Khi SQL Server tối ưu hóa một truy vấn, trong giai đoạn thăm dò, nó tạo ra các kế hoạch ứng viên và chọn trong số đó kế hoạch có chi phí thấp nhất. Kế hoạch đã chọn được cho là có thời gian chạy thấp nhất trong số các kế hoạch đã khám phá. Vấn đề là, trình tối ưu hóa chỉ có thể chọn giữa các chiến lược đã được mã hóa vào nó. Ví dụ:khi tối ưu hóa nhóm và tổng hợp, vào ngày viết bài này, trình tối ưu hóa chỉ có thể chọn giữa các chiến lược Tổng hợp luồng và Tổng hợp băm. Tôi đã trình bày các chiến lược có sẵn trong các phần trước của loạt bài này. Trong Phần 1, tôi đã đề cập đến chiến lược Tổng hợp Luồng được sắp xếp trước, trong Phần 2 là chiến lược Sắp xếp + Tổng hợp Luồng, trong Phần 3 là chiến lược Tổng hợp Băm và trong Phần 4 các cân nhắc về tính song song.
Những gì trình tối ưu hóa SQL Server hiện không hỗ trợ là tùy chỉnh và trí tuệ nhân tạo. Nghĩa là, nếu bạn có thể tìm ra chiến lược mà trong những điều kiện nhất định là tối ưu hơn những điều kiện mà trình tối ưu hóa hỗ trợ, bạn không thể nâng cao trình tối ưu hóa để hỗ trợ nó và trình tối ưu hóa không thể học cách sử dụng nó. Tuy nhiên, những gì bạn có thể làm là viết lại truy vấn bằng cách sử dụng các phần tử truy vấn thay thế có thể được tối ưu hóa với chiến lược mà bạn có trong đầu. Trong phần thứ năm và phần cuối cùng của loạt bài này, tôi trình bày kỹ thuật điều chỉnh truy vấn này bằng cách sử dụng các bản sửa đổi truy vấn.
Xin chân thành cảm ơn Paul White (@SQL_Kiwi) đã giúp thực hiện một số tính toán chi phí được trình bày trong bài viết này!
Giống như các phần trước của loạt bài này, tôi sẽ sử dụng cơ sở dữ liệu mẫu PerformanceV3. Sử dụng mã sau để loại bỏ các chỉ mục không cần thiết khỏi bảng Đơn hàng:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Chiến lược tối ưu hóa mặc định
Hãy xem xét các nhiệm vụ nhóm và tổng hợp cơ bản sau:
Trả lại ngày đặt hàng tối đa cho từng người gửi hàng, nhân viên và khách hàng.
Để có hiệu suất tối ưu, bạn tạo các chỉ mục hỗ trợ sau:
CREATE INDEX idx_sid_od ON dbo.Orders(shipperid, orderdate); CREATE INDEX idx_eid_od ON dbo.Orders(empid, orderdate); CREATE INDEX idx_cid_od ON dbo.Orders(custid, orderdate);
Sau đây là ba truy vấn bạn sẽ sử dụng để xử lý các tác vụ này, cùng với chi phí cây con ước tính, cũng như thống kê I / O, CPU và thời gian đã trôi qua:
-- Query 1 -- Estimated Subtree Cost: 3.5344 -- logical reads: 2484, CPU time: 281 ms, elapsed time: 279 ms SELECT shipperid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY shipperid; -- Query 2 -- Estimated Subtree Cost: 3.62798 -- logical reads: 2610, CPU time: 250 ms, elapsed time: 283 ms SELECT empid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY empid; -- Query 3 -- Estimated Subtree Cost: 4.27624 -- logical reads: 3479, CPU time: 406 ms, elapsed time: 506 ms SELECT custid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY custid;
Hình 1 cho thấy các kế hoạch cho các truy vấn này:
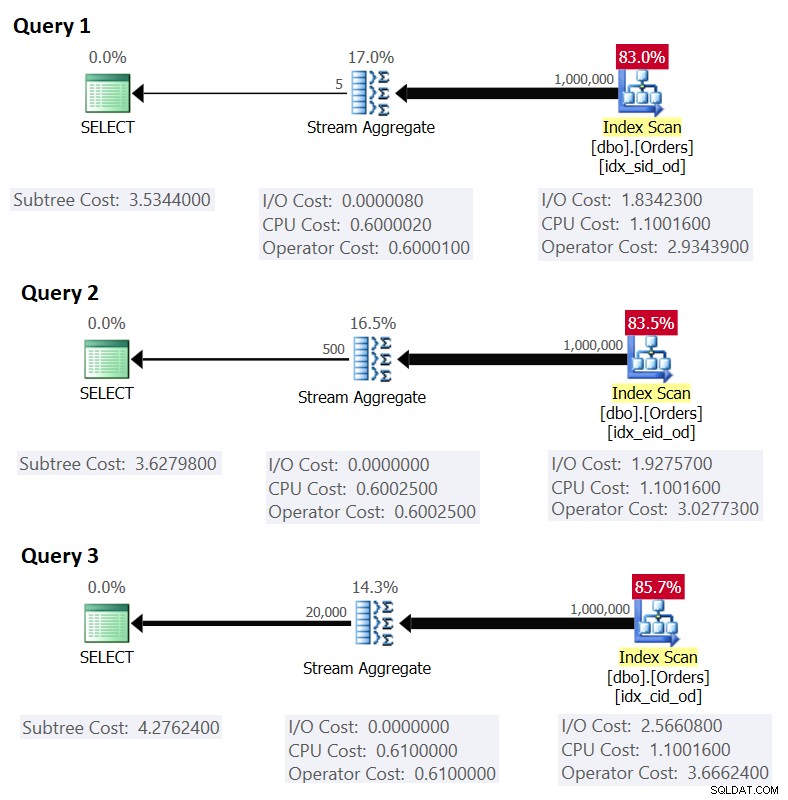 Hình 1:Kế hoạch cho các truy vấn được nhóm
Hình 1:Kế hoạch cho các truy vấn được nhóm
Nhớ lại rằng nếu bạn có chỉ mục bao hàm tại chỗ, với nhóm tập hợp cột làm cột chính hàng đầu, theo sau là cột tổng hợp, SQL Server có khả năng chọn một kế hoạch thực hiện quét theo thứ tự chỉ mục bao phủ hỗ trợ chiến lược Tổng hợp dòng . Như được thể hiện rõ trong các kế hoạch trong Hình 1, người điều hành Index Scan chịu trách nhiệm về phần lớn chi phí của kế hoạch, và trong đó phần I / O là phần nổi bật nhất.
Trước khi tôi trình bày một chiến lược thay thế và giải thích các trường hợp mà chiến lược đó tối ưu hơn chiến lược mặc định, hãy đánh giá chi phí của chiến lược hiện tại. Vì phần I / O chiếm ưu thế nhất trong việc xác định chi phí kế hoạch của chiến lược mặc định này, trước tiên, chúng ta hãy ước tính số lượt đọc trang hợp lý sẽ được yêu cầu. Sau đó, chúng tôi cũng sẽ ước tính chi phí kế hoạch.
Để ước tính số lần đọc logic mà toán tử Quét chỉ mục sẽ yêu cầu, bạn cần biết bạn có bao nhiêu hàng trong bảng và bao nhiêu hàng phù hợp trong một trang dựa trên kích thước hàng. Khi bạn có hai toán hạng này, công thức của bạn cho số trang cần thiết trong cấp độ lá của chỉ mục sau đó là TRẦN (1e0 * @numrows / @rowsperpage). Nếu tất cả những gì bạn có chỉ là cấu trúc bảng và không có dữ liệu mẫu hiện có nào để làm việc, bạn có thể sử dụng bài viết này để ước tính số trang bạn sẽ có trong cấp độ lá của chỉ mục hỗ trợ. Nếu bạn có dữ liệu mẫu đại diện tốt, ngay cả khi không ở cùng quy mô như trong môi trường sản xuất, bạn có thể tính số hàng trung bình vừa với một trang bằng cách truy vấn danh mục và các đối tượng quản lý động, như sau:
SELECT I.name, row_count, in_row_data_page_count,
CAST(ROUND(1e0 * row_count / in_row_data_page_count, 0) AS INT) AS avgrowsperpage
FROM sys.indexes AS I
INNER JOIN sys.dm_db_partition_stats AS P
ON I.object_id = P.object_id
AND I.index_id = P.index_id
WHERE I.object_id = OBJECT_ID('dbo.Orders')
AND I.name IN ('idx_sid_od', 'idx_eid_od', 'idx_cid_od'); Truy vấn này tạo ra kết quả sau trong cơ sở dữ liệu mẫu của chúng tôi:
name row_count in_row_data_page_count avgrowsperpage ----------- ---------- ---------------------- --------------- idx_sid_od 1000000 2473 404 idx_eid_od 1000000 2599 385 idx_cid_od 1000000 3461 289
Bây giờ bạn đã có số hàng vừa với một trang lá của chỉ mục, bạn có thể ước tính tổng số trang lá trong chỉ mục dựa trên số hàng mà bạn mong đợi bảng sản xuất của mình có. Đây cũng sẽ là số lần đọc logic dự kiến được áp dụng bởi toán tử Quét chỉ mục. Trên thực tế, số lần đọc có thể diễn ra nhiều hơn chỉ là số trang ở cấp độ lá của chỉ mục, chẳng hạn như số lần đọc bổ sung được tạo ra bởi cơ chế đọc trước, nhưng tôi sẽ bỏ qua chúng để giữ cho cuộc thảo luận của chúng ta trở nên đơn giản. .
Ví dụ:số lần đọc lôgic ước tính cho Truy vấn 1 đối với số hàng dự kiến là TRẦN (1e0 * @numorws / 404). Với 1.000.000 hàng, số lần đọc lôgic dự kiến là 2476. Sự khác biệt giữa 2476 và số trang được báo cáo trong hàng là 2473 có thể là do làm tròn số mà tôi đã làm khi tính số hàng trung bình trên mỗi trang.
Đối với chi phí gói, tôi đã giải thích cách thiết kế ngược chi phí của nhà điều hành Tổng hợp luồng trong Phần 1 của loạt bài này. Theo cách tương tự, bạn có thể thiết kế ngược chi phí của toán tử Quét chỉ mục. Chi phí kế hoạch sau đó là tổng chi phí của các nhà khai thác Quét chỉ mục và Tổng hợp luồng.
Để tính toán chi phí của toán tử Quét chỉ mục, bạn muốn bắt đầu với kỹ thuật đảo ngược một số hằng số mô hình chi phí quan trọng:
@randomio = 0.003125 -- Random I/O cost @seqio = 0.000740740740741 -- Sequential I/O cost @cpubase = 0.000157 -- CPU base cost @cpurow = 0.0000011 -- CPU cost per row
Với các hằng số của mô hình chi phí đã được tìm ra ở trên, bạn có thể tiến hành thiết kế ngược lại các công thức cho chi phí I / O, chi phí CPU và tổng chi phí vận hành cho toán tử Quét chỉ mục:
I/O cost: @randomio + (@numpages - 1e0) * @seqio = 0.003125 + (@numpages - 1e0) * 0.000740740740741 CPU cost: @cpubase + @numrows * @cpurow = 0.000157 + @numrows * 0.0000011 Operator cost: 0.002541259259259 + @numpages * 0.000740740740741 + @numrows * 0.0000011
Ví dụ:chi phí toán tử Quét chỉ mục cho Truy vấn 1, với 2473 trang và 1.000.000 hàng, là:
0.002541259259259 + 2473 * 0.000740740740741 + 1000000 * 0.0000011 = 2.93439
Sau đây là công thức được thiết kế ngược cho chi phí điều hành Tổng hợp Luồng:
0.000008 + @numrows * 0.0000006 + @numgroups * 0.0000005
Ví dụ:đối với Truy vấn 1, chúng tôi có 1.000.000 hàng và 5 nhóm, do đó chi phí ước tính là 0,6000105.
Kết hợp chi phí của hai nhà khai thác, đây là công thức cho toàn bộ chi phí gói:
0.002549259259259 + @numpages * 0.000740740740741 + @numrows * 0.0000017 + @numgroups * 0.0000005
Đối với Truy vấn 1, với 2473 trang, 1.000.000 hàng và 5 nhóm, bạn nhận được:
0.002549259259259 + 2473 * 0.000740740740741 + 1000000 * 0.0000017 + 5 * 0.0000005 = 3.5344
Điều này phù hợp với những gì Hình 1 cho thấy là chi phí ước tính cho Truy vấn 1.
Nếu bạn dựa vào số hàng ước tính trên mỗi trang, công thức của bạn sẽ là:
0.002549259259259 + CEILING(1e0 * @numrows / @rowsperpage) * 0.000740740740741 + @numrows * 0.0000017 + @numgroups * 0.0000005
Ví dụ:đối với Truy vấn 1, với 1.000.000 hàng, 404 hàng trên mỗi trang và 5 nhóm, chi phí ước tính là:
0.002549259259259 + CEILING(1e0 * 1000000 / 404) * 0.000740740740741 + 1000000 * 0.0000017 + 5 * 0.0000005 = 3.5366
Như một bài tập, bạn có thể áp dụng các con số cho Truy vấn 2 (1.000.000 hàng, 385 hàng trên trang, 500 nhóm) và Truy vấn 3 (1.000.000 hàng, 289 hàng trên trang, 20.000 nhóm) trong công thức của chúng tôi và xem kết quả phù hợp với những gì Hình 1 cho thấy.
Điều chỉnh truy vấn với ghi lại truy vấn
Chiến lược Tổng hợp luồng được sắp xếp trước mặc định để tính toán tổng MIN / MAX cho mỗi nhóm dựa trên quá trình quét theo thứ tự của chỉ mục bao phủ hỗ trợ (hoặc một số hoạt động sơ bộ khác tạo ra các hàng được sắp xếp theo thứ tự). Một chiến lược thay thế, với một chỉ mục bao trùm hỗ trợ hiện tại, sẽ là thực hiện tìm kiếm chỉ mục cho mỗi nhóm. Dưới đây là mô tả về một kế hoạch giả dựa trên một chiến lược như vậy cho một truy vấn nhóm theo grpcol và áp dụng MAX (aggcol):
set @curgrpcol = grpcol from first row obtained by a scan of the index, ordered forward;
while end of index not reached
begin
set @curagg = aggcol from row obtained by a seek to the last point
where grpcol = @curgrpcol, ordered backward;
emit row (@curgrpcol, @curagg);
set @curgrpcol = grpcol from row to the right of last row for current group;
end; Nếu bạn nghĩ về nó, chiến lược dựa trên quét mặc định là tối ưu khi tập hợp nhóm có mật độ thấp (số lượng nhóm lớn, với số lượng hàng trên mỗi nhóm ở mức trung bình). Chiến lược dựa trên tìm kiếm là tối ưu khi tập hợp nhóm có mật độ cao (số lượng nhóm nhỏ, với số lượng lớn hàng trên mỗi nhóm ở mức trung bình). Hình 2 minh họa cả hai chiến lược cho thấy khi nào mỗi chiến lược là tối ưu.
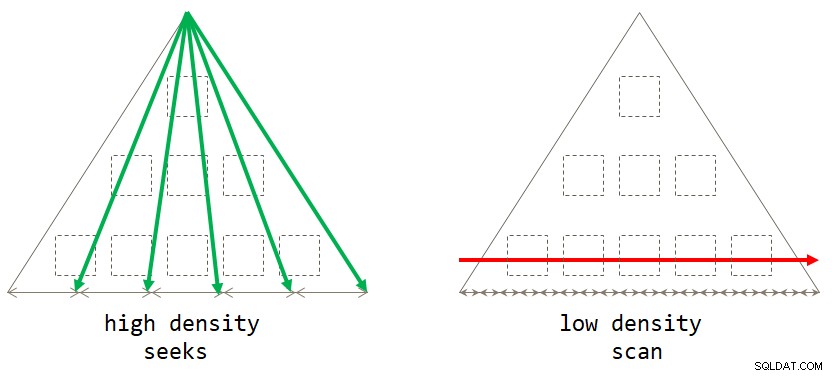 Hình 2:Chiến lược tối ưu dựa trên mật độ thiết lập nhóm
Hình 2:Chiến lược tối ưu dựa trên mật độ thiết lập nhóm
Miễn là bạn viết giải pháp dưới dạng truy vấn được nhóm lại, thì hiện tại SQL Server sẽ chỉ xem xét chiến lược quét. Điều này sẽ hoạt động tốt cho bạn khi tập hợp nhóm có mật độ thấp. Khi bạn có mật độ cao, để có được chiến lược tìm kiếm, bạn sẽ cần áp dụng ghi lại truy vấn. Một cách để đạt được điều này là truy vấn bảng chứa các nhóm và sử dụng truy vấn con tổng hợp vô hướng đối với bảng chính để lấy tổng hợp. Ví dụ:để tính ngày đặt hàng tối đa cho mỗi người gửi hàng, bạn sẽ sử dụng mã sau:
SELECT shipperid,
( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid
ORDER BY O.orderdate DESC ) AS maxod
FROM dbo.Shippers AS S; Các nguyên tắc lập chỉ mục cho bảng chính cũng giống như các nguyên tắc hỗ trợ chiến lược mặc định. Chúng tôi đã có sẵn các chỉ mục đó cho ba nhiệm vụ nói trên. Bạn cũng có thể muốn có một chỉ mục hỗ trợ trên các cột của nhóm nhóm trong bảng chứa các nhóm để giảm thiểu chi phí I / O so với bảng đó. Sử dụng mã sau để tạo các chỉ mục hỗ trợ như vậy cho ba nhiệm vụ của chúng tôi:
CREATE INDEX idx_sid ON dbo.Shippers(shipperid); CREATE INDEX idx_eid ON dbo.Employees(empid); CREATE INDEX idx_cid ON dbo.Customers(custid);
Tuy nhiên, một vấn đề nhỏ là giải pháp dựa trên truy vấn con không phải là giải pháp tương đương lôgic chính xác của giải pháp dựa trên truy vấn được nhóm. Nếu bạn có một nhóm không có mặt trong bảng chính, nhóm trước sẽ trả về nhóm với NULL làm tổng hợp, trong khi nhóm sau sẽ hoàn toàn không trả về nhóm. Một cách đơn giản để đạt được tương đương logic thực sự với truy vấn được nhóm là gọi truy vấn con bằng cách sử dụng toán tử ÁP DỤNG CROSS trong mệnh đề FROM thay vì sử dụng truy vấn con vô hướng trong mệnh đề SELECT. Hãy nhớ rằng ÁP DỤNG CHÉO sẽ không trả về hàng bên trái nếu truy vấn được áp dụng trả về một tập hợp trống. Dưới đây là ba truy vấn giải pháp thực hiện chiến lược này cho ba nhiệm vụ của chúng tôi, cùng với thống kê hiệu suất của chúng:
-- Query 4
-- Estimated Subtree Cost: 0.0072299
-- logical reads: 2 + 15, CPU time: 0 ms, elapsed time: 43 ms
SELECT S.shipperid, A.orderdate AS maxod
FROM dbo.Shippers AS S
CROSS APPLY ( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid
ORDER BY O.orderdate DESC ) AS A;
-- Query 5
-- Estimated Subtree Cost: 0.089694
-- logical reads: 2 + 1620, CPU time: 0 ms, elapsed time: 148 ms
SELECT E.empid, A.orderdate AS maxod
FROM dbo.Employees AS E
CROSS APPLY ( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.empid = E.empid
ORDER BY O.orderdate DESC ) AS A;
-- Query 6
-- Estimated Subtree Cost: 3.5227
-- logical reads: 45 + 63777, CPU time: 171 ms, elapsed time: 306 ms
SELECT C.custid, A.orderdate AS maxod
FROM dbo.Customers AS C
CROSS APPLY ( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.custid = C.custid
ORDER BY O.orderdate DESC ) AS A; Kế hoạch cho các truy vấn này được thể hiện trong Hình 3.
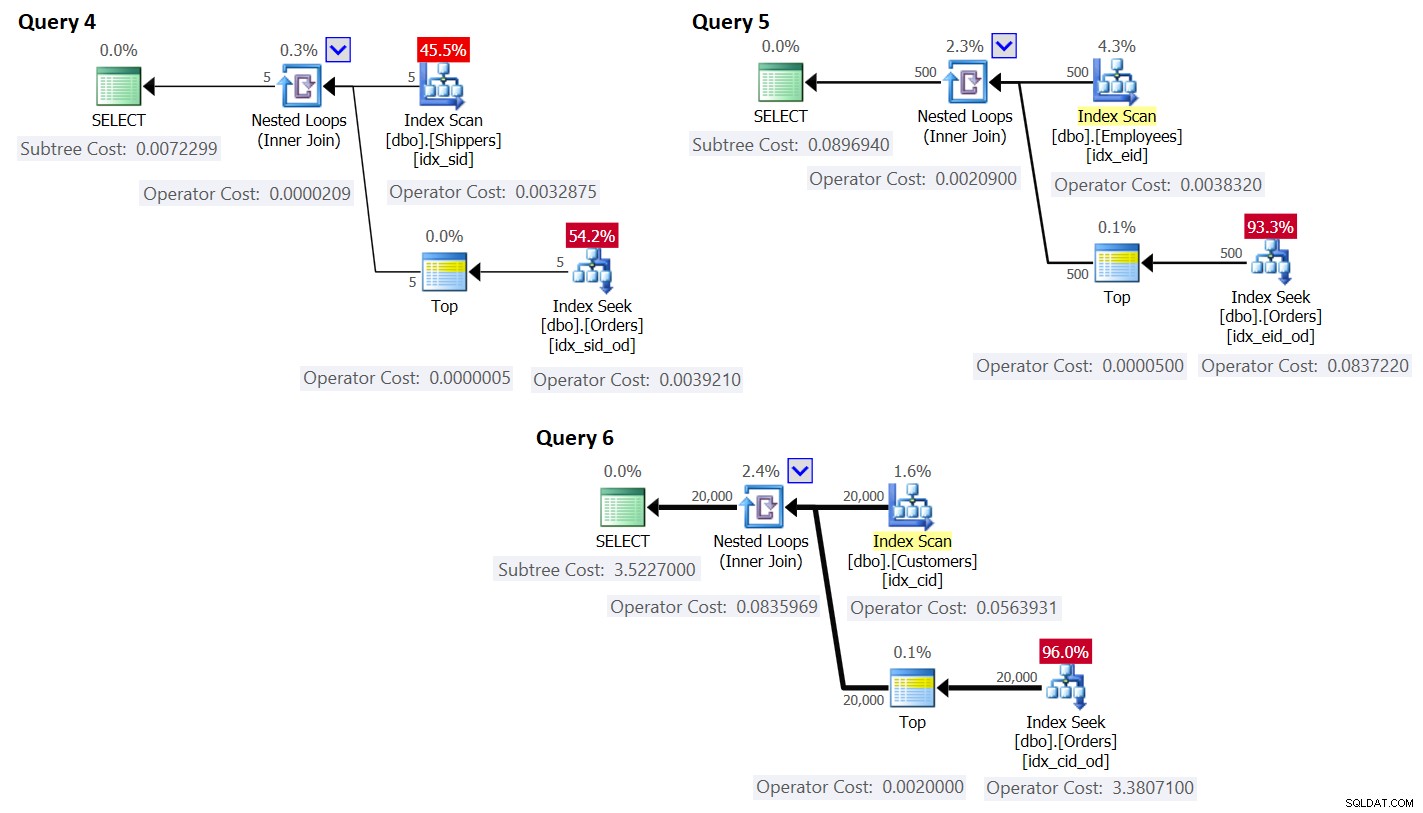 Hình 3:Kế hoạch cho truy vấn có ghi lại
Hình 3:Kế hoạch cho truy vấn có ghi lại
Như bạn có thể thấy, các nhóm được thu thập bằng cách quét chỉ mục trên bảng nhóm và tổng hợp có được bằng cách áp dụng tìm kiếm trong chỉ mục trên bảng chính. Mật độ của tập hợp nhóm càng cao, thì kế hoạch này càng tối ưu hơn so với chiến lược mặc định cho truy vấn được nhóm.
Giống như chúng ta đã làm trước đó đối với chiến lược quét mặc định, hãy ước tính số lần đọc hợp lý và lập kế hoạch chi phí cho chiến lược tìm kiếm. Số lần đọc lôgic ước tính là số lần đọc cho một lần thực thi toán tử Quét chỉ mục truy xuất các nhóm, cộng với số lần đọc cho tất cả các lần thực thi của toán tử Tìm kiếm chỉ mục.
Số lần đọc logic ước tính cho toán tử Quét chỉ mục là không đáng kể so với các lần tìm kiếm; vẫn đang TRẦN (1e0 * @numgroups / @rowsperpage). Lấy Truy vấn 4 làm ví dụ; giả sử idx_sid chỉ mục phù hợp với khoảng 600 hàng trên mỗi trang lá (số lượng thực tế phụ thuộc vào các giá trị shipperid thực tế vì kiểu dữ liệu là VARCHAR (5)). Với 5 nhóm, tất cả các hàng đều nằm gọn trong một trang lá duy nhất. Nếu bạn có 5.000 nhóm, chúng sẽ vừa với 9 trang.
Số lần đọc logic ước tính cho tất cả các lần thực thi của toán tử Tìm kiếm chỉ mục là @numgroups * @indexdepth. Độ sâu của chỉ mục có thể được tính như sau:
CEILING(LOG(CEILING(1e0 * @numrows / @rowsperleafpage), @rowspernonleafpage)) + 1
Sử dụng Truy vấn 4 làm ví dụ, giả sử rằng chúng ta có thể điều chỉnh khoảng 404 hàng trên mỗi trang lá của chỉ mục idx_sid_od và khoảng 352 hàng cho mỗi trang không phải trang. Một lần nữa, các con số thực tế sẽ phụ thuộc vào các giá trị thực tế được lưu trữ trong cột shipperid vì kiểu dữ liệu của nó là VARCHAR (5)). Đối với các ước tính, hãy nhớ rằng bạn có thể sử dụng các phép tính được mô tả ở đây. Với dữ liệu mẫu đại diện tốt có sẵn, bạn có thể sử dụng truy vấn sau để tìm ra số hàng có thể vừa với trang lá và trang không trang của chỉ mục đã cho:
SELECT
CASE P.index_level WHEN 0 THEN 'leaf' WHEN 1 THEN 'nonleaf' END AS pagetype,
FLOOR(8096 / (P.avg_record_size_in_bytes + 2)) AS rowsperpage
FROM (SELECT *
FROM sys.indexes
WHERE object_id = OBJECT_ID('dbo.Orders')
AND name = 'idx_sid_od') AS I
CROSS APPLY sys.dm_db_index_physical_stats
(DB_ID('PerformanceV3'), I.object_id, I.index_id, NULL, 'DETAILED') AS P
WHERE P.index_level <= 1; Tôi nhận được kết quả sau:
pagetype rowsperpage -------- ---------------------- leaf 404 nonleaf 352
Với những con số này, độ sâu của chỉ mục so với số hàng trong bảng là:
CEILING(LOG(CEILING(1e0 * @numrows / 404), 352)) + 1
Với 1.000.000 hàng trong bảng, điều này dẫn đến độ sâu chỉ mục là 3. Ở khoảng 50 triệu hàng, độ sâu chỉ mục tăng lên 4 cấp và ở khoảng 17,62 tỷ hàng, độ sâu chỉ mục tăng lên 5 cấp.
Ở bất kỳ tỷ lệ nào, đối với số nhóm và số hàng, giả sử số hàng trên mỗi trang ở trên, công thức sau sẽ tính số lần đọc lôgic ước tính cho Truy vấn 4:
CEILING(1e0 * @numgroups / 600) + @numgroups * (CEILING(LOG(CEILING(1e0 * @numrows / 404), 352)) + 1)
Ví dụ:với 5 nhóm và 1.000.000 hàng, bạn chỉ nhận được tổng cộng 16 lần đọc! Nhớ lại rằng chiến lược dựa trên quét mặc định cho truy vấn được nhóm bao gồm nhiều lần đọc logic như CEILING (1e0 * @numrows / @rowsperpage). Sử dụng Truy vấn 1 làm ví dụ và giả sử có khoảng 404 hàng trên mỗi trang lá của chỉ mục idx_sid_od, với cùng số hàng 1.000.000, bạn nhận được khoảng 2.476 lần đọc. Tăng số hàng trong bảng theo hệ số từ 1.000 đến 1.000.000.000, nhưng giữ số lượng nhóm cố định. Số lần đọc được yêu cầu với chiến lược tìm kiếm thay đổi rất ít thành 21, trong khi số lần đọc được yêu cầu với chiến lược quét tăng tuyến tính lên 2,475,248.
Cái hay của chiến lược tìm kiếm là miễn là số lượng nhóm nhỏ và cố định, nó có tỷ lệ gần như không đổi so với số hàng trong bảng. Đó là bởi vì số lượng tìm kiếm được xác định bởi số lượng nhóm và độ sâu của chỉ mục liên quan đến số lượng hàng trong bảng theo kiểu lôgarit trong đó cơ sở nhật ký là số hàng phù hợp với một trang không phải trang. Ngược lại, chiến lược dựa trên quét có quy mô tuyến tính liên quan đến số lượng hàng có liên quan.
Hình 4 cho thấy số lần đọc ước tính cho hai chiến lược, được áp dụng bởi Truy vấn 1 và Truy vấn 4, với số lượng cố định của nhóm là 5 và số lượng hàng khác nhau trong bảng chính.
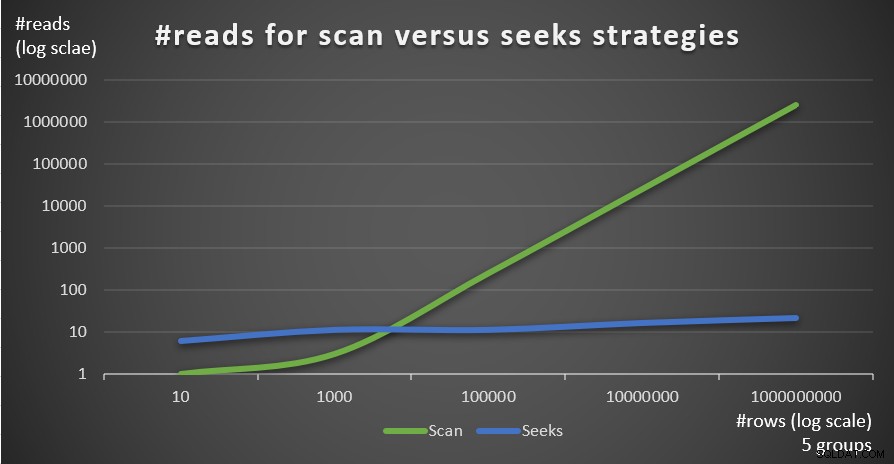 Hình 4:#reads chiến lược quét so với tìm kiếm (5 nhóm)
Hình 4:#reads chiến lược quét so với tìm kiếm (5 nhóm)
Hình 5 cho thấy số lần đọc ước tính cho hai chiến lược, với số hàng cố định là 1.000.000 trong bảng chính và số lượng nhóm khác nhau.
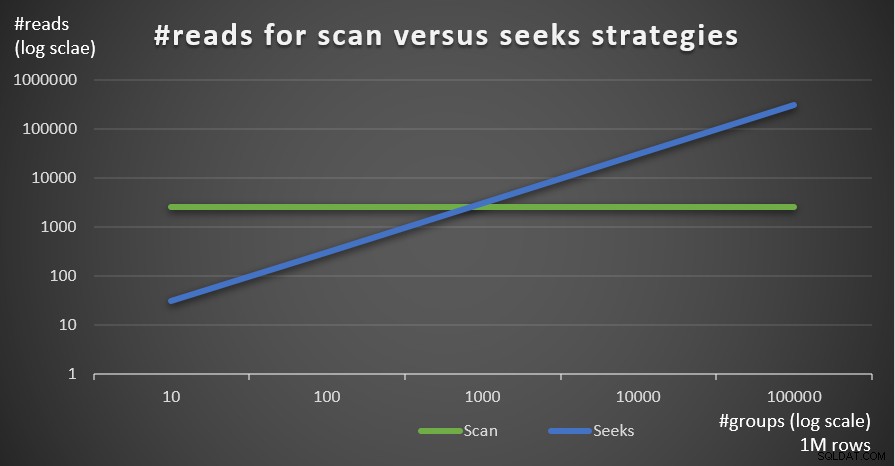 Hình 5:#reads chiến lược quét so với tìm kiếm (1 triệu hàng)
Hình 5:#reads chiến lược quét so với tìm kiếm (1 triệu hàng)
Bạn có thể thấy rất rõ rằng mật độ tập hợp nhóm càng cao (số lượng nhóm nhỏ hơn) và bảng chính càng lớn, thì chiến lược tìm kiếm càng được ưu tiên hơn về số lần đọc. Nếu bạn đang thắc mắc về kiểu I / O được sử dụng bởi từng chiến lược; chắc chắn, hoạt động tìm kiếm chỉ mục thực hiện nhập / xuất ngẫu nhiên, trong khi hoạt động quét chỉ mục thực hiện nhập / xuất tuần tự. Tuy nhiên, khá rõ ràng là chiến lược nào là tối ưu hơn trong những trường hợp khắc nghiệt hơn.
Đối với chi phí kế hoạch truy vấn, một lần nữa, sử dụng kế hoạch cho Truy vấn 4 trong Hình 3 làm ví dụ, hãy chia nhỏ nó cho các toán tử riêng lẻ trong kế hoạch.
Công thức được thiết kế ngược cho chi phí của toán tử Quét chỉ mục là:
0.002541259259259 + @numpages * 0.000740740740741 + @numgroups * 0.0000011
Trong trường hợp của chúng tôi, với 5 nhóm, tất cả đều nằm trong một trang, chi phí là:
0.002541259259259 + 1 * 0.000740740740741 + 5 * 0.0000011 = 0.0032875
Chi phí được trình bày trong kế hoạch là như nhau.
Giống như trước đây, bạn có thể ước tính số trang trong cấp độ lá của chỉ mục dựa trên số hàng ước tính trên mỗi trang bằng cách sử dụng công thức CEILING (1e0 * @numrows / @rowsperpage), trong trường hợp của chúng tôi là CEILING (1e0 * @ numgroups / @groupsperpage). Giả sử idx_sid chỉ mục phù hợp với khoảng 600 hàng trên mỗi trang lá, với 5 nhóm bạn sẽ cần đọc một trang. Ở bất kỳ mức độ nào, công thức tính giá cho toán tử Quét chỉ mục sau đó sẽ trở thành:
0.002541259259259 + CEILING(1e0 * @numgroups / @groupsperpage) * 0.000740740740741 + @numgroups * 0.0000011
Công thức tính chi phí được thiết kế ngược cho toán tử Vòng lặp lồng nhau là:
@executions * 0.00000418
Trong trường hợp của chúng tôi, điều này được dịch thành:
@numgroups * 0.00000418
Đối với Truy vấn 4, với 5 nhóm, bạn nhận được:
5 * 0.00000418 = 0.0000209
Chi phí được trình bày trong kế hoạch là như nhau.
Công thức tính giá được thiết kế ngược cho toán tử Hàng đầu là:
@executions * @toprows * 0.00000001
Trong trường hợp của chúng tôi, điều này được dịch thành:
@numgroups * 1 * 0.00000001
Với 5 nhóm, bạn nhận được:
5 * 0.0000001 = 0.0000005
Chi phí được trình bày trong kế hoạch là như nhau.
Đối với nhà điều hành Index Seek, ở đây tôi đã nhận được sự trợ giúp đắc lực từ Paul White; cảm ơn bạn của tôi! Việc tính toán khác nhau đối với lần thực thi đầu tiên và đối với các giao dịch trả lại (các lần thực thi không phải lần đầu tiên không sử dụng lại kết quả của lần thực hiện trước đó). Giống như chúng ta đã làm với toán tử Quét chỉ mục, hãy bắt đầu với việc xác định các hằng số của mô hình chi phí:
@randomio = 0.003125 -- Random I/O cost @seqio = 0.000740740740741 -- Sequential I/O cost @cpubase = 0.000157 -- CPU base cost @cpurow = 0.0000011 -- CPU cost per row
Đối với một lần thực thi, không áp dụng mục tiêu hàng, chi phí I / O và CPU là:
I/O cost: @randomio + (@numpages - 1e0) * @seqio = 0.002384259259259 + @numpages * 0.000740740740741 CPU cost: @cpubase + @numrows * @cpurow = 0.000157 + @numrows * 0.0000011
Vì chúng tôi sử dụng TOP (1), chúng tôi chỉ có một trang và một hàng liên quan, vì vậy chi phí là:
I/O cost: 0.002384259259259 + 1 * 0.000740740740741 = 0.003125 CPU cost: 0.000157 + 1 * 0.0000011 = 0.0001581
Vì vậy, chi phí thực hiện đầu tiên của toán tử Tìm kiếm chỉ mục trong trường hợp của chúng tôi là:
@firstexecution = 0.003125 + 0.0001581 = 0.0032831
Đối với chi phí hoàn lại, như thường lệ, nó bao gồm chi phí CPU và I / O. Hãy gọi chúng tương ứng là @rebindcpu và @rebindio. Với Truy vấn 4, có 5 nhóm, chúng ta có 4 rebinds (gọi là @rebinds). Chi phí @rebindcpu là một phần dễ dàng. Công thức là:
@rebindcpu = @rebinds * (@cpubase + @cpurow)
Trong trường hợp của chúng tôi, điều này được dịch thành:
@rebindcpu = 4 * (0.000157 + 0.0000011) = 0.0006324
Phần @rebindio phức tạp hơn một chút. Ở đây, công thức tính chi phí sẽ tính toán thống kê số lượng trang riêng biệt dự kiến mà các rebinds dự kiến sẽ đọc bằng cách sử dụng lấy mẫu có thay thế. Chúng tôi sẽ gọi phần tử này là @pswr (đối với các trang riêng biệt được lấy mẫu thay thế). Ý tưởng là, chúng tôi có @indexdatapages số trang trong chỉ mục (trong trường hợp của chúng tôi là 2,473) và số rebinds @rebinds (trong trường hợp của chúng tôi là 4). Giả sử chúng ta có cùng xác suất đọc bất kỳ trang nhất định nào với mỗi lần đóng lại, chúng ta dự kiến sẽ đọc tổng cộng bao nhiêu trang riêng biệt? Điều này tương tự như việc bạn có một chiếc túi có 2.473 quả bóng, và bốn lần bạn lấy một quả bóng từ trong túi ra một cách mù quáng và sau đó trả nó vào túi. Theo thống kê, bạn dự kiến sẽ rút được tổng cộng bao nhiêu quả bóng khác nhau? Công thức cho điều này, sử dụng toán hạng của chúng tôi, là:
@pswr = @indexdatapages * (1e0 - POWER((@indexdatapages - 1e0) / @indexdatapages, @rebinds))
Với những con số của chúng tôi, bạn nhận được:
@pswr = 2473 * (1e0 - POWER((2473 - 1e0) / 2473, 4)) = 3.99757445099277
Tiếp theo, bạn tính số hàng và số trang bạn có trung bình cho mỗi nhóm:
@grouprows = @cardinality * @density @grouppages = CEILING(@indexdatapages * @density)
Trong Truy vấn 4 của chúng ta, mật độ là 1.000.000 và mật độ là 1/5 =0,2. Vì vậy, bạn nhận được:
@grouprows = 1000000 * 0.2 = 200000 @numpages = CEILING(2473 * 0.2) = 495
Sau đó, bạn tính chi phí I / O mà không cần lọc (gọi nó là @io) là:
@io = @randomio + (@seqio * (@grouppages - 1e0))
Trong trường hợp của chúng tôi, bạn nhận được:
@io = 0.003125 + (0.000740740740741 * (495 - 1e0)) = 0.369050925926054
Và cuối cùng, vì tìm kiếm chỉ trích xuất một hàng trong mỗi rebind, bạn tính @rebindio bằng công thức sau:
@rebindio = (1e0 / @grouprows) * ((@pswr - 1e0) * @io)
Trong trường hợp của chúng tôi, bạn nhận được:
@rebindio = (1e0 / 200000) * ((3.99757445099277 - 1e0) * 0.369050925926054) = 0.000005531288
Cuối cùng, chi phí của nhà điều hành là:
Operator cost: @firstexecution + @rebindcpu + @rebindio = 0.0032831 + 0.0006324 + 0.000005531288 = 0.003921031288
Điều này giống như chi phí toán tử Tìm kiếm chỉ mục được hiển thị trong kế hoạch cho Truy vấn 4.
Bây giờ bạn có thể tổng hợp chi phí của tất cả các nhà khai thác để có được chi phí gói truy vấn hoàn chỉnh. Bạn nhận được:
Query plan cost: 0.002541259259259 + CEILING(1e0 * @numgroups / @groupsperpage)
* 0.000740740740741 + @numgroups * 0.0000011
+ @numgroups * 0.00000418
+ @numgroups * 0.00000001
+ 0.0032831 + (@numgroups - 1e0) * 0.0001581
+ (1e0 / (@numrows / @numgroups)) * (CEILING(1e0 * @numrows / @rowsperpage)
* (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0)
/ CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0)
* (0.003125 + (0.000740740740741 * (CEILING((@numrows / @rowsperpage)
* (1e0 / @numgroups)) - 1e0))) Sau khi đơn giản hóa, bạn sẽ có công thức chi phí hoàn chỉnh sau cho chiến lược Tìm kiếm của chúng tôi:
0.005666259259259 + CEILING(1e0 * @numgroups / @groupsperpage)
* 0.000740740740741 + @numgroups * 0.0000011
+ @numgroups * 0.00016229
+ (1e0 / (@numrows / @numgroups)) * (CEILING(1e0 * @numrows / @rowsperpage)
* (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0)
/ CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0)
* (0.003125 + (0.000740740740741 * (CEILING((@numrows / @rowsperpage)
* (1e0 / @numgroups)) - 1e0))) Ví dụ:bằng cách sử dụng T-SQL, đây là việc tính toán chi phí gói truy vấn với chiến lược Tìm kiếm của chúng tôi cho Truy vấn 4:
DECLARE
@numrows AS FLOAT = 1000000,
@numgroups AS FLOAT = 5,
@rowsperpage AS FLOAT = 404,
@groupsperpage AS FLOAT = 600;
SELECT
0.005666259259259 + CEILING(1e0 * @numgroups / @groupsperpage)
* 0.000740740740741 + @numgroups * 0.0000011
+ @numgroups * 0.00016229
+ (1e0 / (@numrows / @numgroups)) * (CEILING(1e0 * @numrows / @rowsperpage)
* (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0)
/ CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0)
* (0.003125 + (0.000740740740741 * (CEILING((@numrows / @rowsperpage)
* (1e0 / @numgroups)) - 1e0)))
AS seeksplancost; Phép tính này tính toán chi phí 0,0072295 cho Truy vấn 4. Chi phí ước tính được hiển thị trong Hình 3 là 0,0072299. Đó là khá gần! Như một bài tập, hãy tính toán chi phí cho Truy vấn 5 và Truy vấn 6 bằng công thức này và xác minh rằng bạn nhận được những con số gần với những con số được hiển thị trong Hình 3.
Nhớ lại rằng công thức tính phí cho chiến lược dựa trên quét mặc định là (gọi nó là Quét chiến lược):
0.002549259259259 + CEILING(1e0 * @numrows / @rowsperpage) * 0.000740740740741 + @numrows * 0.0000017 + @numgroups * 0.0000005
Sử dụng Truy vấn 1 làm ví dụ và giả sử 1.000.000 hàng trong bảng, 404 hàng mỗi trang và 5 nhóm, chi phí kế hoạch truy vấn ước tính của chiến lược quét là 3,5366.
Hình 6 cho thấy chi phí kế hoạch truy vấn ước tính cho hai chiến lược, được áp dụng bởi Truy vấn 1 (quét) và Truy vấn 4 (tìm kiếm), với số lượng cố định nhóm là 5 và số lượng hàng khác nhau trong bảng chính.
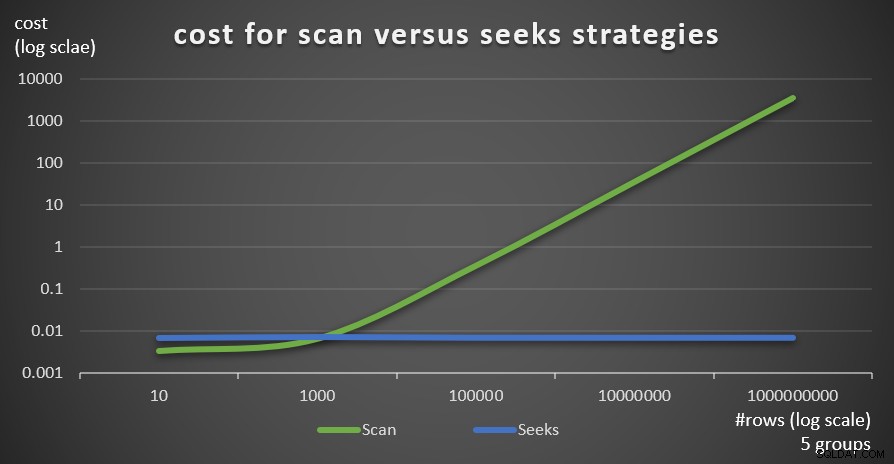 Hình 6:chi phí cho quét so với tìm kiếm chiến lược (5 nhóm)
Hình 6:chi phí cho quét so với tìm kiếm chiến lược (5 nhóm)
Hình 7 cho thấy chi phí kế hoạch truy vấn ước tính cho hai chiến lược, với số lượng hàng cố định trong bảng chính là 1.000.000 và số lượng nhóm khác nhau.
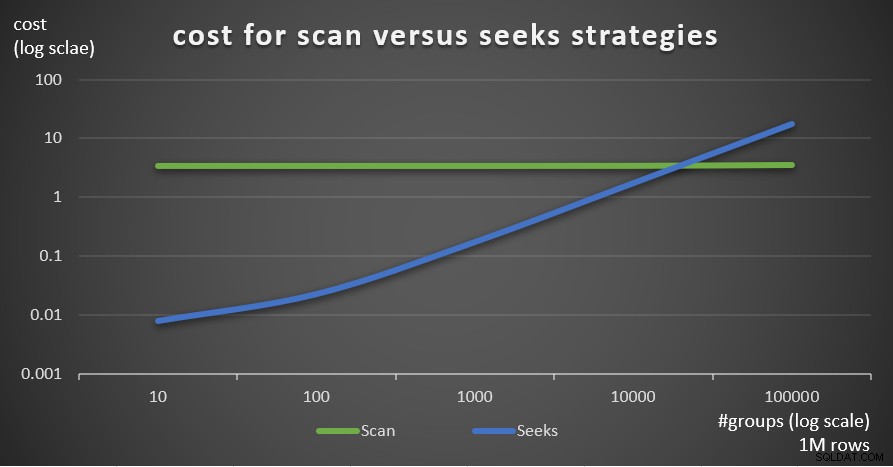 Hình 7:chi phí cho quét so với tìm kiếm chiến lược (1 triệu hàng)
Hình 7:chi phí cho quét so với tìm kiếm chiến lược (1 triệu hàng)
Rõ ràng là từ những phát hiện này, mật độ tập hợp nhóm càng cao và càng nhiều hàng trong bảng chính, thì chiến lược tìm kiếm càng tối ưu hơn so với chiến lược quét. Vì vậy, trong các tình huống mật độ cao, hãy đảm bảo bạn thử giải pháp dựa trên ÁP DỤNG. Trong khi đó, chúng ta có thể hy vọng rằng Microsoft sẽ thêm chiến lược này như một tùy chọn tích hợp cho các truy vấn được nhóm.
Kết luận
Bài viết này kết thúc loạt bài gồm năm phần về ngưỡng tối ưu hóa truy vấn cho các truy vấn nhóm và tổng hợp dữ liệu. Một mục tiêu của loạt bài này là thảo luận về các chi tiết cụ thể của các thuật toán khác nhau mà trình tối ưu hóa có thể sử dụng, các điều kiện mà mỗi thuật toán được ưu tiên và khi nào bạn nên can thiệp bằng cách viết lại truy vấn của riêng mình. Một mục tiêu khác là giải thích quá trình khám phá các lựa chọn khác nhau và so sánh chúng. Rõ ràng, quy trình phân tích tương tự có thể được áp dụng để lọc, nối, tạo cửa sổ và nhiều khía cạnh khác của tối ưu hóa truy vấn. Hy vọng rằng bây giờ bạn cảm thấy được trang bị nhiều hơn để đối phó với việc điều chỉnh truy vấn so với trước đây.