục nhập bảng và chỉ mục.
SELECT
ps.index_id
,[Index] = i.[name]
,ps.index_type_desc
,ps.alloc_unit_type_desc
,ps.index_depth
,ps.index_level
,ps.page_count
,ps.record_count
FROM sys.dm_db_index_physical_stats(DB_ID(),
OBJECT_ID('dbo.LargeTable'), NULL, NULL, 'DETAILED') AS ps
INNER JOIN sys.indexes AS i ON ps.index_id = i.index_id
AND ps.object_id = i.object_id;
Tập hợp kết quả là trong Hình 7.

Nó đây. Hình 7 cho thấy 100 hàng trong ROW_OVERFLOW_DATA. Điều này phù hợp với Hình 6 khi các hàng lớn tồn tại bắt đầu bằng các hàng 301 đến 400.
Câu hỏi tiếp theo là chúng ta nhận được bao nhiêu lần đọc logic khi truy vấn 100 hàng này. Hãy thử.
SELECT * FROM LargeTable
WHERE id BETWEEN 301 AND 400
ORDER BY AnotherString DESC

Chúng tôi thấy 102 lần đọc lôgic và 100 lần đọc lôgic của LargeTable . Hãy để lại những con số này ngay bây giờ - chúng ta sẽ so sánh chúng sau.
Bây giờ, hãy xem điều gì sẽ xảy ra nếu chúng tôi cập nhật 100 hàng với dữ liệu nhỏ hơn.
UPDATE LargeTable
SET AnotherString = 'updated',LargeString='updated'
WHERE id BETWEEN 301 AND 400
Câu lệnh cập nhật này sử dụng cùng một lần đọc logic và đọc logic lob như trong Hình 8. Từ đó, chúng ta biết một điều gì đó lớn hơn đã xảy ra do lượt đọc logic lob của 100 trang.
Nhưng để chắc chắn, hãy kiểm tra bằng sys.dm_db_index_physical_stats như chúng tôi đã làm trước đó. Hình 9 cho thấy kết quả:

Không còn! Các trang và hàng từ ROW_OVERFLOW_DATA trở thành 0 sau khi cập nhật 100 hàng có dữ liệu nhỏ hơn. Bây giờ chúng ta biết rằng việc di chuyển dữ liệu từ ROW_OVERFLOW_DATA sang IN_ROW_DATA xảy ra khi các hàng lớn bị thu hẹp. Hãy tưởng tượng nếu điều này xảy ra nhiều đối với hàng nghìn hoặc thậm chí hàng triệu bản ghi. Thật điên rồ, phải không?
Trong Hình 8, chúng tôi thấy 100 lần đọc logic lob. Bây giờ, hãy xem Hình 10 sau khi chạy lại truy vấn:

Nó đã trở thành con số không!
Điều tồi tệ nhất có thể xảy ra
Hiệu suất truy vấn chậm là sản phẩm phụ của dữ liệu tràn hàng. Cân nhắc chuyển (các) cột có kích thước lớn sang một bảng khác để tránh nó. Hoặc, nếu có, hãy giảm kích thước của varchar hoặc nvarchar cột.
3. Sử dụng chuyển đổi ngầm định một cách mù quáng
SQL không cho phép chúng ta sử dụng dữ liệu mà không chỉ định kiểu. Nhưng sẽ có thể tha thứ nếu chúng ta lựa chọn sai. Nó cố gắng chuyển đổi giá trị thành kiểu mà nó mong đợi, nhưng kèm theo một hình phạt. Điều này có thể xảy ra trong mệnh đề WHERE hoặc JOIN.
USE AdventureWorks2017
GO
SET STATISTICS IO ON
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = 77775294979396 -- this will trigger an implicit conversion
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = '77775294979396'
SET STATISTICS IO OFF
Số thẻ cột không phải là một kiểu số. Đó là nvarchar . Vì vậy, SELECT đầu tiên sẽ gây ra một chuyển đổi ngầm định. Tuy nhiên, cả hai sẽ chạy tốt và tạo ra cùng một tập hợp kết quả.
Hãy kiểm tra kế hoạch thực hiện trong Hình 11.
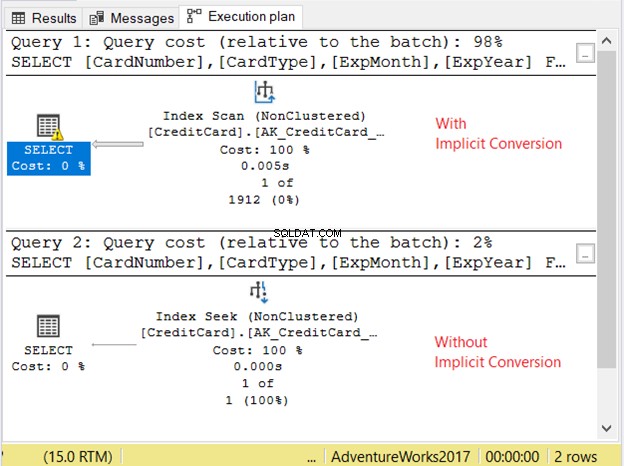
2 truy vấn chạy rất nhanh. Trong Hình 11, đó là 0 giây. Nhưng hãy nhìn vào 2 kế hoạch. Người có chuyển đổi ngầm định đã quét chỉ mục. Ngoài ra còn có một biểu tượng cảnh báo và một mũi tên béo chỉ đến toán tử CHỌN. Nó cho chúng tôi biết rằng điều đó thật tồi tệ.
Nhưng nó không kết thúc ở đó. Nếu bạn di chuột qua toán tử CHỌN, bạn sẽ thấy một cái gì đó khác:

Biểu tượng cảnh báo trong toán tử CHỌN nói về chuyển đổi ngầm định. Nhưng tác động lớn đến mức nào? Hãy kiểm tra các lần đọc hợp lý.
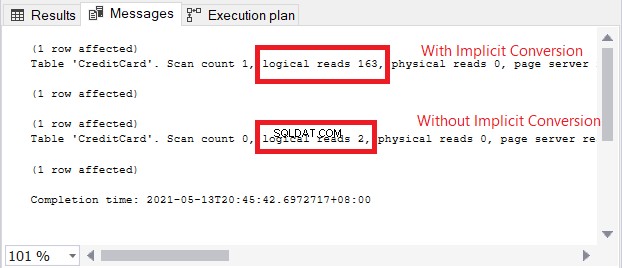
Việc so sánh các giá trị logic trong Hình 13 giống như trời và đất. Trong truy vấn thông tin thẻ tín dụng, chuyển đổi ngầm gây ra hơn một trăm lần số lần đọc logic. Rất tệ!
Điều tồi tệ nhất có thể xảy ra
Nếu một chuyển đổi ngầm gây ra số lần đọc logic cao và một kế hoạch không tốt, hãy mong đợi hiệu suất truy vấn chậm trên các tập kết quả lớn. Để tránh điều này, hãy sử dụng kiểu dữ liệu chính xác trong mệnh đề WHERE và các JOIN để khớp với các cột bạn so sánh.
4. Sử dụng các số gần đúng và làm tròn số
Xem lại hình 2. Kiểu dữ liệu máy chủ SQL thuộc về số gần đúng là float và thực . Các cột và biến được tạo thành từ chúng lưu trữ giá trị gần đúng của một giá trị số. Nếu bạn định làm tròn những con số này lên hoặc xuống, bạn có thể nhận được một bất ngờ lớn. Tôi có một bài báo thảo luận chi tiết về vấn đề này ở đây. Xem cách 1 + 1 dẫn đến 3 và cách bạn có thể đối phó với các số làm tròn.
Điều tồi tệ nhất có thể xảy ra
Làm tròn một phao hoặc thực có thể có kết quả điên rồ. Nếu bạn muốn các giá trị chính xác sau khi làm tròn số, hãy sử dụng thập phân hoặc số thay vào đó.
5. Đặt kiểu dữ liệu chuỗi có kích thước cố định thành NULL
Hãy chuyển sự chú ý của chúng ta đến các loại dữ liệu có kích thước cố định như char và nchar . Ngoài các khoảng trống được đệm, việc đặt chúng thành NULL sẽ vẫn có kích thước bộ nhớ bằng kích thước của char cột. Vì vậy, đặt một char (500) cột thành NULL sẽ có kích thước là 500, không phải bằng 0 hoặc 1.
CREATE TABLE dbo.CharNullSample
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
col1 CHAR(500) NULL,
col2 CHAR(200) NULL,
col3 CHAR(350) NULL,
col4 VARCHAR(500) NULL,
col5 VARCHAR(200) NULL,
col6 VARCHAR(350) NULL
)
GO
INSERT INTO CharNullSample (col1, col2, col3, col4, col5, col6)
VALUES (REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350), REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350));
GO 200
Trong mã trên, dữ liệu được lấy ra tối đa dựa trên kích thước của char và varchar cột. Kiểm tra kích thước hàng của họ bằng DATALENGTH cũng sẽ hiển thị tổng kích thước của mỗi cột. Bây giờ, hãy đặt các cột thành NULL.
UPDATE CharNullSample
SET col1 = NULL, col2=NULL, col3=NULL, col4=NULL, col5=NULL, col6=NULL
Tiếp theo, chúng tôi truy vấn các hàng bằng DATALENGTH:
SELECT
DATALENGTH(ISNULL(col1,0)) AS Col1Size
,DATALENGTH(ISNULL(col2,0)) AS Col2Size
,DATALENGTH(ISNULL(col3,0)) AS Col3Size
,DATALENGTH(ISNULL(col4,0)) AS Col4Size
,DATALENGTH(ISNULL(col5,0)) AS Col5Size
,DATALENGTH(ISNULL(col6,0)) AS Col6Size
FROM CharNullSample
Bạn nghĩ kích thước dữ liệu của mỗi cột sẽ như thế nào? Xem Hình 14.
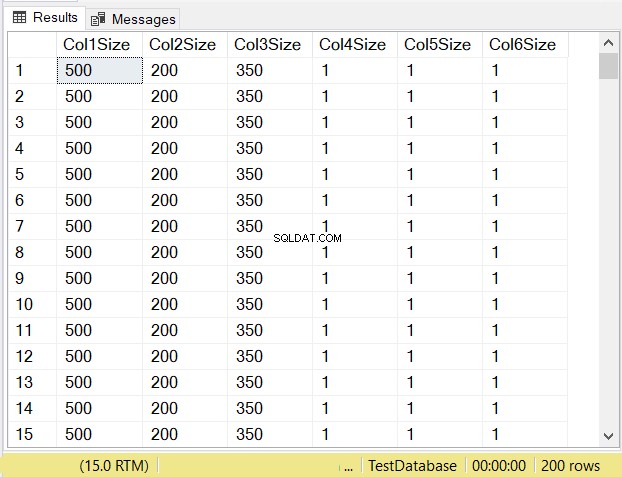
Nhìn vào kích thước cột của 3 cột đầu tiên. Sau đó, so sánh chúng với mã ở trên khi bảng được tạo. Kích thước dữ liệu của các cột NULL bằng kích thước của cột. Trong khi đó, varchar cột khi NULL có kích thước dữ liệu là 1.
Điều tồi tệ nhất có thể xảy ra
Trong khi thiết kế bảng, char nullable các cột, khi được đặt thành NULL, sẽ vẫn có cùng kích thước lưu trữ. Chúng cũng sẽ sử dụng các trang và RAM giống nhau. Nếu bạn không điền vào toàn bộ cột bằng các ký tự, hãy xem xét sử dụng varchar thay vào đó.
Tiếp theo là gì?
Vì vậy, lựa chọn của bạn về kiểu dữ liệu máy chủ SQL và kích thước của chúng có quan trọng không? Các điểm được trình bày ở đây là đủ để tạo ra một quan điểm. Vì vậy, bạn có thể làm gì bây giờ?
- Dành thời gian để xem lại cơ sở dữ liệu bạn hỗ trợ. Bắt đầu với cái dễ nhất nếu bạn có nhiều món trên đĩa. Và vâng, hãy dành thời gian, không phải tìm ra thời gian. Trong dòng công việc của chúng tôi, hầu như không thể tìm được thời gian.
- Xem lại các bảng, thủ tục được lưu trữ và bất kỳ thứ gì liên quan đến kiểu dữ liệu. Lưu ý tác động tích cực khi xác định vấn đề. Bạn sẽ cần nó khi sếp hỏi tại sao bạn phải làm việc này.
- Lên kế hoạch tấn công từng khu vực có vấn đề. Thực hiện theo bất kỳ phương pháp hoặc chính sách nào mà công ty của bạn có để giải quyết các vấn đề.
- Khi vấn đề đã qua đi, hãy ăn mừng.
Nghe có vẻ dễ dàng, nhưng tất cả chúng ta đều biết không phải vậy. Chúng tôi cũng biết rằng có một mặt tươi sáng ở cuối cuộc hành trình. Đó là lý do tại sao chúng được gọi là sự cố - bởi vì có một giải pháp. Vì vậy, hãy vui lên.
Bạn có điều gì khác để thêm về chủ đề này? Cho chúng tôi biết trong phần ý kiến. Và nếu bài đăng này cung cấp cho bạn một ý tưởng hay, hãy chia sẻ nó trên các nền tảng mạng xã hội yêu thích của bạn.