Tất cả các bài đăng của tôi trong năm nay đều nói về phản ứng đầu gối để chờ số liệu thống kê, nhưng trong bài đăng này, tôi chuyển hướng khỏi chủ đề đó để nói về một con gấu lỗi cụ thể của tôi:bộ đếm hiệu suất tuổi thọ trang (mà tôi sẽ gọi là PLE ).
PLE có nghĩa là gì?
Có tất cả các loại tuyên bố không chính xác về tuổi thọ của trang trên Internet và nghiêm trọng nhất là những tuyên bố chỉ định rằng giá trị 300 là ngưỡng mà bạn nên lo lắng.
Để hiểu tại sao tuyên bố này lại gây hiểu lầm như vậy, bạn cần hiểu PLE thực sự là gì.
Định nghĩa của PLE là thời gian dự kiến, tính bằng giây, một trang tệp dữ liệu được đọc vào vùng đệm (bộ nhớ đệm trong bộ nhớ của các trang tệp dữ liệu) sẽ vẫn còn trong bộ nhớ trước khi bị đẩy ra khỏi bộ nhớ để nhường chỗ cho một dữ liệu khác trang tập tin. Một cách khác để nghĩ về PLE là một phép đo tức thời áp lực lên vùng đệm để tạo không gian trống cho các trang được đọc từ đĩa. Đối với cả hai định nghĩa này, con số cao hơn sẽ tốt hơn.
Ngưỡng PLE tốt là gì?
PLE 300 có nghĩa là toàn bộ vùng đệm của bạn đang được xả một cách hiệu quả và được đọc lại sau mỗi năm phút. Khi Microsoft đưa ra hướng dẫn về ngưỡng cho PLE 300 lần đầu tiên vào khoảng năm 2005/2006, con số đó có thể có ý nghĩa hơn vì lượng bộ nhớ trung bình trên máy chủ thấp hơn nhiều.
Ngày nay, nơi các máy chủ thường có dung lượng bộ nhớ từ 64GB, 128GB và cao hơn, thì việc đọc nhiều dữ liệu từ đĩa sau mỗi năm phút có thể là nguyên nhân gây ra sự cố hiệu suất tê liệt
Trên thực tế, vào thời điểm PLE đang lơ lửng ở mức hoặc dưới 300, máy chủ của bạn đã ở trong tình trạng căng thẳng. Bạn sẽ bắt đầu lo lắng, trước khi PLE xuống thấp như vậy.
Vậy ngưỡng nào để sử dụng khi bạn nên lo lắng?
Đó chỉ là vấn đề. Tôi không thể cung cấp cho bạn một ngưỡng vì con số đó sẽ khác nhau đối với mọi người. Nếu bạn thực sự, thực sự muốn một con số để sử dụng, đồng nghiệp của tôi, Jonathan Kehayias đã đưa ra công thức:
(Bộ nhớ đệm vùng đệm tính bằng GB / 4) x 300Ngay cả con số đó cũng hơi tùy ý và số dặm của bạn sẽ thay đổi.
Tôi không muốn giới thiệu bất kỳ con số nào. Lời khuyên của tôi dành cho bạn là đo PLE của mình khi hiệu suất ở mức mong muốn - đó là ngưỡng mà bạn sử dụng.
Vì vậy, bạn có bắt đầu lo lắng ngay khi PLE giảm xuống dưới ngưỡng đó không? Không. Bạn bắt đầu lo lắng khi PLE giảm xuống dưới ngưỡng đó và vẫn ở dưới ngưỡng đó hoặc nếu nó giảm mạnh và bạn không biết tại sao.
Điều này là do có một số hoạt động sẽ gây ra giảm PLE (ví dụ:chạy DBCC CHECKDB hoặc việc xây dựng lại chỉ mục đôi khi có thể thực hiện được) và không gây lo ngại. Nhưng nếu bạn thấy PLE sụt giảm lớn và bạn không biết điều gì gây ra nó, thì đó là lúc bạn nên lo lắng.
Bạn có thể tự hỏi làm thế nào DBCC CHECKDB có thể gây ra sự sụt giảm PLE khi nó không thích và cố gắng tránh làm sạch vùng đệm với dữ liệu mà nó sử dụng (xem bài đăng trên blog này để biết giải thích). Đó là vì cấp bộ nhớ thực thi truy vấn cho DBCC CHECKDB bị tính toán sai bởi Trình tối ưu hóa truy vấn và có thể gây ra giảm đáng kể kích thước của vùng đệm (bộ nhớ cho khoản tài trợ bị đánh cắp khỏi vùng đệm) và do đó PLE giảm.
Bạn giám sát PLE như thế nào?
Đây là một chút khó khăn. Hầu hết mọi người sẽ đi thẳng đến Buffer Manager đối tượng hiệu suất trong PerfMon và theo dõi Page life expectancy ngược lại. Đây có phải là cách tiếp cận đúng? Nhiều khả năng là không.
Tôi muốn nói rằng phần lớn các máy chủ hiện nay đang sử dụng kiến trúc NUMA và điều này có ảnh hưởng sâu sắc đến cách bạn giám sát PLE.
Khi NUMA có liên quan, vùng đệm được chia thành các nút đệm, với một nút đệm trên mỗi nút NUMA mà SQL Server có thể 'nhìn thấy'. Mỗi nút đệm theo dõi PLE riêng biệt và Buffer Manager:Page life expectancy bộ đếm là giá trị trung bình của PLEs nút đệm. Nếu bạn chỉ theo dõi tổng thể vùng đệm PLE, thì áp lực lên một trong các nút đệm có thể bị che bởi giá trị trung bình (tôi thảo luận điều này trong một bài đăng trên blog tại đây).
Vì vậy, nếu máy chủ của bạn đang sử dụng NUMA, bạn cần theo dõi Buffer Node:Page life expectancy riêng lẻ bộ đếm (sẽ có một đối tượng hiệu suất Nút đệm cho mỗi nút NUMA), nếu không, bạn đang theo dõi tốt Buffer Manager:Page life expectancy bộ đếm.
Tốt hơn nữa là sử dụng công cụ giám sát như SQL Sentry Performance Advisor, công cụ này sẽ hiển thị bộ đếm này như một phần của trang tổng quan, có tính đến các nút NUMA trên máy chủ và cho phép bạn dễ dàng định cấu hình cảnh báo.
Ví dụ về việc Sử dụng Cố vấn Hiệu suất
Dưới đây là phần ví dụ về ảnh chụp màn hình từ Trình tư vấn hiệu suất cho hệ thống có một nút NUMA duy nhất:
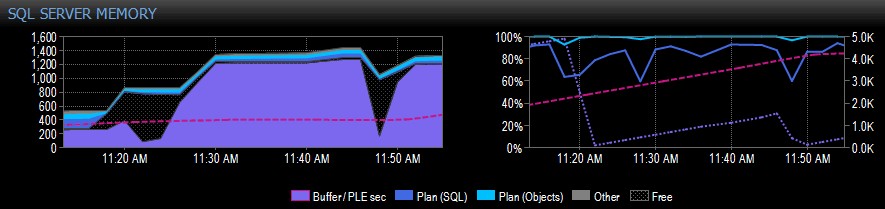
Ở phía bên phải của hình chụp, đường gạch ngang màu hồng là PLE từ 10:30 sáng đến khoảng 11 giờ 20 sáng - nó đang tăng đều đặn lên đến 5.000 hoặc lâu hơn, một con số thực sự tốt. Ngay trước 11 giờ 20, có một mức giảm rất lớn và sau đó nó bắt đầu tăng trở lại cho đến 11 giờ 45, tại đó nó lại giảm xuống.
Đây thường là những gì bạn sẽ thấy nếu vùng đệm đầy, với tất cả các trang được sử dụng và sau đó một truy vấn chạy khiến một lượng lớn dữ liệu khác nhau được đọc từ đĩa, thay thế phần lớn những gì đã có trong bộ nhớ và gây ra giảm mạnh trong PLE. Nếu bạn không biết điều gì đã gây ra sự việc như thế này, bạn muốn điều tra, như tôi mô tả kỹ hơn.
Ví dụ thứ hai, ảnh chụp màn hình bên dưới là từ một trong những máy khách DBA từ xa của chúng tôi, nơi máy chủ có hai nút NUMA (bạn có thể thấy rằng có hai dòng PLE màu tím) và nơi chúng tôi sử dụng Trình tư vấn hiệu suất rộng rãi:

Trên máy chủ của khách hàng này, vào khoảng 5 giờ sáng hàng ngày, công việc kiểm tra tính nhất quán và duy trì chỉ mục bắt đầu khiến PLE giảm ở cả hai nút đệm. Đây là hành vi dự kiến nên không cần điều tra miễn là PLE tăng trở lại trong ngày.
Bạn có thể làm gì khi bỏ PLE?
Nếu không xác định được nguyên nhân của sự sụt giảm PLE, bạn có thể thực hiện một số điều sau:
- Nếu sự cố đang xảy ra ngay bây giờ, hãy điều tra xem truy vấn nào đang gây ra lượt đọc bằng cách sử dụng
sys.dm_os_waiting_tasksDMV để xem chuỗi nào đang đợi các trang được đọc từ đĩa (tức là những chuỗi đang chờPAGEIOLATCH_SH), và sau đó sửa các truy vấn đó. - Nếu sự cố đã xảy ra trước đây, hãy tìm trong DMV sys.dm_exec_query_stats để biết các truy vấn có số lần đọc vật lý cao hoặc sử dụng công cụ giám sát có thể cung cấp cho bạn thông tin đó (ví dụ:dạng xem SQL Hàng đầu trong Trình tư vấn Hiệu suất) và sau đó sửa các truy vấn đó.
- Tương quan giữa sự sụt giảm PLE với các công việc Đại lý đã lên lịch thực hiện bảo trì cơ sở dữ liệu.
- Tìm kiếm các truy vấn có cấp bộ nhớ thực thi truy vấn rất lớn bằng cách sử dụng
sys.dm_exec_query_memory_grantsDMV, sau đó sửa các truy vấn đó.
Bài đăng trước của tôi ở đây giải thích thêm về # 1 và # 2 và một tập lệnh để điều tra các lần chờ xảy ra trên máy chủ và liên kết đến các kế hoạch truy vấn của chúng ở đây.
Việc "khắc phục những truy vấn đó" nằm ngoài phạm vi của bài đăng này, vì vậy tôi sẽ để nó vào lúc khác hoặc như một bài tập cho người đọc ☺
Tóm tắt
Đừng rơi vào bẫy tin vào bất kỳ ngưỡng PLE được đề xuất nào mà bạn có thể đọc trực tuyến. Cách tốt nhất để phản ứng với các thay đổi của PLE là khi PLE giảm xuống dưới bất kỳ giá trị nào của bạn mức độ thoải mái là và vẫn ở đó - đó là dấu hiệu về sự cố hiệu suất mà bạn nên điều tra.
Trong phần tiếp theo của loạt bài này, tôi sẽ thảo luận về một nguyên nhân phổ biến khác của việc điều chỉnh hiệu suất giật đầu gối. Cho đến lúc đó, chúc bạn khắc phục sự cố!