SQL Server 2014 mang đến nhiều tính năng mới mà các DBA và nhà phát triển mong muốn được thử nghiệm và sử dụng trong môi trường của họ, chẳng hạn như chỉ mục Columnstore theo cụm có thể cập nhật, Độ bền bị trễ và Phần mở rộng vùng đệm. Một tính năng không thường được thảo luận là thống kê gia tăng. Trừ khi bạn sử dụng tính năng phân vùng, đây không phải là tính năng bạn có thể triển khai. Nhưng nếu bạn có các bảng được phân vùng trong cơ sở dữ liệu của mình, thì số liệu thống kê gia tăng có thể là thứ mà bạn háo hức mong đợi.
Lưu ý:Benjamin Nevarez đã đề cập đến một số điều cơ bản liên quan đến thống kê gia tăng trong bài đăng vào tháng 2 năm 2014 của anh ấy, Thống kê tăng dần trong SQL Server 2014. Và mặc dù không có nhiều thay đổi về cách tính năng này hoạt động kể từ bài đăng của anh ấy và bản phát hành tháng 4 năm 2014, nhưng có vẻ như đây là thời điểm tốt để tìm hiểu cách kích hoạt số liệu thống kê gia tăng có thể giúp hiệu suất bảo trì như thế nào.
Thống kê tăng dần đôi khi được gọi là thống kê cấp độ phân vùng và điều này là do lần đầu tiên, SQL Server có thể tự động tạo thống kê dành riêng cho một phân vùng. Một trong những thách thức trước đây với phân vùng là, mặc dù bạn có thể có 1 đến n phân vùng cho một bảng, chỉ có một (1) thống kê đại diện cho phân phối dữ liệu trên tất cả các phân vùng đó. Bạn có thể tạo thống kê đã lọc cho bảng được phân vùng - một thống kê cho mỗi phân vùng - để cung cấp cho trình tối ưu hóa truy vấn thông tin tốt hơn về việc phân phối dữ liệu. Nhưng đây là một quy trình thủ công và yêu cầu một tập lệnh để tự động tạo chúng cho mỗi phân vùng mới.
Trong SQL Server 2014, bạn sử dụng STATISTICS_INCREMENTAL tùy chọn để SQL Server tự động tạo các thống kê cấp phân vùng đó. Tuy nhiên, những thống kê này không được sử dụng như bạn nghĩ.
Tôi đã đề cập trước đây rằng, trước năm 2014, bạn có thể tạo thống kê đã lọc để cung cấp cho trình tối ưu hóa thông tin tốt hơn về các phân vùng. Các số liệu thống kê gia tăng đó? Chúng hiện không được trình tối ưu hóa sử dụng. Trình tối ưu hóa truy vấn vẫn chỉ sử dụng biểu đồ chính đại diện cho toàn bộ bảng. (Đăng sẽ chứng minh điều này!)
Vậy mục đích của thống kê gia tăng là gì? Nếu bạn giả định rằng chỉ dữ liệu trong phân vùng gần đây nhất là thay đổi, thì lý tưởng nhất là bạn chỉ cập nhật số liệu thống kê cho phân vùng đó. Bạn có thể thực hiện việc này ngay bây giờ với số liệu thống kê gia tăng - và điều xảy ra là thông tin sau đó được hợp nhất trở lại biểu đồ chính. Biểu đồ cho toàn bộ bảng sẽ cập nhật mà không cần phải đọc toàn bộ bảng để cập nhật thống kê và điều này có thể giúp thực hiện các nhiệm vụ bảo trì của bạn.
Thiết lập
Chúng ta sẽ bắt đầu với việc tạo một hàm và lược đồ phân vùng, sau đó là một bảng mới mà chúng ta sẽ phân vùng. Lưu ý rằng tôi đã tạo một nhóm tệp cho từng chức năng phân vùng như bạn có thể làm trong môi trường sản xuất. Bạn có thể tạo lược đồ phân vùng trên cùng một nhóm tệp (ví dụ:PRIMARY ) nếu bạn không thể dễ dàng bỏ cơ sở dữ liệu thử nghiệm của mình. Mỗi nhóm tệp cũng có kích thước vài GB, vì chúng tôi sẽ thêm gần 400 triệu hàng.
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 1024MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; /* create partition function */ CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', -- everything in 2011 '20120101', -- everything in 2012 '20130101', -- everything in 2013 '20140101', -- everything in 2014 '20150101' -- everything in 2015 ); GO /* create partition scheme */ CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO /* create the table */ CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
Trước khi thêm dữ liệu, chúng tôi sẽ tạo chỉ mục theo nhóm và lưu ý rằng cú pháp bao gồm WITH (STATISTICS_INCREMENTAL = ON) tùy chọn:
/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) WITH (STATISTICS_INCREMENTAL = ON) ON [OrderDateRangePScheme] ([OrderDate]);
Điều thú vị cần lưu ý ở đây là nếu bạn nhìn vào ALTER TABLE mục nhập trong MSDN, nó không bao gồm tùy chọn này. Bạn sẽ chỉ tìm thấy nó trong ALTER INDEX mục nhập… nhưng điều này hoạt động. Nếu bạn muốn theo dõi tài liệu về bức thư, bạn sẽ chạy:
/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) ON [OrderDateRangePScheme] ([OrderDate]); GO ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON);
Khi chỉ mục nhóm đã được tạo cho lược đồ phân vùng, chúng tôi sẽ tải dữ liệu của mình và sau đó kiểm tra xem có bao nhiêu hàng tồn tại trên mỗi phân vùng (lưu ý rằng quá trình này mất hơn 7 phút trên máy tính xách tay của tôi, bạn có thể muốn thêm ít hàng hơn tùy thuộc vào lượng bộ nhớ (và thời gian) bạn có sẵn):
/* load some data */
SET NOCOUNT ON;
DECLARE @Loops SMALLINT = 0;
DECLARE @Increment INT = 5000;
WHILE @Loops < 10000 -- adjust this to increase or decrease the number
-- of rows in the table, 10000 = 40 millon rows
BEGIN
INSERT [dbo].[Orders]
( [PurchaseOrderID]
,[EmployeeID]
,[VendorID]
,[TaxAmt]
,[Freight]
,[SubTotal]
,[Status]
,[RevisionNumber]
,[ModifiedDate]
,[ShipMethodID]
,[ShipDate]
,[OrderDate]
,[TotalDue]
)
SELECT
[PurchaseOrderID] + @Increment
, [EmployeeID]
, [VendorID]
, [TaxAmt]
, [Freight]
, [SubTotal]
, [Status]
, [RevisionNumber]
, [ModifiedDate]
, [ShipMethodID]
, [ShipDate]
, [OrderDate]
, [TotalDue]
FROM [Purchasing].[PurchaseOrderHeader];
CHECKPOINT;
SET @Loops = @Loops + 1;
SET @Increment = @Increment + 5000;
END
/* Check to see how much data exists per partition */
SELECT
$PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number]
, MIN([o].[OrderDate]) AS [Min_Order_Date]
, MAX([o].[OrderDate]) AS [Max_Order_Date]
, COUNT(*) AS [Rows In Partition]
FROM [dbo].[Orders] AS [o]
GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate])
ORDER BY [Partition Number];
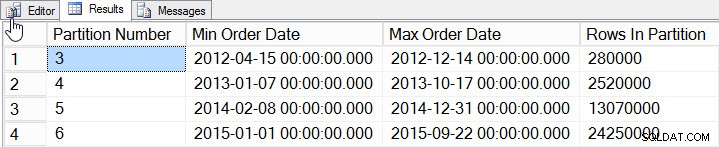 Dữ liệu trên mỗi phân vùng
Dữ liệu trên mỗi phân vùng
Chúng tôi đã thêm dữ liệu cho các năm 2012 đến 2015, với nhiều dữ liệu hơn đáng kể vào năm 2014 và 2015. Hãy xem thống kê của chúng tôi trông như thế nào:
DBCC SHOW_STATISTICS ('dbo.Orders',[OrdersPK]);
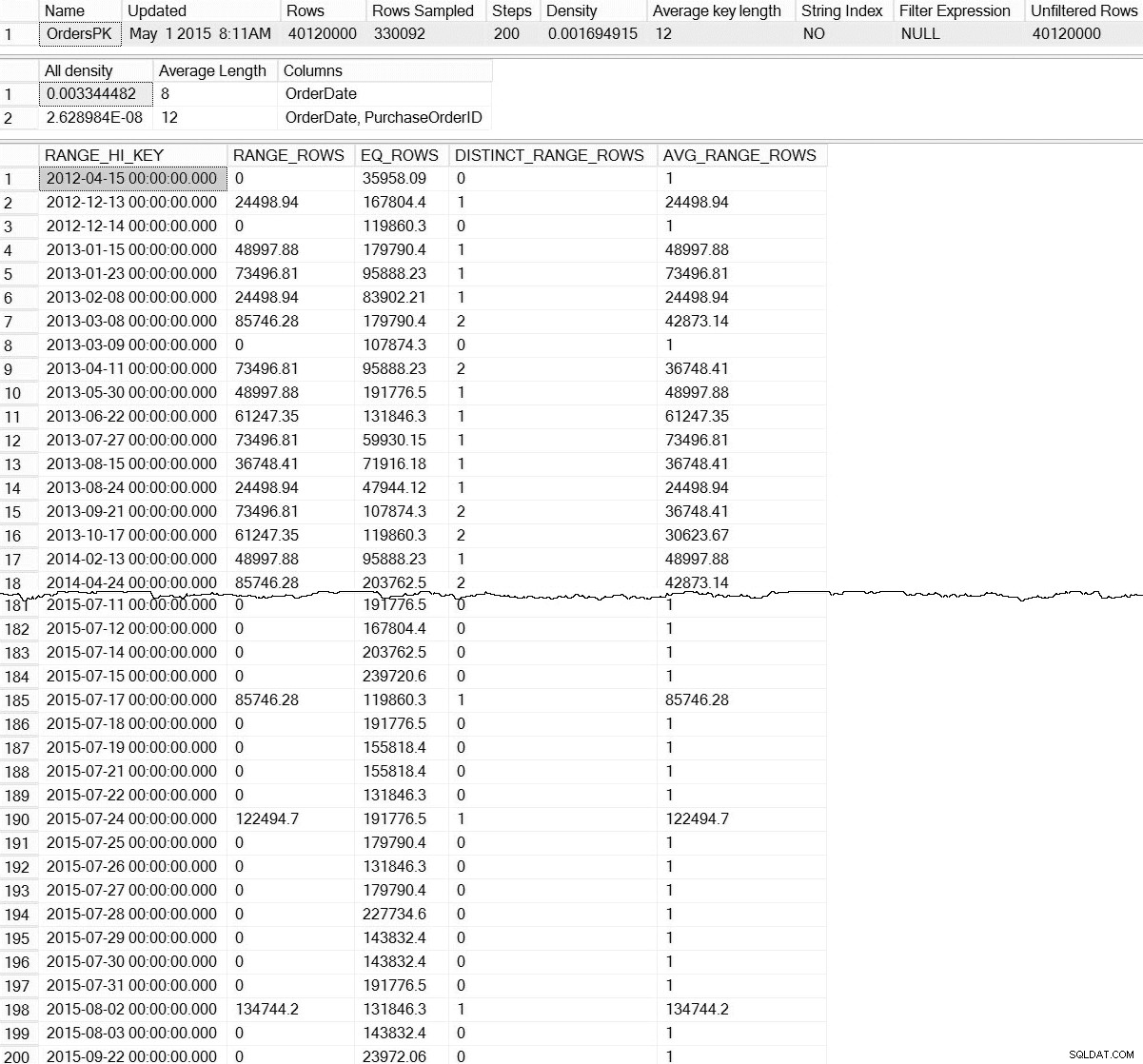 DBCC SHOW_STATISTICS đầu ra cho dbo.Orders (nhấp để phóng to)
DBCC SHOW_STATISTICS đầu ra cho dbo.Orders (nhấp để phóng to)
Với DBCC SHOW_STATISTICS mặc định lệnh, chúng tôi không có bất kỳ thông tin nào về thống kê ở cấp phân vùng. Đừng sợ hãi; chúng ta không hoàn toàn bị diệt vong - có một chức năng quản lý động không có giấy tờ, sys.dm_db_stats_properties_internal . Hãy nhớ rằng không có giấy tờ có nghĩa là nó không được hỗ trợ (không có mục nhập MSDN cho DMF) và nó có thể thay đổi bất kỳ lúc nào mà không có bất kỳ cảnh báo nào từ Microsoft. Điều đó nói rằng, đó là một khởi đầu tốt để có được ý tưởng về những gì tồn tại cho số liệu thống kê gia tăng của chúng tôi:
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 Thông tin biểu đồ từ dm_db_stats_properties_internal (nhấp để phóng to)
Thông tin biểu đồ từ dm_db_stats_properties_internal (nhấp để phóng to)
Điều này thú vị hơn rất nhiều. Ở đây, chúng ta có thể thấy bằng chứng rằng số liệu thống kê cấp phân vùng (và hơn thế nữa) tồn tại. Bởi vì DMF này không được lập thành văn bản, chúng tôi phải thực hiện một số diễn giải. Hôm nay, chúng ta sẽ tập trung vào bảy hàng đầu tiên trong kết quả, trong đó hàng đầu tiên đại diện cho biểu đồ cho toàn bộ bảng (lưu ý các hàng rows giá trị 40 triệu) và các hàng tiếp theo đại diện cho biểu đồ cho mỗi phân vùng. Thật không may, partition_number giá trị trong biểu đồ này không trùng với số phân vùng từ sys.dm_db_index_physical_stats cho phân vùng dựa trên bên phải (nó tương quan đúng với phân vùng bên trái). Cũng lưu ý rằng đầu ra này cũng bao gồm last_updated và modification_counter , hữu ích khi khắc phục sự cố và nó có thể được sử dụng để phát triển các tập lệnh bảo trì cập nhật thông minh số liệu thống kê dựa trên các sửa đổi về độ tuổi hoặc hàng.
Giảm thiểu yêu cầu bảo trì
Giá trị chính của thống kê gia tăng tại thời điểm này là khả năng cập nhật thống kê cho một phân vùng và để các thống kê đó hợp nhất vào biểu đồ cấp bảng mà không cần phải cập nhật thống kê cho toàn bộ bảng (và do đó, đọc qua toàn bộ bảng). Để xem điều này đang hoạt động, trước tiên chúng ta hãy thống kê cập nhật cho phân vùng chứa dữ liệu năm 2015, phân vùng 5 và chúng tôi sẽ ghi lại thời gian thực hiện và chụp nhanh sys.dm_io_virtual_file_stats DMF trước và sau để xem mức độ I / O xảy ra:
SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH RESAMPLE ON PARTITIONS(6); GO SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture AS f INNER JOIN #SecondCapture AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
Đầu ra:
Thời gian thực thi của máy chủ SQL:thời gian CPU =203 ms, thời gian đã trôi qua =240 ms.
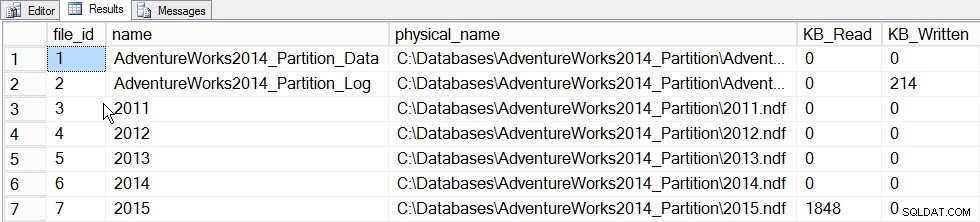 Dữ liệu thống kê tệp sau khi cập nhật một phân vùng
Dữ liệu thống kê tệp sau khi cập nhật một phân vùng
Nếu chúng ta nhìn vào sys.dm_db_stats_properties_internal đầu ra, chúng tôi thấy rằng last_updated đã thay đổi cho cả biểu đồ năm 2015 và biểu đồ cấp bảng (cũng như một số nút khác, dành cho việc điều tra sau này):
 Thông tin biểu đồ được cập nhật từ dm_db_stats_properties_internal
Thông tin biểu đồ được cập nhật từ dm_db_stats_properties_internal
Bây giờ chúng tôi sẽ cập nhật thống kê bằng FULLSCAN cho bảng và chúng tôi sẽ chụp nhanh file_stats trước và sau một lần nữa:
SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH FULLSCAN SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture2 AS f INNER JOIN #SecondCapture2 AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
Đầu ra:
Thời gian thực thi của máy chủ SQL:thời gian CPU =12720 mili giây, thời gian đã trôi qua =13646 mili giây
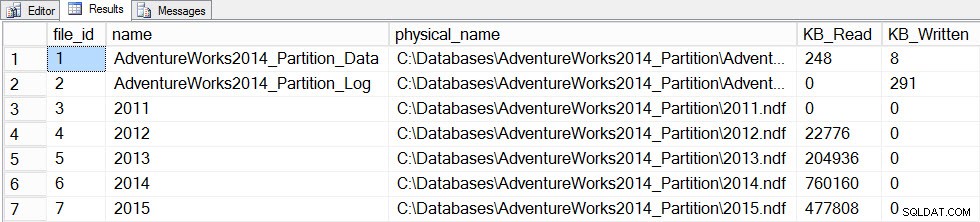 Lọc dữ liệu sau khi cập nhật bằng fullscan
Lọc dữ liệu sau khi cập nhật bằng fullscan
Quá trình cập nhật mất nhiều thời gian hơn đáng kể (13 giây so với vài trăm mili giây) và tạo ra nhiều I / O hơn. Nếu chúng tôi kiểm tra sys.dm_db_stats_properties_internal một lần nữa, chúng tôi thấy rằng last_updated đã thay đổi cho tất cả các biểu đồ:
 Thông tin biểu đồ từ dm_db_stats_properties_internal sau khi quét toàn bộ
Thông tin biểu đồ từ dm_db_stats_properties_internal sau khi quét toàn bộ
Tóm tắt
Mặc dù thống kê gia tăng chưa được trình tối ưu hóa truy vấn sử dụng để cung cấp thông tin về từng phân vùng, nhưng chúng mang lại lợi ích về hiệu suất khi quản lý thống kê cho các bảng được phân vùng. Nếu số liệu thống kê chỉ cần được cập nhật cho các phân vùng đã chọn thì chỉ những phân vùng đó có thể được cập nhật. Sau đó, thông tin mới được hợp nhất vào biểu đồ cấp bảng, cung cấp cho trình tối ưu hóa nhiều thông tin hiện tại hơn mà không phải trả chi phí đọc toàn bộ bảng. Trong tương lai, chúng tôi hy vọng rằng các số liệu thống kê cấp phân vùng đó sẽ được sử dụng bởi trình tối ưu hóa. Hãy theo dõi…