Khi xem xét hiệu suất truy vấn, có rất nhiều nguồn thông tin tuyệt vời bên trong SQL Server và một trong những mục yêu thích của tôi là chính kế hoạch truy vấn. Trong một số bản phát hành gần đây nhất, đặc biệt là bắt đầu với SQL Server 2012, mỗi phiên bản mới đã bao gồm nhiều chi tiết hơn trong các kế hoạch thực thi. Trong khi danh sách các tính năng nâng cao tiếp tục tăng lên, đây là một số thuộc tính mà tôi có, tôi thấy có giá trị:
- NonParallelPlanReason (SQL Server 2012)
- Chẩn đoán vị từ kéo xuống còn lại (SQL Server 2012 SP3, SQL Server 2014 SP2, SQL Server 2016 SP1)
- chẩn đoán tràn tempdb (SQL Server 2012 SP3, SQL Server 2014 SP2, SQL Server 2016)
- Đã bật cờ theo dõi (SQL Server 2012 SP4, SQL Server 2014 SP2, SQL Server 2016 SP1)
- Thống kê thực thi truy vấn của toán tử (SQL Server 2014 SP2, SQL Server 2016)
- Bộ nhớ tối đa được kích hoạt cho một truy vấn (SQL Server 2014 SP2, SQL Server 2016 SP1)
Để xem những gì tồn tại cho từng phiên bản của SQL Server, hãy truy cập trang Showplan Schema, nơi bạn có thể tìm thấy giản đồ cho từng phiên bản kể từ SQL Server 2005.
Tôi rất thích tất cả dữ liệu bổ sung này, điều quan trọng cần lưu ý là một số thông tin phù hợp hơn với kế hoạch thực thi thực tế, so với thông tin ước tính (ví dụ:thông tin tràn tempdb). Một số ngày chúng tôi có thể nắm bắt và sử dụng kế hoạch thực tế để xử lý sự cố, những lúc khác chúng tôi phải sử dụng kế hoạch ước tính. Rất thường xuyên, chúng tôi nhận được kế hoạch ước tính đó - kế hoạch đã được sử dụng để thực thi có vấn đề - từ bộ đệm kế hoạch của SQL Server. Và kéo các kế hoạch riêng lẻ là thích hợp khi điều chỉnh một truy vấn hoặc tập hợp hoặc các truy vấn cụ thể. Nhưng còn khi bạn muốn có ý tưởng về nơi tập trung nỗ lực điều chỉnh của mình về mặt mẫu thì sao?
Bộ đệm ẩn kế hoạch SQL Server là một nguồn thông tin quan trọng khi nói đến việc điều chỉnh hiệu suất và ý tôi không chỉ đơn giản là khắc phục sự cố và cố gắng hiểu những gì đang chạy trong hệ thống. Trong trường hợp này, tôi đang nói về thông tin khai thác từ chính các kế hoạch, được tìm thấy trong sys.dm_exec_query_plan, được lưu trữ dưới dạng XML trong cột query_plan.
Khi bạn kết hợp dữ liệu này với thông tin từ sys.dm_exec_sql_text (để bạn có thể dễ dàng xem văn bản của truy vấn) và sys.dm_exec_query_stats (thống kê thực thi), bạn có thể đột nhiên bắt đầu tìm kiếm không chỉ những truy vấn là những câu hỏi hay thực thi thường xuyên nhất, nhưng những kế hoạch có chứa một loại kết hợp cụ thể, hoặc quét chỉ mục, hoặc những kế hoạch có chi phí cao nhất. Điều này thường được gọi là khai thác bộ nhớ cache của kế hoạch và có một số bài đăng trên blog nói về cách thực hiện điều này. Đồng nghiệp của tôi, Jonathan Kehayias, nói rằng anh ấy ghét viết XML nhưng anh ấy có một số bài đăng với các truy vấn để khai thác bộ nhớ cache của kế hoạch:
- Điều chỉnh "ngưỡng chi phí cho tính song song" từ Plan Cache
- Tìm chuyển đổi cột ngầm định trong bộ nhớ cache kế hoạch
- Tìm những truy vấn nào trong bộ nhớ cache của gói sử dụng một chỉ mục cụ thể
- Tìm hiểu sâu về bộ nhớ cache của kế hoạch SQL:Tìm chỉ mục bị thiếu
- Tìm các Tra cứu chính bên trong Bộ nhớ cache kế hoạch
Nếu bạn chưa bao giờ khám phá những gì trong bộ nhớ cache kế hoạch của mình, các truy vấn trong các bài đăng này là một khởi đầu tốt. Tuy nhiên, bộ nhớ cache của kế hoạch có những hạn chế của nó. Ví dụ:có thể thực hiện một truy vấn và không có kế hoạch đi vào bộ nhớ cache. Ví dụ:nếu bạn đã bật tùy chọn tối ưu hóa cho khối lượng công việc adhoc, thì trong lần thực thi đầu tiên, sơ đồ kế hoạch đã biên dịch được lưu trữ trong bộ nhớ cache của kế hoạch, không phải là kế hoạch được biên dịch đầy đủ. Nhưng thách thức lớn nhất là bộ nhớ cache của kế hoạch là tạm thời. Có nhiều sự kiện trong SQL Server có thể xóa hoàn toàn bộ nhớ cache của gói hoặc xóa nó cho cơ sở dữ liệu và các kế hoạch có thể bị xóa khỏi bộ nhớ cache nếu không được sử dụng hoặc bị xóa sau khi biên dịch lại. Để chống lại điều này, thông thường bạn phải truy vấn bộ nhớ cache kế hoạch thường xuyên hoặc chụp nhanh nội dung vào một bảng theo lịch trình.
Điều này thay đổi trong SQL Server 2016 với Cửa hàng truy vấn.
Khi cơ sở dữ liệu người dùng đã bật Query Store, văn bản và kế hoạch cho các truy vấn được thực thi dựa trên cơ sở dữ liệu đó sẽ được ghi lại và lưu giữ trong các bảng nội bộ. Thay vì một cái nhìn tạm thời về những gì hiện đang thực thi, chúng ta có một bức tranh dài hạn về những gì đã thực thi trước đó. Lượng dữ liệu được giữ lại được xác định bởi cài đặt CLEANUP_POLICY, cài đặt này mặc định là 30 ngày. So với bộ nhớ cache của gói có thể biểu thị thời gian thực thi truy vấn chỉ trong vài giờ, dữ liệu Cửa hàng truy vấn là một công cụ thay đổi trò chơi.
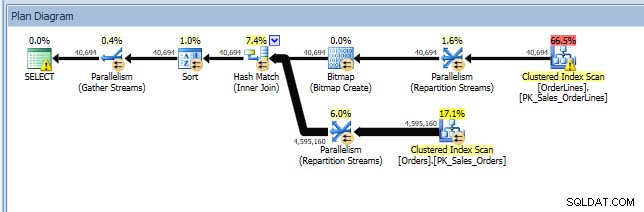
Hãy xem xét một tình huống mà bạn đang thực hiện một số phân tích chỉ mục - bạn có một số chỉ mục không được sử dụng và bạn có một số đề xuất từ các DMV chỉ mục bị thiếu. Các DMV chỉ mục bị thiếu không cung cấp bất kỳ chi tiết nào về truy vấn nào đã tạo ra đề xuất chỉ mục bị thiếu. Bạn có thể truy vấn bộ đệm ẩn kế hoạch, sử dụng truy vấn từ bài đăng Tìm chỉ mục bị thiếu của Jonathan. Nếu tôi thực thi điều đó đối với phiên bản SQL Server cục bộ của mình, tôi sẽ nhận được một vài hàng kết quả liên quan đến một số truy vấn mà tôi đã chạy trước đó.

Tôi có thể mở kế hoạch trong Plan Explorer và tôi thấy có một cảnh báo trên toán tử SELECT, dành cho chỉ mục bị thiếu:
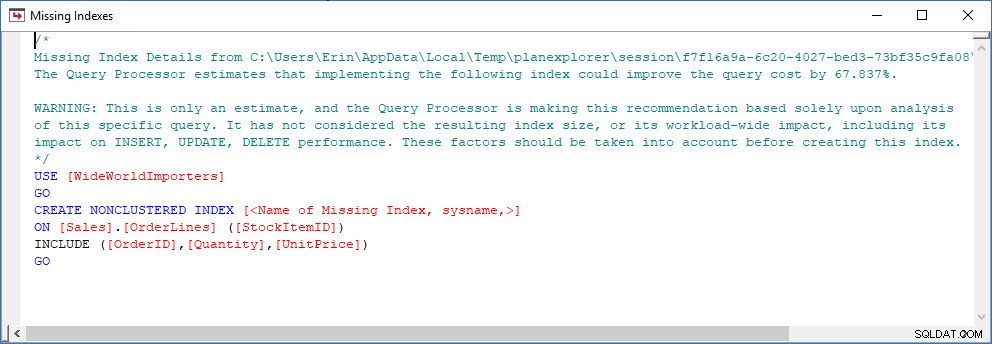
Đây là một khởi đầu tuyệt vời, nhưng một lần nữa, kết quả đầu ra của tôi phụ thuộc vào bất cứ thứ gì có trong bộ nhớ cache. Tôi có thể lấy truy vấn của Jonathan và sửa đổi cho Cửa hàng truy vấn, sau đó chạy nó trên cơ sở dữ liệu WideWorldImporters bản demo của tôi:
USE WideWorldImporters;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT TRY_CONVERT(XML, [qsp].[query_plan]) AS [query_plan]
FROM sys.query_store_plan [qsp]) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1;
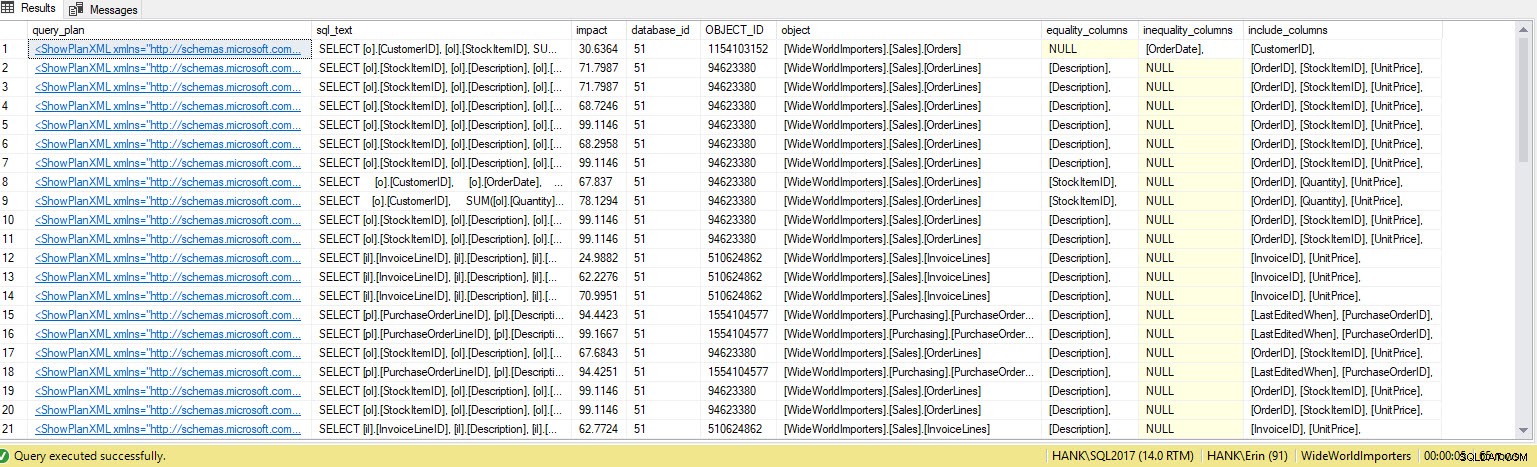
Tôi nhận được nhiều hàng hơn trong đầu ra. Một lần nữa, dữ liệu Cửa hàng truy vấn đại diện cho một chế độ xem lớn hơn về các truy vấn được thực thi đối với hệ thống và việc sử dụng dữ liệu này cung cấp cho chúng ta một phương pháp toàn diện để xác định không chỉ những chỉ mục nào bị thiếu mà còn những truy vấn nào mà những chỉ mục đó sẽ hỗ trợ. Từ đây, chúng ta có thể tìm hiểu sâu hơn về Cửa hàng truy vấn và xem xét các chỉ số hiệu suất và tần suất thực thi để hiểu tác động của việc tạo chỉ mục và quyết định xem truy vấn có thực thi thường xuyên đủ để đảm bảo chỉ mục hay không.
Nếu bạn không sử dụng Query Store, nhưng bạn đang sử dụng SentryOne, bạn có thể khai thác thông tin tương tự này từ cơ sở dữ liệu SentryOne. Kế hoạch truy vấn được lưu trữ trong bảng dbo.PerformanceAnalysisPlan ở định dạng nén, do đó, truy vấn chúng tôi sử dụng là một biến thể tương tự như ở trên, nhưng bạn sẽ nhận thấy hàm DECOMPRESS cũng được sử dụng:
USE SentryOne;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT -- need to decompress the gzipped xml here:
CONVERT(xml, CONVERT(nvarchar(max), CONVERT(varchar(max), DECOMPRESS(PlanTextGZ)))) AS [query_plan]
FROM dbo.PerformanceAnalysisPlan) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1; Trên một hệ thống SentryOne, tôi có kết quả sau (và tất nhiên việc nhấp vào bất kỳ giá trị query_plan nào sẽ mở ra sơ đồ đồ họa):

Một vài lợi thế mà SentryOne cung cấp so với Query Store là bạn không phải bật kiểu thu thập này trên mỗi cơ sở dữ liệu và cơ sở dữ liệu được giám sát không phải hỗ trợ các yêu cầu lưu trữ, vì tất cả dữ liệu được lưu trữ trong kho lưu trữ. Bạn cũng có thể nắm bắt thông tin này trên tất cả các phiên bản SQL Server được hỗ trợ, không chỉ những phiên bản hỗ trợ Cửa hàng truy vấn. Xin lưu ý rằng SentryOne chỉ thu thập các truy vấn vượt quá ngưỡng như thời lượng và số lần đọc. Bạn có thể điều chỉnh các ngưỡng mặc định này, nhưng cần lưu ý một điều khi khai thác cơ sở dữ liệu SentryOne:không phải tất cả các truy vấn đều có thể được thu thập. Ngoài ra, chức năng DECOMPRESS không khả dụng cho đến SQL Server 2016; đối với các phiên bản SQL Server cũ hơn, bạn sẽ muốn:
- Sao lưu cơ sở dữ liệu SentryOne và khôi phục nó trên SQL Server 2016 trở lên để chạy các truy vấn;
- bcp dữ liệu ra khỏi bảng dbo.PerformanceAnalysisPlan và nhập dữ liệu đó vào một bảng mới trên phiên bản SQL Server 2016;
- truy vấn cơ sở dữ liệu SentryOne qua một máy chủ được liên kết từ phiên bản SQL Server 2016; hoặc,
- truy vấn cơ sở dữ liệu từ mã ứng dụng có thể phân tích cú pháp cho những thứ cụ thể sau khi giải nén.
Với SentryOne, bạn có khả năng khai thác không chỉ bộ nhớ cache của gói mà còn cả dữ liệu được giữ lại trong kho lưu trữ SentryOne. Nếu bạn đang chạy SQL Server 2016 trở lên và bạn đã bật Cửa hàng truy vấn, bạn cũng có thể tìm thấy thông tin này trong sys.query_store_plan . Bạn không bị giới hạn chỉ trong ví dụ này về việc tìm kiếm các chỉ mục bị thiếu; tất cả các truy vấn từ các bài đăng trong bộ nhớ cache gói khác của Jonathan có thể được sửa đổi để được sử dụng để khai thác dữ liệu từ SentryOne hoặc từ Query Store. Hơn nữa, nếu bạn đủ quen thuộc với XQuery (hoặc sẵn sàng học hỏi), bạn có thể sử dụng Lược đồ Showplan để tìm ra cách phân tích cú pháp kế hoạch để tìm thông tin bạn muốn. Điều này cung cấp cho bạn khả năng tìm các mẫu và phản mẫu trong các kế hoạch truy vấn mà nhóm của bạn có thể khắc phục trước khi chúng trở thành sự cố.