Karen Ly, nhà phân tích thu nhập cố định của Jr. tại RBC, đã đưa ra cho tôi một thử thách T-SQL liên quan đến việc tìm kiếm kết quả phù hợp nhất, trái ngược với việc tìm kiếm một kết quả phù hợp chính xác. Trong bài viết này, tôi đề cập đến một dạng thử thách tổng quát, đơn giản.
Thử thách
Thử thách liên quan đến việc kết hợp các hàng từ hai bảng, T1 và T2. Sử dụng mã sau để tạo một cơ sở dữ liệu mẫu có tên là testdb và bên trong đó là các bảng T1 và T2:
SET NOCOUNT ON;
IF DB_ID('testdb') IS NULL
CREATE DATABASE testdb;
GO
USE testdb;
DROP TABLE IF EXISTS dbo.T1, dbo.T2;
CREATE TABLE dbo.T1
(
keycol INT NOT NULL IDENTITY
CONSTRAINT PK_T1 PRIMARY KEY,
val INT NOT NULL,
othercols BINARY(100) NOT NULL
CONSTRAINT DFT_T1_col1 DEFAULT(0xAA)
);
CREATE TABLE dbo.T2
(
keycol INT NOT NULL IDENTITY
CONSTRAINT PK_T2 PRIMARY KEY,
val INT NOT NULL,
othercols BINARY(100) NOT NULL
CONSTRAINT DFT_T2_col1 DEFAULT(0xBB)
); Như bạn thấy, cả T1 và T2 đều có một cột số (kiểu INT trong ví dụ này) được gọi là val. Thách thức là đối sánh với từng hàng từ T1 với hàng từ T2 nơi chênh lệch tuyệt đối giữa T2.val và T1.val là thấp nhất. Trong trường hợp quan hệ (nhiều hàng khớp trong T2), hãy khớp hàng trên cùng dựa trên thứ tự tăng dần val, keycol. Đó là, hàng có giá trị thấp nhất trong cột val và nếu bạn vẫn còn quan hệ, thì hàng có giá trị móc khóa thấp nhất. Công cụ buộc dây được sử dụng để đảm bảo tính xác định.
Sử dụng mã sau để điền vào T1 và T2 với các tập hợp nhỏ dữ liệu mẫu để có thể kiểm tra tính đúng đắn của các giải pháp của bạn:
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 (val)
VALUES(1),(1),(3),(3),(5),(8),(13),(16),(18),(20),(21);
INSERT INTO dbo.T2 (val)
VALUES(2),(2),(7),(3),(3),(11),(11),(13),(17),(19); Kiểm tra nội dung của T1:
SELECT keycol, val, SUBSTRING(othercols, 1, 1) AS othercols FROM dbo.T1 ORDER BY val, keycol;
Mã này tạo ra kết quả sau:
keycol val othercols ----------- ----------- --------- 1 1 0xAA 2 1 0xAA 3 3 0xAA 4 3 0xAA 5 5 0xAA 6 8 0xAA 7 13 0xAA 8 16 0xAA 9 18 0xAA 10 20 0xAA 11 21 0xAA
Kiểm tra nội dung của T2:
SELECT keycol, val, SUBSTRING(othercols, 1, 1) AS othercols FROM dbo.T2 ORDER BY val, keycol;
Mã này tạo ra kết quả sau:
keycol val othercols ----------- ----------- --------- 1 2 0xBB 2 2 0xBB 4 3 0xBB 5 3 0xBB 3 7 0xBB 6 11 0xBB 7 11 0xBB 8 13 0xBB 9 17 0xBB 10 19 0xBB
Đây là kết quả mong muốn cho dữ liệu mẫu đã cho:
keycol1 val1 othercols1 keycol2 val2 othercols2 ----------- ----------- ---------- ----------- ----------- ---------- 1 1 0xAA 1 2 0xBB 2 1 0xAA 1 2 0xBB 3 3 0xAA 4 3 0xBB 4 3 0xAA 4 3 0xBB 5 5 0xAA 4 3 0xBB 6 8 0xAA 3 7 0xBB 7 13 0xAA 8 13 0xBB 8 16 0xAA 9 17 0xBB 9 18 0xAA 9 17 0xBB 10 20 0xAA 10 19 0xBB 11 21 0xAA 10 19 0xBB
Trước khi bạn bắt đầu thực hiện thử thách, hãy kiểm tra kết quả mong muốn và đảm bảo rằng bạn hiểu logic đối sánh, bao gồm cả logic kết hợp. Ví dụ:hãy xem xét hàng trong T1 trong đó keycol là 5 và val là 5. Hàng này có nhiều kết quả phù hợp nhất trong T2:
keycol val othercols ----------- ----------- --------- 4 3 0xBB 5 3 0xBB 3 7 0xBB
Trong tất cả các hàng này, sự khác biệt tuyệt đối giữa T2.val và T1.val (5) là 2. Sử dụng logic bẻ khóa dựa trên thứ tự val tăng dần, keycol tăng dần hàng trên cùng ở đây là hàng trong đó val là 3 và keycol là 4.
Bạn sẽ sử dụng các bộ dữ liệu mẫu nhỏ để kiểm tra tính hợp lệ của các giải pháp của mình. Để kiểm tra hiệu suất, bạn cần các bộ lớn hơn. Sử dụng mã sau để tạo một hàm trợ giúp được gọi là GetNums, hàm này tạo ra một chuỗi các số nguyên trong một phạm vi được yêu cầu:
DROP FUNCTION IF EXISTS dbo.GetNums;
GO
CREATE OR ALTER FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO Sử dụng mã sau để điền vào T1 và T2 với các bộ dữ liệu mẫu lớn:
DECLARE
@numrowsT1 AS INT = 1000000,
@maxvalT1 AS INT = 10000000,
@numrowsT2 AS INT = 1000000,
@maxvalT2 AS INT = 10000000;
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT1 + 1 AS val
FROM dbo.GetNums(1, @numrowsT1) AS Nums;
INSERT INTO dbo.T2 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT2 + 1 AS val
FROM dbo.GetNums(1, @numrowsT2) AS Nums; Các biến @ numrowsT1 và @ numrowsT2 kiểm soát số hàng mà bạn muốn các bảng được điền vào. Các biến @ maxvalT1 và @ maxvalT2 kiểm soát phạm vi giá trị khác biệt trong cột val và do đó ảnh hưởng đến mật độ của cột. Đoạn mã trên điền vào các bảng với 1.000.000 hàng mỗi bảng và sử dụng phạm vi từ 1 - 10.000.000 cho cột val trong cả hai bảng. Điều này dẫn đến mật độ trong cột thấp (số lượng lớn các giá trị khác biệt, với số lượng trùng lặp nhỏ). Việc sử dụng các giá trị tối đa thấp hơn sẽ dẫn đến mật độ cao hơn (số lượng các giá trị riêng biệt nhỏ hơn và do đó có nhiều bản sao hơn).
Giải pháp 1, sử dụng một truy vấn con HÀNG ĐẦU
Giải pháp đơn giản và rõ ràng nhất có lẽ là giải pháp truy vấn T1 và sử dụng toán tử ÁP DỤNG CHÉO áp dụng truy vấn với bộ lọc TOP (1), sắp xếp các hàng bằng sự khác biệt tuyệt đối giữa T1.val và T2.val, sử dụng T2.val , T2.keycol là người kết thúc. Đây là mã của giải pháp:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) T2.*
FROM dbo.T2
ORDER BY ABS(T2.val - T1.val), T2.val, T2.keycol ) AS A; Hãy nhớ rằng có 1.000.000 hàng trong mỗi bảng. Và mật độ của cột val là thấp trong cả hai bảng. Rất tiếc, vì không có vị từ lọc nào trong truy vấn được áp dụng và thứ tự liên quan đến một biểu thức thao tác các cột, nên ở đây không có khả năng tạo các chỉ mục hỗ trợ. Truy vấn này tạo ra kế hoạch trong Hình 1.
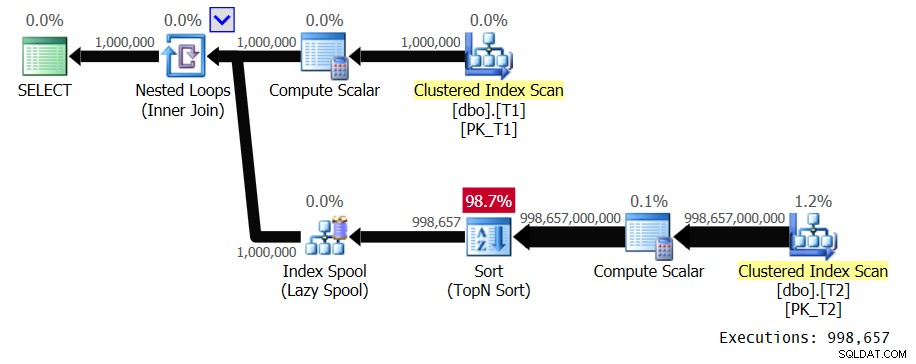 Hình 1:Kế hoạch cho Giải pháp 1
Hình 1:Kế hoạch cho Giải pháp 1
Đầu vào bên ngoài của vòng lặp quét 1.000.000 hàng từ T1. Đầu vào bên trong của vòng lặp thực hiện quét toàn bộ T2 và sắp xếp TopN cho mỗi giá trị T1.val riêng biệt. Trong kế hoạch của chúng tôi, điều này xảy ra 998.657 lần vì chúng tôi có mật độ rất thấp. Nó đặt các hàng trong một ống chỉ mục, được khóa bởi T1.val, để nó có thể sử dụng lại những hàng đó cho những lần xuất hiện trùng lặp của giá trị T1.val, nhưng chúng tôi có rất ít bản sao. Kế hoạch này có độ phức tạp bậc hai. Giữa tất cả các lần thực thi dự kiến của nhánh bên trong của vòng lặp, nó dự kiến sẽ xử lý gần một nghìn tỷ hàng. Khi nói về số lượng lớn hàng để truy vấn xử lý, khi bạn bắt đầu đề cập đến hàng tỷ hàng, mọi người đã biết bạn đang xử lý một truy vấn đắt tiền. Thông thường, mọi người không thốt ra những thuật ngữ như nghìn tỷ, trừ khi họ đang thảo luận về khoản nợ quốc gia của Hoa Kỳ hoặc sự sụp đổ của thị trường chứng khoán. Bạn thường không xử lý những con số như vậy trong ngữ cảnh xử lý truy vấn. Nhưng các kế hoạch có độ phức tạp bậc hai có thể nhanh chóng kết thúc với những con số như vậy. Chạy truy vấn trong SSMS có bật Bao gồm thống kê truy vấn trực tiếp mất 39,6 giây để xử lý chỉ 100 hàng từ T1 trên máy tính xách tay của tôi. Điều này có nghĩa là truy vấn này sẽ mất khoảng 4,5 ngày để hoàn thành. Câu hỏi đặt ra là bạn có thực sự thích xem các kế hoạch truy vấn trực tiếp không? Có thể là một kỷ lục Guinness thú vị để thử và thiết lập.
Giải pháp 2, sử dụng hai truy vấn con HÀNG ĐẦU
Giả sử bạn đang tìm kiếm một giải pháp mất vài giây chứ không phải vài ngày để hoàn thành, thì đây là một ý tưởng. Trong biểu thức bảng được áp dụng, hãy hợp nhất hai truy vấn TOP (1) bên trong — một truy vấn lọc một hàng trong đó T2.val
Dưới đây là các chỉ mục được đề xuất để hỗ trợ giải pháp này:
CREATE INDEX idx_val_key ON dbo.T1(val, keycol) INCLUDE(othercols); CREATE INDEX idx_val_key ON dbo.T2(val, keycol) INCLUDE(othercols); CREATE INDEX idx_valD_key ON dbo.T2(val DESC, keycol) INCLUDE(othercols);
Đây là mã giải pháp hoàn chỉnh:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A; Hãy nhớ rằng chúng ta có 1.000.000 hàng trong mỗi bảng, với cột val có các giá trị trong phạm vi 1 - 10.000.000 (mật độ thấp) và các chỉ mục tối ưu tại chỗ.
Kế hoạch cho truy vấn này được thể hiện trong Hình 2.
Hình 2:Kế hoạch cho Giải pháp 2
Quan sát việc sử dụng tối ưu các chỉ số trên T2, dẫn đến một kế hoạch với tỷ lệ tuyến tính. Kế hoạch này sử dụng một ống chỉ mục theo cách giống như kế hoạch trước đó đã làm, tức là, để tránh lặp lại công việc trong nhánh bên trong của vòng lặp đối với các giá trị T1.val trùng lặp. Dưới đây là thống kê hiệu suất mà tôi nhận được để thực hiện truy vấn này trên hệ thống của mình:
Elapsed: 27.7 sec, CPU: 27.6 sec, logical reads: 17,304,674
Giải pháp 2, với bộ đệm bị vô hiệu hóa
Bạn không thể không tự hỏi liệu ống chỉ mục có thực sự có lợi ở đây hay không. Vấn đề là để tránh lặp lại công việc cho các giá trị T1.val trùng lặp, nhưng trong tình huống như của chúng tôi, nơi chúng tôi có mật độ rất thấp, có rất ít trùng lặp. Điều này có nghĩa là rất có thể công việc liên quan đến bộ đệm lớn hơn là chỉ lặp lại công việc cho các bản sao. Có một cách đơn giản để xác minh điều này — sử dụng cờ theo dõi 8690, bạn có thể vô hiệu hóa bộ đệm trong kế hoạch, như sau:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A
OPTION(QUERYTRACEON 8690); Tôi nhận được kế hoạch được hiển thị trong Hình 3 cho việc thực thi này:
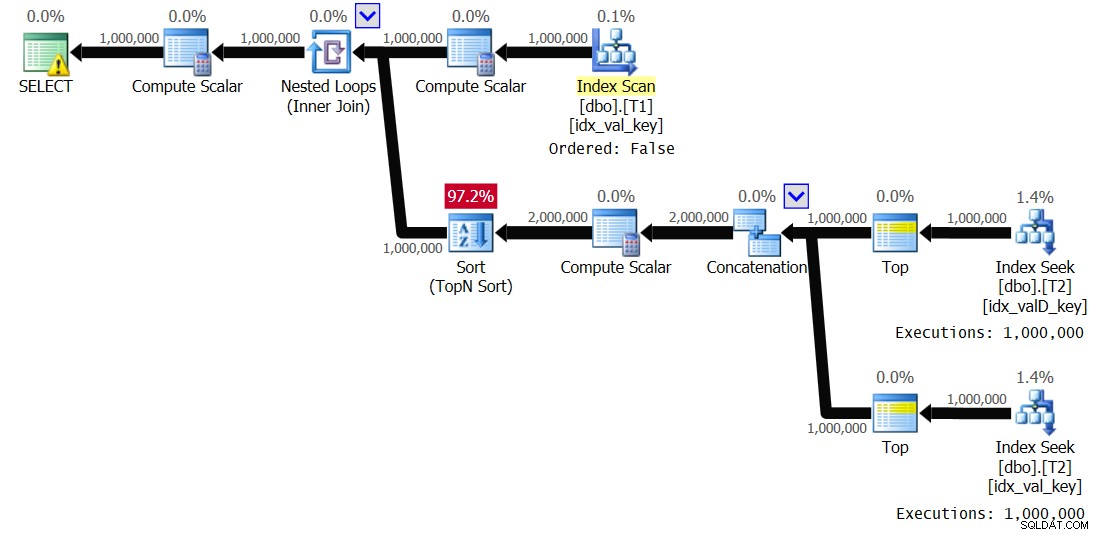 Hình 3:Kế hoạch cho Giải pháp 2, đã tắt bộ đệm
Hình 3:Kế hoạch cho Giải pháp 2, đã tắt bộ đệm
Quan sát rằng ống chỉ mục đã biến mất và lần này nhánh bên trong của vòng lặp được thực thi 1.000.000 lần. Dưới đây là thống kê hiệu suất mà tôi nhận được cho lần thực thi này:
Elapsed: 19.18 sec, CPU: 19.17 sec, logical reads: 6,042,148
Đó là giảm 44% thời gian thực hiện.
Giải pháp 2, với phạm vi giá trị được sửa đổi và lập chỉ mục
Vô hiệu hóa bộ đệm có ý nghĩa rất nhiều khi bạn có mật độ thấp trong các giá trị T1.val; tuy nhiên, việc tạo ống đệm có thể rất có lợi khi bạn có mật độ cao. Ví dụ:chạy mã sau để tạo lại T1 và T2 với cài đặt dữ liệu mẫu @ maxvalT1 và @ maxvalT2 thành 1000 (1.000 giá trị khác biệt tối đa):
DECLARE
@numrowsT1 AS INT = 1000000,
@maxvalT1 AS INT = 1000,
@numrowsT2 AS INT = 1000000,
@maxvalT2 AS INT = 1000;
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT1 + 1 AS val
FROM dbo.GetNums(1, @numrowsT1) AS Nums;
INSERT INTO dbo.T2 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT2 + 1 AS val
FROM dbo.GetNums(1, @numrowsT2) AS Nums; Chạy lại Giải pháp 2, trước tiên không có cờ theo dõi:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A; Kế hoạch cho việc thực hiện này được thể hiện trong Hình 4:
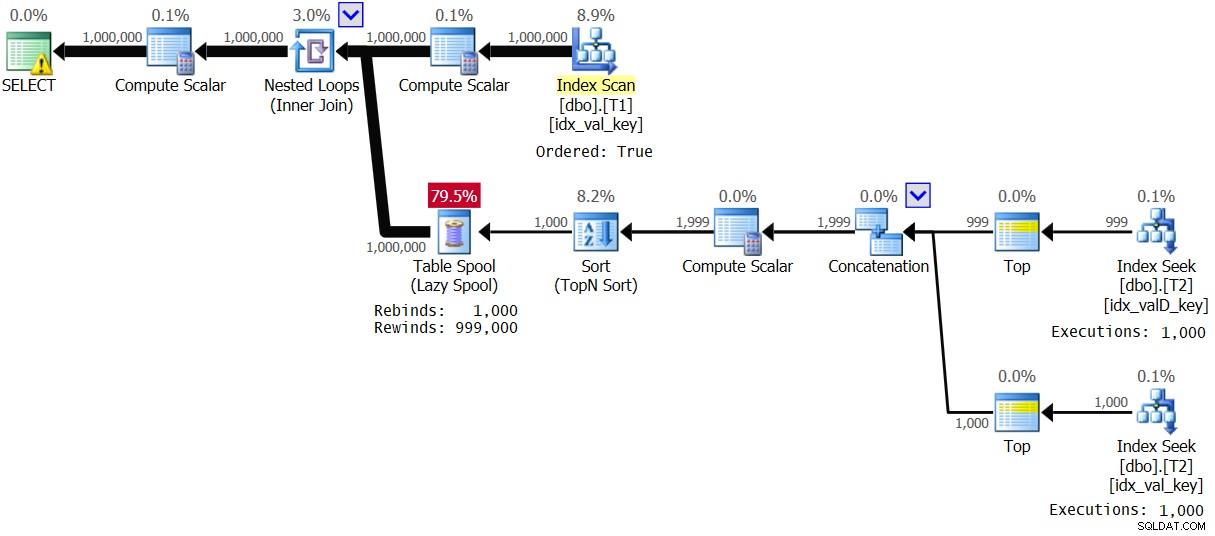 Hình 4:Kế hoạch cho Giải pháp 2, với phạm vi giá trị 1 - 1000
Hình 4:Kế hoạch cho Giải pháp 2, với phạm vi giá trị 1 - 1000
Trình tối ưu hóa đã quyết định sử dụng một kế hoạch khác do mật độ cao trong T1.val. Quan sát rằng chỉ mục trên T1 được quét theo thứ tự chính. Vì vậy, đối với mỗi lần xuất hiện đầu tiên của một giá trị T1.val riêng biệt, nhánh bên trong của vòng lặp sẽ được thực thi và kết quả được lưu trong một cuộn bảng thông thường (rebind). Sau đó, đối với mỗi lần xuất hiện đầu tiên của giá trị, một tua lại được áp dụng. Với 1.000 giá trị khác biệt, nhánh bên trong chỉ được thực hiện 1.000 lần. Điều này dẫn đến thống kê hiệu suất tuyệt vời:
Elapsed: 1.16 sec, CPU: 1.14 sec, logical reads: 23,278
Bây giờ, hãy thử chạy giải pháp với bộ đệm bị vô hiệu hóa:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A
OPTION(QUERYTRACEON 8690); Tôi nhận được kế hoạch được hiển thị trong Hình 5.
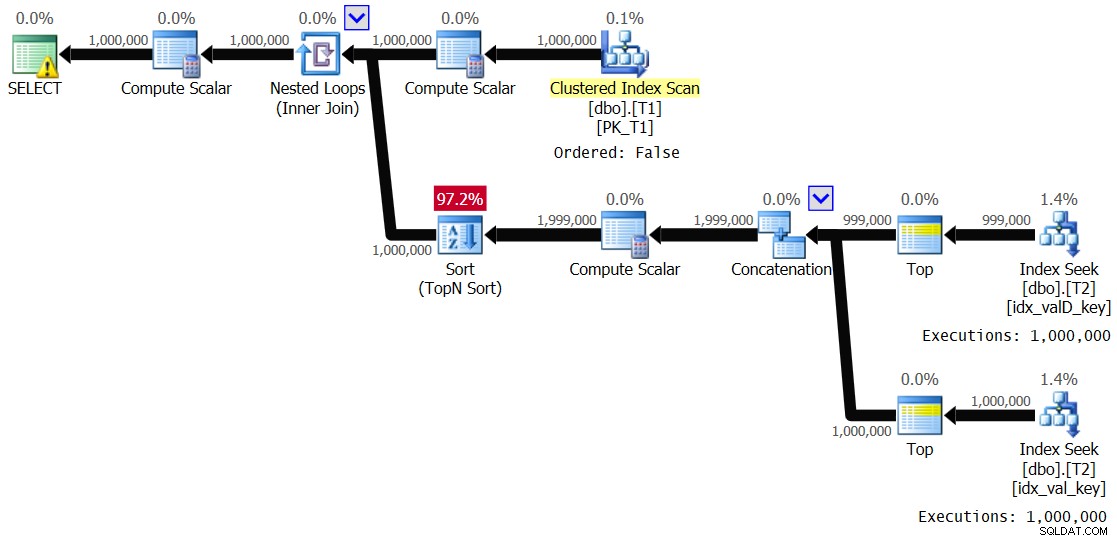 Hình 5:Kế hoạch cho Giải pháp 2, với phạm vi giá trị 1 - 1.000 và bộ đệm bị tắt
Hình 5:Kế hoạch cho Giải pháp 2, với phạm vi giá trị 1 - 1.000 và bộ đệm bị tắt
Về cơ bản, nó giống với kế hoạch được hiển thị trước đó trong Hình 3. Nhánh bên trong của vòng lặp được thực hiện 1.000.000 lần. Dưới đây là thống kê hiệu suất mà tôi nhận được cho lần thực thi này:
Elapsed: 24.5 sec, CPU: 24.2 sec, logical reads: 8,012,548
Rõ ràng, bạn muốn cẩn thận không vô hiệu hóa bộ đệm khi bạn có mật độ cao trong T1.val.
Cuộc sống tốt đẹp khi hoàn cảnh của bạn đủ đơn giản để bạn có thể tạo ra các chỉ số hỗ trợ. Thực tế là trong một số trường hợp trong thực tế, có đủ logic bổ sung trong truy vấn, điều này loại trừ khả năng tạo các chỉ mục hỗ trợ tối ưu. Trong những trường hợp như vậy, Giải pháp 2 sẽ không hoạt động tốt.
Để chứng minh hiệu suất của Giải pháp 2 mà không có chỉ mục hỗ trợ, hãy tạo lại T1 và T2 trở lại với cài đặt dữ liệu mẫu @ maxvalT1 và @ maxvalT2 thành 10000000 (phạm vi giá trị 1 - 10M), đồng thời xóa các chỉ mục hỗ trợ:
DROP INDEX IF EXISTS idx_val_key ON dbo.T1;
DROP INDEX IF EXISTS idx_val_key ON dbo.T2;
DROP INDEX IF EXISTS idx_valD_key ON dbo.T2;
DECLARE
@numrowsT1 AS INT = 1000000,
@maxvalT1 AS INT = 10000000,
@numrowsT2 AS INT = 1000000,
@maxvalT2 AS INT = 10000000;
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT1 + 1 AS val
FROM dbo.GetNums(1, @numrowsT1) AS Nums;
INSERT INTO dbo.T2 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT2 + 1 AS val
FROM dbo.GetNums(1, @numrowsT2) AS Nums; Chạy lại Giải pháp 2, với Bao gồm Thống kê Truy vấn Trực tiếp được bật trong SSMS:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A; Tôi nhận được kế hoạch được hiển thị trong Hình 6 cho truy vấn này:
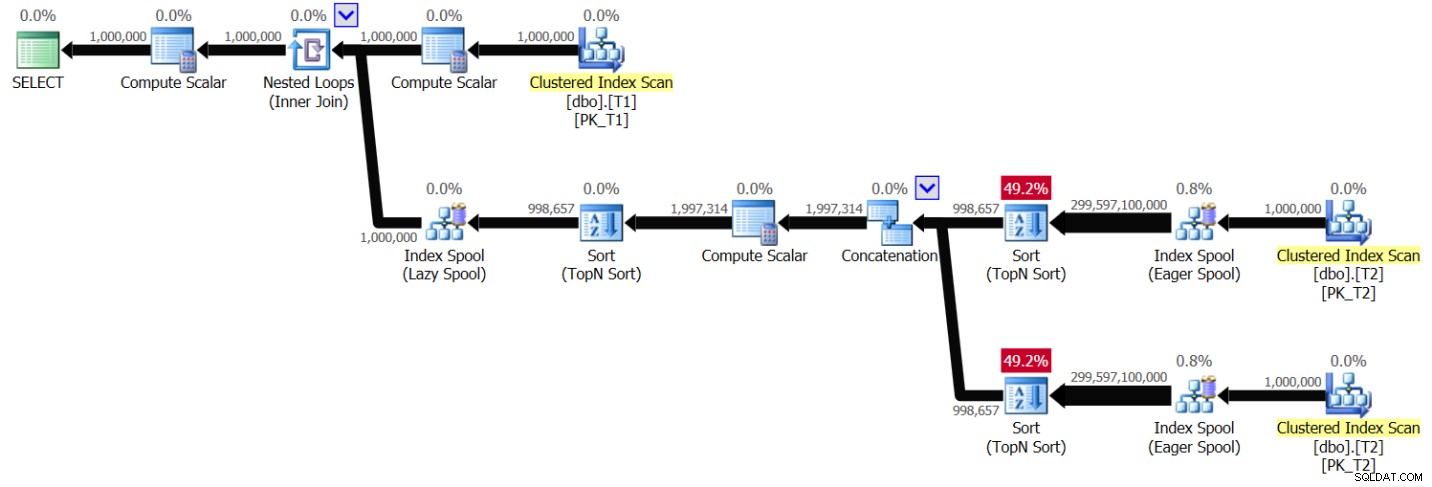 Hình 6:Kế hoạch cho Giải pháp 2, không lập chỉ mục, với phạm vi giá trị 1 - 1.000.000
Hình 6:Kế hoạch cho Giải pháp 2, không lập chỉ mục, với phạm vi giá trị 1 - 1.000.000
Bạn có thể thấy một mẫu rất giống với mẫu được hiển thị trước đó trong Hình 1, chỉ khác là lần này kế hoạch quét T2 hai lần cho mỗi giá trị T1.val riêng biệt. Một lần nữa, độ phức tạp của kế hoạch tăng lên bậc hai. Chạy truy vấn trong SSMS có bật Bao gồm thống kê truy vấn trực tiếp mất 49,6 giây để xử lý 100 hàng từ T1 trên máy tính xách tay của tôi, có nghĩa là truy vấn này sẽ mất khoảng 5,7 ngày để hoàn thành. Tất nhiên, điều này có thể có nghĩa là tin tốt nếu bạn đang cố gắng phá kỷ lục Guinness thế giới về việc xem một cách say sưa một kế hoạch truy vấn trực tiếp.
Kết luận
Tôi muốn cảm ơn Karen Ly từ RBC đã giới thiệu cho tôi thử thách đối đầu thú vị nhất này. Tôi khá ấn tượng với mã của cô ấy để xử lý nó, bao gồm rất nhiều logic bổ sung dành riêng cho hệ thống của cô ấy. Trong bài viết này, tôi đã chỉ ra các giải pháp hoạt động hợp lý khi bạn có thể tạo các chỉ mục hỗ trợ tối ưu. Nhưng như bạn có thể thấy, trong trường hợp đây không phải là một tùy chọn, rõ ràng là thời gian thực thi mà bạn nhận được là rất cao. Bạn có thể nghĩ ra các giải pháp sẽ hoạt động tốt ngay cả khi không có các chỉ số hỗ trợ tối ưu không? Còn tiếp…