Tại Hội nghị thượng đỉnh PASS vài tuần trước, Microsoft đã phát hành CTP2.1 của SQL Server 2019 và một trong những cải tiến tính năng lớn được bao gồm trong CTP là Nội tuyến UDF vô hướng. Trước bản phát hành này, tôi muốn tìm hiểu sự khác biệt về hiệu suất giữa nội tuyến của các UDF vô hướng và việc thực thi RBAR (hàng theo hàng) của các UDF vô hướng trong các phiên bản SQL Server trước đó và tôi đã xảy ra một tùy chọn cú pháp cho TẠO CHỨC NĂNG trong SQL Server Books Online mà tôi chưa từng thấy trước đây.
DDL cho TẠO CHỨC NĂNG hỗ trợ mệnh đề WITH cho các tùy chọn chức năng và trong khi đọc Sách Trực tuyến, tôi nhận thấy rằng cú pháp bao gồm như sau:
-- Transact-SQL Function Clauses
<function_option>::=
{
[ ENCRYPTION ]
| [ SCHEMABINDING ]
| [ RETURNS NULL ON NULL INPUT | CALLED ON NULL INPUT ]
| [ EXECUTE_AS_Clause ]
} Tôi thực sự tò mò về RETURNS NULL ON NULL INPUT tùy chọn chức năng vì vậy tôi quyết định thực hiện một số thử nghiệm. Tôi rất ngạc nhiên khi biết rằng đó thực sự là một dạng tối ưu hóa UDF vô hướng đã có trong sản phẩm ít nhất là SQL Server 2008 R2.
Hóa ra là nếu bạn biết rằng UDF vô hướng sẽ luôn trả về kết quả NULL khi đầu vào NULL được cung cấp thì UDF sẽ LUÔN được tạo với RETURNS NULL ON NULL INPUT tùy chọn, bởi vì sau đó SQL Server thậm chí không chạy định nghĩa hàm cho bất kỳ hàng nào có đầu vào là NULL - làm tắt nó có hiệu lực và tránh việc thực thi lãng phí thân hàm.
Để cho bạn thấy hành vi này, tôi sẽ sử dụng phiên bản SQL Server 2017 với Bản cập nhật tích lũy mới nhất được áp dụng cho nó và AdventureWorks2017 cơ sở dữ liệu từ GitHub (bạn có thể tải xuống từ đây) được cung cấp với dbo.ufnLeadingZeros hàm chỉ cần thêm các số 0 ở đầu vào giá trị đầu vào và trả về một chuỗi tám ký tự bao gồm các số 0 ở đầu đó. Tôi sẽ tạo một phiên bản mới của chức năng đó bao gồm RETURNS NULL ON NULL INPUT để tôi có thể so sánh nó với hàm ban đầu để biết hiệu suất thực thi.
USE [AdventureWorks2017];
GO
CREATE FUNCTION [dbo].[ufnLeadingZeros_new](
@Value int
)
RETURNS varchar(8)
WITH SCHEMABINDING, RETURNS NULL ON NULL INPUT
AS
BEGIN
DECLARE @ReturnValue varchar(8);
SET @ReturnValue = CONVERT(varchar(8), @Value);
SET @ReturnValue = REPLICATE('0', 8 - DATALENGTH(@ReturnValue)) + @ReturnValue;
RETURN (@ReturnValue);
END;
GO Với mục đích kiểm tra sự khác biệt về hiệu suất thực thi trong công cụ cơ sở dữ liệu của hai chức năng, tôi quyết định tạo phiên Sự kiện mở rộng trên máy chủ để theo dõi sqlserver.module_end sự kiện sẽ kích hoạt vào cuối mỗi lần thực thi UDF vô hướng cho mỗi hàng. Điều này cho phép tôi chứng minh ngữ nghĩa xử lý từng hàng và cũng để tôi theo dõi số lần hàm thực sự được gọi trong quá trình kiểm tra. Tôi cũng quyết định thu thập sql_batch_completed và sql_statement_completed sự kiện và lọc mọi thứ theo session_id để đảm bảo rằng tôi chỉ nắm bắt thông tin liên quan đến phiên mà tôi thực sự đang chạy thử nghiệm (nếu bạn muốn sao chép các kết quả này, bạn sẽ cần thay đổi 74 ở tất cả các vị trí trong mã bên dưới thành bất kỳ ID phiên nào mà bạn kiểm tra mã sẽ được chạy trong). Phiên sự kiện đang sử dụng TRACK_CAUSALITY để có thể dễ dàng đếm số lần thực thi hàm đã xảy ra thông qua activity_id.seq_no giá trị cho các sự kiện (tăng một cho mỗi sự kiện đáp ứng session_id bộ lọc).
CREATE EVENT SESSION [Session72] ON SERVER ADD EVENT sqlserver.module_end( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_batch_completed( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_batch_starting( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_statement_completed( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_statement_starting( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))) WITH (TRACK_CAUSALITY=ON) GO
Khi tôi bắt đầu phiên sự kiện và mở Trình xem dữ liệu trực tiếp trong Management Studio, tôi đã chạy hai truy vấn; một hàm sử dụng phiên bản gốc của hàm để chèn các số không vào CurrencyRateID trong cột Sales.SalesOrderHeader và hàm mới để tạo ra đầu ra giống hệt nhau nhưng sử dụng RETURNS NULL ON NULL INPUT và tôi đã nắm bắt thông tin Kế hoạch Thực thi Thực tế để so sánh.
SELECT SalesOrderID, dbo.ufnLeadingZeros(CurrencyRateID) FROM Sales.SalesOrderHeader; GO SELECT SalesOrderID, dbo.ufnLeadingZeros_new(CurrencyRateID) FROM Sales.SalesOrderHeader; GO
Xem xét dữ liệu Sự kiện mở rộng cho thấy một số điều thú vị. Đầu tiên, hàm gốc đã chạy 31.465 lần (từ số lượng của module_end sự kiện) và tổng thời gian CPU cho sql_statement_completed sự kiện là 204 mili giây với thời lượng 482 mili giây.
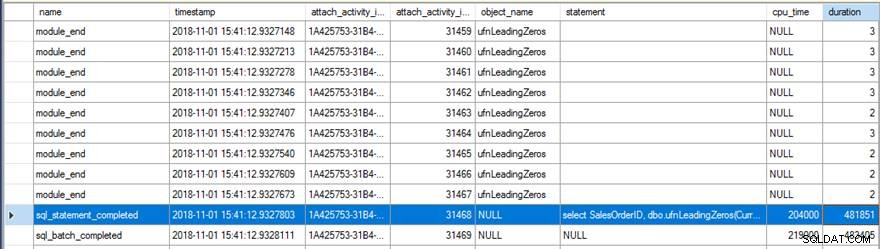
Phiên bản mới với tính năng RETURNS NULL ON NULL INPUT tùy chọn được chỉ định chỉ chạy 13.976 lần (một lần nữa, từ tổng số module_end sự kiện) và thời gian CPU cho sql_statement_completed sự kiện là 78 mili giây với thời lượng 359 mili giây.

Tôi thấy điều này thú vị nên để xác minh số lần thực thi, tôi đã chạy truy vấn sau để đếm KHÔNG ĐỦ hàng giá trị, hàng giá trị NULL và tổng số hàng trong Sales.SalesOrderHeader bảng.
SELECT SUM(CASE WHEN CurrencyRateID IS NOT NULL THEN 1 ELSE 0 END) AS NOTNULL, SUM(CASE WHEN CurrencyRateID IS NULL THEN 1 ELSE 0 END) AS NULLVALUE, COUNT(*) FROM Sales.SalesOrderHeader;
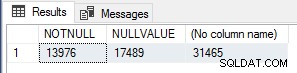
Những con số này tương ứng chính xác với số module_end sự kiện cho mỗi bài kiểm tra, vì vậy đây chắc chắn là một tối ưu hóa hiệu suất rất đơn giản cho các UDF vô hướng sẽ được sử dụng nếu bạn biết rằng kết quả của hàm sẽ là NULL nếu giá trị đầu vào là NULL, để thực hiện ngắn mạch / bỏ qua hàm hoàn toàn cho các hàng đó.
Thông tin QueryTimeStats trong Kế hoạch thực thi thực tế cũng phản ánh mức tăng hiệu suất:
<QueryTimeStats CpuTime="204" ElapsedTime="482" UdfCpuTime="160" UdfElapsedTime="218" /> <QueryTimeStats CpuTime="78" ElapsedTime="359" UdfCpuTime="52" UdfElapsedTime="64" />
Chỉ riêng điều này đã làm giảm đáng kể thời gian của CPU, có thể là một điểm khó khăn đáng kể đối với một số hệ thống.
Việc sử dụng các UDF vô hướng là một thiết kế chống lại hiệu suất nổi tiếng và có nhiều phương pháp để viết lại mã để tránh việc sử dụng chúng và ảnh hưởng đến hiệu suất. Nhưng nếu chúng đã ở đúng vị trí và không thể dễ dàng thay đổi hoặc loại bỏ, chỉ cần tạo lại UDF với RETURNS NULL ON NULL INPUT tùy chọn có thể là một cách rất đơn giản để nâng cao hiệu suất nếu có nhiều đầu vào NULL trên tập dữ liệu nơi UDF được sử dụng.