Trong bài đăng trước của tôi về thống kê gia tăng, một tính năng mới trong SQL Server 2014, tôi đã trình bày cách chúng có thể giúp giảm thời gian tác vụ bảo trì. Điều này là do số liệu thống kê có thể được cập nhật ở cấp phân vùng và các thay đổi được hợp nhất thành biểu đồ chính cho bảng. Tôi cũng lưu ý rằng Trình tối ưu hóa Truy vấn không sử dụng các thống kê cấp phân vùng đó khi tạo các kế hoạch truy vấn, đây có thể là điều mà mọi người đang mong đợi. Không có tài liệu nào để nói rằng thống kê gia tăng sẽ hoặc sẽ không được Trình tối ưu hoá Truy vấn sử dụng. Vậy làm sao bạn biết? Bạn phải kiểm tra nó. :-)
Thiết lập
Thiết lập cho thử nghiệm này sẽ tương tự như thiết lập trong bài viết trước, nhưng với ít dữ liệu hơn. Lưu ý rằng kích thước mặc định nhỏ hơn cho các tệp dữ liệu và tập lệnh chỉ tải trong một vài triệu hàng dữ liệu:
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', --everything in 2011 '20120101', --everything in 2012 '20130101', --everything in 2013 '20140101', --everything in 2014 '20150101' --everything in 2015 ); GO CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
Khi chúng tôi tạo chỉ mục nhóm cho dbo.Orders, chúng tôi sẽ tạo nó mà không có STATISTICS_INCREMENTAL đã bật tùy chọn, vì vậy chúng tôi sẽ bắt đầu với một bảng được phân vùng truyền thống không có thống kê gia tăng:
ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ([OrderDate], [PurchaseOrderID]) ON [OrderDateRangePScheme] ([OrderDate]);
Tiếp theo, chúng tôi sẽ tải trong khoảng 4 triệu hàng, chỉ mất chưa đầy một phút trên máy của tôi:
SET NOCOUNT ON; DECLARE @Loops SMALLINT = 0; DECLARE @Increment INT = 3000; WHILE @Loops < 1000 BEGIN INSERT [dbo].[Orders] ([PurchaseOrderID] ,[EmployeeID] ,[VendorID] ,[TaxAmt] ,[Freight] ,[SubTotal] ,[Status] ,[RevisionNumber] ,[ModifiedDate] ,[ShipMethodID] ,[ShipDate] ,[OrderDate] ,[TotalDue] ) SELECT [PurchaseOrderID] + @Increment , [EmployeeID] , [VendorID] , [TaxAmt] , [Freight] , [SubTotal] , [Status] , [RevisionNumber] , [ModifiedDate] , [ShipMethodID] , DATEADD(DAY, 365, [ShipDate]) , DATEADD(DAY, 365, [OrderDate]) , [TotalDue] + 365 FROM [Purchasing].[PurchaseOrderHeader]; CHECKPOINT; SET @Loops = @Loops + 1; SET @Increment = @Increment + 5000; END
Sau khi tải dữ liệu, chúng tôi sẽ cập nhật thống kê bằng FULLSCAN (để chúng tôi có thể tạo biểu đồ nhất quán nhất có thể cho các thử nghiệm) và sau đó xác minh dữ liệu nào chúng tôi có trong mỗi phân vùng:
UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN; SELECT $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number] , MIN([o].[OrderDate]) AS [Min_Order_Date] , MAX([o].[OrderDate]) AS [Max_Order_Date] , COUNT(*) AS [Rows_In_Partition] FROM [dbo].[Orders] AS [o] GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) ORDER BY [Partition Number];
 Dữ liệu trong mỗi phân vùng sau khi tải dữ liệu
Dữ liệu trong mỗi phân vùng sau khi tải dữ liệu
Hầu hết dữ liệu nằm trong phân vùng 2015, nhưng cũng có dữ liệu cho 2012, 2013 và 2014. Và nếu chúng tôi kiểm tra kết quả từ DMV sys.dm_db_stats_properties_internal không có giấy tờ , chúng tôi có thể thấy rằng không tồn tại thống kê cấp độ phân vùng:
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 sys.dm_db_stats_properties_internal đầu ra chỉ hiển thị một thống kê cho dbo.Orders
sys.dm_db_stats_properties_internal đầu ra chỉ hiển thị một thống kê cho dbo.Orders
Bài kiểm tra
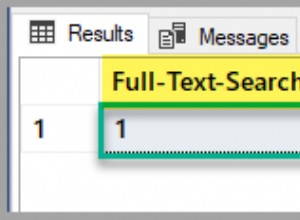
Kiểm tra yêu cầu một truy vấn đơn giản mà chúng tôi có thể sử dụng để xác minh rằng loại bỏ phân vùng xảy ra và cũng kiểm tra ước tính dựa trên thống kê. Truy vấn không trả lại bất kỳ dữ liệu nào, nhưng điều đó không quan trọng, chúng tôi quan tâm đến những gì mà trình tối ưu hóa nghĩ nó sẽ trở lại, dựa trên số liệu thống kê:
SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
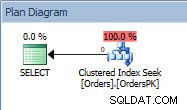 Kế hoạch truy vấn cho câu lệnh SELECT
Kế hoạch truy vấn cho câu lệnh SELECT
Kế hoạch có Tìm kiếm chỉ mục theo cụm và nếu chúng tôi kiểm tra các thuộc tính, chúng tôi thấy rằng nó ước tính khoảng 4000 hàng và đã truy cập phân vùng 5, chứa dữ liệu năm 2014.
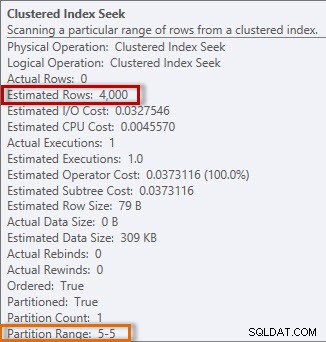 Thông tin ước tính và thực tế từ Tìm kiếm chỉ mục theo cụm
Thông tin ước tính và thực tế từ Tìm kiếm chỉ mục theo cụm
Nếu chúng ta nhìn vào biểu đồ cho bảng dbo.Orders, cụ thể là trong vùng dữ liệu của tháng 4 năm 2014, chúng ta thấy rằng không có bước nào cho 2014-04-01, vì vậy trình tối ưu hóa ước tính số hàng cho ngày đó bằng cách sử dụng bước cho 2014-04-24, trong đó AVG_RANGE_ROWS là 4000 (đối với bất kỳ giá trị nào trong khoảng thời gian từ 2014-02-14 đến 2014-04-23, trình tối ưu hóa sẽ ước tính rằng 4000 hàng sẽ được trả lại).
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');
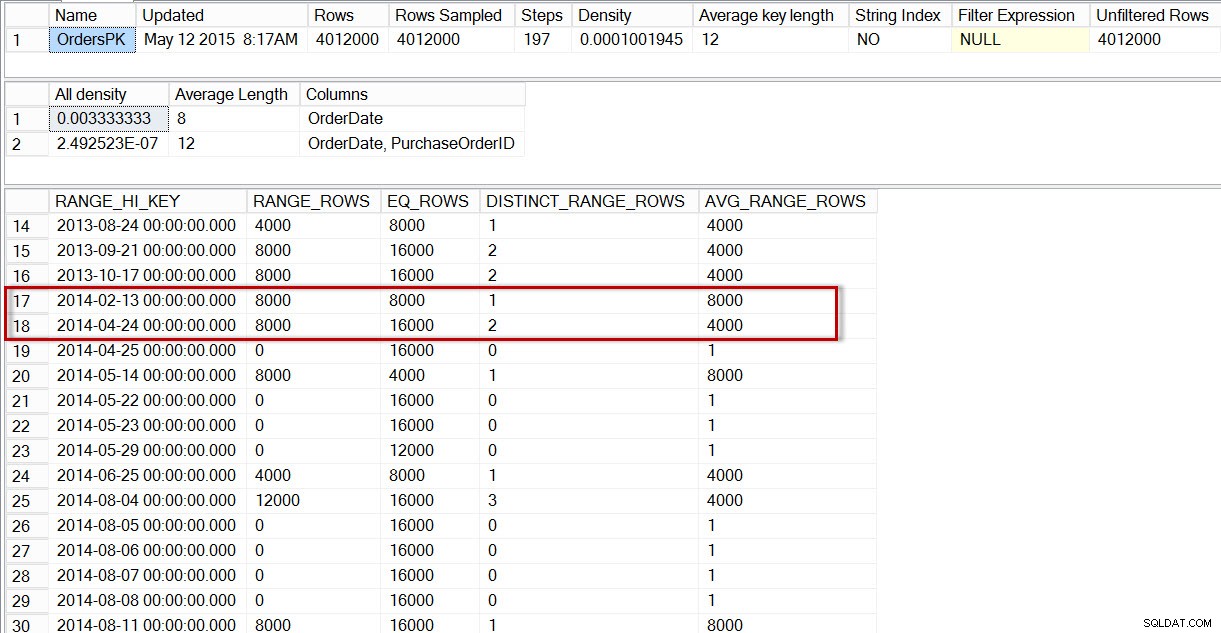 Phân phối trong biểu đồ dbo.Orders
Phân phối trong biểu đồ dbo.Orders
Dự toán và kế hoạch hoàn toàn nằm ngoài dự kiến. Hãy bật số liệu thống kê gia tăng và xem những gì chúng ta nhận được.
ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON); GO UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN;
Nếu chúng tôi chạy lại truy vấn của mình đối với sys.dm_db_stats_properties_internal , chúng ta có thể thấy các thống kê gia tăng:
 sys.dm_db_stats_properties_internal hiển thị thông tin thống kê gia tăng
sys.dm_db_stats_properties_internal hiển thị thông tin thống kê gia tăng
Bây giờ, hãy chạy lại truy vấn của chúng ta lần nữa dbo.Orders và chúng ta sẽ chạy DBCC FREEPROCCACHE đầu tiên để đảm bảo hoàn toàn gói không được sử dụng lại:
DBCC FREEPROCCACHE; GO SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
Chúng tôi nhận được cùng một kế hoạch và cùng một ước tính:
Kế hoạch truy vấn cho câu lệnh SELECT
Thông tin ước tính và thực tế từ Tìm kiếm chỉ mục theo cụm
Nếu chúng tôi kiểm tra biểu đồ chính cho dbo.Orders, chúng tôi thấy biểu đồ gần giống như trước đây:
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');
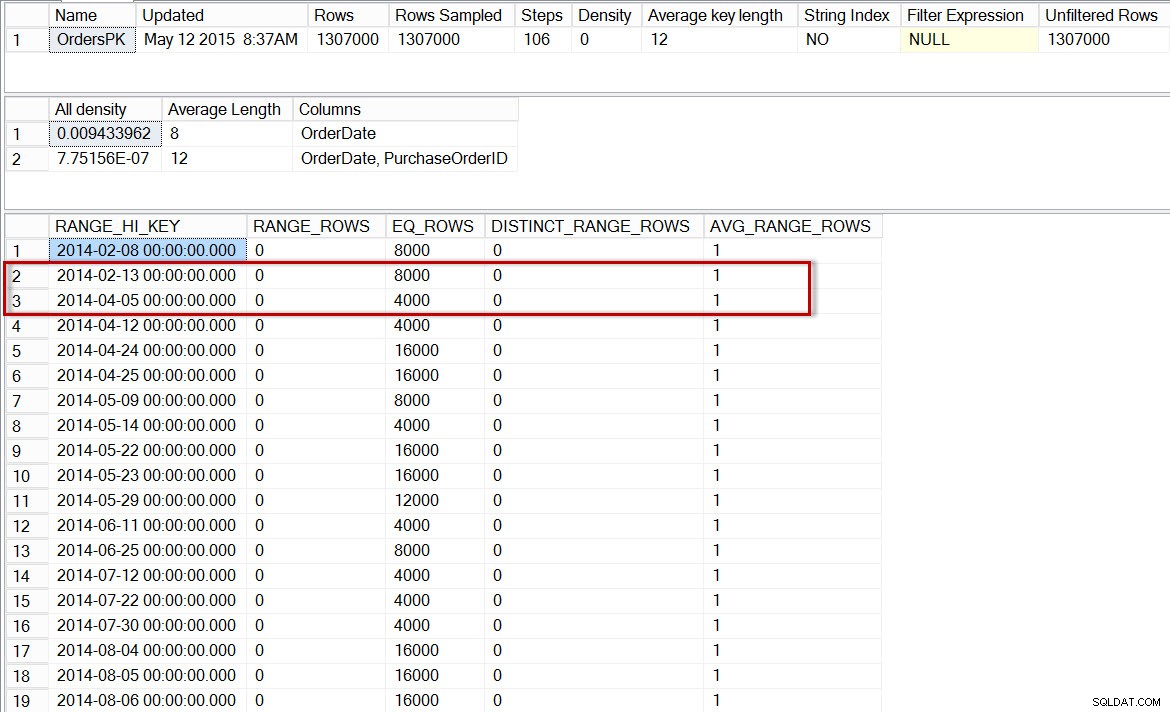 Biểu đồ cho dbo.Orders, sau khi bật thống kê gia tăng
Biểu đồ cho dbo.Orders, sau khi bật thống kê gia tăng
Bây giờ, hãy kiểm tra biểu đồ cho phân vùng có dữ liệu năm 2014 (chúng ta có thể thực hiện việc này bằng cách sử dụng cờ theo dõi không có tài liệu 2309, cho phép chỉ định số phân vùng làm đối số bổ sung cho DBCC SHOW_STATISTICS ):
DBCC TRACEON(2309);
GO
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK', 6);
Biểu đồ cho phân vùng năm 2014 của dbo.Orders, sau khi bật thống kê gia tăng
Ở đây chúng ta thấy rằng, một lần nữa, không có bước nào cho 2014-04-01, nhưng có 0 RANGE_ROWS giữa 2014-02-13 và 2014-04-05, với AVG_RANGE_ROWS của 1. Nếu trình tối ưu hóa đang sử dụng biểu đồ cho thống kê cấp độ phân vùng, thì ước tính số hàng cho 2014-04-01 sẽ là 1.
Lưu ý:Phân vùng được xác định là được sử dụng trong kế hoạch truy vấn là 5, nhưng bạn sẽ nhận thấy rằng DBCC SHOW_STATISTICS phân vùng tham chiếu câu lệnh 6. Giả định là sự không nhất quán trong siêu dữ liệu thống kê (một lỗi phổ biến riêng lẻ, có thể do đếm dựa trên 0 so với đếm dựa trên 1), có thể được khắc phục hoặc không được sửa trong tương lai. Hãy hiểu rằng cờ theo dõi không được lập thành văn bản tại thời điểm này và nó không được khuyến khích sử dụng trong môi trường sản xuất.
Tóm tắt
Việc bổ sung số liệu thống kê gia tăng trong bản phát hành SQL Server 2014 là một bước đi đúng hướng để cải thiện ước tính số lượng bản chất cho các bảng được phân vùng. Tuy nhiên, như chúng tôi đã chứng minh, giá trị hiện tại của thống kê gia tăng bị giới hạn ở việc giảm thời lượng bảo trì, vì những thống kê gia tăng đó chưa được Trình tối ưu hóa truy vấn sử dụng.