Trở lại năm 2012, tôi đã viết một bài đăng trên blog nêu bật các cách tiếp cận để tính giá trị trung bình. Trong bài đăng đó, tôi đã giải quyết một trường hợp rất đơn giản:chúng tôi muốn tìm giá trị trung bình của một cột trên toàn bộ bảng. Kể từ đó, tôi đã đề cập nhiều lần rằng một yêu cầu thực tế hơn là tính toán một trung vị phân vùng . Giống như trường hợp cơ bản, có nhiều cách để giải quyết vấn đề này trong các phiên bản SQL Server khác nhau; không ngạc nhiên khi một số hoạt động tốt hơn nhiều so với những người khác.
Trong ví dụ trước, chúng ta chỉ có các cột chung chung id và val. Hãy làm cho điều này thực tế hơn và nói rằng chúng ta có những người bán hàng và số lượng bán hàng mà họ đã thực hiện trong một khoảng thời gian nào đó. Để kiểm tra các truy vấn của chúng tôi, trước tiên chúng ta hãy tạo một đống đơn giản với 17 hàng và xác minh rằng tất cả chúng đều tạo ra kết quả mà chúng tôi mong đợi (Người bán hàng 1 có giá trị trung bình là 7,5 và Người bán hàng 2 có giá trị trung bình là 6,0):
CREATE TABLE dbo.Sales(SalesPerson INT, Amount INT); GO INSERT dbo.Sales WITH (TABLOCKX) (SalesPerson, Amount) VALUES (1, 6 ),(1, 11),(1, 4 ),(1, 4 ), (1, 15),(1, 14),(1, 4 ),(1, 9 ), (2, 6 ),(2, 11),(2, 4 ),(2, 4 ), (2, 15),(2, 14),(2, 4 );
Đây là các truy vấn mà chúng tôi sẽ kiểm tra (với nhiều dữ liệu hơn!) So với đống ở trên, cũng như với các chỉ mục hỗ trợ. Tôi đã loại bỏ một số truy vấn từ thử nghiệm trước, truy vấn này không chia tỷ lệ hoặc không liên kết rất tốt với các phương tiện được phân vùng (cụ thể là 2000_B, sử dụng bảng #temp và 2005_A, sử dụng hàng đối lập số). Tuy nhiên, tôi đã thêm một vài ý tưởng thú vị từ một bài viết gần đây của Dwain Camps (@DwainCSQL), được xây dựng dựa trên bài viết trước của tôi.
SQL Server 2000+
Phương pháp duy nhất từ phương pháp trước đó hoạt động đủ tốt trên SQL Server 2000 để đưa nó vào thử nghiệm này là phương pháp "tối thiểu của một nửa, tối đa của phương pháp kia":
SELECT DISTINCT s.SalesPerson, Median = (
(SELECT MAX(Amount) FROM
(SELECT TOP 50 PERCENT Amount FROM dbo.Sales
WHERE SalesPerson = s.SalesPerson ORDER BY Amount) AS t)
+ (SELECT MIN(Amount) FROM
(SELECT TOP 50 PERCENT Amount FROM dbo.Sales
WHERE SalesPerson = s.SalesPerson ORDER BY Amount DESC) AS b)
) / 2.0
FROM dbo.Sales AS s; Thành thật mà nói, tôi đã cố gắng bắt chước phiên bản bảng #temp mà tôi đã sử dụng trong ví dụ đơn giản hơn, nhưng nó không chia tỷ lệ tốt chút nào. Ở 20 hoặc 200 hàng, nó hoạt động tốt; ở năm 2000, nó mất gần một phút; ở mức 1.000.000 tôi đã bỏ cuộc sau một giờ. Tôi đã đưa nó vào đây cho hậu thế (bấm vào để tiết lộ).
CREATE TABLE #x
(
i INT IDENTITY(1,1),
SalesPerson INT,
Amount INT,
i2 INT
);
CREATE CLUSTERED INDEX v ON #x(SalesPerson, Amount);
INSERT #x(SalesPerson, Amount)
SELECT SalesPerson, Amount
FROM dbo.Sales
ORDER BY SalesPerson,Amount OPTION (MAXDOP 1);
UPDATE x SET i2 = i-
(
SELECT COUNT(*) FROM #x WHERE i <= x.i
AND SalesPerson < x.SalesPerson
)
FROM #x AS x;
SELECT SalesPerson, Median = AVG(0. + Amount)
FROM #x AS x
WHERE EXISTS
(
SELECT 1
FROM #x
WHERE SalesPerson = x.SalesPerson
AND x.i2 - (SELECT MAX(i2) / 2.0 FROM #x WHERE SalesPerson = x.SalesPerson)
IN (0, 0.5, 1)
)
GROUP BY SalesPerson;
GO
DROP TABLE #x; SQL Server 2005+ 1
Điều này sử dụng hai chức năng cửa sổ khác nhau để lấy ra một chuỗi và tổng số tiền trên mỗi người bán hàng.
SELECT SalesPerson, Median = AVG(1.0*Amount)
FROM
(
SELECT SalesPerson, Amount, rn = ROW_NUMBER() OVER
(PARTITION BY SalesPerson ORDER BY Amount),
c = COUNT(*) OVER (PARTITION BY SalesPerson)
FROM dbo.Sales
)
AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2)
GROUP BY SalesPerson; SQL Server 2005+ 2
Điều này đến từ bài báo của Dwain Camps, tương tự như trên, theo một cách phức tạp hơn một chút. Về cơ bản, điều này sẽ bỏ phân vùng (các) hàng thú vị trong mỗi nhóm.
;WITH Counts AS
(
SELECT SalesPerson, c
FROM
(
SELECT SalesPerson, c1 = (c+1)/2,
c2 = CASE c%2 WHEN 0 THEN 1+c/2 ELSE 0 END
FROM
(
SELECT SalesPerson, c=COUNT(*)
FROM dbo.Sales
GROUP BY SalesPerson
) a
) a
CROSS APPLY (VALUES(c1),(c2)) b(c)
)
SELECT a.SalesPerson, Median=AVG(0.+b.Amount)
FROM
(
SELECT SalesPerson, Amount, rn = ROW_NUMBER() OVER
(PARTITION BY SalesPerson ORDER BY Amount)
FROM dbo.Sales a
) a
CROSS APPLY
(
SELECT Amount FROM Counts b
WHERE a.SalesPerson = b.SalesPerson AND a.rn = b.c
) b
GROUP BY a.SalesPerson; SQL Server 2005+ 3
Điều này dựa trên gợi ý từ Adam Machanic trong các nhận xét trên bài đăng trước của tôi và cũng được Dwain nâng cao trong bài viết của anh ấy ở trên.
;WITH Counts AS
(
SELECT SalesPerson, c = COUNT(*)
FROM dbo.Sales
GROUP BY SalesPerson
)
SELECT a.SalesPerson, Median = AVG(0.+Amount)
FROM Counts a
CROSS APPLY
(
SELECT TOP (((a.c - 1) / 2) + (1 + (1 - a.c % 2)))
b.Amount, r = ROW_NUMBER() OVER (ORDER BY b.Amount)
FROM dbo.Sales b
WHERE a.SalesPerson = b.SalesPerson
ORDER BY b.Amount
) p
WHERE r BETWEEN ((a.c - 1) / 2) + 1 AND (((a.c - 1) / 2) + (1 + (1 - a.c % 2)))
GROUP BY a.SalesPerson; SQL Server 2005+ 4
Điều này tương tự như "2005+ 1" ở trên, nhưng thay vì sử dụng COUNT(*) OVER() để lấy số lượng, nó thực hiện tự nối với một tổng hợp cô lập trong một bảng dẫn xuất.
SELECT SalesPerson, Median = AVG(1.0 * Amount)
FROM
(
SELECT s.SalesPerson, s.Amount, rn = ROW_NUMBER() OVER
(PARTITION BY s.SalesPerson ORDER BY s.Amount), c.c
FROM dbo.Sales AS s
INNER JOIN
(
SELECT SalesPerson, c = COUNT(*)
FROM dbo.Sales GROUP BY SalesPerson
) AS c
ON s.SalesPerson = c.SalesPerson
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2)
GROUP BY SalesPerson; SQL Server 2012+ 1
Đây là một đóng góp rất thú vị từ đồng nghiệp của SQL Server MVP Peter "Peso" Larsson (@SwePeso) trong các nhận xét về bài viết của Dwain; nó sử dụng CROSS APPLY và OFFSET / FETCH mới chức năng theo một cách thậm chí còn thú vị và đáng ngạc nhiên hơn giải pháp của Itzik để tính toán trung vị đơn giản hơn.
SELECT d.SalesPerson, w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w(Median); SQL Server 2012+ 2
Cuối cùng, chúng ta có PERCENTILE_CONT() mới chức năng được giới thiệu trong SQL Server 2012.
SELECT SalesPerson, Median = MAX(Median)
FROM
(
SELECT SalesPerson,Median = PERCENTILE_CONT(0.5) WITHIN GROUP
(ORDER BY Amount) OVER (PARTITION BY SalesPerson)
FROM dbo.Sales
)
AS x
GROUP BY SalesPerson; Thử nghiệm thực tế
Để kiểm tra hiệu suất của các truy vấn trên, chúng tôi sẽ xây dựng một bảng quan trọng hơn nhiều. Chúng tôi sẽ có 100 nhân viên bán hàng duy nhất, với 10.000 nhân viên bán hàng mỗi nhân viên, với tổng số 1.000.000 hàng. Chúng tôi cũng sẽ chạy từng truy vấn đối với đống như nó vốn có, với một chỉ mục không phân cụm được thêm vào (SalesPerson, Amount) và với một chỉ mục được nhóm trên các cột giống nhau. Đây là thiết lập:
CREATE TABLE dbo.Sales(SalesPerson INT, Amount INT); GO --CREATE CLUSTERED INDEX x ON dbo.Sales(SalesPerson, Amount); --CREATE NONCLUSTERED INDEX x ON dbo.Sales(SalesPerson, Amount); --DROP INDEX x ON dbo.sales; ;WITH x AS ( SELECT TOP (100) number FROM master.dbo.spt_values GROUP BY number ) INSERT dbo.Sales WITH (TABLOCKX) (SalesPerson, Amount) SELECT x.number, ABS(CHECKSUM(NEWID())) % 99 FROM x CROSS JOIN x AS x2 CROSS JOIN x AS x3;
Và đây là kết quả của các truy vấn trên, so với heap, chỉ mục không phân cụm và chỉ mục được phân cụm:
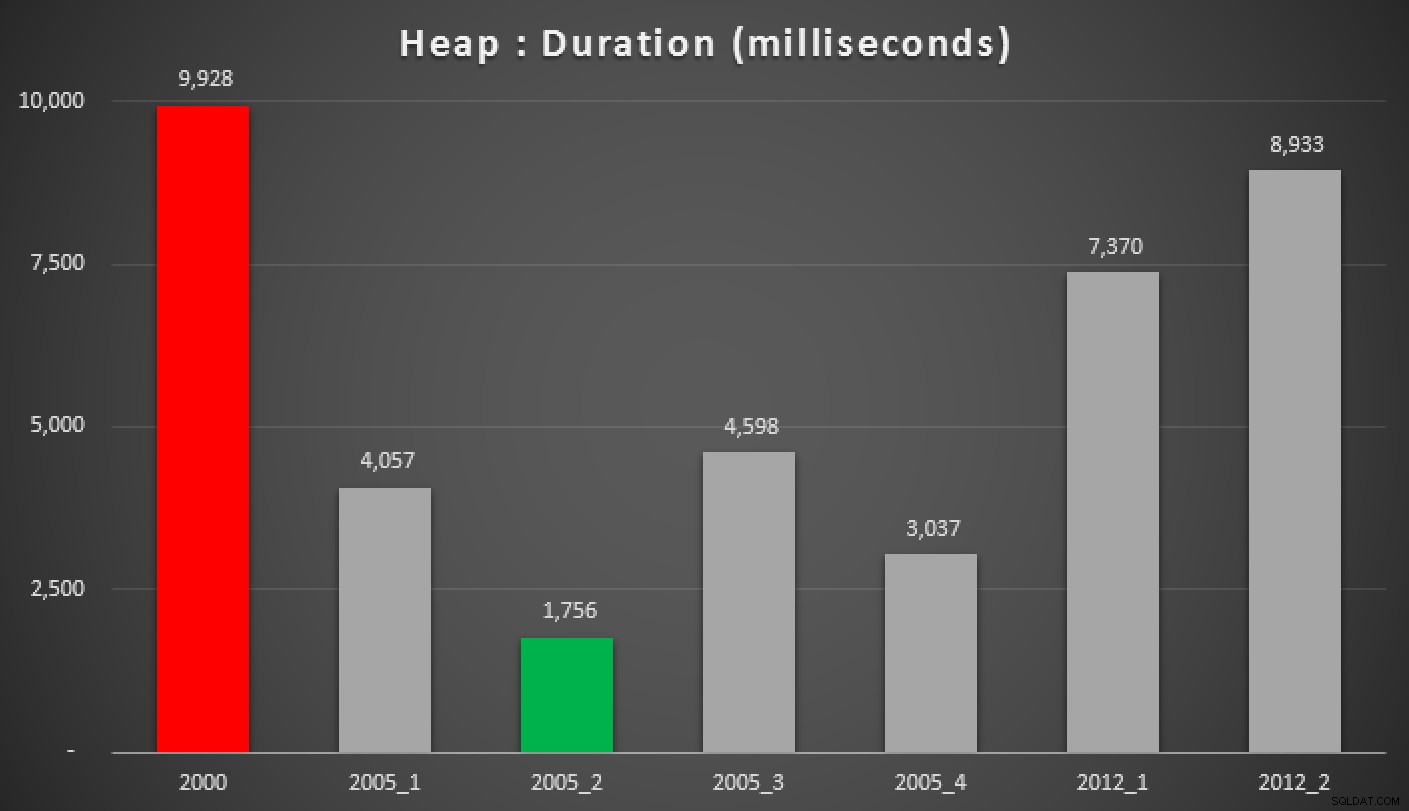
Thời lượng, tính bằng mili giây, của các phương pháp tiếp cận trung bình được nhóm khác nhau (so với đống)
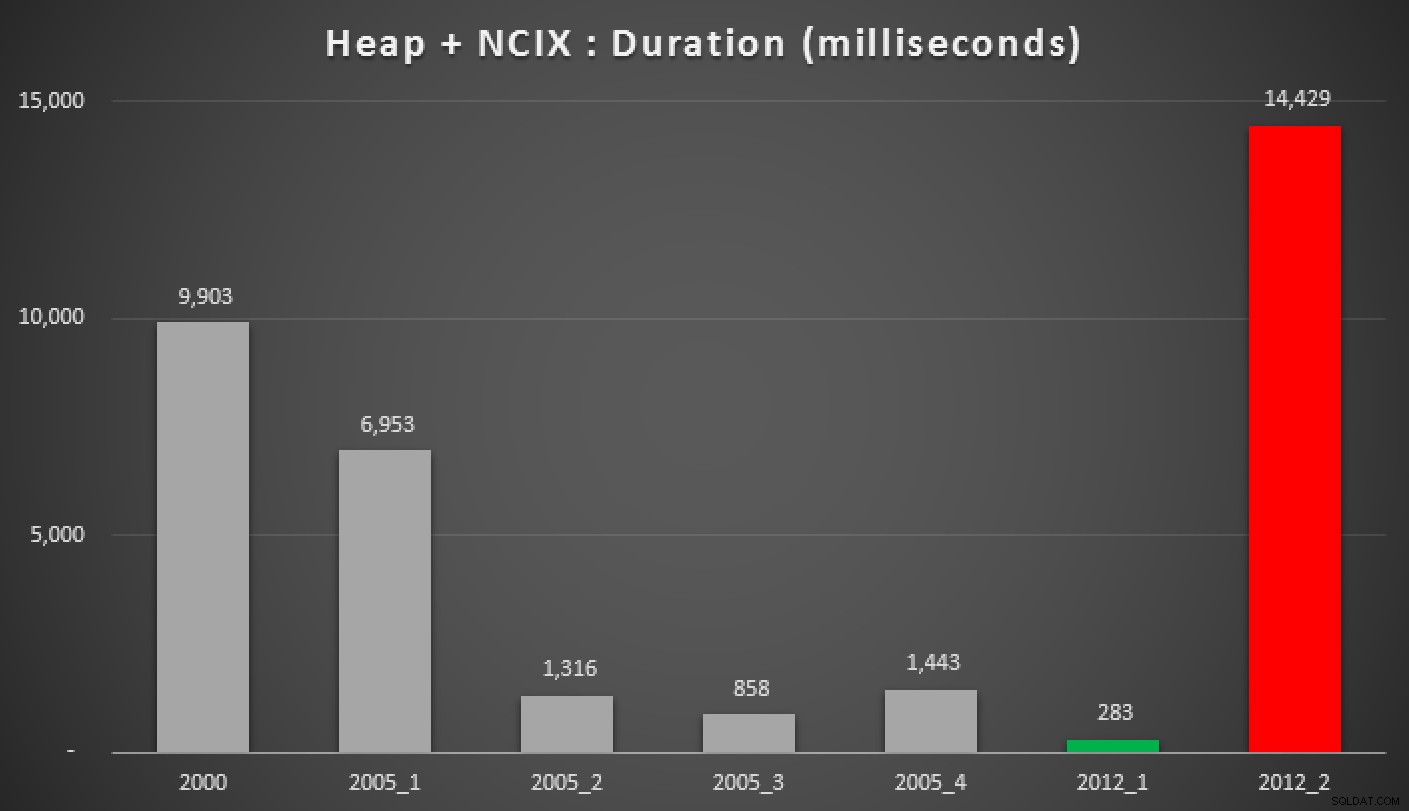
Thời lượng, tính bằng mili giây, của các phương pháp tiếp cận trung bình được nhóm khác nhau (so với đống với chỉ mục không được phân cụm)
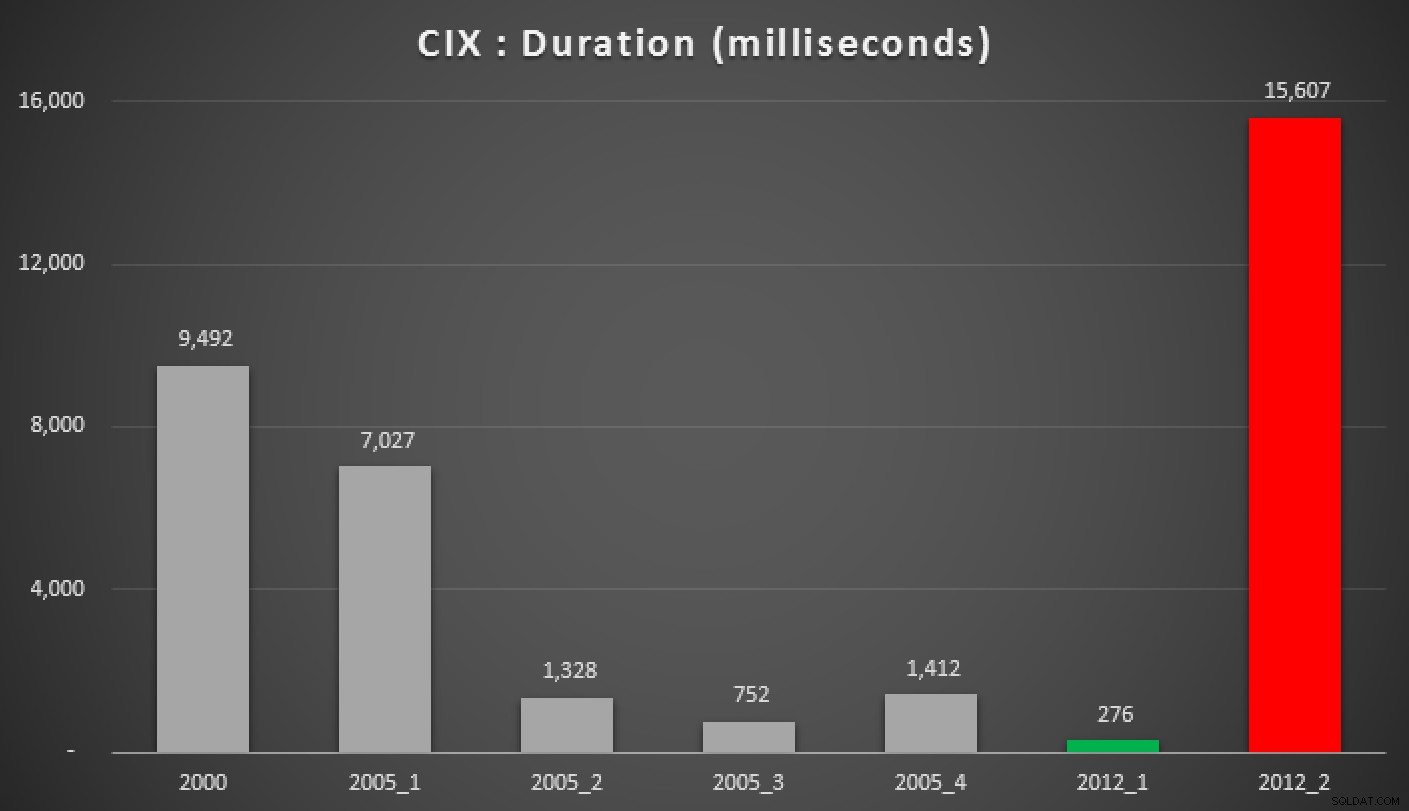
Thời lượng, tính bằng mili giây, của các phương pháp tiếp cận trung bình được nhóm khác nhau (so với chỉ mục nhóm)
Còn Hekaton thì sao?
Đương nhiên, tôi tò mò liệu tính năng mới này trong SQL Server 2014 có thể giúp giải quyết bất kỳ truy vấn nào trong số này hay không. Vì vậy, tôi đã tạo cơ sở dữ liệu Trong Bộ nhớ, hai phiên bản Trong Bộ nhớ của bảng Bán hàng (một phiên bản có chỉ mục băm trên (SalesPerson, Amount) và cái kia chỉ trên (SalesPerson) ), và chạy lại các bài kiểm tra tương tự:
CREATE DATABASE Hekaton; GO ALTER DATABASE Hekaton ADD FILEGROUP xtp CONTAINS MEMORY_OPTIMIZED_DATA; GO ALTER DATABASE Hekaton ADD FILE (name = 'xtp', filename = 'c:\temp\hek.mod') TO FILEGROUP xtp; GO ALTER DATABASE Hekaton SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT ON; GO USE Hekaton; GO CREATE TABLE dbo.Sales1 ( ID INT IDENTITY(1,1) PRIMARY KEY NONCLUSTERED, SalesPerson INT NOT NULL, Amount INT NOT NULL, INDEX x NONCLUSTERED HASH (SalesPerson, Amount) WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); GO CREATE TABLE dbo.Sales2 ( ID INT IDENTITY(1,1) PRIMARY KEY NONCLUSTERED, SalesPerson INT NOT NULL, Amount INT NOT NULL, INDEX x NONCLUSTERED HASH (SalesPerson) WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); GO ;WITH x AS ( SELECT TOP (100) number FROM master.dbo.spt_values GROUP BY number ) INSERT dbo.Sales1 (SalesPerson, Amount) -- TABLOCK/TABLOCKX not allowed here SELECT x.number, ABS(CHECKSUM(NEWID())) % 99 FROM x CROSS JOIN x AS x2 CROSS JOIN x AS x3; INSERT dbo.Sales2 (SalesPerson, Amount) SELECT SalesPerson, Amount FROM dbo.Sales1;
Kết quả:
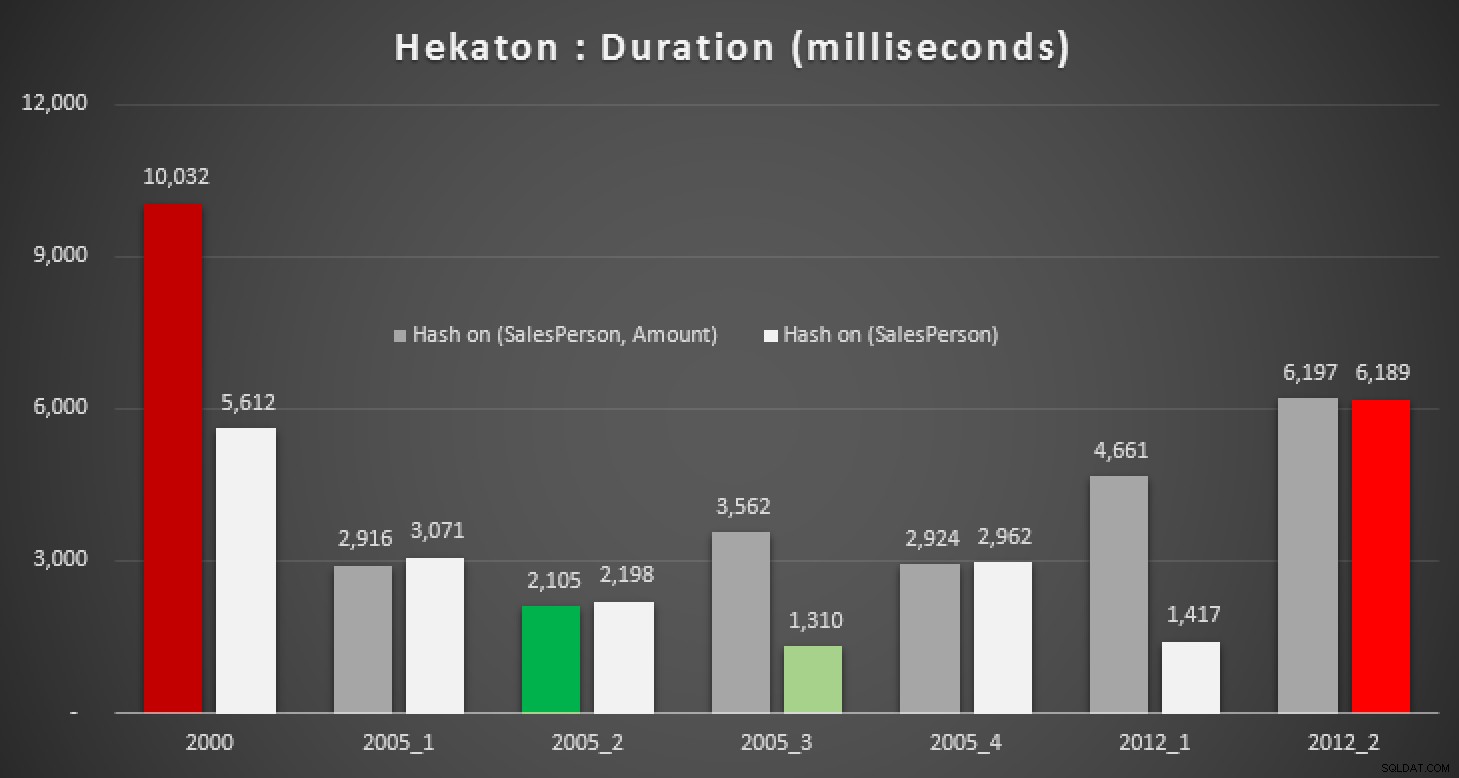
Thời lượng, tính bằng mili giây, cho các phép tính trung bình khác nhau đối với Trong bộ nhớ bảng
Ngay cả với chỉ mục băm phù hợp, chúng tôi không thực sự thấy những cải tiến đáng kể so với bảng truyền thống. Hơn nữa, cố gắng giải quyết vấn đề trung bình bằng cách sử dụng một thủ tục được lưu trữ được biên dịch nguyên bản sẽ không phải là một nhiệm vụ dễ dàng, vì nhiều cấu trúc ngôn ngữ được sử dụng ở trên không hợp lệ (tôi cũng ngạc nhiên về một vài cấu trúc trong số này). Việc cố gắng biên dịch tất cả các biến thể truy vấn ở trên đã dẫn đến loạt lỗi này; một số xảy ra nhiều lần trong mỗi quy trình và ngay cả sau khi loại bỏ các bản sao, điều này vẫn khá hài hước:
Msg 10794, Level 16, State 47, Procedure GroupedMedian_2000Tùy chọn 'DISTINCT' không được hỗ trợ với các thủ tục được lưu trữ được biên dịch nguyên bản.
Msg 12311, Level 16, State 37, Thủ tục GroupedMedian_2000
Truy vấn con ( các truy vấn lồng trong một truy vấn khác) không được hỗ trợ với các thủ tục được lưu trữ được biên dịch nguyên bản.
Msg 10794, Cấp 16, Trạng thái 48, Thủ tục GroupedMedian_2000
Tùy chọn 'PERCENT' không được hỗ trợ với các thủ tục được lưu trữ được biên dịch tự nhiên.
Msg 12311, Cấp 16, Trạng thái 37, Thủ tục GroupedMedian_2005_1
Truy vấn con (các truy vấn được lồng bên trong một truy vấn khác) không được hỗ trợ với các thủ tục được lưu trữ được biên dịch nguyên bản.
Msg 10794, Cấp 16, Trạng thái 91 , Thủ tục GroupedMedian_2005_1
Hàm tổng hợp 'ROW_NUMBER' không được hỗ trợ với các thủ tục được lưu trữ được biên dịch nguyên bản.
Msg 10794, Cấp 16, Trạng thái 56, Thủ tục GroupedMedian_2005_1
Toán tử 'IN' không được hỗ trợ với các thủ tục được lưu trữ được biên dịch tự nhiên.
Msg 12310, Cấp 16, Trạng thái 36, Thủ tục GroupedMedian_2005_2
Biểu thức bảng chung (CTE) không được hỗ trợ với các thủ tục được lưu trữ được biên dịch nguyên bản.
Msg 12309, Cấp 16, Trạng thái 35, Thủ tục GroupedMedian_2005_2
Các câu lệnh của biểu mẫu CHÈN… GIÁ TRỊ… chèn nhiều hàng không được hỗ trợ với các thủ tục được lưu trữ được biên dịch nguyên bản.
Msg 10794, Cấp 16, Trạng thái 53, Thủ tục GroupedMedian_2005_2
Toán tử 'APPLICY' không được hỗ trợ với các thủ tục được lưu trữ được biên dịch tự nhiên.
Msg 12311, Cấp 16, Trạng thái 37, Thủ tục GroupedMedian_2005_2
Truy vấn con (các truy vấn được lồng bên trong một truy vấn khác) không được hỗ trợ với các thủ tục được lưu trữ được biên dịch nguyên bản.
Thủ tục 10794, Cấp 16, Trạng thái 91, Thủ tục GroupedMedian_2005_2
Hàm tổng hợp 'ROW_NUMBER' không được hỗ trợ với các thủ tục được lưu trữ được biên dịch nguyên bản.
Msg 12310, Level 16, State 36, Thủ tục GroupedMedian_2005_3
Common Table Expressions (CTE) là không được hỗ trợ với lưu trữ được biên dịch tự nhiên các thủ tục.
Msg 12311, Cấp 16, Trạng thái 37, Thủ tục GroupedMedian_2005_3
Truy vấn con (truy vấn lồng trong một truy vấn khác) không được hỗ trợ với các thủ tục được lưu trữ được biên dịch nguyên bản.
Thủ tục 10794, Cấp 16, Trạng thái 91 , Thủ tục GroupedMedian_2005_3
Hàm tổng hợp 'ROW_NUMBER' không được hỗ trợ với các thủ tục được lưu trữ được biên dịch nguyên bản.
Msg 10794, Mức 16, Trạng thái 53, Thủ tục GroupedMedian_2005_3
Toán tử 'APPLICY' không được hỗ trợ với Các thủ tục được lưu trữ được biên dịch tự nhiên.
Msg 12311, Cấp 16, Trạng thái 37, Thủ tục GroupedMedian_2005_4
Các truy vấn con (các truy vấn được lồng bên trong một truy vấn khác) không được hỗ trợ với các thủ tục được lưu trữ được biên dịch tự nhiên.
Msg 10794, Cấp 16, Trạng thái 91, Thủ tục GroupedMedian_2005_4. 'IN' không được hỗ trợ với stor được biên dịch nguyên bản thủ tục ed.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2012_1
Các truy vấn con (truy vấn lồng trong một truy vấn khác) không được hỗ trợ với các thủ tục được lưu trữ được biên dịch nguyên bản.
Msg 10794, Cấp 16, Trạng thái 38, Thủ tục GroupedMedian_2012_1
Toán tử 'OFFSET' không được hỗ trợ với các thủ tục được lưu trữ được biên dịch nguyên bản.
Msg 10794, Cấp 16, Trạng thái 53, Thủ tục GroupedMedian_2012_1
Toán tử 'ÁP DỤNG' không được hỗ trợ với các thủ tục được lưu trữ được biên dịch tự nhiên.
Msg 12311, Mức 16, Trạng thái 37, Thủ tục GroupedMedian_2012_2
Các truy vấn con (các truy vấn lồng trong một truy vấn khác) không được hỗ trợ với các thủ tục được lưu trữ được biên dịch tự nhiên.
Msg 10794, Mức 16, Trạng thái 90, Thủ tục GroupedMedian_2012_2
Hàm tổng hợp 'PERCENTILE_CONT' không được hỗ trợ với các thủ tục được lưu trữ được biên dịch nguyên bản.
Như được viết hiện tại, không một trong các truy vấn này có thể được chuyển sang một thủ tục được lưu trữ được biên dịch nguyên bản. Có lẽ điều gì đó cần xem xét cho một bài đăng tiếp theo khác.
Kết luận
Loại bỏ kết quả Hekaton và khi có chỉ mục hỗ trợ, truy vấn của Peter Larsson ("2012+ 1") sử dụng OFFSET / FETCH xuất hiện với tư cách là người chiến thắng rất xa trong các bài kiểm tra này. Mặc dù phức tạp hơn một chút so với truy vấn tương đương trong các thử nghiệm không phân vùng, nhưng điều này phù hợp với kết quả mà tôi đã quan sát lần trước.
Trong những trường hợp tương tự, 2000 MIN/MAX phương pháp tiếp cận và PERCENTILE_CONT() của năm 2012 xuất hiện như những con chó thực sự; một lần nữa, giống như các thử nghiệm trước đây của tôi đối với trường hợp đơn giản hơn.
Nếu bạn chưa sử dụng SQL Server 2012, thì tùy chọn tốt nhất tiếp theo của bạn là "2005+ 3" (nếu bạn có chỉ mục hỗ trợ) hoặc "2005+ 2" nếu bạn đang xử lý một đống. Xin lỗi, tôi phải nghĩ ra một sơ đồ đặt tên mới cho những thứ này, chủ yếu là để tránh nhầm lẫn với các phương pháp trong bài đăng trước của tôi.
Tất nhiên, đây là kết quả của tôi dựa trên một lược đồ và tập dữ liệu rất cụ thể - như với tất cả các đề xuất, bạn nên kiểm tra các phương pháp tiếp cận này dựa trên giản đồ và dữ liệu của mình, vì các yếu tố khác có thể ảnh hưởng đến các kết quả khác nhau.
Một lưu ý khác
Ngoài việc có hiệu suất kém và không được hỗ trợ trong các thủ tục được lưu trữ được biên dịch nguyên bản, một điểm khó khăn khác của PERCENTILE_CONT() là nó không thể được sử dụng trong các chế độ tương thích cũ hơn. Nếu bạn cố gắng, bạn sẽ gặp lỗi này:
Chức năng PERCENTILE_CONT không được phép trong chế độ tương thích hiện tại. Nó chỉ được phép ở chế độ 110 hoặc cao hơn.