Cơ sở dữ liệu phục vụ các ứng dụng kinh doanh thường phải hỗ trợ dữ liệu tạm thời. Ví dụ:giả sử hợp đồng với nhà cung cấp chỉ có hiệu lực trong thời gian giới hạn. Nó có thể có hiệu lực từ một thời điểm cụ thể trở đi hoặc nó có thể có hiệu lực trong một khoảng thời gian cụ thể — từ thời điểm bắt đầu đến thời điểm kết thúc. Ngoài ra, nhiều khi bạn cần phải kiểm tra tất cả các thay đổi trong một hoặc nhiều bảng. Bạn cũng có thể cần hiển thị trạng thái tại một thời điểm cụ thể hoặc tất cả các thay đổi được thực hiện đối với bảng trong một khoảng thời gian cụ thể. Từ quan điểm toàn vẹn dữ liệu, bạn có thể cần triển khai nhiều ràng buộc cụ thể theo thời gian bổ sung.
Giới thiệu Dữ liệu Thời gian
Trong bảng có hỗ trợ tạm thời, tiêu đề đại diện cho một vị từ có ít nhất một tham số một lần đại diện cho khoảng thời gian khi phần còn lại của vị từ là hợp lệ — do đó, vị từ hoàn chỉnh là một vị từ có dấu thời gian. Các hàng đại diện cho các mệnh đề được đánh dấu thời gian và khoảng thời gian hợp lệ của hàng thường được biểu thị bằng hai thuộc tính: from và đến hoặc bắt đầu và end .
Các loại bảng tạm thời
Bạn có thể nhận thấy trong phần giới thiệu rằng có hai loại vấn đề thời gian. Đầu tiên là thời gian hiệu lực của mệnh đề - trong khoảng thời gian mà mệnh đề mà một hàng được đánh dấu thời gian trong bảng biểu thị thực sự là đúng. Ví dụ, hợp đồng với nhà cung cấp chỉ có hiệu lực từ thời điểm 1 đến thời điểm 2. Loại thời hạn hiệu lực này có ý nghĩa đối với con người, có ý nghĩa đối với doanh nghiệp. Thời gian hiệu lực còn được gọi là thời gian áp dụng hoặc thời gian của con người . Chúng tôi có thể có nhiều khoảng thời gian hợp lệ cho cùng một thực thể. Ví dụ, hợp đồng nói trên có hiệu lực từ thời điểm 1 đến thời điểm 2 cũng có thể có hiệu lực từ thời điểm 7 đến thời điểm 9.
Vấn đề thời gian thứ hai là thời gian giao dịch . Một hàng cho hợp đồng được đề cập ở trên đã được chèn vào thời điểm 1 và là phiên bản sự thật duy nhất được cơ sở dữ liệu biết cho đến khi ai đó thay đổi nó, hoặc thậm chí là hết thời gian. Khi hàng được cập nhật tại thời điểm 2, hàng ban đầu được biết là đúng với cơ sở dữ liệu từ thời điểm 1 đến thời điểm 2. Một hàng mới cho cùng một mệnh đề được chèn với thời gian hợp lệ cho cơ sở dữ liệu từ thời điểm 2 đến hết thời gian. Thời gian giao dịch còn được gọi là thời gian hệ thống hoặc thời gian cơ sở dữ liệu .
Tất nhiên, bạn cũng có thể triển khai cả bảng phiên bản ứng dụng và hệ thống. Các bảng như vậy được gọi là cắnmporal bảng.
Trong SQL Server 2016, bạn nhận được hỗ trợ cho hệ thống hết thời gian sử dụng với bảng tạm thời được phiên bản hệ thống . Nếu bạn cần thời gian triển khai ứng dụng, bạn cần tự phát triển một giải pháp.
Người điều hành khoảng thời gian của Allen
Lý thuyết về dữ liệu thời gian trong mô hình quan hệ bắt đầu phát triển hơn ba mươi năm trước. Tôi sẽ giới thiệu một số toán tử Boolean khá hữu ích và một vài toán tử hoạt động trên các khoảng và trả về một khoảng. Các toán tử này được gọi là toán tử Allen, được đặt theo tên của J. F. Allen, người đã xác định một số trong số chúng trong một bài báo nghiên cứu năm 1983 về các khoảng thời gian. Tất cả chúng vẫn được chấp nhận là hợp lệ và cần thiết. Hệ thống quản lý cơ sở dữ liệu có thể giúp bạn xử lý thời gian ứng dụng bằng cách triển khai các toán tử này ngay lập tức.
Đầu tiên hãy để tôi giới thiệu ký hiệu mà tôi sẽ sử dụng. Tôi sẽ làm việc theo hai khoảng thời gian, ký hiệu là i 1 và i 2 . Thời điểm bắt đầu của khoảng thời gian đầu tiên là b 1 và kết thúc là e 1 ; thời điểm bắt đầu của khoảng thời gian thứ hai là b 2 và kết thúc là e 2 . Toán tử Boolean của Allen được định nghĩa trong bảng sau.
[table id =2 /]
Ngoài toán tử Boolean, có ba toán tử của Allen chấp nhận khoảng thời gian làm tham số đầu vào và trả về một khoảng thời gian. Các toán tử này tạo thành đại số khoảng đơn giản . Lưu ý rằng các toán tử đó có cùng tên với các toán tử quan hệ mà bạn có thể đã quen thuộc:Union, Intersect và Minus. Tuy nhiên, chúng không hoạt động chính xác như các đối tác quan hệ của chúng. Nói chung, sử dụng bất kỳ toán tử nào trong ba toán tử khoảng thời gian, nếu hoạt động sẽ dẫn đến một tập hợp thời gian trống hoặc trong một tập hợp không thể được mô tả bởi một khoảng thời gian, thì toán tử phải trả về NULL. Sự kết hợp của hai khoảng chỉ có ý nghĩa nếu các khoảng gặp nhau hoặc trùng nhau. Giao lộ chỉ có ý nghĩa nếu các khoảng trùng nhau. Toán tử khoảng trừ chỉ có ý nghĩa trong một số trường hợp. Ví dụ, (3:10) Minus (5:7) trả về NULL vì kết quả không thể được mô tả bằng một khoảng. Bảng sau đây tóm tắt định nghĩa về các toán tử của đại số khoảng.
[id bảng =3 /]
Vấn đề hiệu suất truy vấn chồng chéo Một trong những toán tử phức tạp nhất cần triển khai là chồng chéo nhà điều hành. Các truy vấn cần tìm các khoảng chồng chéo không đơn giản để được tối ưu hóa. Tuy nhiên, các truy vấn như vậy là khá thường xuyên trên các bảng tạm thời. Trong phần này và hai bài tiếp theo, tôi sẽ chỉ cho bạn một số cách để tối ưu hóa các truy vấn như vậy. Nhưng trước khi tôi giới thiệu các giải pháp, hãy để tôi giới thiệu vấn đề.
Để giải thích vấn đề, tôi cần một số dữ liệu. Đoạn mã sau đây cho thấy một ví dụ về cách tạo bảng với các khoảng thời gian hợp lệ được biểu thị bằng b và e cột, nơi bắt đầu và kết thúc khoảng thời gian được biểu thị dưới dạng số nguyên. Bảng được điền với dữ liệu demo từ bảng WideWorldImporters.Sales.OrderLines. Xin lưu ý rằng có nhiều phiên bản WideWorldImporters cơ sở dữ liệu, vì vậy bạn có thể nhận được kết quả hơi khác một chút. Tôi đã sử dụng tệp sao lưu WideWorldImporters-Standard.bak từ https://github.com/Microsoft/sql-server-samples/releases/tag/wide-world-importers-v1.0 để khôi phục cơ sở dữ liệu demo này trên phiên bản SQL Server của tôi .
Tạo dữ liệu demo
Tôi đã tạo một bảng trình diễn dbo.Intervals trong tempd cơ sở dữ liệu với mã sau.
USE tempdb; GO SELECT OrderLineID AS id, StockItemID * (OrderLineID % 5 + 1) AS b, LastEditedBy + StockItemID * (OrderLineID % 5 + 1) AS e INTO dbo.Intervals FROM WideWorldImporters.Sales.OrderLines; -- 231412 rows GO ALTER TABLE dbo.Intervals ADD CONSTRAINT PK_Intervals PRIMARY KEY(id); CREATE INDEX idx_b ON dbo.Intervals(b) INCLUDE(e); CREATE INDEX idx_e ON dbo.Intervals(e) INCLUDE(b); GO
Cũng xin lưu ý các chỉ mục tạo. Hai chỉ mục này là tối ưu cho các tìm kiếm ở đầu khoảng thời gian hoặc ở cuối khoảng thời gian. Bạn có thể kiểm tra điểm bắt đầu tối thiểu và kết thúc tối đa của tất cả các khoảng thời gian bằng mã sau.
SELECT MIN(b), MAX(e) FROM dbo.Intervals;
Bạn có thể thấy trong kết quả rằng thời điểm bắt đầu tối thiểu là 1 và thời gian kết thúc tối đa là 1155.
Đưa ra bối cảnh cho dữ liệu
Bạn có thể nhận thấy rằng tôi đại diện cho thời điểm bắt đầu và kết thúc dưới dạng số nguyên. Bây giờ tôi cần cung cấp cho các khoảng thời gian một số bối cảnh thời gian. Trong trường hợp này, một mốc thời gian duy nhất đại diện cho ngày . Đoạn mã sau tạo bảng tra cứu ngày và điền vào nó. Lưu ý rằng ngày bắt đầu là ngày 1 tháng 7 năm 2014.
CREATE TABLE dbo.DateNums (n INT NOT NULL PRIMARY KEY, d DATE NOT NULL); GO DECLARE @i AS INT = 1, @d AS DATE = '20140701'; WHILE @i <= 1200 BEGIN INSERT INTO dbo.DateNums (n, d) SELECT @i, @d; SET @i += 1; SET @d = DATEADD(day,1,@d); END; GO
Bây giờ, bạn có thể nối bảng dbo.Intervals với bảng dbo.DateNums hai lần, để cung cấp ngữ cảnh cho các số nguyên đại diện cho phần đầu và phần cuối của các khoảng.
SELECT i.id, i.b, d1.d AS dateB, i.e, d2.d AS dateE FROM dbo.Intervals AS i INNER JOIN dbo.DateNums AS d1 ON i.b = d1.n INNER JOIN dbo.DateNums AS d2 ON i.e = d2.n ORDER BY i.id;
Giới thiệu Vấn đề Hiệu suất
Vấn đề với các truy vấn tạm thời là khi đọc từ một bảng, SQL Server chỉ có thể sử dụng một chỉ mục và loại bỏ thành công các hàng không phải là ứng cử viên cho kết quả chỉ từ một phía, sau đó quét phần còn lại của dữ liệu. Ví dụ:bạn cần tìm tất cả các khoảng trong bảng trùng với một khoảng đã cho. Hãy nhớ rằng hai khoảng trùng nhau khi đầu khoảng thời gian đầu tiên thấp hơn hoặc bằng cuối khoảng thời gian thứ hai và đầu khoảng thời gian thứ hai thấp hơn hoặc bằng cuối khoảng thời gian đầu tiên hoặc theo toán học khi (b1 ≤ e2) VÀ (b2 ≤ e1).
Truy vấn sau đây đã tìm kiếm tất cả các khoảng trùng lặp với khoảng (10, 30). Lưu ý rằng điều kiện thứ hai (b2 ≤ e1) được chuyển thành (e1 ≥ b2) để đọc đơn giản hơn (khoảng đầu và cuối khoảng từ bảng luôn nằm ở bên trái của điều kiện). Khoảng thời gian đã cho hoặc đã tìm kiếm nằm ở đầu dòng thời gian cho tất cả các khoảng thời gian trong bảng.
SET STATISTICS IO ON; DECLARE @b AS INT = 10, @e AS INT = 30; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND e >= @b OPTION (RECOMPILE);
Truy vấn sử dụng 36 lần đọc logic. Nếu bạn kiểm tra kế hoạch thực thi, bạn có thể thấy rằng truy vấn đã sử dụng tìm kiếm chỉ mục trong chỉ mục idx_b với vị từ tìm kiếm [tempdb]. [Dbo]. [Khoảng] .b <=Toán tử vô hướng ((30)) và sau đó quét các hàng và chọn các hàng kết quả bằng cách sử dụng vị từ dư [tempdb]. [dbo]. [Khoảng]. [e]> =(10). Bởi vì khoảng thời gian được tìm kiếm là ở đầu dòng thời gian, vị từ tìm kiếm đã loại bỏ thành công phần lớn các hàng; chỉ một vài khoảng trong bảng có điểm đầu thấp hơn hoặc bằng 30.
Bạn sẽ nhận được truy vấn hiệu quả tương tự nếu khoảng thời gian được tìm kiếm nằm ở cuối dòng thời gian, chỉ là SQL Server sẽ sử dụng chỉ mục idx_e để tìm kiếm. Tuy nhiên, điều gì sẽ xảy ra nếu khoảng thời gian được tìm kiếm ở giữa dòng thời gian, như truy vấn sau đây hiển thị?
DECLARE @b AS INT = 570, @e AS INT = 590; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND e >= @b OPTION (RECOMPILE);
Lần này, truy vấn sử dụng 111 lần đọc logic. Với một bảng lớn hơn, sự khác biệt với truy vấn đầu tiên sẽ còn lớn hơn. Nếu bạn kiểm tra kế hoạch thực thi, bạn có thể phát hiện ra rằng SQL Server đã sử dụng chỉ mục idx_e với [tempdb]. [Dbo]. [Intervals] .e> =Scalar Operator ((570)) seek vị từ và [tempdb]. [ dbo]. [Khoảng]. [b] <=(590) vị từ dư. Vị từ tìm kiếm loại trừ khoảng một nửa số hàng từ một phía, trong khi một nửa số hàng từ phía bên kia được quét và kết quả là các hàng được trích xuất với vị từ còn lại.
Giải pháp T-SQL nâng cao
Có một giải pháp sẽ sử dụng chỉ mục đó để loại bỏ các hàng ở cả hai phía của khoảng thời gian được tìm kiếm bằng cách sử dụng một chỉ mục duy nhất. Hình sau cho thấy logic này.
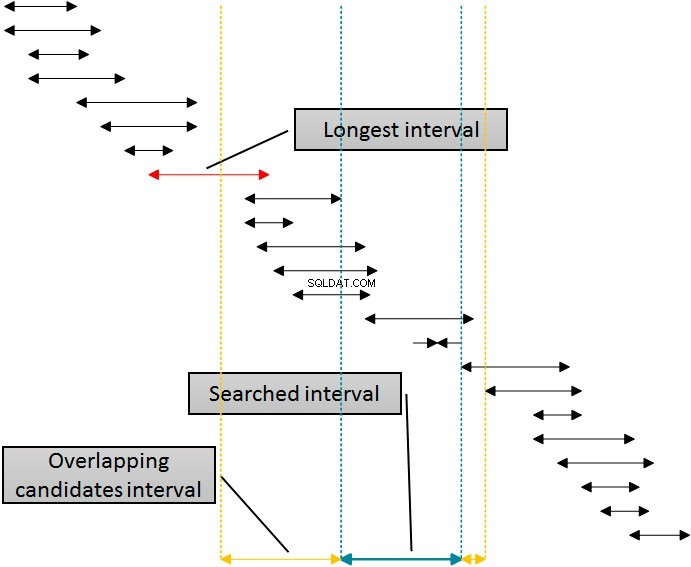
Các khoảng trong hình được sắp xếp theo đường biên dưới, thể hiện việc sử dụng chỉ mục idx_b của SQL Server. Việc loại bỏ các khoảng ở phía bên phải của khoảng đã cho (đã tìm kiếm) rất đơn giản:chỉ cần loại bỏ tất cả các khoảng mà phần đầu lớn hơn ít nhất một đơn vị (nhiều hơn bên phải) của phần cuối của khoảng đã cho. Bạn có thể thấy ranh giới này trong hình được biểu thị bằng đường chấm ngoài cùng bên phải. Tuy nhiên, việc loại bỏ từ bên trái phức tạp hơn. Để sử dụng cùng một chỉ mục, chỉ mục idx_b để loại bỏ từ bên trái, tôi cần sử dụng phần đầu của các khoảng trong bảng trong mệnh đề WHERE của truy vấn. Tôi phải đi về phía bên trái từ đầu của khoảng đã cho (đã tìm kiếm) ít nhất bằng độ dài của khoảng dài nhất trong bảng, được đánh dấu bằng chú thích trong hình. Các khoảng bắt đầu trước vạch vàng bên trái không được trùng với khoảng đã cho (xanh lam).
Vì tôi đã biết rằng độ dài của khoảng thời gian dài nhất là 20, tôi có thể viết một truy vấn nâng cao theo một cách khá đơn giản.
DECLARE @b AS INT = 570, @e AS INT = 590; DECLARE @max AS INT = 20; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND b >= @b - @max AND e >= @b AND e <= @e + @max OPTION (RECOMPILE);
Truy vấn này truy xuất các hàng giống như truy vấn trước đó chỉ với 20 lần đọc logic. Nếu bạn kiểm tra kế hoạch thực thi, bạn có thể thấy rằng idx_b đã được sử dụng, với vị từ tìm kiếm Các phím tìm kiếm [1]:Bắt đầu:[tempdb]. [Dbo]. [Khoảng] .b> =Toán tử vô hướng ((550)) , Kết thúc:[tempdb]. [Dbo]. [Khoảng] .b <=Toán tử vô hướng ((590)), đã loại bỏ thành công các hàng từ cả hai phía của dòng thời gian và sau đó là vị từ còn lại [tempdb]. [Dbo]. [Khoảng]. [E]> =(570) VÀ [tempdb]. [Dbo]. [Khoảng]. [E] <=(610) được sử dụng để chọn các hàng từ quá trình quét một phần rất hạn chế.
Tất nhiên, con số này có thể được thay đổi để bao gồm các trường hợp khi chỉ mục idx_e sẽ hữu ích hơn. Với chỉ số này, việc loại bỏ từ bên trái rất đơn giản - loại bỏ tất cả các khoảng kết thúc ít nhất một đơn vị trước khi bắt đầu khoảng đã cho. Lần này, việc loại bỏ từ bên phải phức tạp hơn - phần cuối của các khoảng trong bảng không được ở bên phải nhiều hơn phần cuối của khoảng đã cho cộng với độ dài lớn nhất của tất cả các khoảng trong bảng.
Xin lưu ý rằng hiệu suất này là kết quả của dữ liệu cụ thể trong bảng. Độ dài tối đa của một khoảng là 20. Bằng cách này, SQL Server có thể loại bỏ rất hiệu quả các khoảng từ cả hai phía. Tuy nhiên, nếu chỉ có một khoảng dài trong bảng, mã sẽ trở nên kém hiệu quả hơn nhiều, bởi vì SQL Server sẽ không thể loại bỏ nhiều hàng từ một phía, bên trái hoặc bên phải, tùy thuộc vào chỉ mục mà nó sẽ sử dụng. . Dù sao, trong cuộc sống thực, độ dài khoảng không thay đổi nhiều lần, vì vậy kỹ thuật tối ưu hóa này có thể rất hữu ích, đặc biệt là vì nó đơn giản.
Kết luận
Xin lưu ý rằng đây chỉ là một giải pháp khả thi. Bạn có thể tìm thấy một giải pháp phức tạp hơn, nhưng nó mang lại hiệu suất có thể dự đoán được bất kể độ dài của khoảng thời gian dài nhất trong bài viết Truy vấn khoảng thời gian trong SQL Server của Itzik Ben-Gan (https://sqlmag.com/t-sql/ sql-server-khoảng thời gian-truy vấn). Tuy nhiên, tôi thực sự thích T-SQL nâng cao giải pháp tôi đã trình bày trong bài viết này. Giải pháp này rất đơn giản; tất cả những gì bạn cần làm là thêm hai vị từ vào mệnh đề WHERE của các truy vấn chồng chéo của bạn. Tuy nhiên, đây không phải là sự kết thúc của các khả năng. Hãy theo dõi, trong hai bài viết tiếp theo, tôi sẽ chỉ cho bạn nhiều giải pháp hơn, vì vậy bạn sẽ có nhiều khả năng trong hộp công cụ tối ưu hóa của mình.
Công cụ hữu ích:
dbForge Query Builder dành cho SQL Server - cho phép người dùng tạo các truy vấn SQL phức tạp một cách nhanh chóng và dễ dàng thông qua giao diện trực quan trực quan mà không cần viết mã thủ công.