Gần đây tôi đã viết một bài về DISTINCT và GROUP BY. Đó là một so sánh cho thấy rằng GROUP BY nói chung là một lựa chọn tốt hơn DISTINCT. Nó nằm trên một trang web khác, nhưng hãy nhớ quay lại sqlperformance.com ngay sau ..
Một trong những so sánh truy vấn mà tôi đã hiển thị trong bài đăng đó là giữa GROUP BY và DISTINCT cho một truy vấn phụ, cho thấy rằng DISTINCT chậm hơn rất nhiều, vì nó phải tìm nạp Tên Sản phẩm cho mọi hàng trong bảng Bán hàng, thay vì thay vì chỉ cho mỗi ProductID khác nhau. Điều này khá rõ ràng so với các kế hoạch truy vấn, nơi bạn có thể thấy rằng trong truy vấn đầu tiên, Tổng hợp hoạt động trên dữ liệu chỉ từ một bảng, thay vì dựa trên kết quả của phép kết hợp. Ồ, và cả hai truy vấn đều cho 266 hàng giống nhau.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID;
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od;

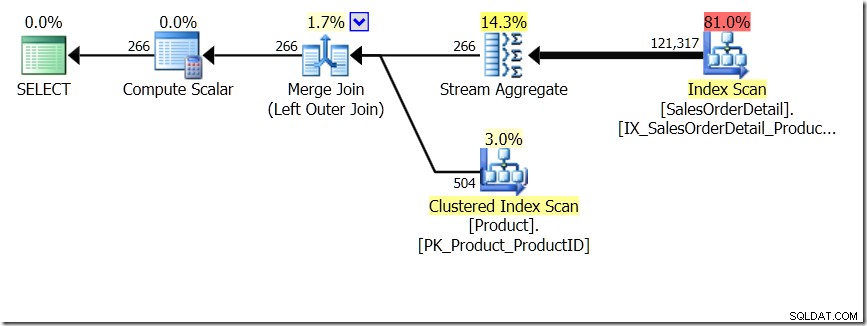
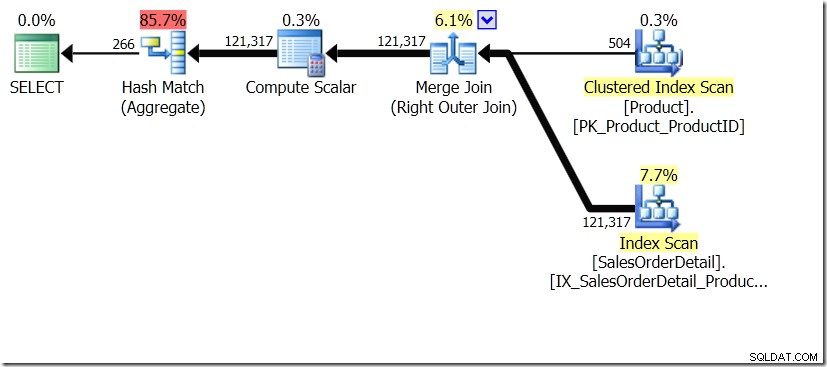
Bây giờ, nó đã được chỉ ra bởi Adam Machanic (@adammachanic) trong một tweet đề cập đến bài đăng của Aaron về GROUP BY v DISTINCT rằng hai truy vấn về cơ bản là khác nhau, rằng một truy vấn thực sự đang yêu cầu tập hợp các kết hợp riêng biệt dựa trên kết quả của truy vấn phụ, thay vì chạy truy vấn phụ trên các giá trị riêng biệt được chuyển vào. Đó là những gì chúng ta thấy trong kế hoạch và là lý do tại sao hiệu suất lại khác biệt như vậy.
Vấn đề là tất cả chúng ta đều giả định rằng kết quả sẽ giống hệt nhau.
Nhưng đó là một giả định và không phải là một giả định tốt.
Tôi sẽ tưởng tượng trong giây lát rằng Trình tối ưu hóa Truy vấn đã đưa ra một kế hoạch khác. Tôi đã sử dụng các gợi ý cho việc này, nhưng như bạn biết, Trình tối ưu hóa Truy vấn có thể chọn tạo các kế hoạch ở tất cả các loại hình dạng vì mọi lý do.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID
option (loop join);
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
option (loop join);
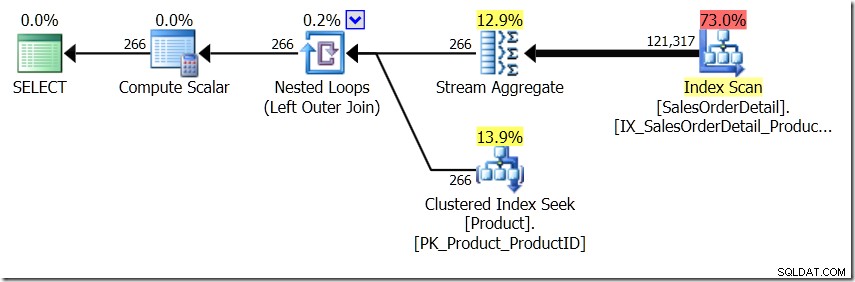
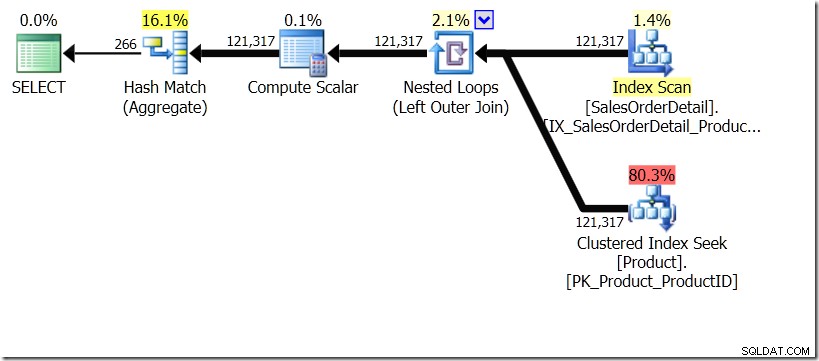
Trong tình huống này, chúng tôi thực hiện 266 Tìm kiếm trong bảng Sản phẩm, một tìm kiếm cho mỗi ProductID khác nhau mà chúng tôi quan tâm, hoặc 121.317 Tìm kiếm. Vì vậy, nếu chúng tôi đang nghĩ về một ProductID cụ thể, chúng tôi biết rằng chúng tôi sẽ lấy lại một Tên duy nhất từ cái đầu tiên. Và chúng tôi giả định rằng chúng tôi sẽ lấy lại một Tên duy nhất cho ProductID đó, ngay cả khi chúng tôi phải yêu cầu nó hàng trăm lần. Chúng tôi chỉ giả sử rằng chúng tôi sẽ nhận lại kết quả tương tự.
Nhưng nếu chúng ta không làm như vậy thì sao?
Điều này nghe có vẻ giống như một điều ở mức độ cô lập, vì vậy hãy sử dụng NOLOCK khi chúng ta nhấn vào bảng Sản phẩm. Và hãy chạy (trong một cửa sổ khác) một tập lệnh để thay đổi văn bản trong các cột Tên. Tôi sẽ làm đi làm lại, để cố gắng thực hiện một số thay đổi giữa truy vấn của mình.
update Production.Product set Name = cast(newid() as varchar(36)); go 1000
Bây giờ, kết quả của tôi đã khác. Các kế hoạch giống nhau (ngoại trừ số hàng đến từ Tổng hợp băm trong truy vấn thứ hai), nhưng kết quả của tôi khác.
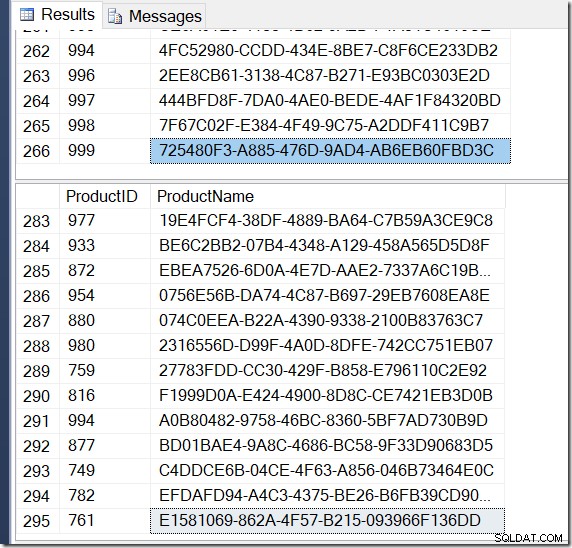
Chắc chắn rồi, tôi có nhiều hàng hơn với DISTINCT, vì nó tìm các giá trị Tên khác nhau cho cùng một ProductID. Và tôi không nhất thiết phải có 295 hàng. Một cái khác mà tôi chạy nó, tôi có thể nhận được 273, hoặc 300, hoặc có thể, 121.317.
Không khó để tìm một ví dụ về ProductID hiển thị nhiều giá trị Tên, xác nhận điều gì đang xảy ra.

Rõ ràng, để đảm bảo rằng chúng tôi không nhìn thấy những hàng này trong kết quả, chúng tôi sẽ KHÔNG sử dụng DISTINCT hoặc sử dụng mức cách ly chặt chẽ hơn.
Vấn đề là mặc dù tôi đã đề cập đến việc sử dụng NOLOCK cho ví dụ này, nhưng tôi không cần phải làm như vậy. Tình huống này xảy ra ngay cả với READ COMMITTED, là mức cách ly mặc định trên nhiều hệ thống SQL Server.
Bạn thấy đấy, chúng ta cần mức cách ly REPEATABLE READ để tránh tình trạng này, để giữ các khóa trên mỗi hàng khi nó đã được đọc. Nếu không, một chuỗi riêng có thể thay đổi dữ liệu, như chúng ta đã thấy.
Nhưng… Tôi không thể cho bạn biết rằng kết quả đã được sửa, vì tôi không thể tránh khỏi bế tắc về truy vấn.
Vì vậy, hãy thay đổi các điều kiện, bằng cách đảm bảo rằng truy vấn khác của chúng ta ít gặp vấn đề hơn. Thay vì cập nhật toàn bộ bảng cùng một lúc (điều này ít xảy ra hơn trong thế giới thực), chúng ta hãy chỉ cập nhật một hàng duy nhất tại một thời điểm.
declare @id int = 1; declare @maxid int = (select count(*) from Production.Product); while (@id < @maxid) begin with p as (select *, row_number() over (order by ProductID) as rn from Production.Product) update p set Name = cast(newid() as varchar(36)) where rn = @id; set @id += 1; end go 100
Bây giờ, chúng tôi vẫn có thể chứng minh vấn đề ở mức độ cô lập nhỏ hơn, chẳng hạn như ĐỌC ĐÃ ĐƯỢC CAM KẾT hoặc ĐỌC KHÔNG ĐƯỢC ĐỀ XUẤT (mặc dù bạn có thể cần chạy truy vấn nhiều lần nếu bạn nhận được 266 lần đầu tiên, vì cơ hội cập nhật một hàng trong khi truy vấn ít hơn) và bây giờ chúng tôi có thể chứng minh rằng REPEATABLE READ sửa được lỗi đó (bất kể chúng tôi chạy truy vấn bao nhiêu lần).
REPEATABLE READ thực hiện những gì nó nói trên thiếc. Khi bạn đọc một hàng trong một giao dịch, hàng đó sẽ bị khóa để đảm bảo bạn có thể lặp lại việc đọc và nhận được kết quả tương tự. Các mức cô lập thấp hơn sẽ không loại bỏ các khóa đó cho đến khi bạn cố gắng thay đổi dữ liệu. Nếu kế hoạch truy vấn của bạn không bao giờ cần lặp lại một lần đọc (như trường hợp của kế hoạch GROUP BY của chúng tôi), thì bạn sẽ không cần ĐỌC LẶP LẠI.
Có thể cho rằng, chúng ta luôn nên sử dụng các mức cô lập cao hơn, chẳng hạn như REPEATABLE READ hoặc SERIALIZABLE, nhưng tất cả đều nhằm vào việc tìm ra những gì hệ thống của chúng ta cần. Các cấp độ này có thể dẫn đến khóa không mong muốn và các cấp độ cách ly SNAPSHOT cũng yêu cầu lập phiên bản đi kèm với giá cả. Đối với tôi, tôi nghĩ đó là một sự đánh đổi. Nếu tôi đang yêu cầu một truy vấn có thể bị ảnh hưởng bởi việc thay đổi dữ liệu, thì tôi có thể cần phải tăng mức cô lập trong một thời gian.
Lý tưởng nhất là bạn không cập nhật dữ liệu vừa được đọc và có thể cần được đọc lại trong khi truy vấn, do đó bạn không cần ĐỌC LẶP LẠI. Nhưng chắc chắn đáng để hiểu những gì có thể xảy ra và nhận ra rằng đây là loại kịch bản khi DISTINCT và GROUP BY có thể không giống nhau.
@rob_farley